
前言
在上一章【课程总结】day21(下):大模型的三大架构及T5体验中,我们体验了Encoder-Decoder架构的T5模型。本章内容,我们将以Decoder-Only架构的Qwen模型入手,了解Qwen模型结构、聊天模板的概念以及通过大模型进行翻译、信息抽取等任务的尝试。
模型选择
访问ModelScope官网,在模型库搜索Qwen2。
补充说明:
- Qwen2-7B是一个通用的Base模型。
- Qwen2-7B-Instruct是经过监督微调SFT的模型,在处理指令时的表现通常会更好。
关于
底座模型以及SFT训练的内容回顾,可以查看【课程总结】day21(下):大模型的三大架构及T5体验中的大模型训练过程内容。
Qwen模型简介
Qwen2是Qwen大型语言模型的新系列,基于LLaMA架构,由Qwen团队进行训练。
- 参数规模:Qwen2系列模型的参数范围从0.5亿到72亿,Qwen2-7B对应是70亿参数规模。
- 上下文长度:Qwen2-7B-Instruct支持最长达131,072个标记的上下文长度,能够处理大量输入。
- 应用场景:Qwen2模型可应用于多种自然语言处理任务,包括语言理解、语言生成、多语言能力、编码、数学推理等。
- 开源情况:Qwen2模型是开源的,Github地址:https://github.com/QwenLM/Qwen2
- 技术博客:https://qwenlm.github.io/blog/qwen2/
- 技术文档:https://qwen.readthedocs.io/en/latest/
模型下载
第一步:启动ModelScope平台的PAI-DSW的GPU环境
第二步:在终端中,输入以下命令进行模型下载:
git clone https://www.modelscope.cn/qwen/qwen2-7b-instruct.gitQwen2模型目录简介
qwen2-7b-instruct/
│
├── .gitattributes # Git属性文件,用于配置Git的行为。
│
├── config.json # 模型配置文件,包含模型的基本参数和设置。
│
├── configuration.json # 系统初始化配置文件,定义系统启动时的配置。
│
├── generation_config.json # 生成配置文件,包含文本生成时的参数设置。
│
├── LICENSE # 许可证文件,说明模型的使用条款和条件。
│
├── merges.txt # 词汇合并文件,通常用于处理子词分割。
│
├── model-00001-of-00004.safetensors # 模型权重文件(第1部分),使用Safetensors格式存储。
├── model-00002-of-00004.safetensors # 模型权重文件(第2部分),使用Safetensors格式存储。
├── model-00003-of-00004.safetensors # 模型权重文件(第3部分),使用Safetensors格式存储。
├── model-00004-of-00004.safetensors # 模型权重文件(第4部分),使用Safetensors格式存储。
│
├── model.safetensors.index.json # 模型索引文件,包含模型权重的索引信息。
│
├── README.md # 项目说明文件,提供模型的使用说明和相关信息。
│
├── tokenizer.json # 分词器配置文件,定义分词器的参数和设置。
│
├── tokenizer_config.json # 分词器初始化配置文件,包含分词器的启动配置。
│
└── vocab.json # 词汇表文件,列出模型可识别的所有词汇。
模型使用
第一步:创建Jupyter Notebook文件
在与qwen2-7b-instruct同一目录下,新建Jupyter Notebook文件,命名为qwen2测试.ipynb
workspace/
├── qwen2-7b-instruct/
├── qwen2测试.ipynb
第二步:运行测试代码
在qwen2测试.ipynb中,输入以下代码:
# 导入依赖组件
from modelscope import AutoModelForCausalLM
from modelscope import AutoTokenizer
# 判断设备
device = "cuda" # the device to load the model onto
# 模型ID,对应git clone的模型文件夹名称
model_id = "qwen2-7b-instruct"
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto"
)
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 准备提示词
messages = [
{"role": "system", "content": """
You are a helpful assistant.
"""},
{"role": "user", "content": """
中华人民共和国的首都是哪里?
