文章来源于互联网:Bengio团队提出多模态新基准,直指Claude 3.5和GPT-4o弱点

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文作者张天宇,就读于加拿大Mila人工智能研究所,师从图灵奖得主Yoshua Bengio教授。博士期间的主要工作聚焦于多模态、GFlowNet、多智能体强化学习、AI于气候变化的应用。目前已在ICML、ICLR、ICASSP等机器学习顶会发表论文。代表作为Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation (CLAP)。


-
论文标题:VCR: Visual Caption Restoration -
论文链接:arxiv.org/abs/2406.06462 -
代码仓库:github.com/tianyu-z/VCR (点击阅读原文即可直达,包含评用于模型评测和预训练的数据生成代码) -
Hugging Face 链接:huggingface.co/vcr-org
-
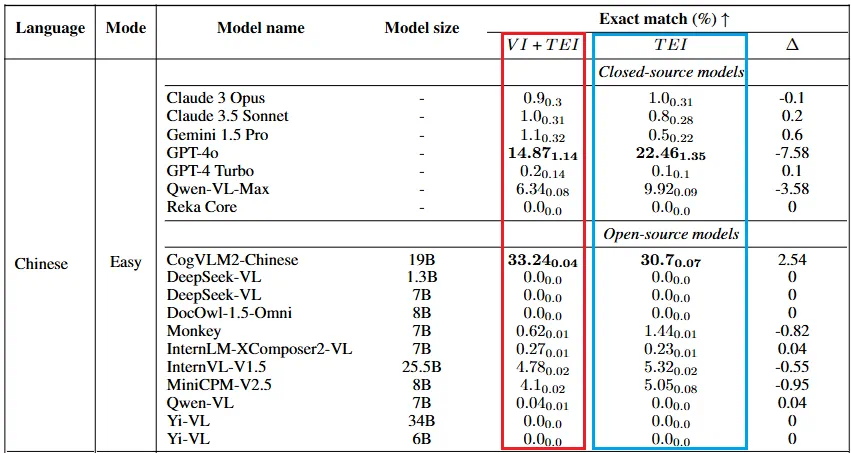
“简单” 难度 VCR 任务能使得 OCR 模型失效; -
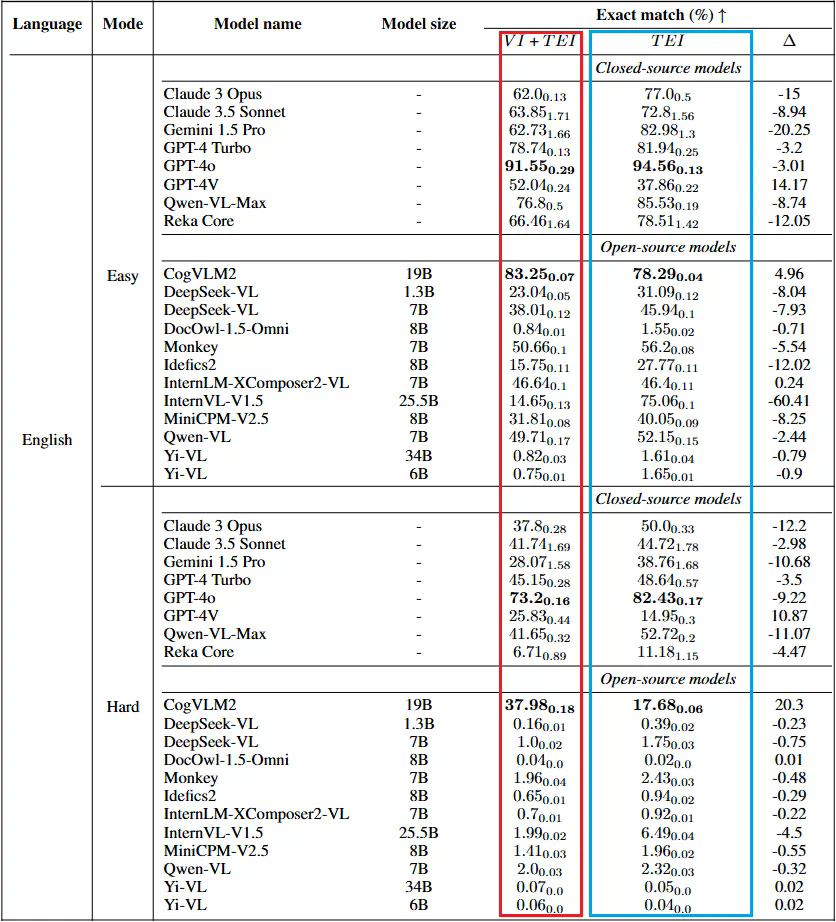
“困难” 难度 VCR 任务则对每个被遮挡的文本只保留上下各 1-2 个像素的高度,但依然能让对应语言的使用者完成任务。





-
绝大多数模型目前都不能胜任这个任务; -
绝大多数模型没有利用好图像信息,没有因为图像信息(VI)而提高准确率。


-
VCR 任务的独特挑战在于要求模型在视觉和文本信息之间进行精确的对齐,这与 OCR 的简单文本提取任务形成鲜明对比。在 OCR 中,主要关注的是识别可见字符,而无需理解它们在图像叙事中的上下文相关性。相比之下,VCR 要求模型协同利用可用的部分像素级文本提示和视觉上下文来准确地重建被遮挡的内容。这不仅测试了模型处理嵌入文本和视觉元素的能力,还考验了其保持内部一致性的能力,类似于人类通过上下文和视觉线索进行理解和响应的认知过程。 -
与 VQA 不同,VCR 任务的问题有唯一的答案,这使得评估可以通过准确度进行,使评测指标更加明确。 -
通过调整文本的遮盖比例,可以控制任务的难度,从而提供一个丰富的测试环境。 -
与 OCR 任务一样,VCR 任务也可以充当 VLM 的训练任务。作者开放了 transform 代码,可以生成任意给定图像 – 文字对的 VCR 任务图。
