文章来源于互联网:超越CVPR 2024方法,DynRefer在区域级多模态识别任务上,多项SOTA
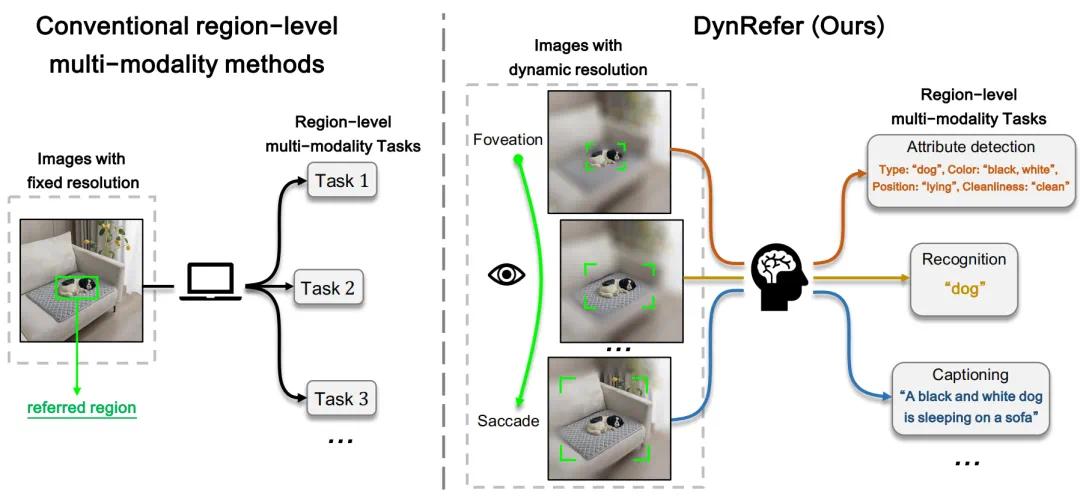
为了实现高精度的区域级多模态理解,本文提出了一种动态分辨率方案来模拟人类视觉认知系统。
本文作者来自于中国科学院大学LAMP实验室,其中第一作者赵毓钟是中国科学院大学的2023级博士生,共同一作刘峰是中国科学院大学2020级直博生。他们的主要研究方向是视觉语言模型和视觉目标感知。

-
论文标题:DynRefer: Delving into Region-level Multi-modality Tasks via Dynamic Resolution -
论文链接:https://arxiv.org/abs/2405.16071 -
论文代码:https://github.com/callsys/DynRefer
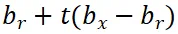 ,其中
,其中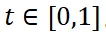 。这里的
。这里的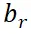 表示参考区域的边界框,
表示参考区域的边界框,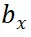 表示整个图像的尺寸,t 表示插值系数。在训练过程中,我们从候选视图中随机选择 n 个视图,以模拟由于注视和眼球快速运动而生成的图像。这些 n 个视图对应于插值系数 t,即
表示整个图像的尺寸,t 表示插值系数。在训练过程中,我们从候选视图中随机选择 n 个视图,以模拟由于注视和眼球快速运动而生成的图像。这些 n 个视图对应于插值系数 t,即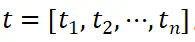 。我们固定保留仅包含参考区域的视图(即
