过去两年,视频生成模型的发展呈现出一个非常明显的趋势:视觉质量在快速逼近真实世界。从最初的模糊片段,到如今可以生成具有复杂场景、多主体交互甚至长时序叙事的视频,模型在纹理、光影和语义一致性方面已经取得了长足进步。一些系统甚至被称为通用世界模型的雏形,试图通过数据驱动的方式重建现实世界的运行规律。
但随着分辨率和时长的提升,一个更深层的问题开始暴露出来:模型在视觉上越来越真实,却在物理上仍然不可信。也就是说,模型擅长生成看起来像真实世界的画面,却并不真正理解现实世界是如何运作的。这种差距在动态场景中尤为明显。当场景涉及接触、受力、流动或能量传递时,模型往往无法维持一致的物理逻辑。
例如,在一些生成视频中,可以观察到物体在移动过程中缺乏连续的动力来源,运动像被“直接插值”出来;两个物体发生交互时,接触关系模糊甚至消失,表现为轻微重叠或延迟响应;再比如布料、烟雾或水流的变化往往只遵循外观模式,而不是环境约束,导致整体行为缺乏稳定性。
这些问题的本质并不是数据不足,而是模型缺少对物理因果关系和空间约束的建模能力。如何让视频生成模型从“视觉拟合”走向“物理一致”,成为当前领域中的关键问题之一。
在这样的背景下,中山大学梁小丹团队提出了《ProPhy: Progressive Physical Alignment for Dynamic World Simulation》,尝试系统性地解决这一问题。
与以往方法不同,这项研究不再依赖单一层面的物理提示,而是通过分层建模和逐步对齐的方式,将物理信息从全局语义逐渐细化到局部空间,使模型能够在不同区域响应不同的物理规律。
更重要的是,研究团队引入视觉语言模型作为中介,将其在空间理解上的优势转化为生成模型的监督信号,从而弥补生成模型在物理定位能力上的不足。这种设计使模型不仅能够判断发生了什么,还能够理解发生在什么位置,并在时间上保持一致的物理行为。
从更宏观的角度来看,这项工作所指向的并不仅仅是视频生成质量的提升,而是一个更深层的转变:生成模型正在从再现视觉现象,逐步迈向对世界运行机制的近似建模。
这一转变对于未来的智能系统具有基础性意义,因为只有当模型能够在动态过程中遵循基本规律时,才有可能被用于更复杂的任务,例如交互式环境构建、真实场景仿真以及决策系统训练。

论文地址:https://arxiv.org/pdf/2512.05564
从「看起来真实」到「物理上正确」