"""}
]
# 应用聊天模板
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 输入内容转ID
model_inputs = tokenizer([text], return_tensors="pt").to(device)
# 模型预测
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
# 删除问句信息
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 翻译答案
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 输出结果
print(response)
运行结果:

代码理解
导入依赖及初始化部分
# 导入依赖组件
from modelscope import AutoModelForCausalLM
from modelscope import AutoTokenizer
# 判断设备
device = "cuda" # the device to load the model onto
# 模型ID,对应git clone的模型文件夹名称
model_id = "qwen2-7b-instruct"
上述的model_id对应本地下载的模型文件夹名称,特别注意文件名及大小写保持一致。
模型结构
在Jupyter Notebook中打印model的模型结构,得到如下内容:
Qwen2ForCausalLM(
(model): Qwen2Model(
(embed_tokens): Embedding(152064, 3584)
(layers): ModuleList(
(0-27): 28 x Qwen2DecoderLayer(
(self_attn): Qwen2SdpaAttention(
(q_proj): Linear(in_features=3584, out_features=3584, bias=True)
(k_proj): Linear(in_features=3584, out_features=512, bias=True)
(v_proj): Linear(in_features=3584, out_features=512, bias=True)
(o_proj): Linear(in_features=3584, out_features=3584, bias=False)
(rotary_emb): Qwen2RotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=3584, out_features=18944, bias=False)
(up_proj): Linear(in_features=3584, out_features=18944, bias=False)
(down_proj): Linear(in_features=18944, out_features=3584, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm()
(post_attention_layernorm): Qwen2RMSNorm()
)
)
(norm): Qwen2RMSNorm()
)
(lm_head): Linear(in_features=3584, out_features=152064, bias=False)
)- Qwen2ForCausalLM 是一个Decoder-Only结构模型。
embed_tokens对应输出层的上文处理外挂部分。layers对应Decoder部分,由28个Qwen2DecoderLayer构成。self_attn对应mask自注意力机制部分。由于Decoder-Only结构,所以该模型没有融合注意力机制部分。mlp:多层感知机结构
lm_head:对应全链接输出层,负责将模型的输出映射到词汇表的维度。
分词器tokenizer
在Jupyter Notebook中打印model的模型结构,得到如下内容:
Qwen2TokenizerFast(name_or_path='qwen2-7b-instruct', vocab_size=151643,
model_max_length=131072, is_fast=True, padding_side='right',
truncation_side='right',
special_tokens={
'eos_token': '<|im_end|>',
'pad_token': '<|endoftext|>',
'additional_special_tokens': ['<|im_start|>', '<|im_end|>']},
clean_up_tokenization_spaces=False),
added_tokens_decoder={
151643: AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151644: AddedToken("<|im_start|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151645: AddedToken("<|im_end|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}vocab_size:词汇表包含151,643个词汇。model_max_length:支持的最大输入长度为131,072个token。- 特殊标记有:
<|im_start|>: 表示开始一个对话。<|im_end|>: 表示结束一个对话。|endoftext|: 表示文本结束。
查看参数量
total_params = sum(p.numel() for p in model.parameters())
print(f"模型参数总量: {total_params}")
# 运行结果:
# 模型参数总量: 7615616512使用上述测试可以查看模型的参数量,对应为76亿。
message
messages = [
{"role": "system", "content": """
You are a helpful assistant.
"""},
{"role": "user", "content": """
中华人民共和国的首都是哪里?
"""}
]messages是一个包含对话信息的列表。- 每个消息都有一个
role字段,表示消息的发送者角色。常见的角色有:"system":系统角色,用于设置助手的行为或提供上下文信息。"user":用户角色,表示提问或请求的内容。
- 每个消息都有一个
content字段,包含具体的文本内容。这个字段存储了角色所传达的信息。
聊天模板
在Jupyter Notebook中打印text,得到如下内容:
'<|im_start|>system\n\n
You are a helpful assistant.\n
<|im_end|>\n<|im_start|>user\n\n
中华人民共和国的首都是哪里?\n
<|im_end|>\n<|im_start|>assistant\n'- 以上内容即传入给模型的上文内容,然后由大模型进行自回归式补全,其原理与【课程总结】day21(上):Transformer源码深入理解之预测过程类似
模型输出
在Jupyter Notebook中,使用以下测试代码,可以看到模型输出的原始内容。
# 模型预测
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
# 删除问句信息
# generated_ids = [
# output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
# ]
# 翻译答案
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=False)[0]
# 输出结果
print(response)输出结果:
<|im_start|>system
You are a helpful assistant.
