前言
在上一章【课程总结】day20:Transformer源码深入理解-训练过程总结中,我们对Transformer的训练过程进行了详细的分析,本章将介绍Transformer的预测过程。
预测流程
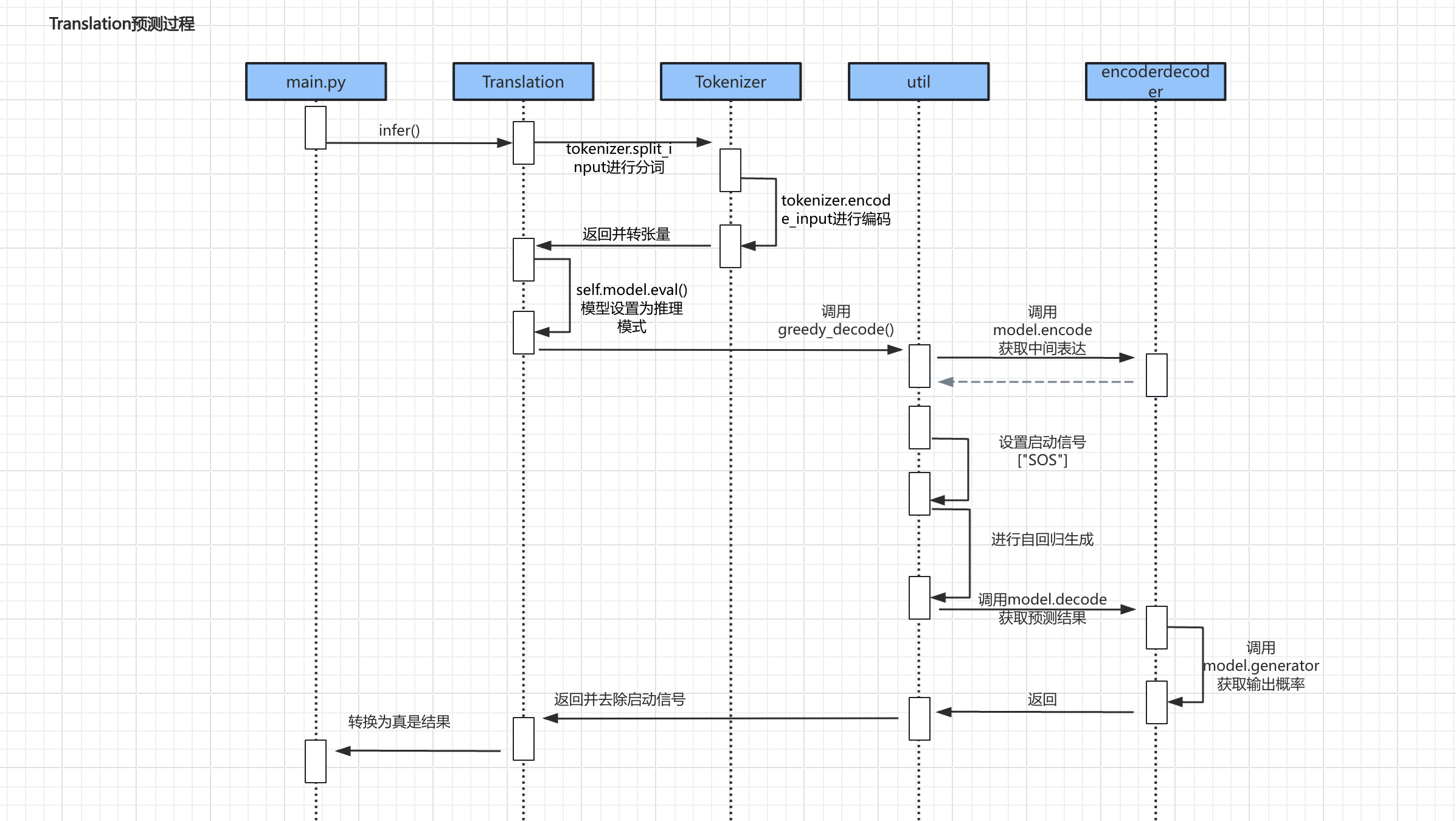
- 预测大致为如下步骤:
- 第一部分:准备数据,通过调用
tokenizer的split_input()进行分词、encoder_input()进行编码,将输入内容最终转为张量。 - 第二部分:调用greed_decoder()进行预测,返回预测结果。
- 第三部分:将预测的结果进行处理,使用
get_real_output()方法将预测的输出进行处理,得到真实输出序列。
代码分析理解
预测过程
def infer(self, sentence="Am I wrong?"):
"""
预测过程
"""
print("原文:", sentence)
sentence = self.tokenizer.split_input(sentence=sentence)
print("分词:", sentence)
sentence = self.tokenizer.encode_input(input_sentence=sentence, input_sentence_len=len(sentence))
print("编码:", sentence)
src = torch.LongTensor([sentence]).to(device=self.device)
print("张量:", src)
# src = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
max_len = src.size(1)
src_mask = torch.ones(1, 1, max_len)
# 模型推理
self.model.eval()
with torch.no_grad():
y_pred = greedy_decode(self.model,
src,
src_mask,
max_len=self.tokenizer.output_max_len,
start_symbol=self.tokenizer.output_word2idx.get("<SOS>"))
# 去除 启动信号 <SOS>
y_pred = y_pred[:, 1:]
raw_results, final_results = get_real_output(y_pred.cpu(), self.tokenizer)
print("原始预测:", raw_results[0])
print("最终预测:", final_results[0])代码理解:
- 在Translation类中,封装infer()函数,该函数用于预测。
- 在预测的时候,设置模型为eval模式,即关闭dropout;
- 在无梯度模式下,调用模型推理函数greed_decode()进行预测。