。我们固定保留仅包含参考区域的视图(即 )。经实验证明该视图有助于保留区域细节,对于所有区域多模态任务都至关重要。
)。经实验证明该视图有助于保留区域细节,对于所有区域多模态任务都至关重要。
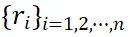 。如图 3 左侧所示。由于裁剪、调整大小和 RoI-Align 引入的空间误差,这些区域嵌入在空间上并不对齐。受 deformable convolution 操作启发,我们提出了一个对齐模块,通过将
。如图 3 左侧所示。由于裁剪、调整大小和 RoI-Align 引入的空间误差,这些区域嵌入在空间上并不对齐。受 deformable convolution 操作启发,我们提出了一个对齐模块,通过将  对齐到
对齐到 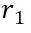 来减少偏差,其中
来减少偏差,其中 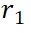 是仅包含参考区域的视图编码的区域嵌入。对于每个区域嵌入
是仅包含参考区域的视图编码的区域嵌入。对于每个区域嵌入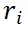 ,首先将其与
,首先将其与  连接,然后通过卷积层计算一个二维偏移图。
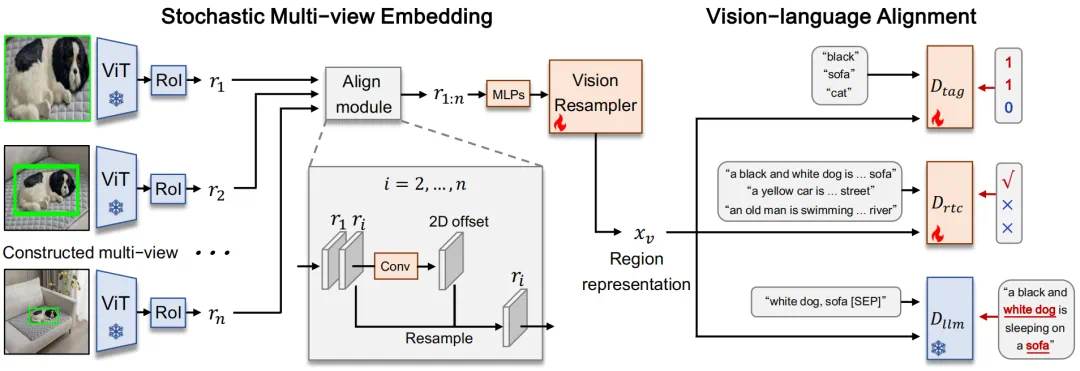
连接,然后通过卷积层计算一个二维偏移图。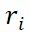 的空间特征然后根据二维偏移重新采样。最后,对齐后的区域嵌入沿通道维度连接并通过 linear 层进行融合。输出进一步通过视觉重采样模块,即 Q-former,进行压缩,从而提取原始图像 x 的参考区域
