
前言
DeepSeek作为国产顶尖大模型,在代码生成和逻辑推理方面表现优异。本文提供三种不同场景下的接入方案,满足从普通用户到开发者的不同需求。
当前问题
由于访问量激增和网络攻击,Deepseek 官网服务经常出现不稳定情况,例如提示"服务器繁忙,请稍后再试"。
基于以上问题,本文提供三种备用使用Deepseek的方法:
- 方法一:使用
chatbox+硅基流动接入云端API使用(适合于普通用户使用) - 方法二:使用
Cursor+硅基流动接入云端API使用(适合于程序员人群) - 方法三:使用
ollama本地化部署使用(适用于有安全隐私需求的用户)
方法一:使用chatbox+硅基流动接入云端API使用
1. 安装chatbox
-
下载对应版本并安装chatbox
说明:
- 本例中以Windows为例,其他平台请参考官网
2. 注册硅基流动账号
-
访问硅基流动官网 https://cloud.siliconflow.cn/

-
完成注册和实名认证
说明:
硅基流动现在注册并实名认证后,会赠送14元金额试用。
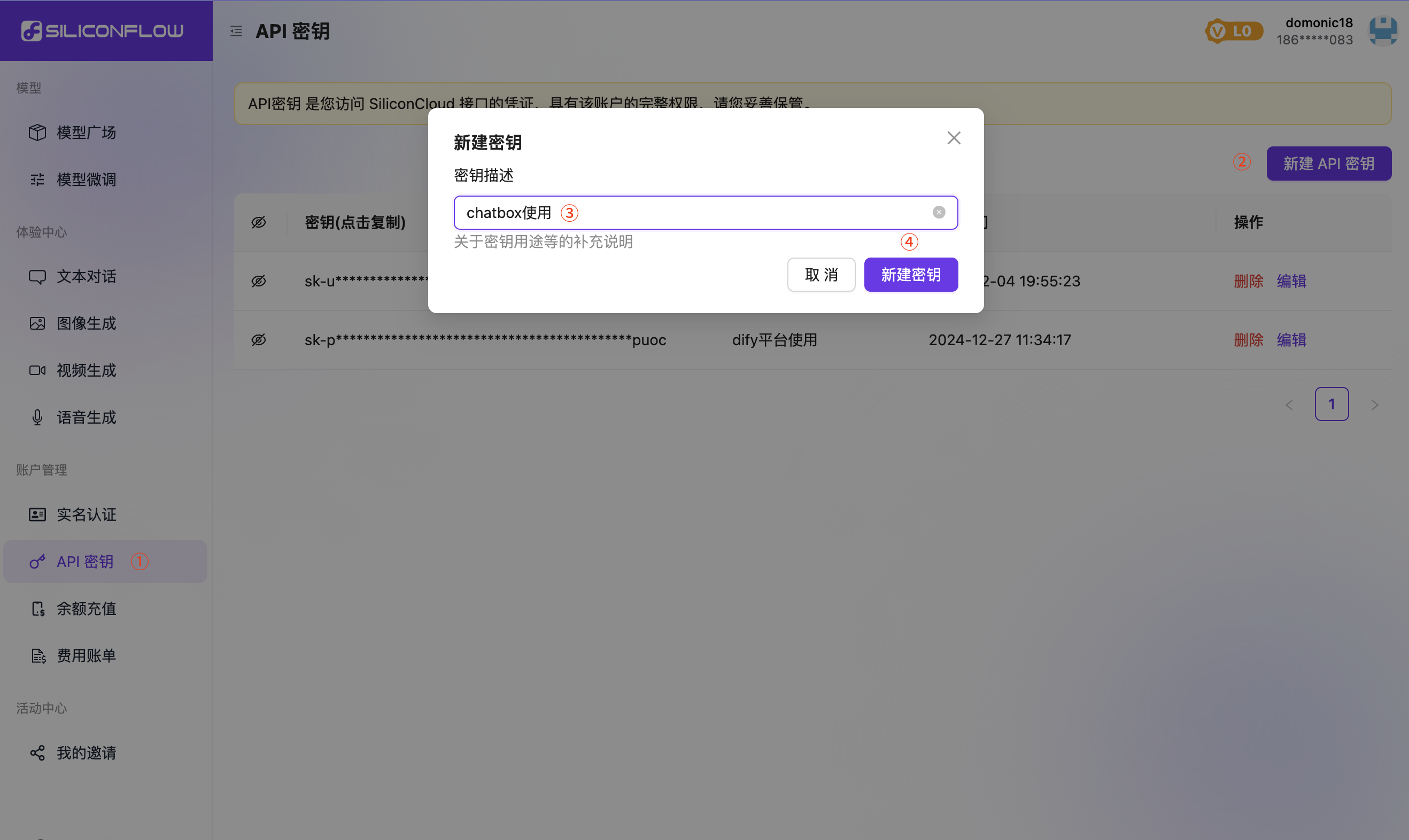
3. 获取API Key