<|im_end|>
<|im_start|>user
中华人民共和国的首都是哪里?
<|im_end|>
<|im_start|>assistant
中华人民共和国的首都是北京。<|im_end|>- 将
skip_special_tokens设置为False,可以输出完整的对话内容。如果改为True,则输出内容会去掉im_start等特殊字符。
streamlit调用模型
为了便于修改message的内容,接下来我们通过streamlit搭建一个简易的调用Qwen2的页面,来测试模型的不同任务胜任能力。
安装streamlit
pip install streamlit下载模型
实测Qwen2-7B模型在魔搭社区GPU环境上运行会因为显存不足,导致无法有效运行,所以这里我们选择使用Qwen2-0.5B-Instruction模型。
git clone https://www.modelscope.cn/qwen/Qwen2-0.5B-Instruct.git创建代码
创建app.py文件,代码内容如下:
import streamlit as st
from modelscope import AutoModelForCausalLM, AutoTokenizer
import torch
# 判断设备
device = "cuda" if torch.cuda.is_available() else "cpu"
# 模型ID
model_id = "Qwen2-0.5B-Instruct"
# 加载模型
model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Streamlit 页面标题
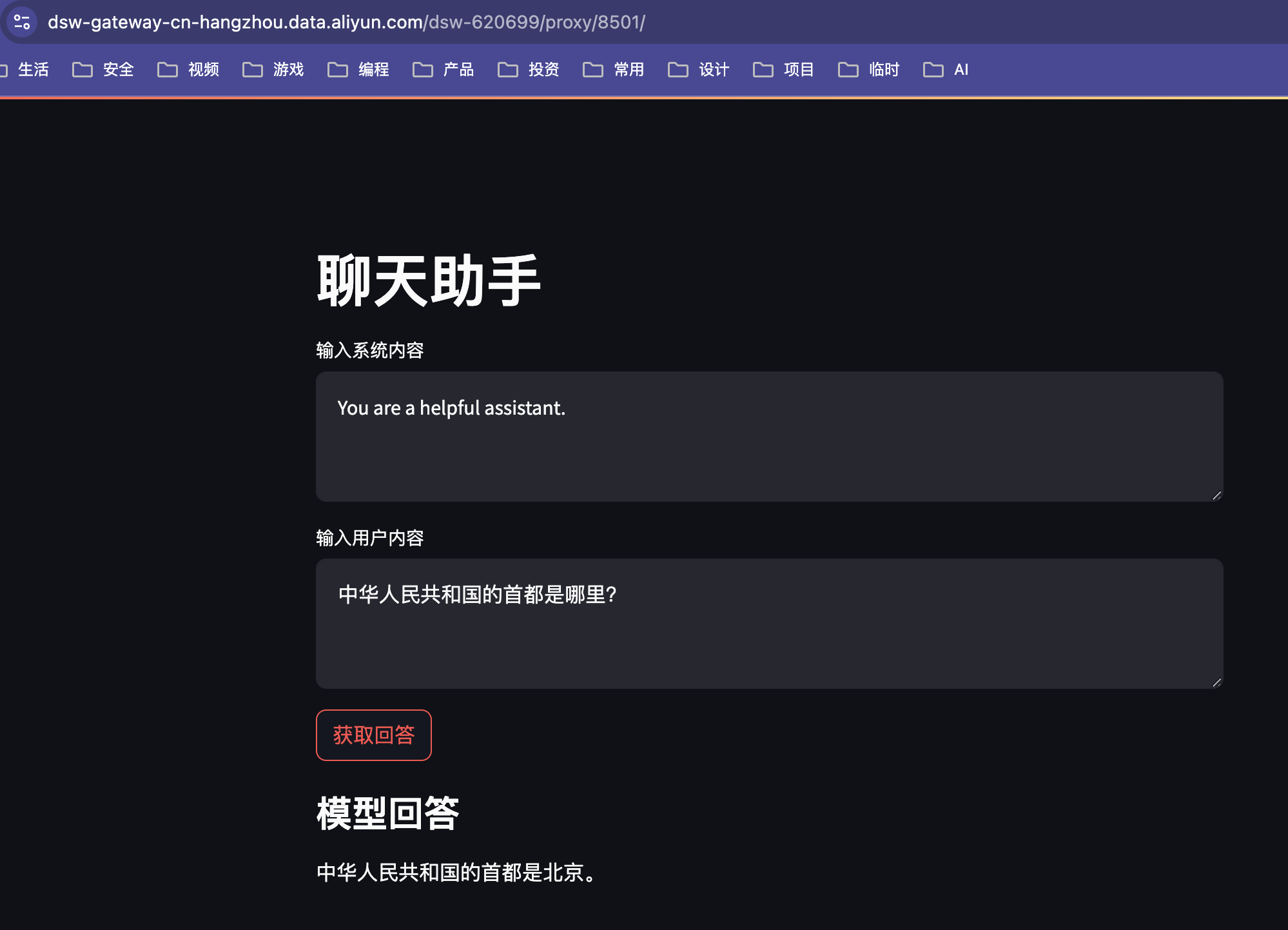
st.title("聊天助手")
# 输入系统内容
system_content = st.text_area("输入系统内容", "You are a helpful assistant.")
# 输入用户内容
user_content = st.text_area("输入用户内容", "中华人民共和国的首都是哪里?")
