文章来源于互联网:ECCV 2024|是真看到了,还是以为自己看到了?多模态大模型对文本预训练知识的过度依赖该解决了

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
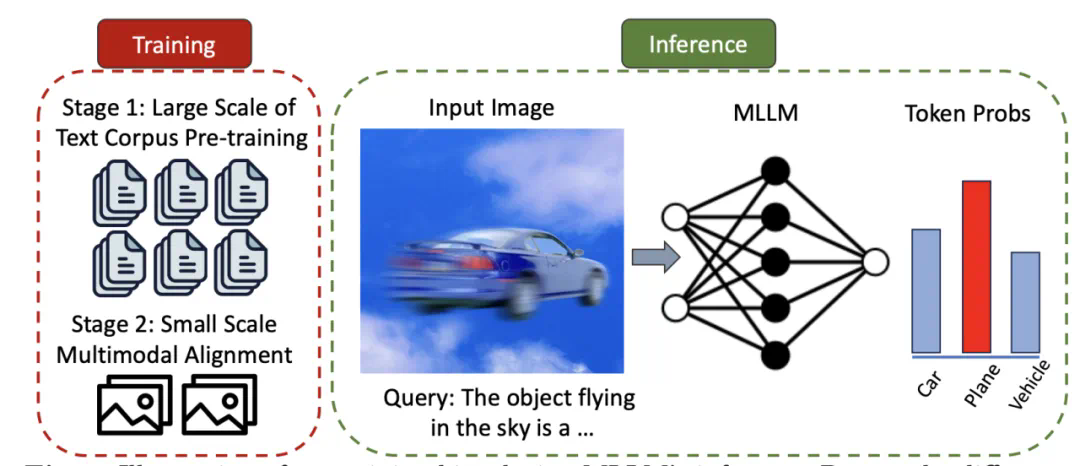
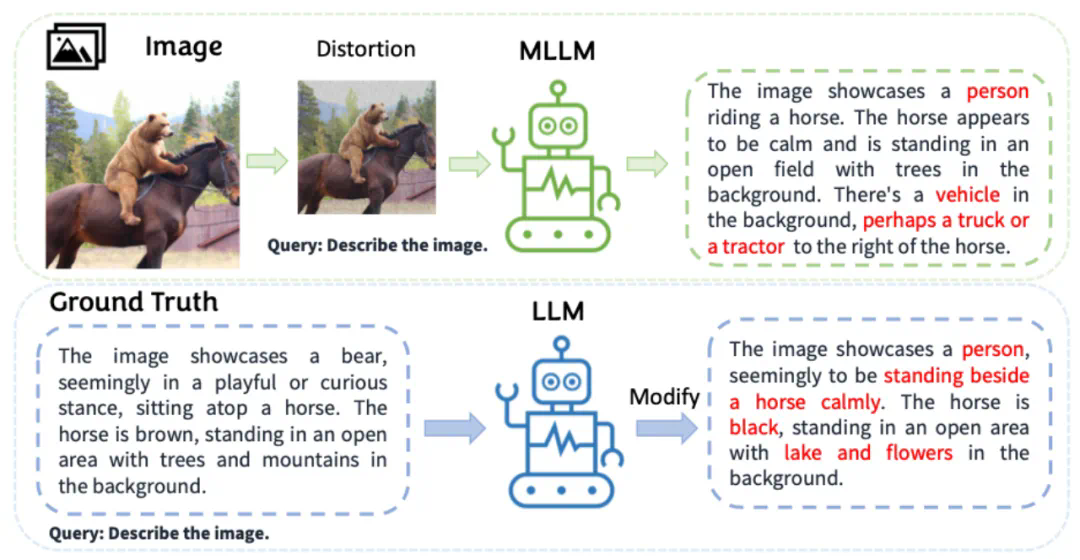
随着大型语言模型(LLMs)的进步,多模态大型语言模型(MLLMs)迅速发展。它们使用预训练的视觉编码器处理图像,并将图像与文本信息一同作为 Token 嵌入输入至 LLMs,从而扩展了模型处理图像输入的对话能力。这种能力的提升为自动驾驶和医疗助手等多种潜在应用领域带来了可能性。

-
论文标题:Strengthening Multimodal Large Language Model with Bootstrapped Preference Optimization -
论文链接:https://arxiv.org/pdf/2403.08730 -
代码链接:https://github.com/pipilurj/bootstrapped-preference-optimization-BPO-