- 登录后,点击左侧菜单栏的「API密钥」
- 选择「API密钥」->「新建API密钥」
- 输入密钥描述内容后,点击「新建密钥」
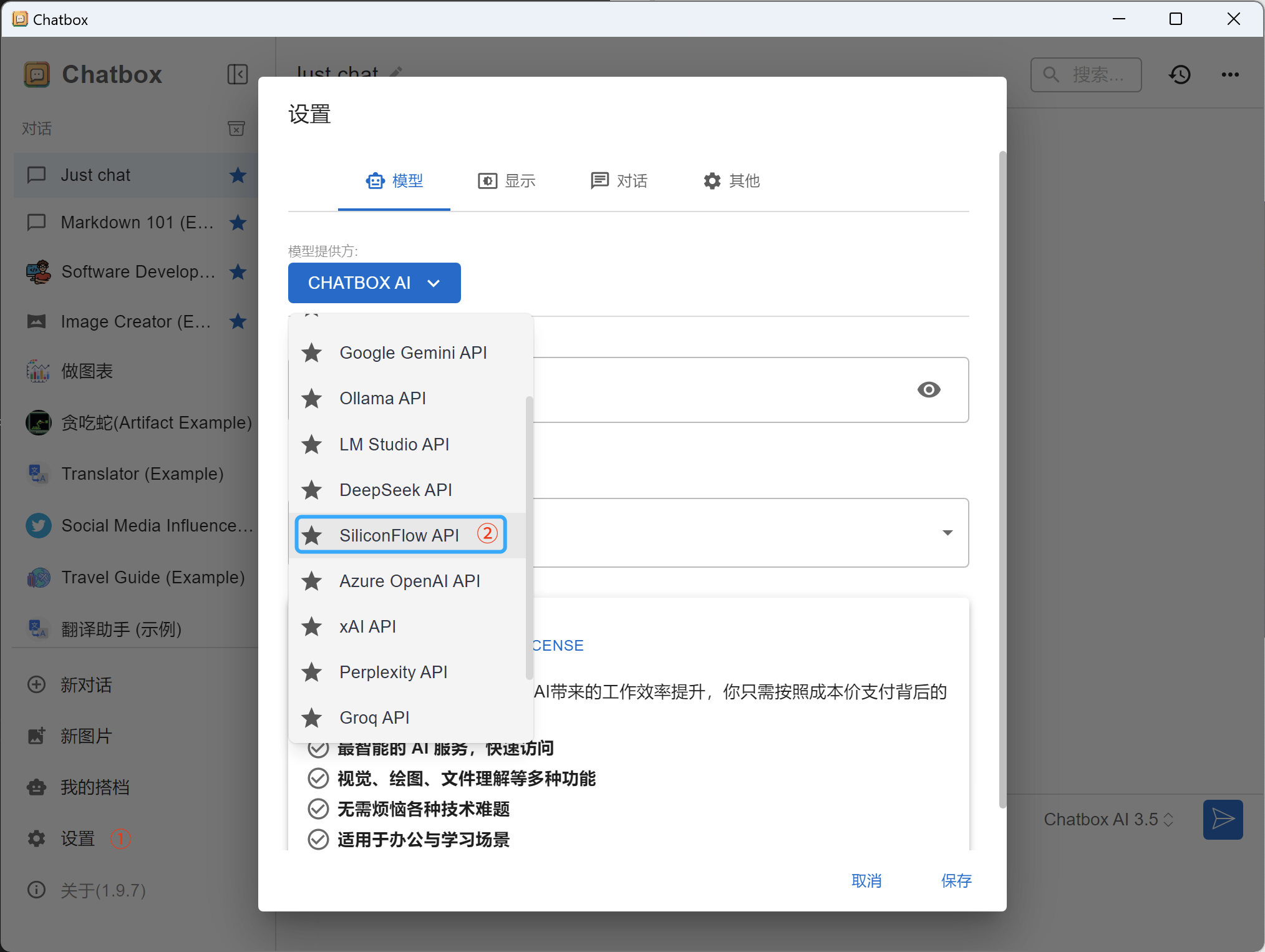
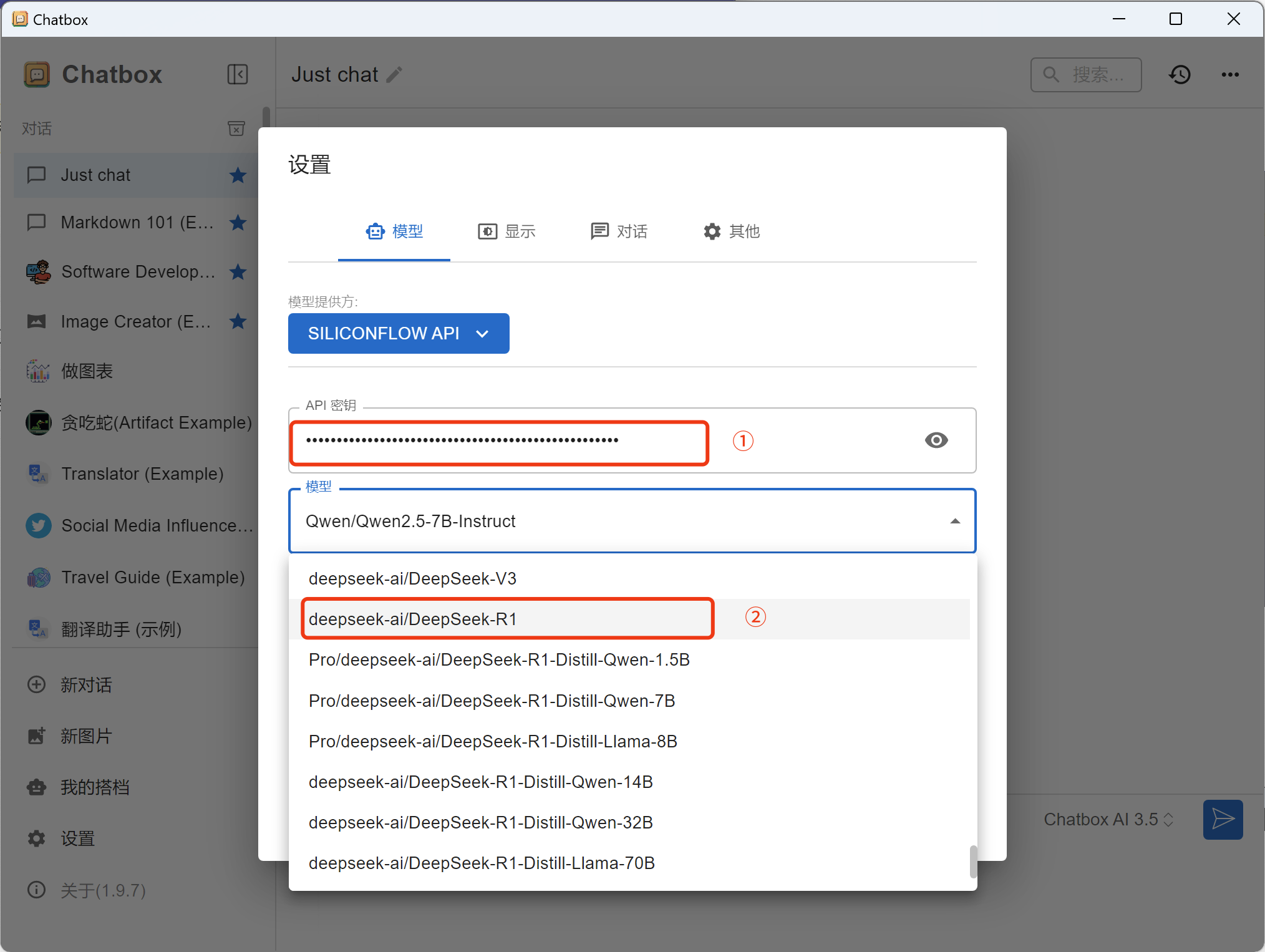
4. 配置chatbox
-
设置 -> 模型提供商 -> 选择「SiliconFlow API」
-
在API密钥框,将上一步获取的API Key填入「API 密钥」
-
在模型框,选择「deepseek-r1」后,点击保存
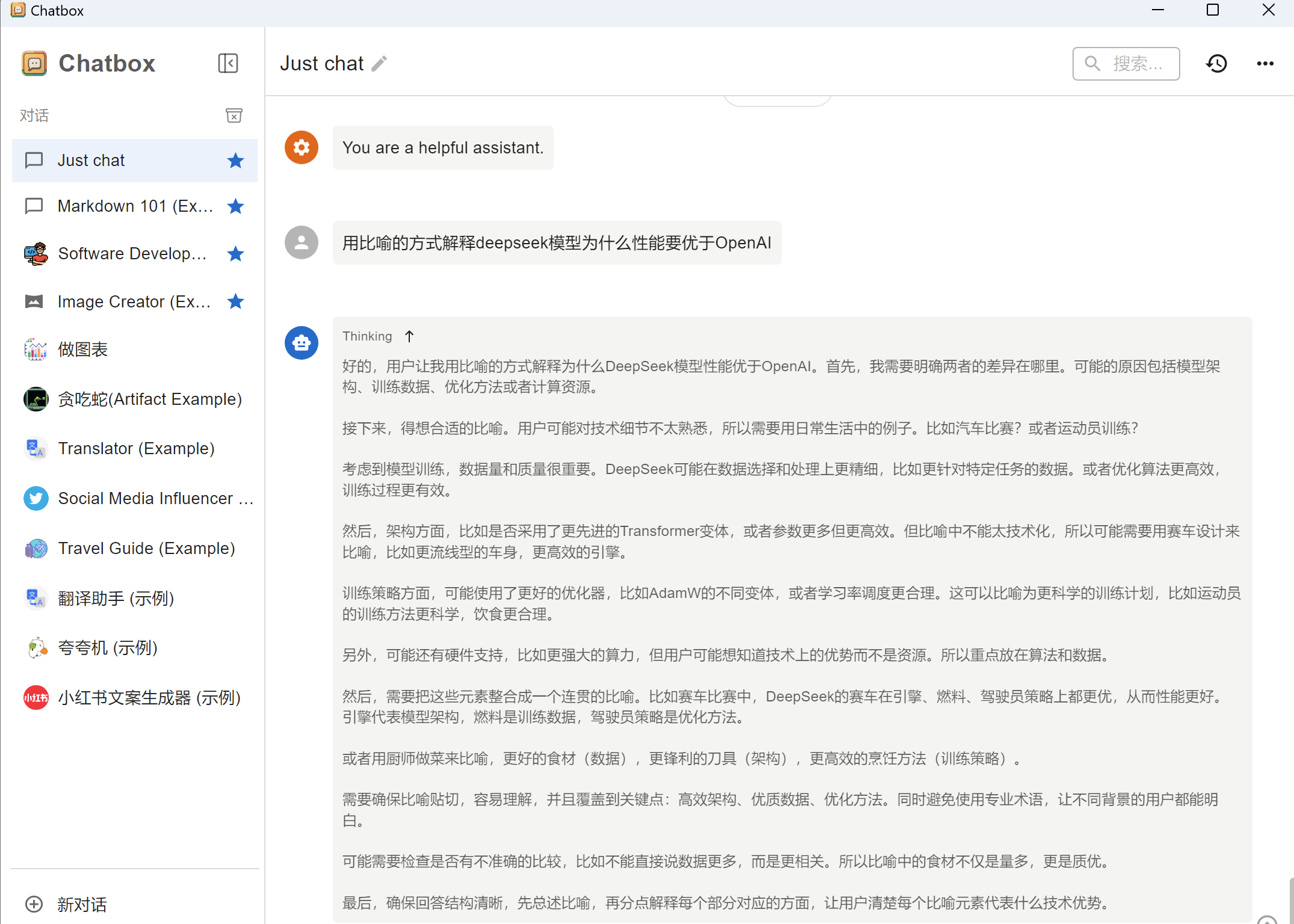
5. 测试模型效果
输入测试问题:"用比喻的方式解释deepseek模型为什么性能要优于OpenAI"

方法二:使用cursor+硅基流动接入云端API使用
1. 安装cursor
-
下载并安装IDE
-
注册cursor账号
2. 配置硅基流动API
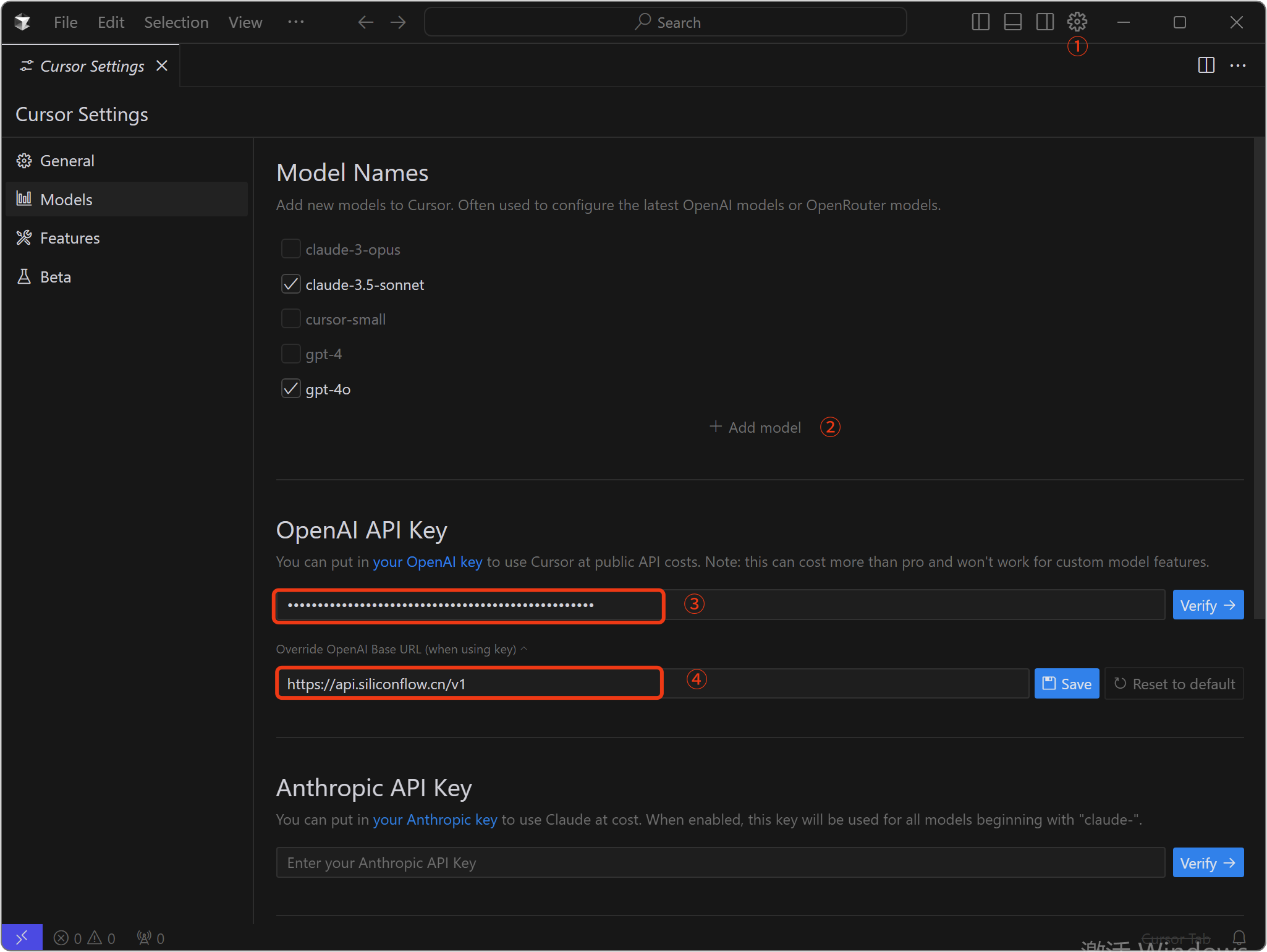
- 打开Cursor设置对话框
- 左侧选择Models
- 在OpenAI API Key框,填入硅基流动上创建的API Key