的空间特征然后根据二维偏移重新采样。最后,对齐后的区域嵌入沿通道维度连接并通过 linear 层进行融合。输出进一步通过视觉重采样模块,即 Q-former,进行压缩,从而提取原始图像 x 的参考区域 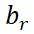 的区域表示(图 3 中的
的区域表示(图 3 中的 )。
)。
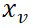 ,由三个解码器
,由三个解码器 解码,如图 3(右)所示,分别受三个多模态任务的监督:
解码,如图 3(右)所示,分别受三个多模态任务的监督: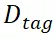 如图 3(右侧)所示。通过使用标签作为查询,
如图 3(右侧)所示。通过使用标签作为查询,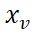 作为键和值,计算预定义标记的置信度来完成标记过程。我们从真值字幕中解析出标签,以监督识别解码器。ii) 区域 – 文本对比学习。类似于区域标记解码器,解码器
作为键和值,计算预定义标记的置信度来完成标记过程。我们从真值字幕中解析出标签,以监督识别解码器。ii) 区域 – 文本对比学习。类似于区域标记解码器,解码器  定义为基于查询的识别解码器。该解码器计算字幕与区域特征之间的相似性分数,使用 SigLIP loss 进行监督。iii) 语言建模。我们采用预训练的大语言模型
定义为基于查询的识别解码器。该解码器计算字幕与区域特征之间的相似性分数,使用 SigLIP loss 进行监督。iii) 语言建模。我们采用预训练的大语言模型  将区域表示
将区域表示  转换为语言描述。
转换为语言描述。
 。视图一是固定的(
。视图一是固定的(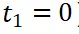 ),视图二随机选择或固定。