greedy_decode() 函数
def greedy_decode(model, src, src_mask, max_len, start_symbol):
# 获取中间表达
memory = model.encode(src, src_mask)
# 启动信号
ys = torch.zeros(1, 1).fill_(start_symbol).type_as(src.data)
# 自回归式生成
for _ in range(max_len - 1):
# 获取结果
out = model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
)
# print(out)
# 取出最后一步的结果
prob = model.generator(out[:, -1])
# 获取概率最大的值
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
# 拼接起来,准备生成下一个词
ys = torch.cat(
[ys, torch.zeros(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
return ys假设示例如下:
- 上文输入:Am I wrong?
初始输入:
- 上文输入(源序列):[‘am’, ‘i’, ‘wrong’, ‘?’]
- 下文输入(目标序列):"SOS"
memory的形状:[1, 4, 512]ys的形状:[1, 1],其值为7228对应SOS
第一轮自回归生成
- 上文输入(源序列):[‘am’, ‘i’, ‘wrong’, ‘?’]
- 下文输入(目标序列):["SOS"]
out的形状:[1, 1, 512]prob的形状:[1, 12547]- 得到下一个词是:
4890,对应是"我" 拼接后的ys的形状:[1, 2]
第二轮自回归生成
- 上文输入(源序列):[‘am’, ‘i’, ‘wrong’, ‘?’]
- 下文输入(目标序列):["SOS", "我"]
out的形状:[1, 2, 512]- 得到下一个词是:
1924,对应是"错" 拼接后的ys的形状:[1, 3]
第三轮自回归生成
- 上文输入(源序列):[‘am’, ‘i’, ‘wrong’, ‘?’]
- 下文输入(目标序列):["SOS", "我", "错"]
out的形状:[1, 3, 512]- 得到下一个词是:"了"
拼接后的ys的形状:[1, 4]
第四轮自回归生成
- 上文输入(源序列):[‘am’, ‘i’, ‘wrong’, ‘?’]
- 下文输入(目标序列):["SOS", "我", "错", "了"]
- 得到下一个词是:"吗"
第五轮自回归生成
- 上文输入(源序列):[‘am’, ‘i’, ‘wrong’, ‘?’]
- 下文输入(目标序列):["SOS", "我", "错", "了", "吗"]
- 得到下一个词是:"?"