- 在OpenAI Base URL框,填入
https://api.siliconflow.cn/v1并保存 - 点击Add Model,输入
deepseek-ai/DeepSeek-R1 - 点击Verify,验证模型是否可用
说明:
- 硅基流动的API Base URL可以在硅基流动官网的模型广场,选择对应的模型查看其API文档获得。
- 模型名称
deepseek-ai/DeepSeek-R1可以在硅基流动的模型广场中,选择对应的模型后直接复制获得。
3. 测试代码功能
-
使用cursor创建一个新的项目,例如"俄罗斯方块游戏"
-
使用快捷键
Cmd/Ctrl+I打开Composer界面 -
输入我们的需求后回车,例如:"请使用html实现一个俄罗斯方块游戏"
-
Cursor会调用硅基流动的DeepSeek-R1模型,自动生成俄罗斯方块游戏,如下图:
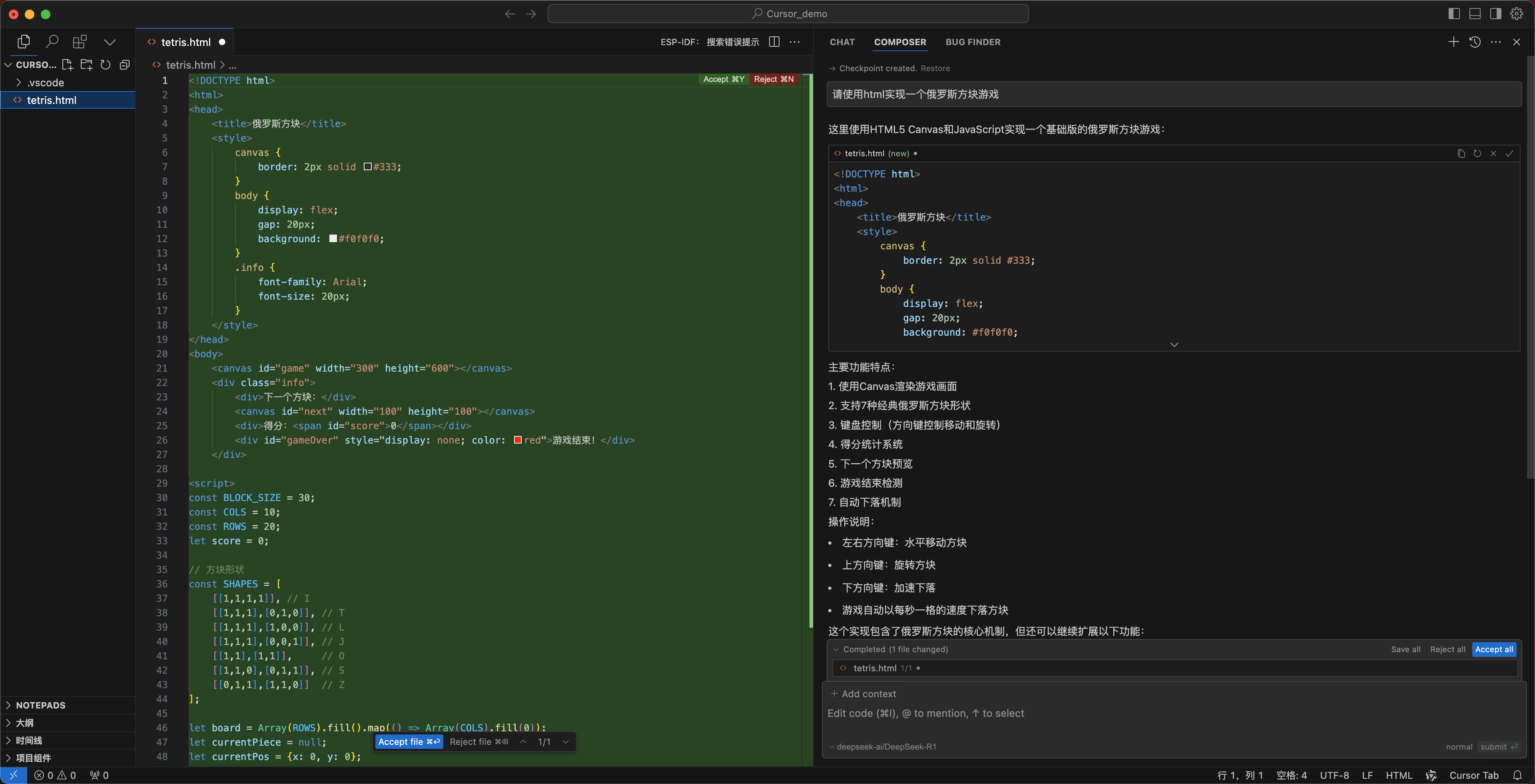
-
使用浏览器打开生成的tetris.html文件,即可看到俄罗斯方块游戏,如下图:
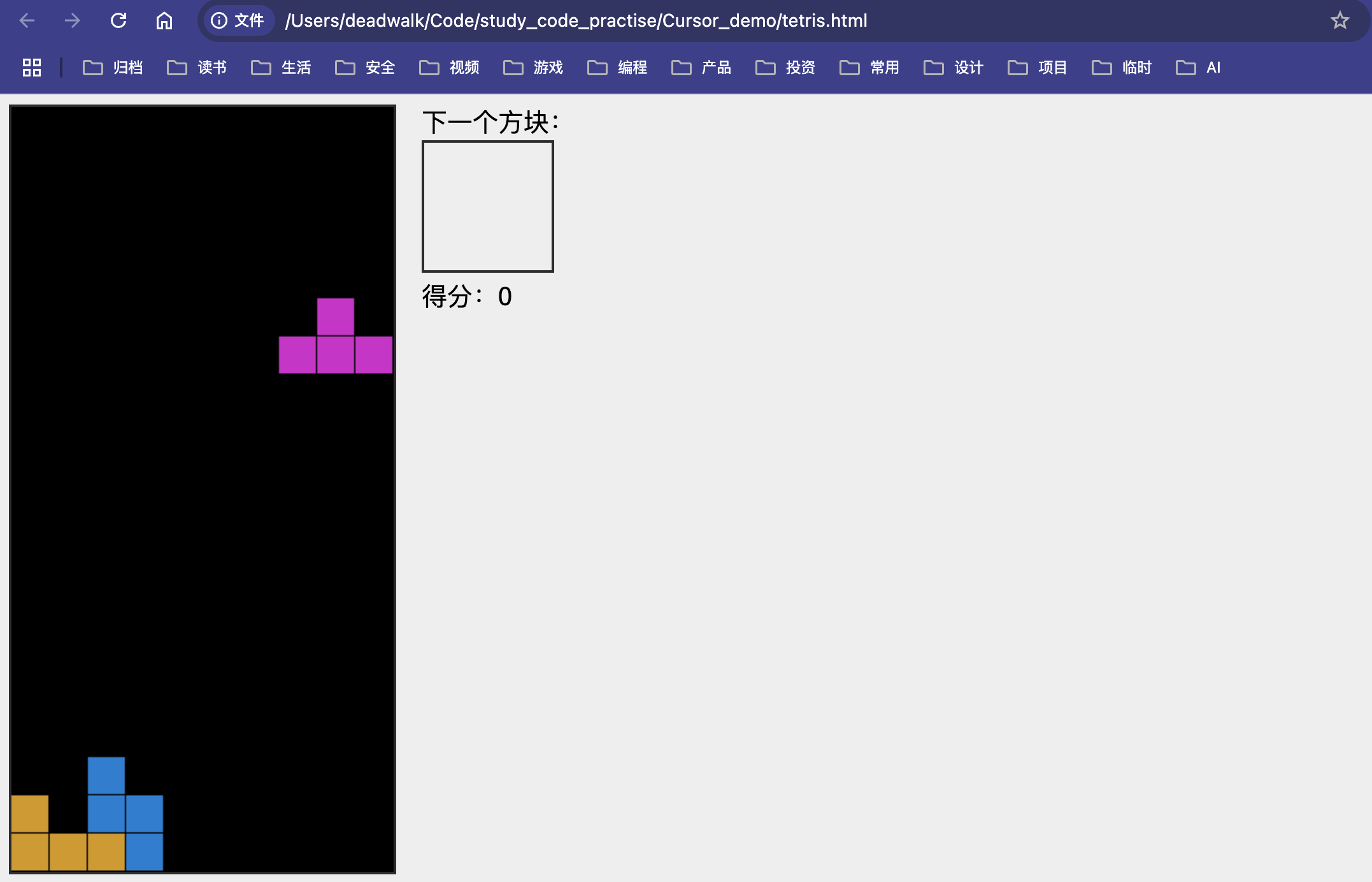
备注:
- Cursor有14天的试用期,试用期结束后需要购买订阅才能继续使用。