整体来看,研究结果主要围绕一个核心目标展开,也就是让生成的视频不仅看起来真实,而且能够符合物理规律。研究团队并不是用普通的视频生成评测方式,而是专门采用了一个面向物理合理性的评测体系 VideoPhy2。
在这个评测中,输入是一段文本描述,例如“球撞击地面扬起灰尘”,模型需要根据文本生成视频,然后由评测系统判断两个问题:第一,生成的视频是否符合物理常识;第二,视频内容是否符合文本描述。
在这一评测体系中,有三个非常关键的指标。第一个是 PC,也就是 Physical Commonsense,用来衡量视频是否违反基本物理规律,比如重力、流体运动或者碰撞行为。第二个是 SA,也就是 Semantic Adherence,用来判断视频是否正确完成了文本描述中的语义任务,例如是否真的发生了“倒水”这一行为。第三个是 Joint,表示同时满足 PC 和 SA,也就是既符合物理,又符合语义,这是评估模型生成的视频是否符合物理现象的综合指标。
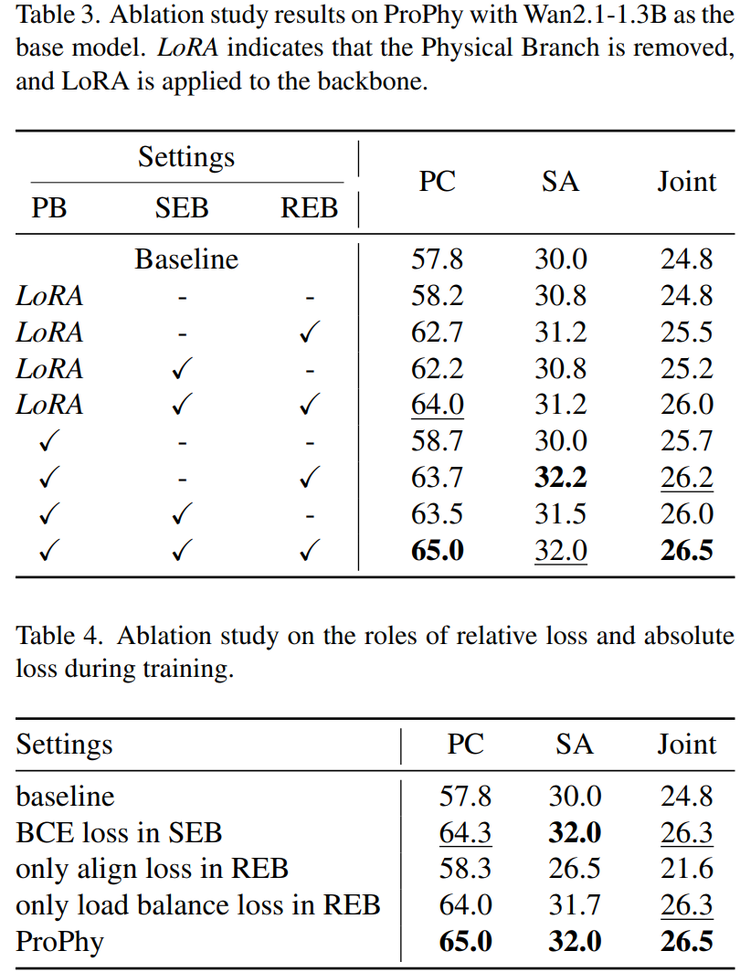
在具体实验结果方面,研究人员首先在 Wan2.1(1.3B)模型上进行了对比。原始模型的 PC 为 57.8,SA 为 30.0,Joint 为 24.8;加入 ProPhy 之后,PC 提升到 65.0,SA 提升到 32.0,Joint 提升到 26.5。可以看到,PC 提升了 7.2,这是最显著的变化,说明模型明显减少了违反物理规律的情况,例如更少出现水向上流动或者物体发生穿透的现象。
相比之下,SA 只提升了 2,这说明 ProPhy 的主要作用并不在于提升对文本的理解能力,而是在于增强物理正确性。Joint 只提升了 1.7,原因在于 Joint 必须同时满足 PC 和 SA,而 SA 本身数值较低,限制了整体提升空间。
在更强的模型 CogVideoX 上,结果同样显著。原始模型的 Joint 约为 22.3,加入 ProPhy 后提升到约 26.7,提升幅度约为 4.4。这个结果不仅超过了 WISA,也超过了 VideoREPA,说明这种方法能够同时提升参数量不同的视频生成模型的物理生成能力。
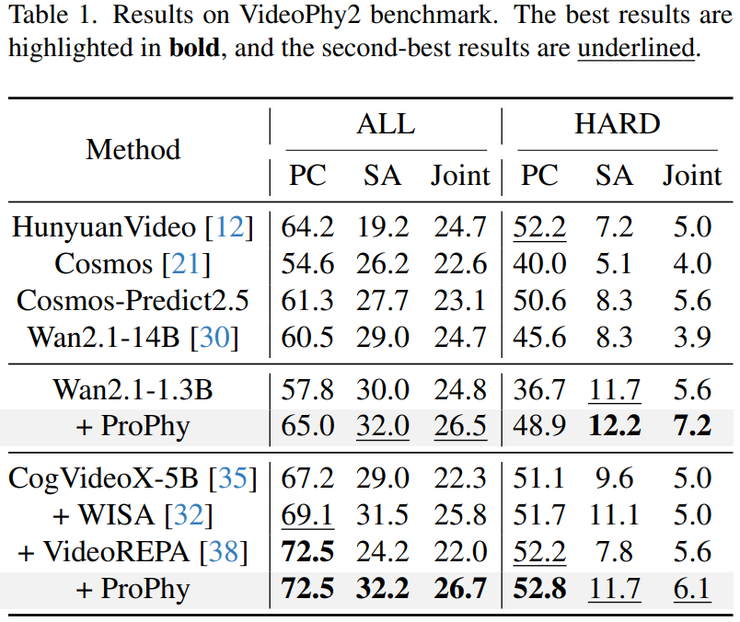