代码运行
切换至程序目录下
cd transformer_demo安装相关依赖
pip install OpenCC
pip install jieba运行程序
python main.py运行效果:
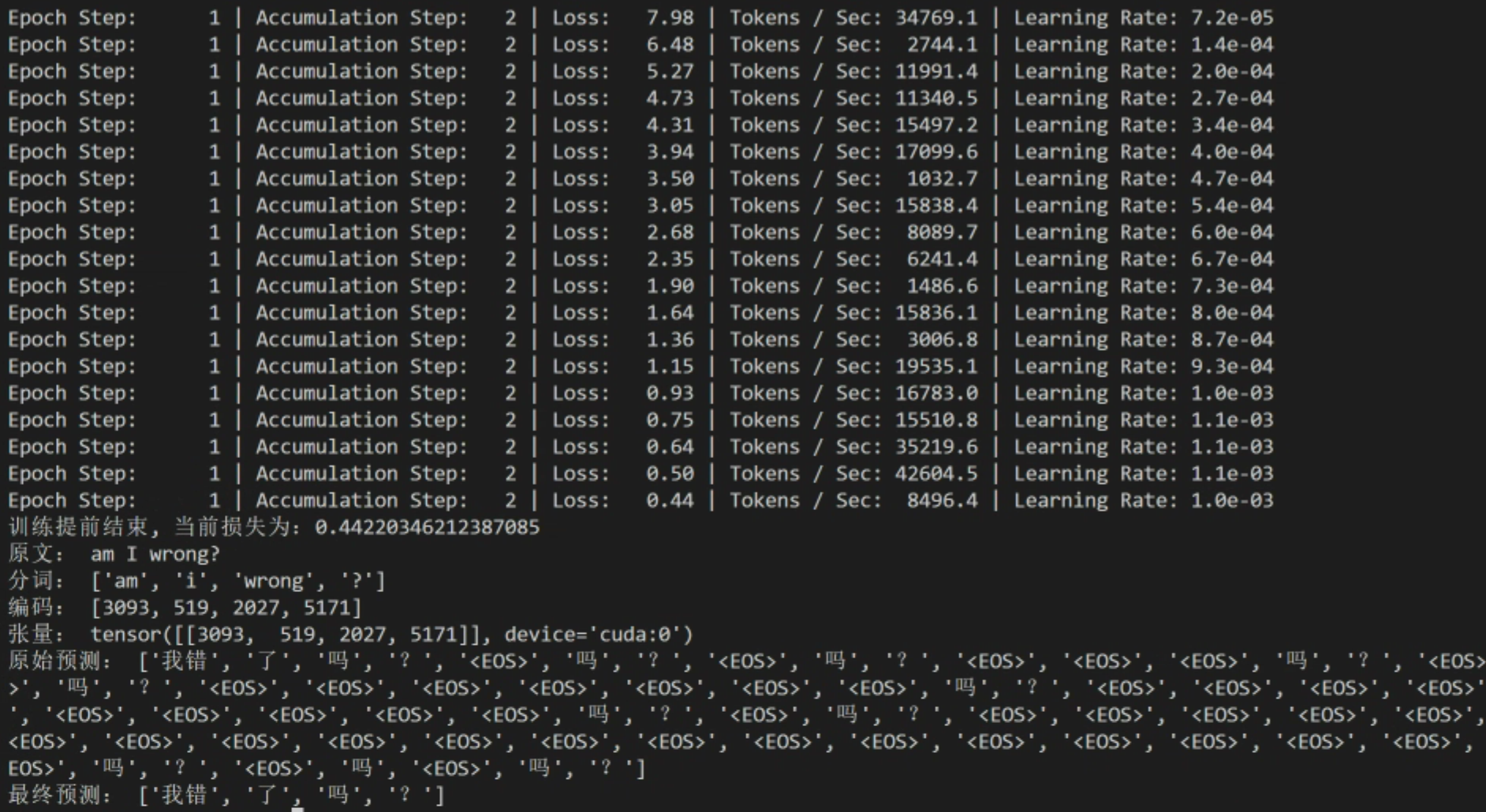
内容小结
- 预测过程注意事项有:
- 首先需要对输入进行分词、编码、转张量处理。
- 其次要将模型设置为eval模式,同时在无梯度模式下,调用模型推理函数greed_decode()进行预测。
- 下文的输入序列在初始化时需要增加启动信号\
,预测完毕后需要将启动信号从结果中去除。 - 在自回归的过程中,每次预测下一个词时,需要将预测结果拼接到输入序列中,作为下一轮的输入。
- 预测完毕后,通过get_real_output()函数,将预测结果进行处理,得到真实输出序列。
参考资料
欢迎关注公众号以获得最新的文章和新闻