- 经过实测,使用Cursor内置的DeepSeek-R1模型会比硅基流动API的DeepSeek-R1模型速度会更快。
方法三:使用ollama本地化部署使用
1. 硬件配置
| 模型规模 | 使用场景 | CPU核心 | 内存容量 | 显卡型号 | 显存需求 | 推荐部署方式 |
|---|---|---|---|---|---|---|
| 1.5B | 嵌入式设备 | 4核 | 8GB | Jetson Orin | 6GB | 4-bit量化+TensorRT加速 |
| 7B | 个人开发/测试 | 8核 | 32GB | RTX 3060 | 14GB | FP16精度+单卡推理 |
| 70B | 企业级服务 | 32核×4 | 512GB | A100 80G ×4 | 320GB | 张量并行+流水线并行 |
| 671B | 超大规模计算 | 64核×8 | 2TB | H100 80G ×16 | 1.28TB | 混合并行+专家并行 |
注明:
- 显存预估方式一般为:模型参数×2.5(如7B模型需7×2.5=17.5GB,需RTX 3090 24GB)
- 本例中,笔者使用的是RTX 4080显卡16G显存,所以选择7B模型。
2. 安装ollama
-
访问ollama官网 https://ollama.com/
-
根据系统选择对应的安装方式
# Windows用户:访问 https://ollama.com/download/windows 下载安装包 # Mac用户:访问 https://ollama.com/download/mac 下载安装包 # Linux用户:执行 curl -fsSL https://ollama.com/install.sh | sh说明:
- 本例中以Windows为例,其他平台请参考官网
- 安装完成后,在命令行中输入ollama可以看到命令行帮助文档
3. 配置ollama的下载路径
因为ollama默认下载路径为C:\Users\用户名\.ollama,所以我们需要配置ollama的下载路径,避免C盘占用过大。
- 在
系统设置→搜索"环境变量"→高级系统设置→添加系统变量中新增Ollama的下载路径变量名:OLLAMA_MODELS 变量值:G:\ai_LLMs_modules\Ollama说明:变量值请根据自己的情况修改,本例中是
G:\ai_LLMs_modules\Ollama