为了进一步验证方法在复杂场景中的表现,研究人员还在 HARD 子集上进行了测试。这一子集包含多物体交互、高速运动以及复杂物理过程等更具挑战性的情况。在 Wan2.1 上,Joint 从 5.6 提升到 7.2;在 CogVideoX 上,Joint 从 5.0 提升到 6.1。虽然这些数值整体较低,但由于任务本身难度极高,这种提升具有重要意义,说明 ProPhy 在真正需要物理推理的场景中更有效。

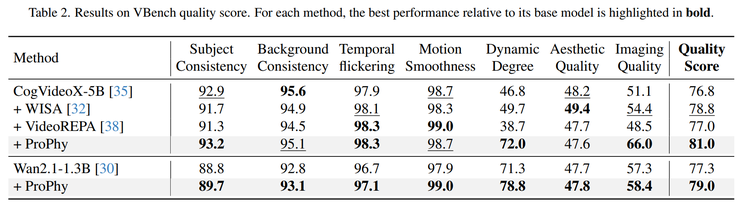
除了物理合理性,研究人员还使用VBench 评测体系评估了生成视频的质量。结果显示,动态程度从 46.8 提升到 72,总体质量评分从 76.8 提升到 81。这一现象说明物理建模在提升视频动态表现的同时,略微提升了视频的质量。深层原因在于,动态如果不符合物理规律,会直接导致视觉不自然,例如水流错误会显得不真实,碰撞错误会让动作显得不连贯。
在定性结果方面,研究通过多个案例展示模型行为的变化。在扬尘场景中,传统模型会在球还未落地时就产生灰尘,而 ProPhy 只有在接触地面之后才产生扬尘,这表明模型学会了“接触导致结果”的因果关系。
在碰撞场景中,传统模型可能出现球体穿透或静止不动,而 ProPhy 能够表现出动量传递,小球在被撞击后开始运动,说明模型隐式地学习到了动量守恒。在流体场景中,传统模型可能生成违反约束的水流,而 ProPhy 的流动表现更加合理。
综合来看,这些结果说明模型不再只是依赖图像模式进行生成,而是开始遵循一定的物理规则,表现出对物理因果关系的理解能力。雷峰网(公众号:雷峰网)
一条从语义到空间的物理建模链路
实验经过可以理解为一个从文本到物理再到视频逐步细化的过程。模型首先接收文本 prompt 作为输入,随后依次经历三个关键步骤:提取物理信息,将这些物理信息注入到视频生成过程中,并在生成过程中逐层进行细化,使物理规律逐渐融入到视频内容中。
在第一阶段,研究团队设计了语义级物理模块 SEB,其核心作用是从文本中提取视频涉及的物理现象,也就是判断“这个视频涉及哪些物理过程”。在内部结构上,这一模块包含 32 个物理专家,每个专家对应一种不同的物理模式,例如燃烧、流体或碰撞等。
SEB 中还存在一个路由器,用于为每个特定领域的隐式物理专家分配权重。通过这种方式,模型可以得到一个加权组合的结果,也就是一个“混合的物理先验”。从本质上看,SEB 可以理解为一个物理分类器与权重分配器的结合体,它负责在全局层面确定视频的物理属性。
