文章来源于互联网:首个开源、原生多模态生成大模型:一键生成 「煎鸡蛋」图文菜谱

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

-
项目主页:https://gair-nlp.github.io/anole -
Github: https://github.com/GAIR-NLP/anole -
Huggingface: https://huggingface.co/GAIR/Anole-7b-v0.1
-
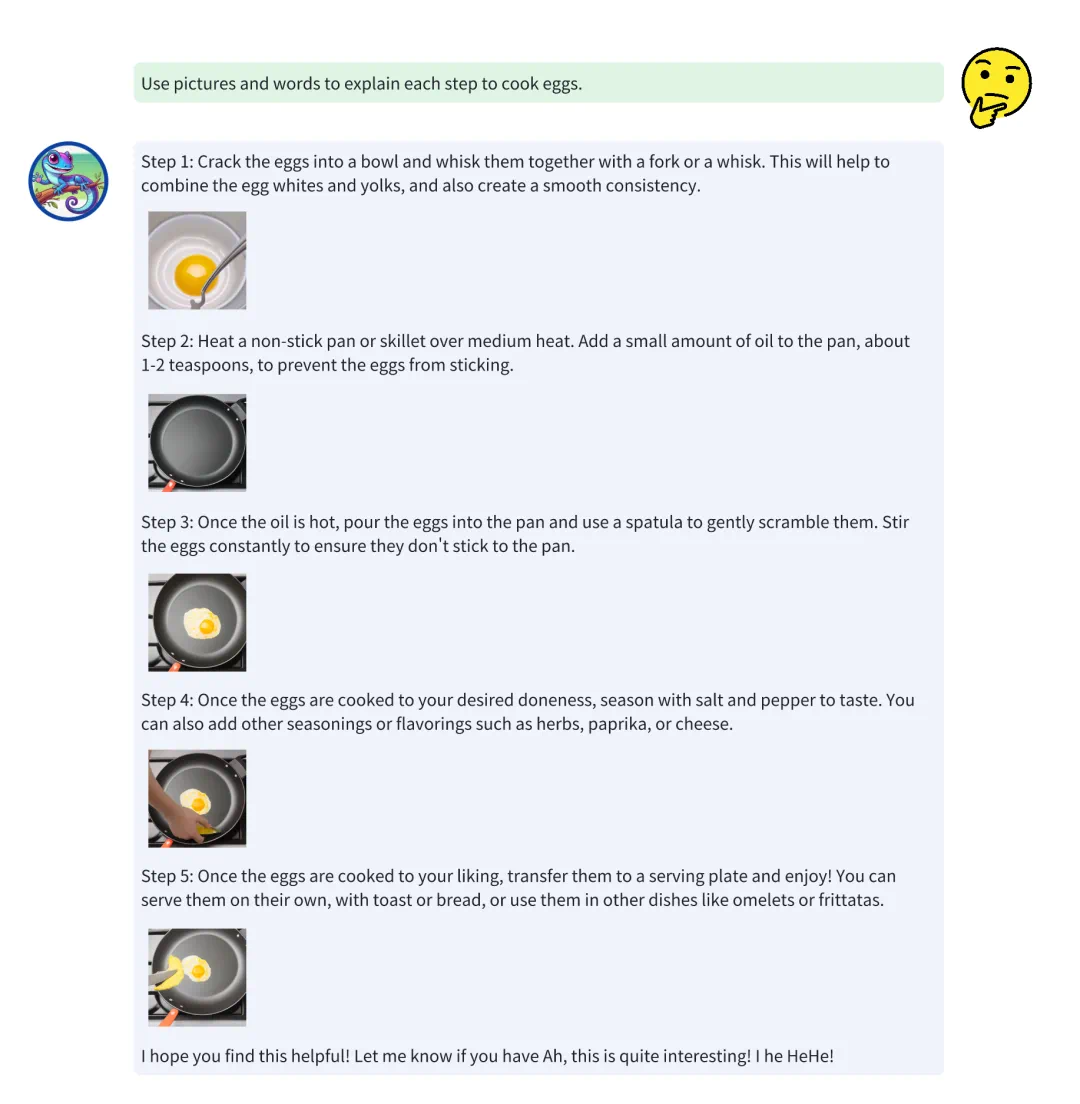
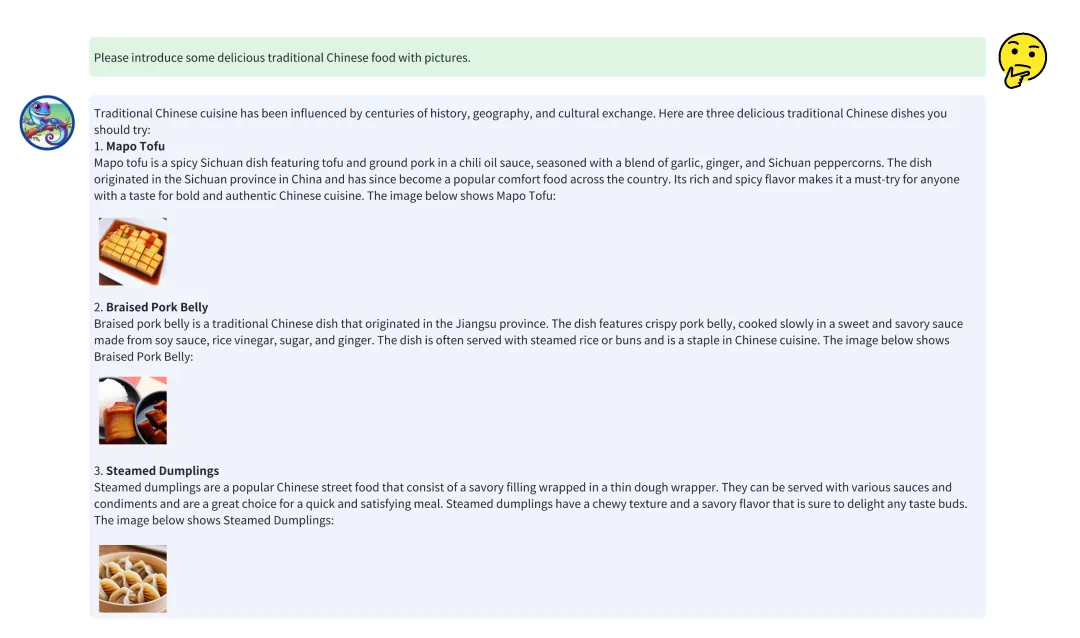
文本 → 图片 + 文本:能够生成图像并附带相关文本描述。除开上文中使用Anole以生成一系列煎蛋步骤的图片并附上相关描述文字的例子外。模型还可以生成其他图文交错的数据。这种能力在初步测试中表现良好,能够生成有意义的图像并准确传达文本信息。