# 提交按钮
if st.button("获取回答"):
# 准备提示词
messages = [
{"role": "system", "content": system_content},
{"role": "user", "content": user_content}
]
# 应用聊天模板
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 输入内容转ID
model_inputs = tokenizer([text], return_tensors="pt").to(device)
# 模型预测
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
# 删除问句信息
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 翻译答案
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 输出结果
st.subheader("模型回答")
st.write(response)
运行代码
在终端中运行以下命令
streamlit run app.py启动后点击Local URL: http://localhost:8501 得到如下效果:
特别说明:
在使用streamlit启动页面前,请在终端命令行中使用nvidia-smi查看显存的释放情况;如果显存未释放,建议在Jupyter Notebook中Shutdown Kernel以便释放显存。
大模型能力
大模型有着非常强的能力,通过修改system和user中的内容,可以胜任不同的任务。
翻译任务
在streamlit页面中编辑框中输入对应内容:
-
系统内容:
你是一个翻译助手,请将输入的文本翻译成英文。 -
用户内容:
中国队在巴黎奥运会中取得了11金7银6铜的成绩,位列奖牌榜首位。
运行结果:

情感识别任务
- 系统内容:
你是一个情感识别机器人,请将用户的输入做情感分类。 如果是正面的情感,请输出:正面 如果是负面的情感,请输出:负面 如果是中性的情感,请输出:中性 - 用户内容:
送餐快,态度也特别好,辛苦啦谢谢