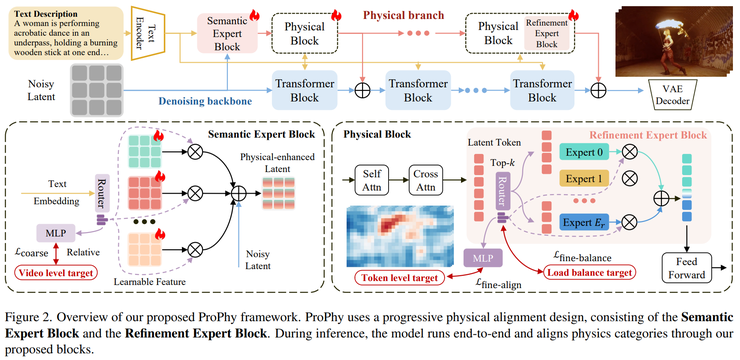
在第二阶段,研究人员引入了细粒度模块 REB,用于进行 token 级别的物理建模。引入这一层的原因在于,同一个视频中往往存在多个不同的物理现象,例如火焰可能出现在画面左侧,而水流可能出现在右侧,因此需要对空间进行区分。REB的具体作用是针对每一个 token 判断其对应的物理现象。
在实现上,与 SEB 不同的是,每个 token 会从中选择 top-k 个专家进行计算,从而得到更精细的物理表达。最终输出的是一个空间上的物理分布图,也就是每个位置对应哪种物理现象。从本质上看,REB可以理解为一个基于VLM的物理分割器,使模型能够在空间上区分不同物理过程。

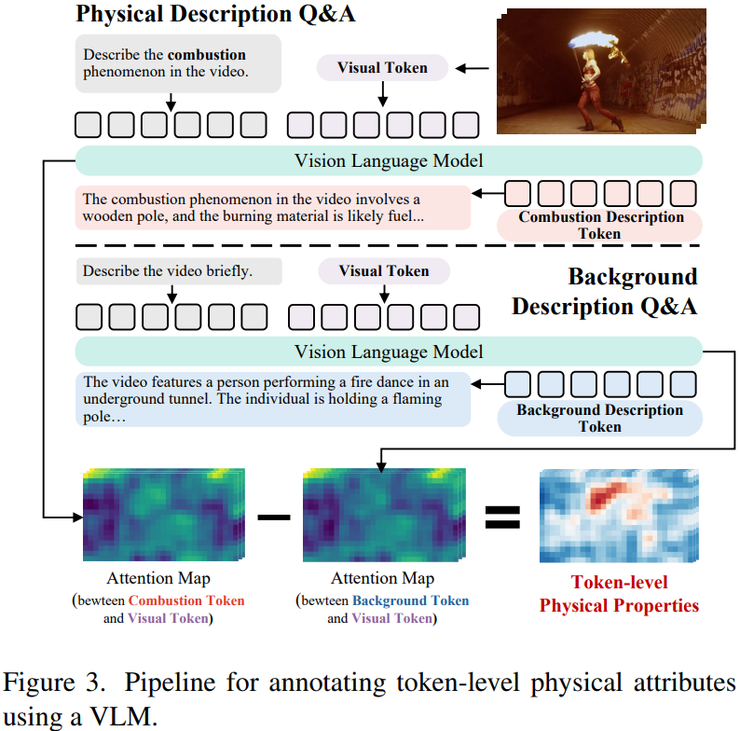
在整个方法中,最关键的一部分是引入了 VLM 监督机制。研究人员发现,视频生成模型在识别“物理现象发生在哪里”这一问题上能力较弱,而视觉语言模型在这一任务上表现更强。因此,研究团队利用 VLM 来为模型提供监督信号。
具体流程分为多个步骤:首先向 VLM 提问“视频中的燃烧在哪里”,然后得到文本 token 以及与之对应的视觉 token;接着通过计算注意力得到燃烧区域;随后再询问“背景是什么”,得到背景区域;最后将两者相减,从而得到纯粹的物理区域。
通过这一过程,可以得到一个矩阵,其中每个 token 对应某种物理现象的概率分布。这个结果被用来训练 REB,使其逐渐学会识别物理现象在空间中的分布位置,也就是学会“物理在哪里”。
在训练过程中,研究团队设计了三个目标函数来约束模型行为。第一个是 Lcoarse,对应语义级对齐,其目标是让属于同一物理类别的样本具有相似表示,而不同类别之间能够被区分开。第二个是 Lfine-align,对应空间级对齐,其目标是让模型在 token 层面的预测尽可能接近 VLM 提供的标注。第三个是 Lfine-balance,其目标是保证所有专家都能被有效使用,避免只有少数专家被频繁激活。三者的权重分别设置为 0.1、0.02 和 0.01,从而在训练中形成平衡。雷峰网
为了验证这些设计的必要性,研究人员进行了消融实验。结果表明,如果去掉 REB,模型将失去空间层面的物理建模能力;如果去掉 SEB,模型的物理分类能力会明显下降;如果去掉对齐机制,模型训练会变得不稳定。综合来看,这三个部分是相互递进的,缺少任何一部分都会导致性能下降。
