文章来源于互联网:Llama3训练每3小时崩一次?豆包大模型、港大团队为脆皮万卡训练提效
伴随大模型迭代速度越来越快,训练集群规模越来越大,高频率的软硬件故障已经成为阻碍训练效率进一步提高的痛点,检查点(Checkpoint)系统在训练过程中负责状态的存储和恢复,已经成为克服训练故障、保障训练进度和提高训练效率的关键。
近日,字节跳动豆包大模型团队与香港大学联合提出了 ByteCheckpoint。这是一个 PyTorch 原生,兼容多个训练框架,支持 Checkpoint 的高效读写和自动重新切分的大模型 Checkpointing 系统,相比现有方法有显著性能提升和易用性优势。本文介绍了大模型训练提效中 Checkpoint 方向面临的挑战,总结 ByteCheckpoint 的解决思路、系统设计、I/O 性能优化技术,以及在存储性能和读取性能测试的实验结果。
Meta 官方最近披露了在 16384 块 H100 80GB 训练集群上进行 Llama3 405B 训练的故障率 —— 短短 54 天,发生 419 次中断,平均每三小时崩溃一次,引来不少从业者关注。
正如业内一句常言,大型训练系统唯一确定的,便是软硬件故障。随着训练规模与模型大小的日益增长,克服软硬件故障,提高训练效率成为大模型迭代的重要影响要素。
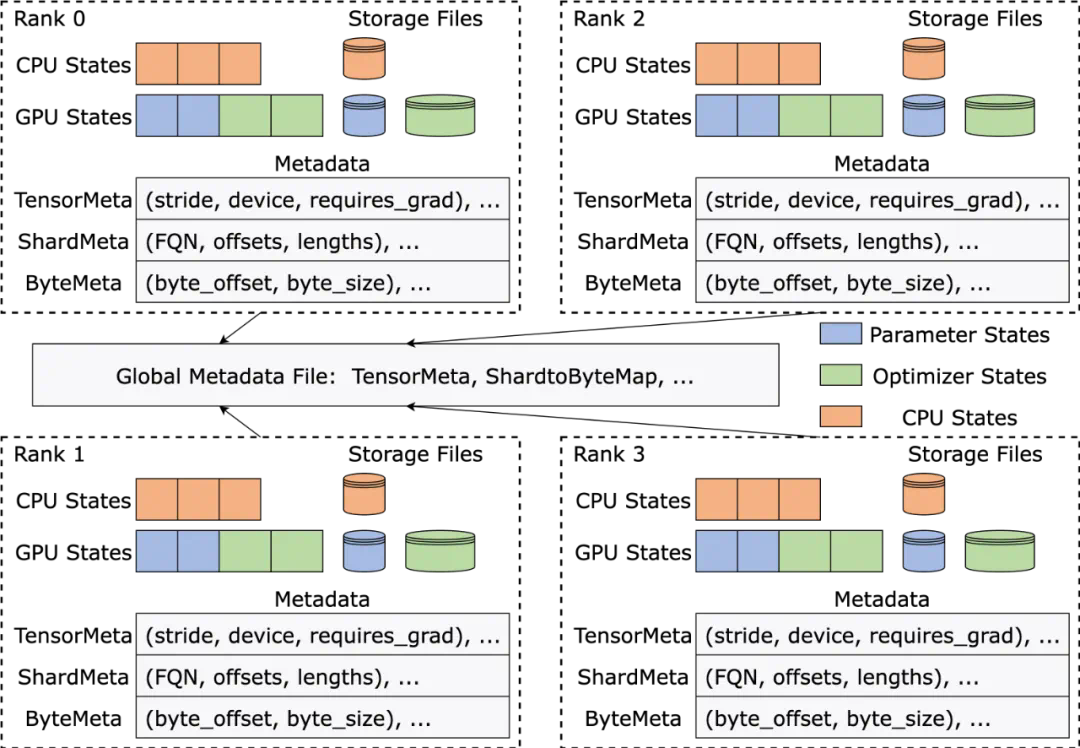
Checkpoint 已成为训练提效关键。在 Llama 训练报告中,技术团队提到,为了对抗高故障率,需要在训练过程中频繁地进行 Checkpoint ,保存训练中的模型、优化器、数据读取器状态,减少训练进度损失。
字节跳动豆包大模型团队与港大近期公开了成果 —— ByteCheckpoint ,一个 PyTorch 原生,兼容多个训练框架,支持 Checkpoint 的高效读写和自动重新切分的大模型 Checkpointing 系统。
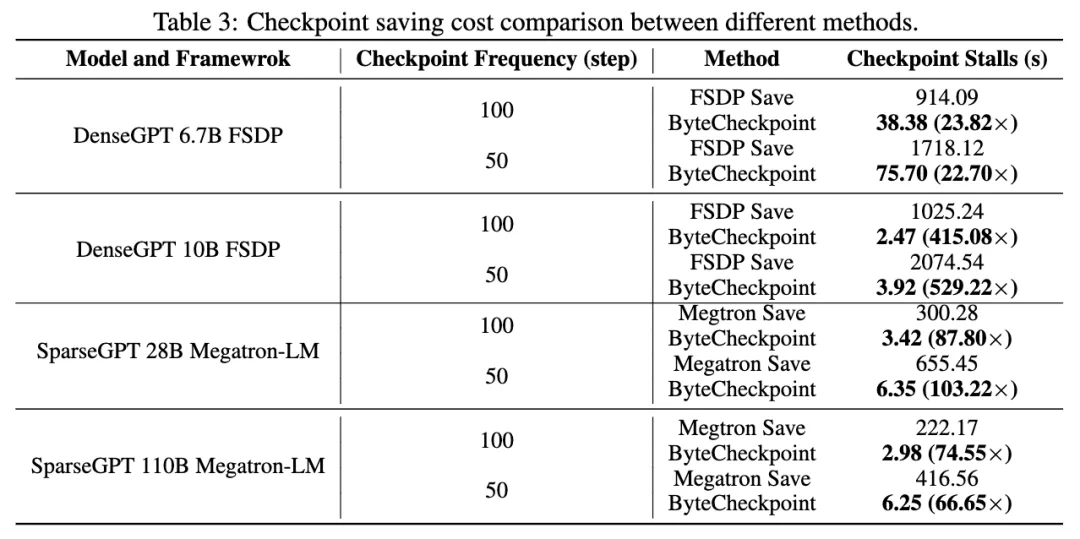
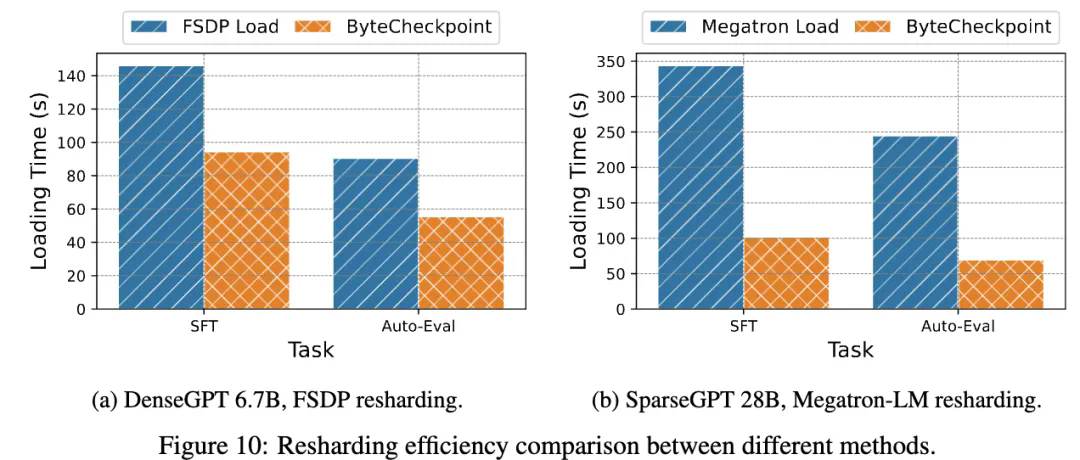
与基线方法相比,ByteCheckpoint 在 Checkpoint 保存上性能提升高达 529.22 倍,在加载上,性能提升高达 3.51 倍。极简的用户接口和 Checkpoint 自动重新切分功能,显著降低了用户上手和使用成本,提高了系统的易用性。