-
文本 → 图片:能够根据文本生成图像。
指令: A piece of paper with word like “Anole” written on it, and a drawing of an Anole.
生成结果:

指令: An image depicting three cubes stacked on a table. Each cube has a random color and a letter on it.
生成结果:

更多例子:


-
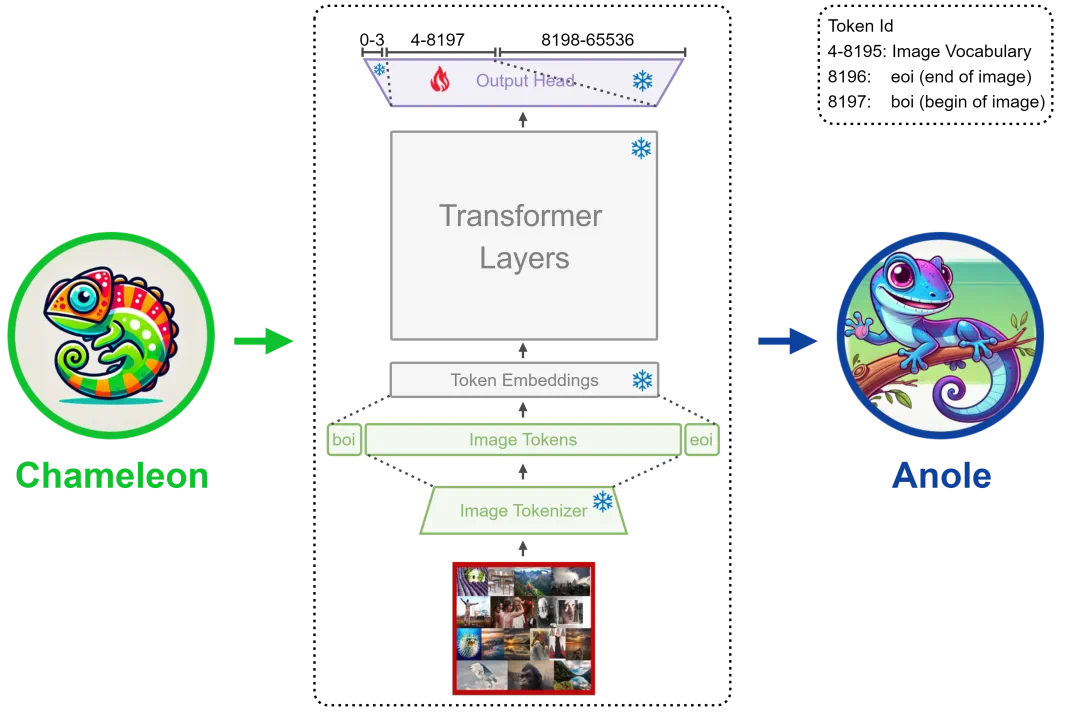
快速高效的微调手段:通过创新的局部微调方法,只调整不到40m参数,在短时间内(8 个 A100 GPU 上大约 30 分钟),便成功激发出Chameleon的图像生成能力,使研究人员和开发者能够充分利用并基于Chameleon的架构进行后续的多模态AI研究工作。 -
少即是多(Less is More)的微调数据:仅需5,859个图片样本便可有效激发Chameleon的图像生成能力,展示了在大型多模态模型中恢复复杂功能的高效性。 -
全面的微调和推理代码:提供了一整套用于微调、推理Chameleon和Anole的代码库,显著降低了开发和实验的门槛。 -
丰富的资源以提升可及性:提供了丰富的数据资源和详细的教程,旨在帮助各级别的研究人员更容易上手和实验。
-
模型微调代码(基于HuggingFace Trainer) -
权重转换代码(Hf->Meta & Meta->Hf) -
与图像生成有关的推理代码:包括文生图以及图文交互 -
5k+图片用于微调模型以赋予其图像生成的能力
-
它为探索统一的基于分词器的多模态模型(token-based)的性能上限提供了新的途径,使得与扩散模型 (diffusion-based) 等方法的比较成为可能。 -
同时,它推动了高效交错文本-图像解码技术的发展,这对实时应用至关重要(比如动漫生成、教材生成) -
此外,Anole 为探索这类复杂模型的最优微调策略创造了契机,并提出了如何确保生成图像安全性和伦理使用等亟待解决的问题。
文章来源于互联网:首个开源、原生多模态生成大模型:一键生成 「煎鸡蛋」图文菜谱