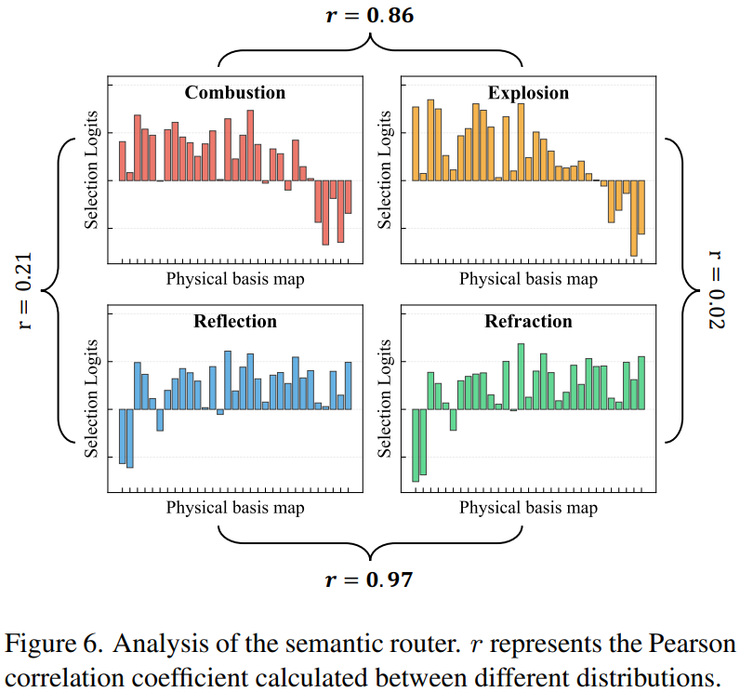
最后,研究团队还分析了不同专家所学习到的物理知识之间的关系。通过计算专家之间的相关性发现,与燃烧相关的专家和爆炸相关的专家之间具有较高相关性,而爆炸与折射之间的相关性较低。
这一现象说明模型不仅学会了单一的物理现象,还捕捉到了不同物理过程之间的结构关系,从而形成了一种更加系统化的物理知识表示。
面向动态世界的一种建模尝试
整体来看,这项研究实验意义不仅体现在方法层面的改进,还反映了视频生成技术发展方向的一次重要转变。
以往的视频生成模型主要依赖数据中出现频率较高的视觉模式进行学习,本质上是在回答画面长什么样,而不是解释为什么会出现这样的变化。这种方式虽然可以生成外观逼真的视频,但缺乏对物理规律和因果关系的理解,因此经常出现看似合理却违背现实规律的现象。
围绕这一问题,研究团队提出了几个关键突破。首先,将物理从隐式的统计规律转变为显式的知识结构,通过引入物理专家,使模型能够区分不同类型的物理过程,例如燃烧、流体和碰撞,从而避免将所有现象混合在一起进行学习。
其次,将物理建模从整体层面推进到空间层面,使模型能够在同一视频中区分不同区域的物理现象,例如某一位置发生燃烧,而另一位置存在流体运动,这种空间区分能力显著提高了生成结果的合理性。
再次,引入视觉语言模型作为教师角色,利用其更强的理解能力为生成模型提供物理定位信息,使模型不仅知道发生了什么,还能够知道发生在什么位置,这种方式形成了一种新的训练思路,也就是用理解能力更强的模型去指导生成模型学习更复杂的结构。
从更深层的角度来看,这项研究推动人工智能从单纯的视觉生成向世界模拟迈进。随着物理建模能力的加入,模型开始具备一定程度的因果理解能力,能够在生成过程中遵循基本约束并体现出规律性。这种能力对于未来技术的发展具有重要意义,例如在机器人训练中,可以通过生成更符合物理规律的环境来提高学习效果,在自动驾驶领域,可以更真实地模拟复杂交通场景,在仿真系统中,可以用于构建更加可靠的虚拟测试环境。
从普通人的角度来看,这项研究的影响也会逐渐显现。在内容创作方面,视频生成工具将不再只是生成好看的画面,而是能够生成更加真实、更加自然的动态内容,减少违和感,从而提升影视制作、短视频创作和游戏开发的效率与质量。