运行结果:

说明:
- 外卖评价数据集可以查看往期的文章总结获得:【课程总结】Day6(上):机器学习项目实战–外卖点评情感分析预测
- 大模型的能力确实很强,分类效果远远好于之前的机器学习模型。
信息提取任务
- 系统内容:
你是一个信息抽取机器人,请从用户的投诉中抽取核心信息,输出格式请参考: { 'name' : '投诉人的姓名', ‘phone’ : '投诉人的电话号码', 'reason' : '投诉原因', 'appeal' : '投诉人期望的解决办法', }, 请注意:务必严格按照用户输入来抽取信息,切记随意捏造答案!如果没有相关的信息,请直接把该字段赋值为"不知道"。 - 用户内容:
我是楼下的小李子,家里快递丢了3天了,给你们打电话也打不通!赶紧处理!否则,我要给拨打市长热线了。运行结果:

阅读理解任务
-
系统内容:
你是一个阅读理解机器人,请认真阅读用户的输入内容,严格根据文章的内容来回答用户的问题。 注意:如果文章中没有出现相关问题的答案,请直接回答"不知道"。 -
用户内容:
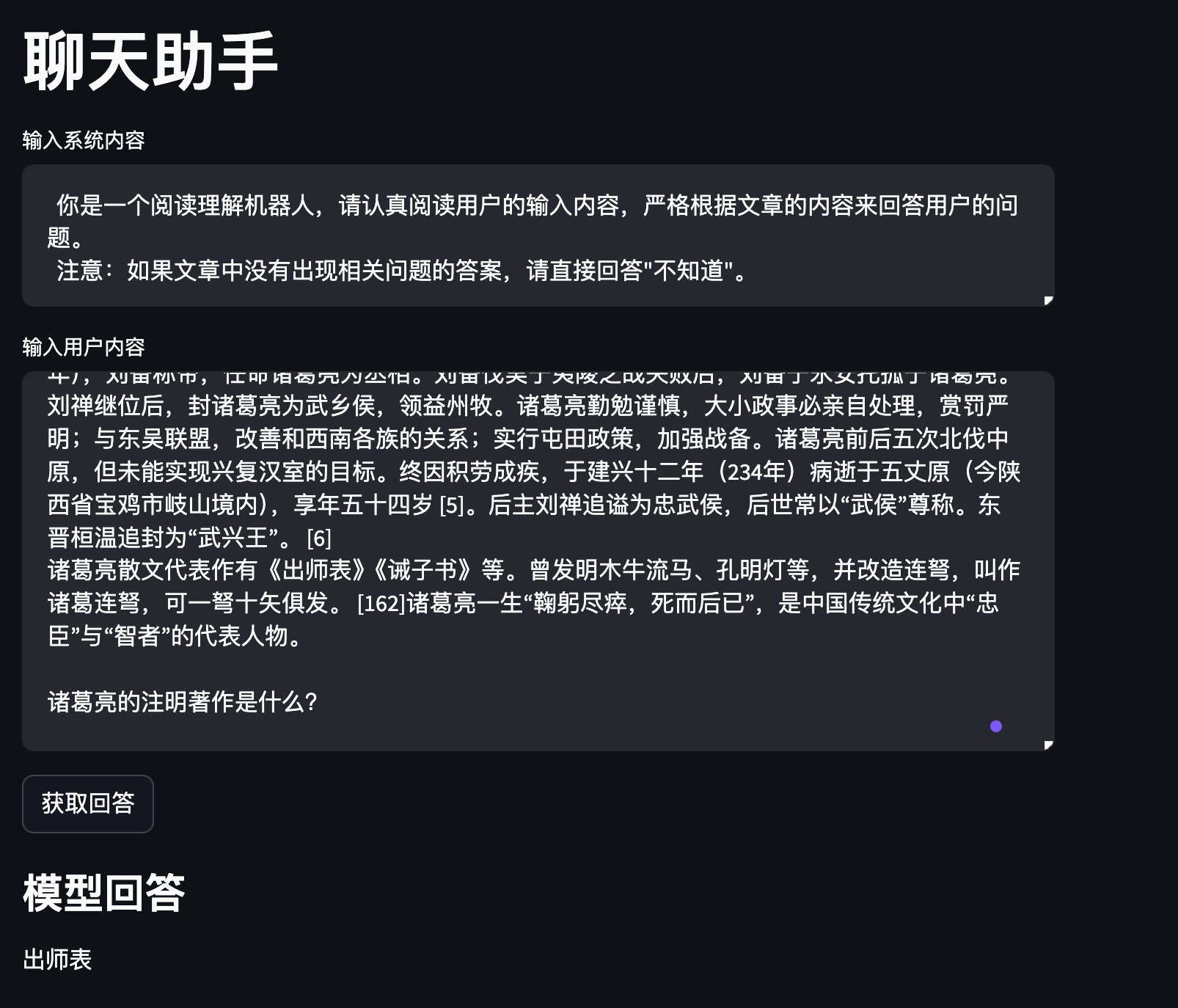
诸葛亮(181年—234年10月8日),字孔明,号卧龙,琅琊阳都(今山东省沂南县)人 [126],三国时期蜀汉丞相,中国古代杰出的政治家、军事家、战略家 [256]、发明家、文学家。 [164] 诸葛亮早年随叔父诸葛玄到荆州,诸葛玄死后,诸葛亮躬耕于南阳。 [1-4]刘备依附荆州刘表时三顾茅庐,诸葛亮向刘备提出占据荆州、益州,联合孙权共同对抗曹操的《隆中对》,刘备根据诸葛亮的策略,成功占领荆州、益州之地,与孙权、曹操形成三足鼎立之势。章武元年(221年),刘备称帝,任命诸葛亮为丞相。刘备伐吴于夷陵之战失败后,刘备于永安托孤于诸葛亮。刘禅继位后,封诸葛亮为武乡侯,领益州牧。诸葛亮勤勉谨慎,大小政事必亲自处理,赏罚严明;与东吴联盟,改善和西南各族的关系;实行屯田政策,加强战备。诸葛亮前后五次北伐中原,但未能实现兴复汉室的目标。终因积劳成疾,于建兴十二年(234年)病逝于五丈原(今陕西省宝鸡市岐山境内),享年五十四岁 [5]。后主刘禅追谥为忠武侯,后世常以“武侯”尊称。东晋桓温追封为“武兴王”。 [6] 诸葛亮散文代表作有《出师表》《诫子书》等。曾发明木牛流马、孔明灯等,并改造连弩,叫作诸葛连弩,可一弩十矢俱发。 [162]诸葛亮一生“鞠躬尽瘁,死而后已”,是中国传统文化中“忠臣”与“智者”的代表人物。 诸葛亮的注明著作是什么?
