文章来源于互联网:新PyTorch API:几行代码实现不同注意力变体,兼具FlashAttention性能和PyTorch灵活性
用 FlexAttention 尝试一种新的注意力模式。
-
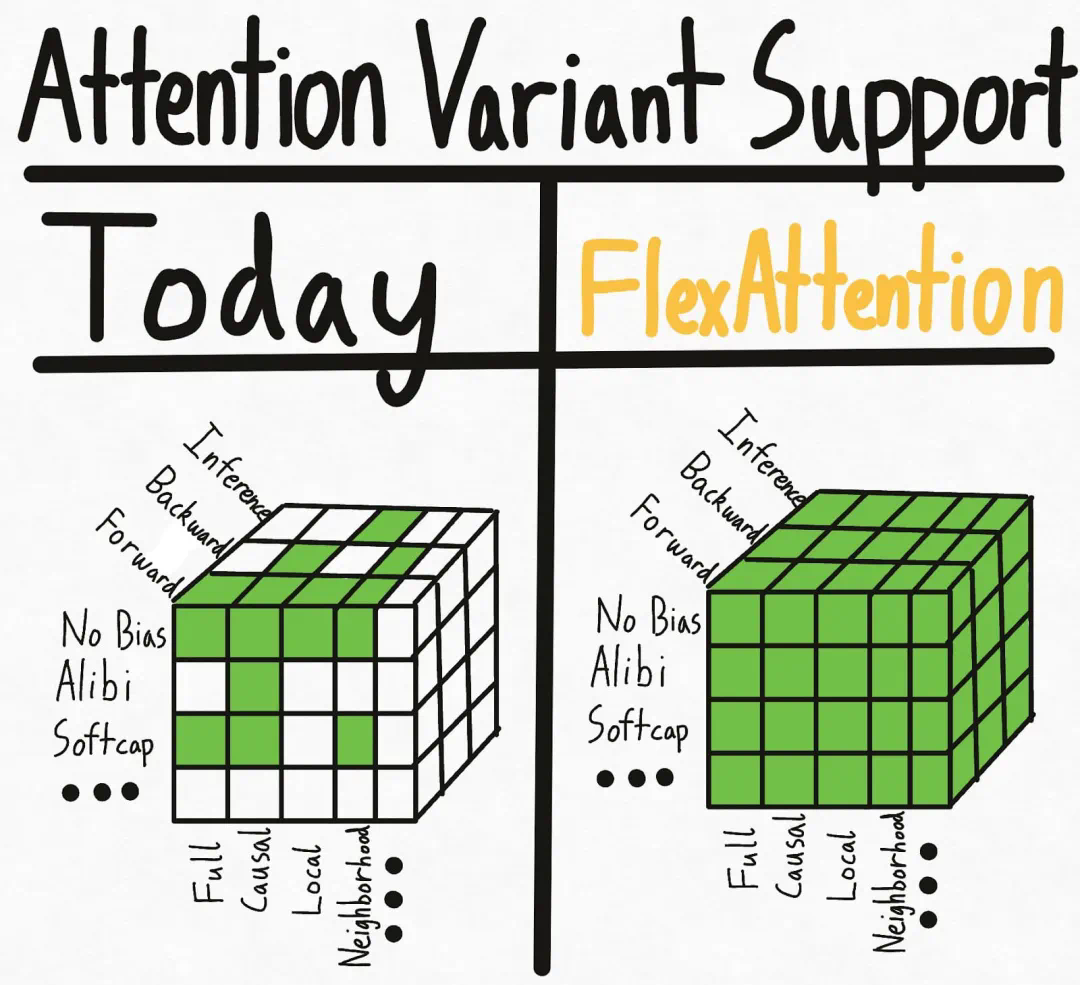
FlexAttention 是一个灵活的 API,允许用户使用几行惯用的 PyTorch 代码就能实现多个注意力变体。 -
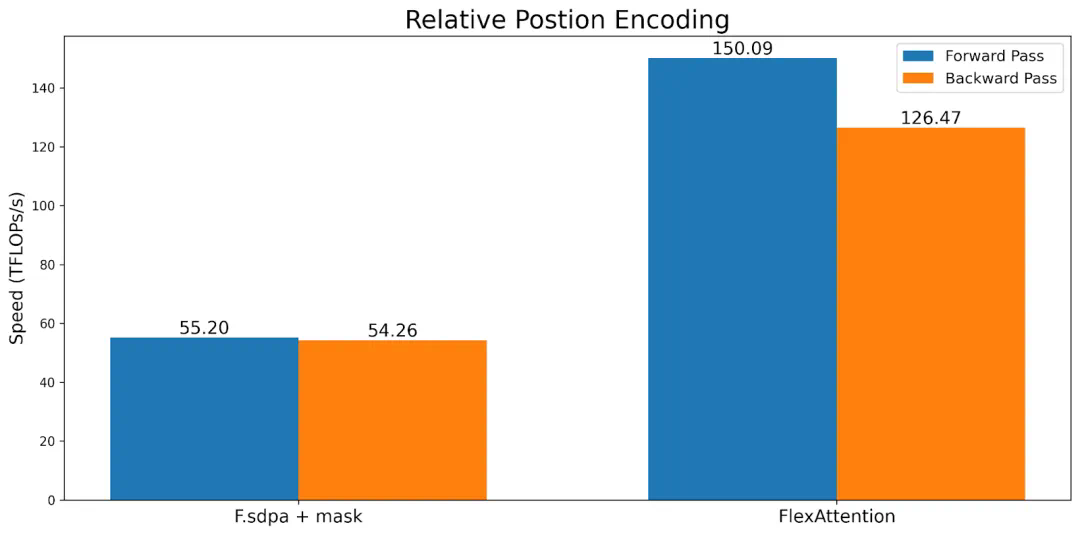
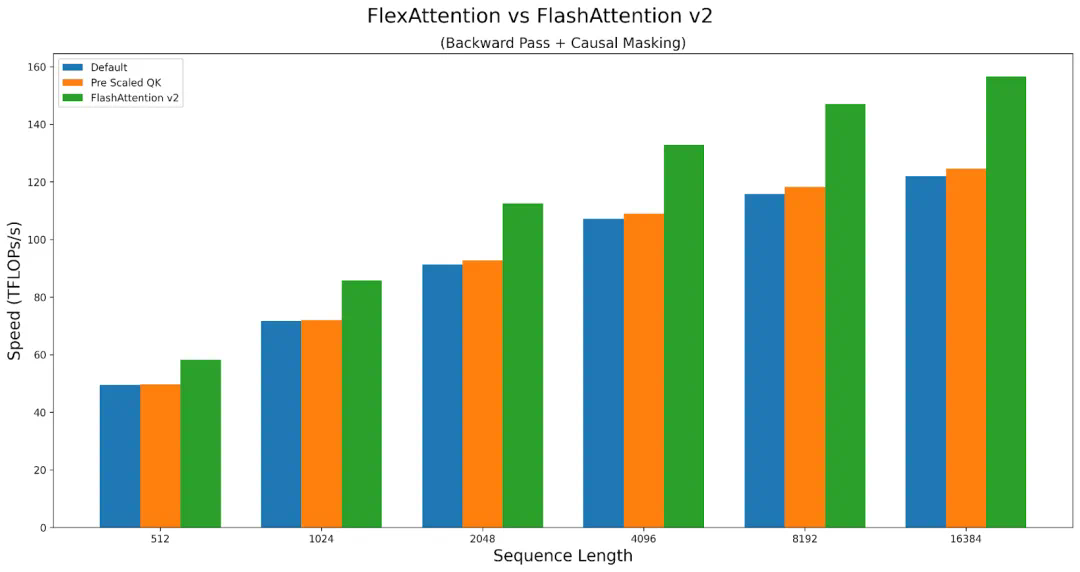