3. 下载DeepSeek大模型
-
访问ollama模型查询页面https://ollama.com/search
-
搜索deepseek-r1模型
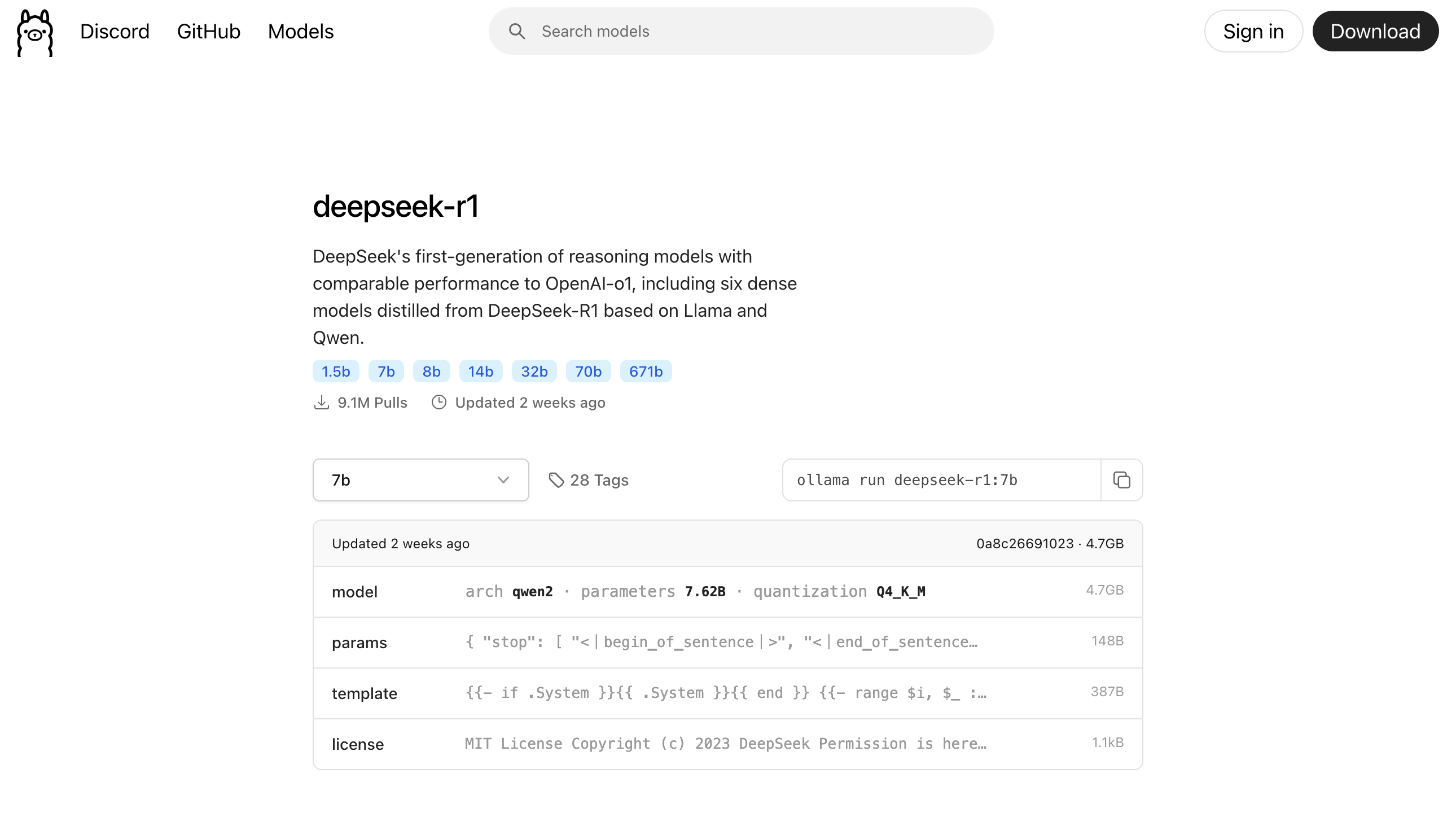
-
根据本机配置情况,我们选择
deepseek-r1:7b模型,执行如下命令ollama run deepseek-r1:7b -
下载模型根据网络环境会花费不同的时间,待下载完成后,会提示"success"

4. 测试模型效果
>>> 请用Python写一个快速排序算法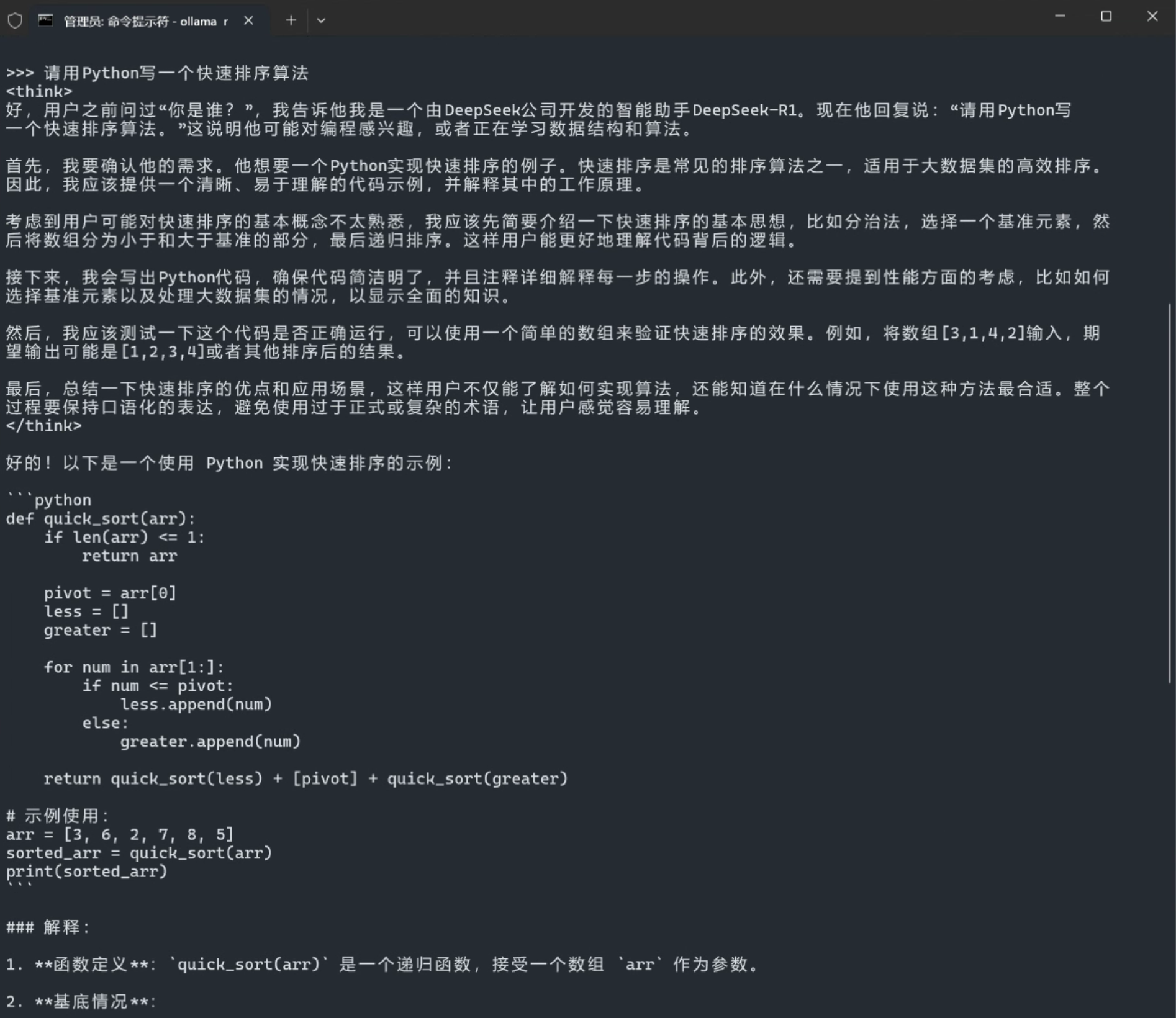
5. 集成前端UI
因为ollama本身没有提供前端UI,通过命令行交互起来比较繁琐。
所以,我们可以根据之前介绍的方法一或方法二,将模型集成到前端chatbox或者cursor中。
本例,我们采用方法一,将模型集成到chatbox中。
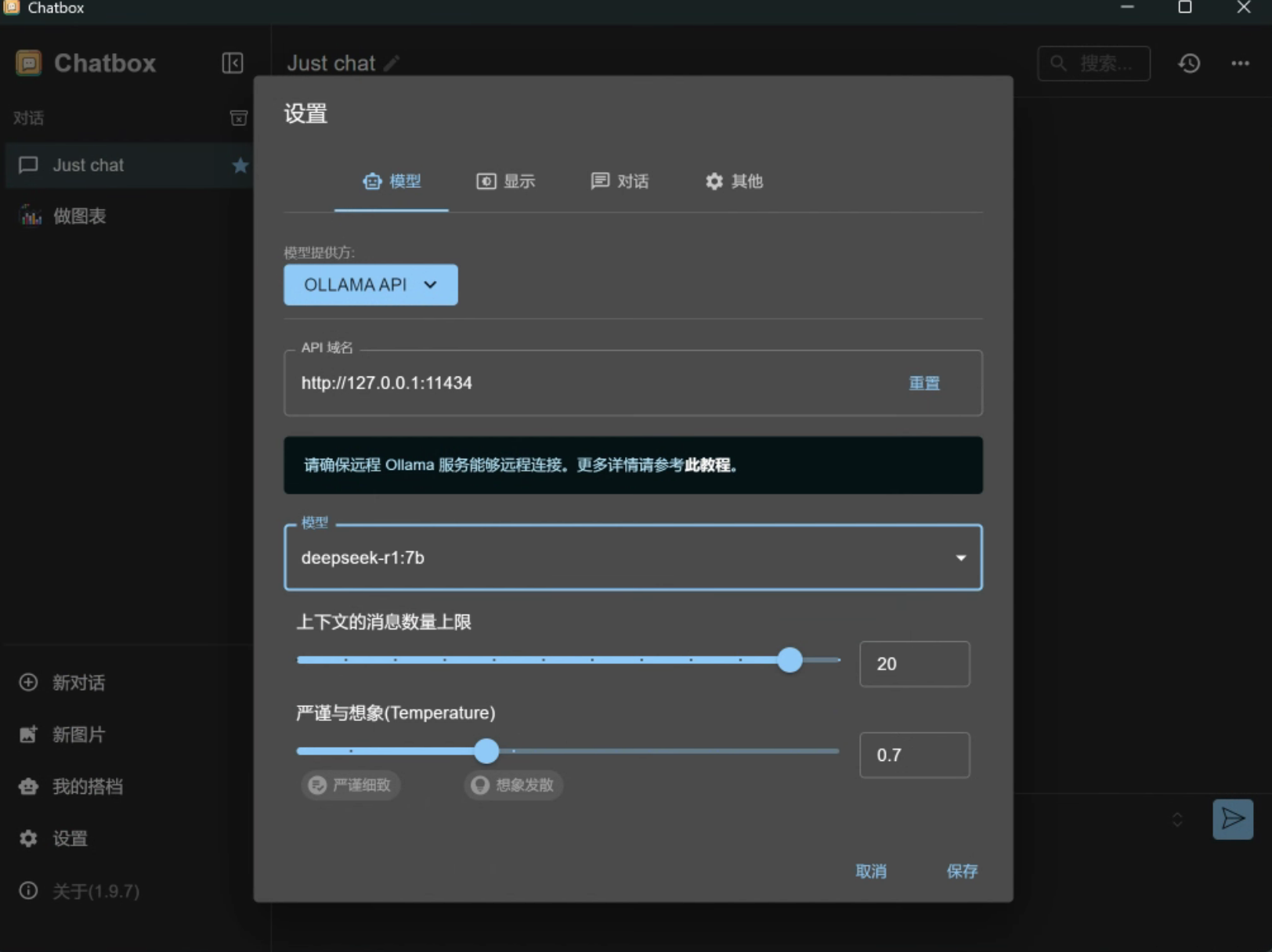
- 打开chatbox,点击设置
- 模型提供方选择
Ollama API - API域名填写
http://127.0.0.1:11434 - 模型选择