),视图二随机选择或固定。 ,我们可以得到具有动态分辨率特性的区域表示。为了评估不同动态分辨率下的特性,我们训练了一个双视图(n=2)的 DynRefer 模型,并在四个多模态任务上进行评估。从图 4 中的曲线可以看出,对于没有上下文信息的视图(
,我们可以得到具有动态分辨率特性的区域表示。为了评估不同动态分辨率下的特性,我们训练了一个双视图(n=2)的 DynRefer 模型,并在四个多模态任务上进行评估。从图 4 中的曲线可以看出,对于没有上下文信息的视图(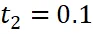 ),属性检测(Attribute detection)获得了更好的结果。这可以解释为这种任务通常需要详细的区域信息。而对于区域级字幕(Region-level captioning)和密集字幕生成(Dense captioning)任务,需要上下文丰富的视图(
),属性检测(Attribute detection)获得了更好的结果。这可以解释为这种任务通常需要详细的区域信息。而对于区域级字幕(Region-level captioning)和密集字幕生成(Dense captioning)任务,需要上下文丰富的视图( 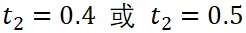 ),以便完整理解参考区域。需要注意的是,过多上下文的视图(
),以便完整理解参考区域。需要注意的是,过多上下文的视图( )会降低所有任务的性能,因为它们引入了过多与区域无关的信息。当已知任务类型时,我们可以根据任务特性采样适当的视图。当任务类型未知时,我们首先构建一组在不同插值系数 t 下的候选视图集合,
)会降低所有任务的性能,因为它们引入了过多与区域无关的信息。当已知任务类型时,我们可以根据任务特性采样适当的视图。当任务类型未知时,我们首先构建一组在不同插值系数 t 下的候选视图集合,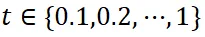 。从候选集中,通过贪婪搜索算法采样 n 个视图。搜索的目标函数定义为:
。从候选集中,通过贪婪搜索算法采样 n 个视图。搜索的目标函数定义为: 其中
其中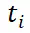 表示第 i 个视图的插值系数,
表示第 i 个视图的插值系数,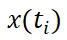 表示第 i 个视图,pHASH (・) 表示感知图像哈希函数,
表示第 i 个视图,pHASH (・) 表示感知图像哈希函数,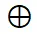 表示异或操作。为了从全局视角比较视图的信息,我们利用 “pHASH (・)” 函数将视图从空间域转换到频域,然后编码成哈希码。对于
表示异或操作。为了从全局视角比较视图的信息,我们利用 “pHASH (・)” 函数将视图从空间域转换到频域,然后编码成哈希码。对于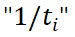 这一项,我们减少上下文丰富视图的权重,以避免引入过多冗余信息。
这一项,我们减少上下文丰富视图的权重,以避免引入过多冗余信息。
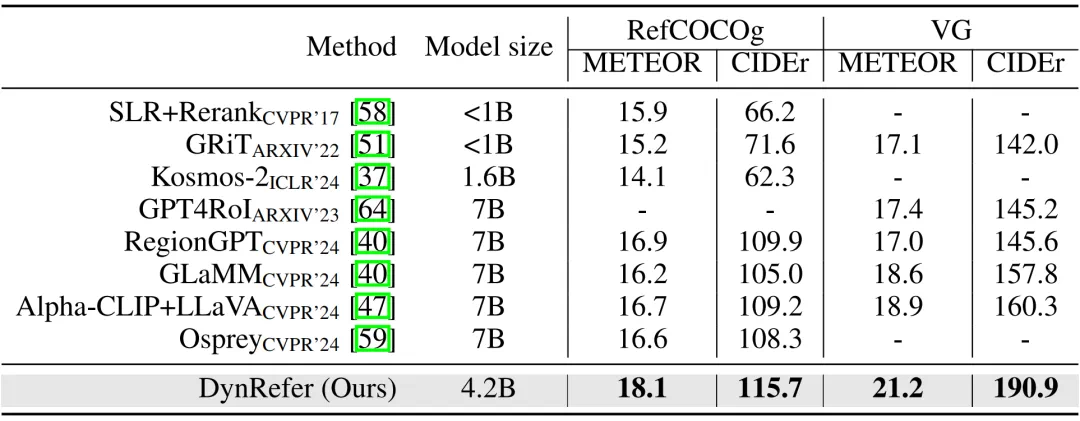
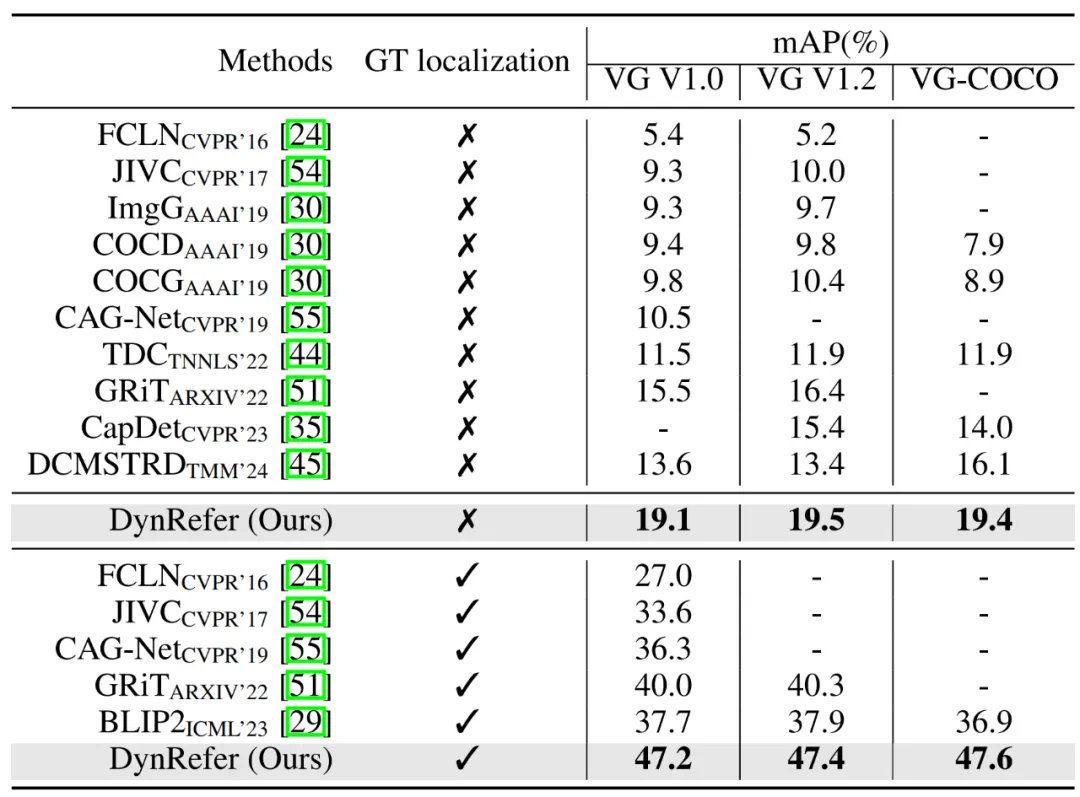
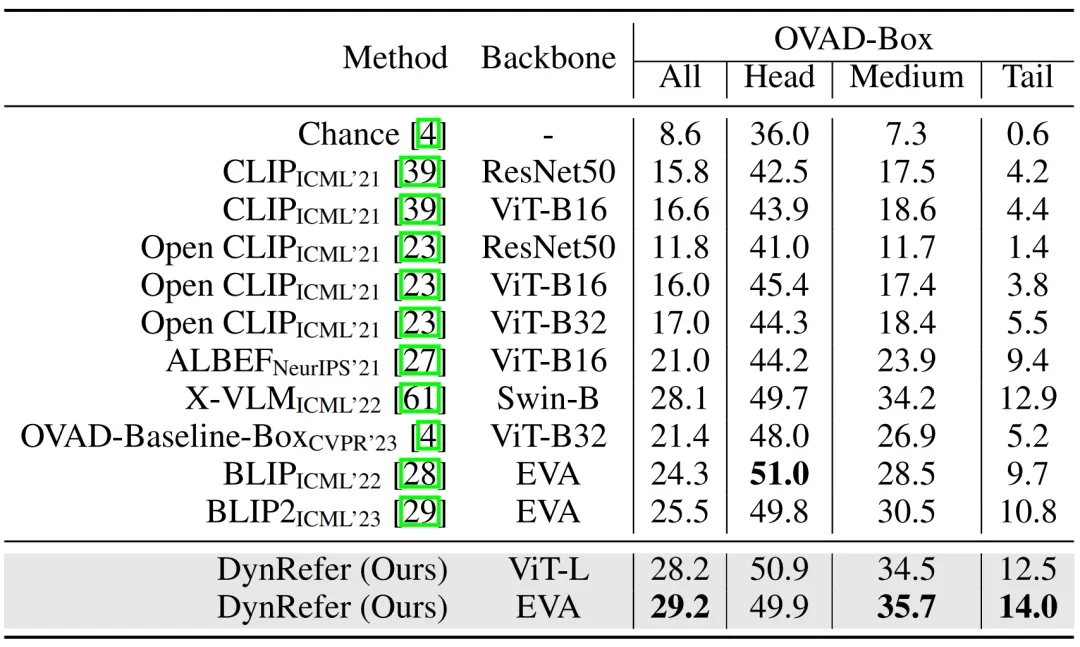
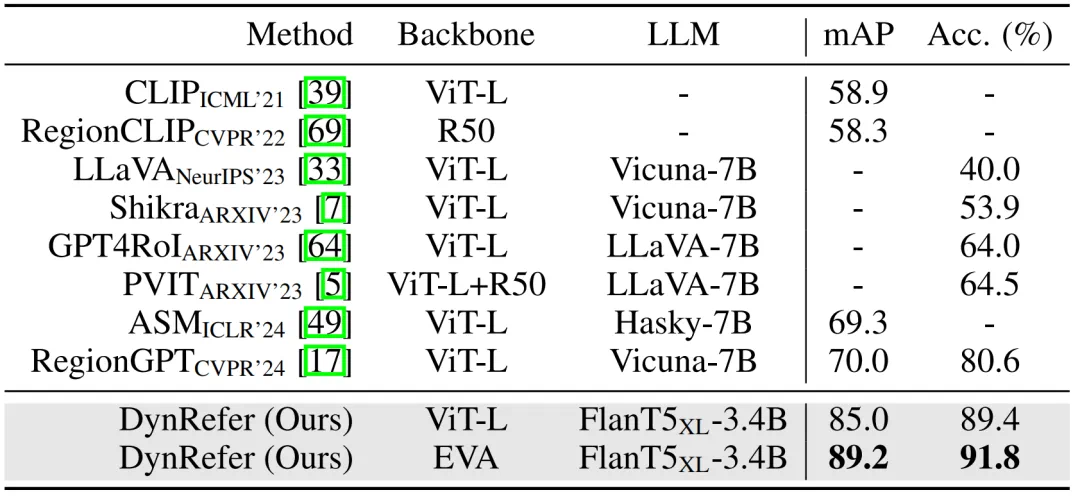
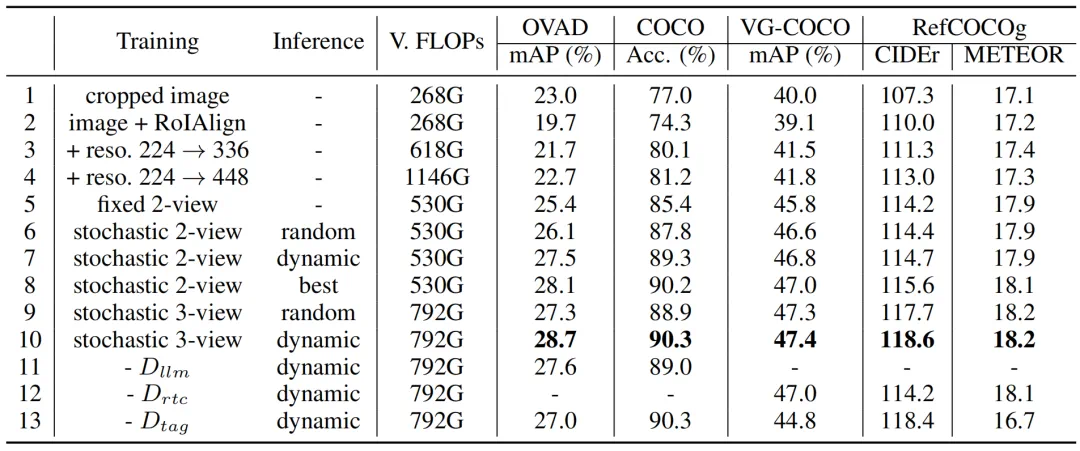
-
Line 1-6:随机动态多视图要优于固定视图。 -
Line 6-10:通过最大化信息选择视图优于随机选择视图。 -
Line 10-13:多任务训练可以学习得到更好的区域表征。