在教育领域,可以利用这种技术生成更直观的物理演示,帮助理解复杂的现象,例如碰撞过程或流体变化。在日常应用中,更真实的虚拟场景也意味着更可靠的数字孪生环境,例如用于训练或模拟现实任务。
与此同时,研究人员也指出了当前方法的局限性。一方面,物理监督依赖视觉语言模型的标注,而这种标注不可避免地存在噪声,可能影响学习效果;另一方面,模型目前主要学习的是物理现象的表层模式,而不是基于严格方程的物理机制,因此仍然属于近似模拟。
基于这些问题,未来的研究方向包括引入更加严格的物理方程以及构建更强的因果建模能力,使模型能够从经验式学习进一步走向更加可靠的物理推理,从而提升对真实世界的理解与模拟水平。
ProPhy 背后的科研工作者
王子俊,中山大学智能工程学院 2025 级博士研究生,本科毕业于中山大学智能工程学院,师从梁小丹教授。他的研究方向是视频生成和世界模型。

胡攀文,现在是穆罕默德·本·扎耶德人工智能大学(MBZUAI)计算机视觉系博士后,主要研究方向为个性化和视频生成,世界模型。分别于 2023 年和 2018 年从香港中文大学(深圳)和中国科学技术大学获得博士和硕士学位。

黎汉汇, 分别于 2012 年和 2018 年获得中山大学计算机科学与技术学士学位和计算机软件与理论博士学位。他目前是中山大学深圳校区的特聘研究员。此前,他于 2019 年至 2021 年在新加坡南洋理工大学担任研究员。他的研究方向包括视觉媒体分析与推理。

梁小丹是中山大学深圳校区的教授,同时也是穆罕默德·本·扎耶德人工智能大学(MBZUAI)计算机视觉系的副教授。她曾是卡内基梅隆大学的项目科学家,与邢教授合作。
她在视觉语言理解与生成及其在具身人工智能中的应用方面发表了 120 余篇前沿论文,这些论文发表于该领域最负盛名的期刊和会议,谷歌引用量超过 30000 次。
她定期担任 ICCV、CVPR、NeurIPS、ICML、ICLR 和 AAAI 等会议的领域主席,并担任 CVPR 2021 的教程主席、 CVPR 2023 的评审主席。她曾荣获ACM中国最佳博士论文奖、CCF 最佳博士论文奖以及阿里巴巴达摩院青年学者奖。她的研究成果已被应用于多家知名人工智能公司(如 Deepseek、联想、字节跳动和腾讯)的关键产品中。

雷峰网原创文章,未经授权禁止转载。详情见转载须知。