-
ByteCheckpoint: A Unified Checkpointing System for LLM Development -
论文链接:https://team.doubao.com/zh/publication/bytecheckpoint-a-unified-checkpointing-system-for-llm-development?view_from=research
-
现有系统设计存在缺陷,显著增加训练额外 I/O 开销
-
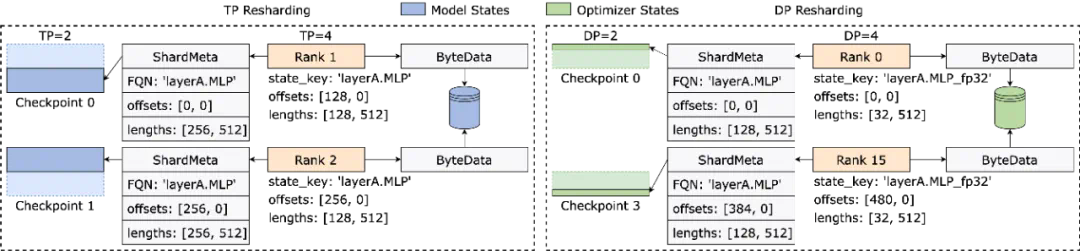
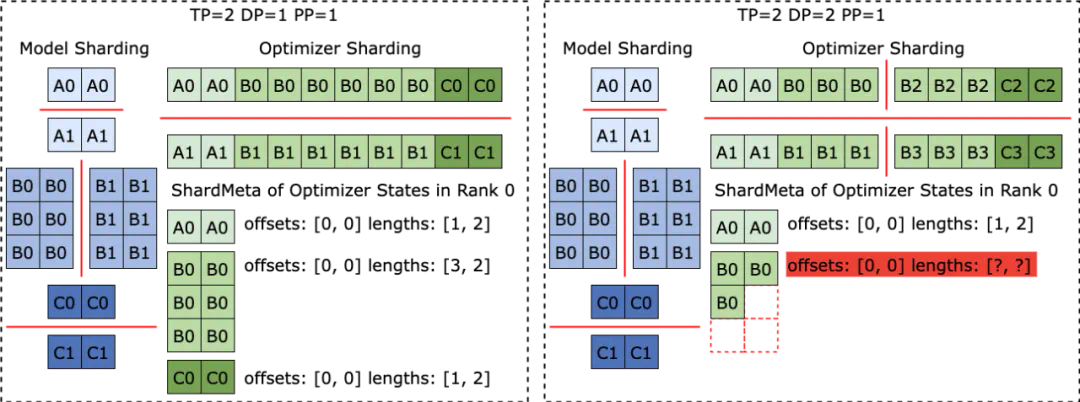
Checkpoint 重新切分困难,手动切分脚本开发维护开销过高
-
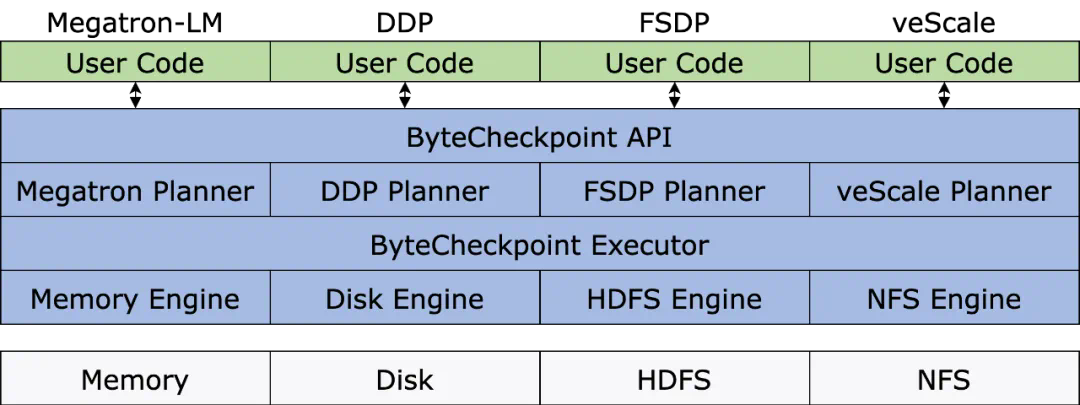
不同的训练框架 Checkpoint 模块割裂,为 Checkpoint 统一管理和性能优化带来挑战
-
分布式训练系统的用户面临多重困扰



文章来源于互联网:Llama3训练每3小时崩一次?豆包大模型、港大团队为脆皮万卡训练提效