deepseek-r1:7b - 点击保存
运行效果:

说明:
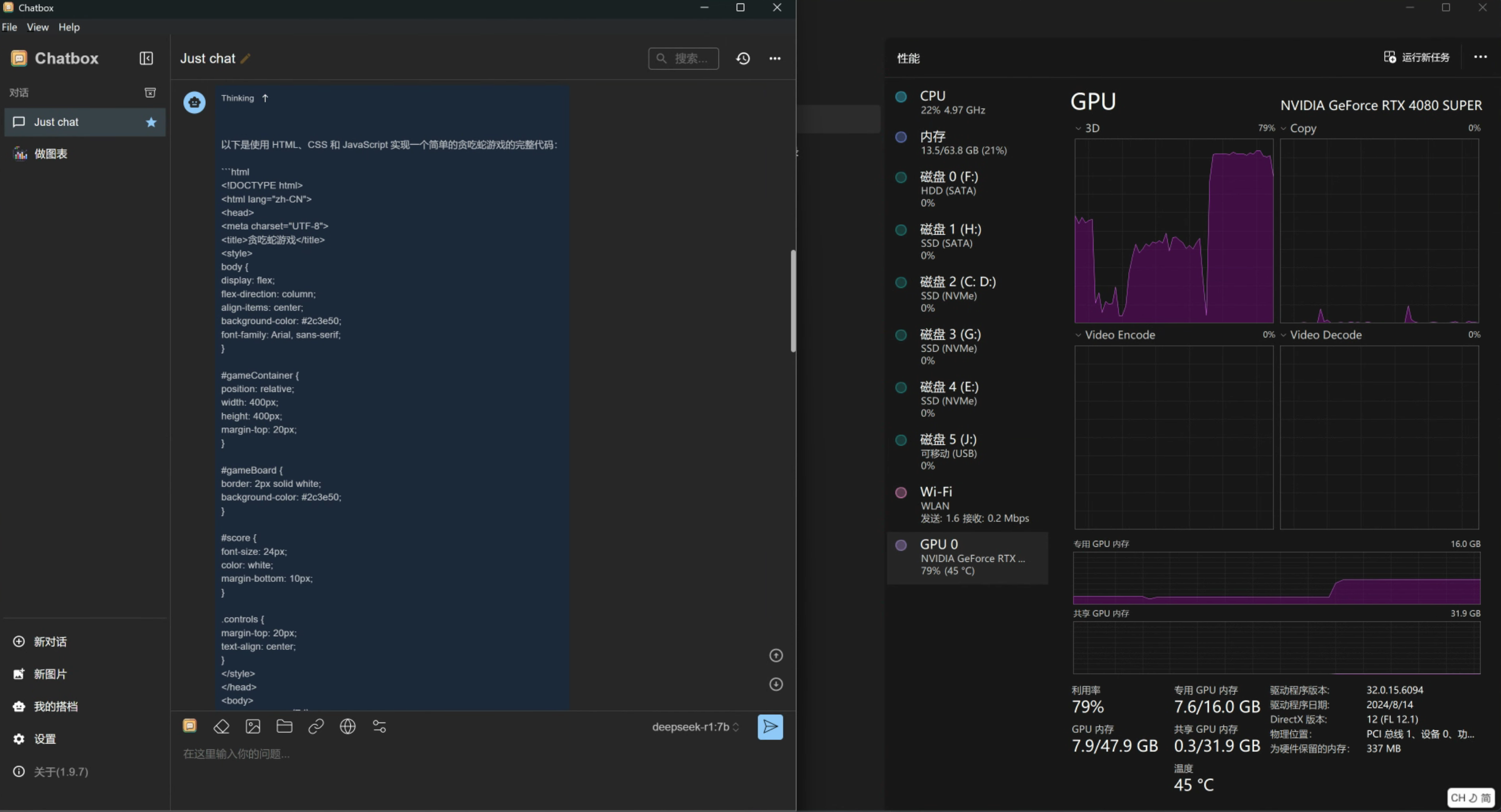
经过实测,笔者4080显卡16G显存,使用ollama本地化部署deepseek-r1:7b 模型, 显存占用从1.5G增加到约7G,内存占用从20G增加到约26G,可以实现流畅的交互体验。如果部署deepseek-r1:14b 模型,显存占用从1.5G增加到约12G,内存占用从20G增加到约30G,可以实现流畅的交互体验。
优缺点对比
| 对比维度 | 方法一:ChatBox+API | 方法二:Cursor+API | 方法三:Ollama本地部署 |
|---|---|---|---|
| 部署难度 | ⭐⭐ (需注册API Key) | ⭐⭐⭐ (需IDE配置) | ⭐⭐⭐⭐ (需硬件环境) |
| 响应速度 | 100-200ms (依赖网络质量) | 300-500ms (试验时较慢) | 50-150ms (本地计算) |
| 隐私性 | 中 (数据经过第三方服务器) | 中 (数据经过第三方服务器) | 高 (完全本地运行) |
| 硬件要求 | 无特殊要求 | 无特殊要求 | 16GB内存+独立显卡 |
| 成本 | ¥4/100 万个 Tokens | $10/月订阅费 | 一次性硬件投入 |
| 适用场景 | 日常办公/简单问答 | 程序开发/技术写作 | 敏感数据处理/定制开发 |
| 模型更新 | 自动更新 | 跟随IDE版本 | 手动更新 |
| 离线可用性 | 否 | 否 | 完全离线 |
备注说明:
¥4/100 万个 Tokens 是硅基流动的API价格,其相当于:
- 让AI写一个5000字的文章,花费约为:1万 Tokens(1个汉字≈2个Token) ÷ 100万 Tokens × 4元 = 0.04元;
- 让AI每天写100个5000字的文章,花费约为:100次 × 1000 Tokens = 10万 Tokens → 10万 ÷100万 ×4元 = 0.4元
内容小结
- DeepSeek大模型在部署方面,支持多种方式,满足从普通用户到开发者的不同需求。
- 对于普通用户,使用chatbox+硅基流动接入云端API使用,可以实现快速接入和使用。
- 对于程序员,使用cursor+硅基流动接入云端API使用,可以实现代码开发和调试辅助。
- 对于有安全隐私需求的用户,使用ollama本地化部署使用,可以实现完全离线使用。