运行结果:
文本摘要任务
- 系统内容:
你是一个文本摘要机器人,请将用户输入的文章输出摘要,要求100字以内。 - 用户内容:
鲁迅(1881年9月25日—1936年10月19日),原名周樟寿,后改名周树人,字豫山,后改字豫才,浙江绍兴人。中国著名文学家、思想家、革命家、教育家、美术家、书法家、民主战士,新文化运动的重要参与者,中国现代文学的奠基人之一。 [181-185] 他早年与厉绥之和钱均夫同赴日本公费留学,于日本仙台医科专门学校肄业。 [172] [180]“鲁迅”,是他在1918年发表《狂人日记》时所用的笔名,也是最为广泛的笔名。 [1-6] 鲁迅一生在文学创作、文学批评、思想研究、文学史研究、翻译、美术理论引进、基础科学介绍和古籍校勘与研究等多个领域具有重大贡献。他对于五四运动以后的中国社会思想文化发展具有重大影响,蜚声世界文坛,尤其在韩国、日本思想文化领域有极其重要的地位和影响,被誉为“二十世纪东亚文化地图上占最大领土的作家”。运行结果:

回想2019年在搜狗时,参加了一年一度的《黑客马拉松大赛》,其中我们小组的主题就是进行文本摘要提取。当时只是使用word2vec词向量提取后进行机器学习,虽然创意较好,但是效果并不理想。如今对比大模型的效果,真是感慨技术进步之快。
少样本学习推理任务
- 系统内容:
请学习下面用户给定的样本,据此做出相关的推理: {'input':'北京', 'output':'北京烤鸭'} {'input':'山西', 'output':'肉夹馍'} - 用户内容:
兰州运行结果:

内容小结
- Qwen系列模型是Decoder-Only模型,其中Qwen2-7B-Instruct是经过监督微调SFT的模型,参数支持70亿。
- Qwen模型可以支持多种任务,如:翻译任务、信息提取、情感识别、文本摘要、少样本学习推理任务等。
参考资料
暂无
欢迎关注公众号以获得最新的文章和新闻