团队人员通过 torch.compile 将其降低到一个融合的 FlashAttention 内核中 ,生成了一个不会占用额外内存且性能可与手写内核相媲美的 FlashAttention 内核。 -
利用 PyTorch 的自动求导机制自动生成反向传播。 -
最后,PyTorch 团队还可以利用注意力掩码中的稀疏性,从而显著改善标准注意力实现。


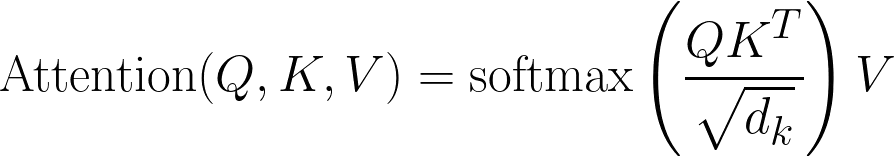

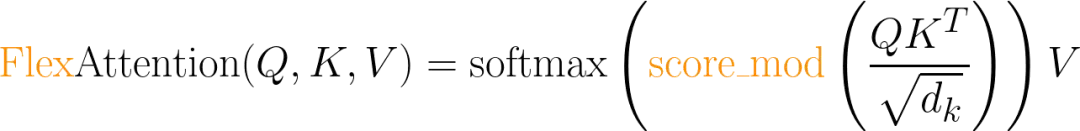 代码形式:
代码形式:

for b in range (batch_size):for h in range (num_heads):for q_idx in range (sequence_length):for kv_idx in range (sequence_length):modified_scores [b, h, q_idx, kv_idx] = score_mod (scores [b, h, q_idx, kv_idx], b, h, q_idx, kv_idx)





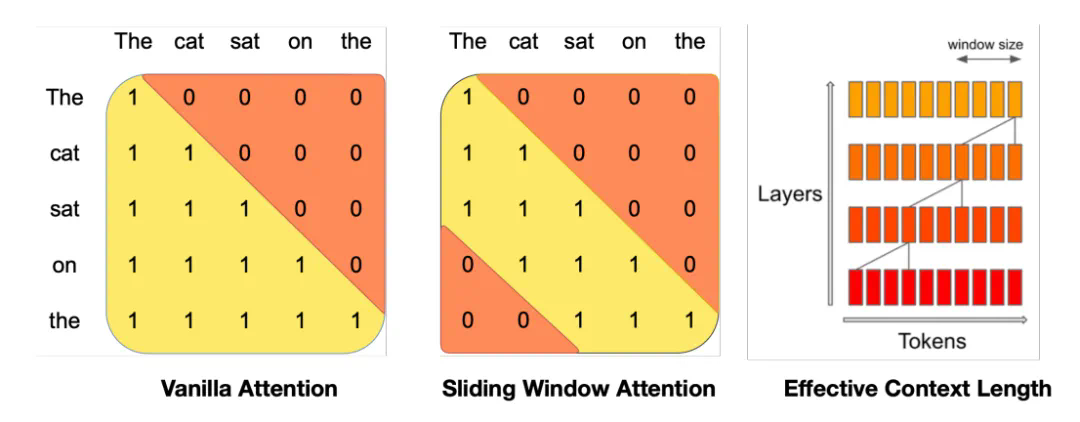
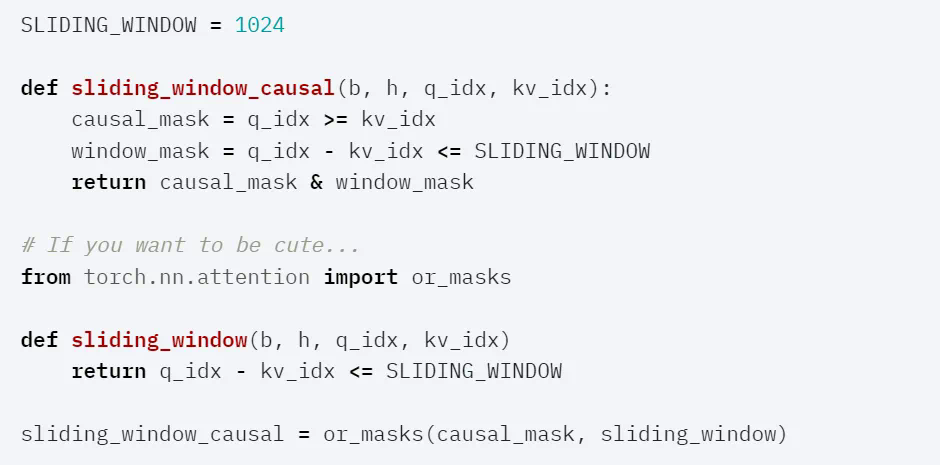
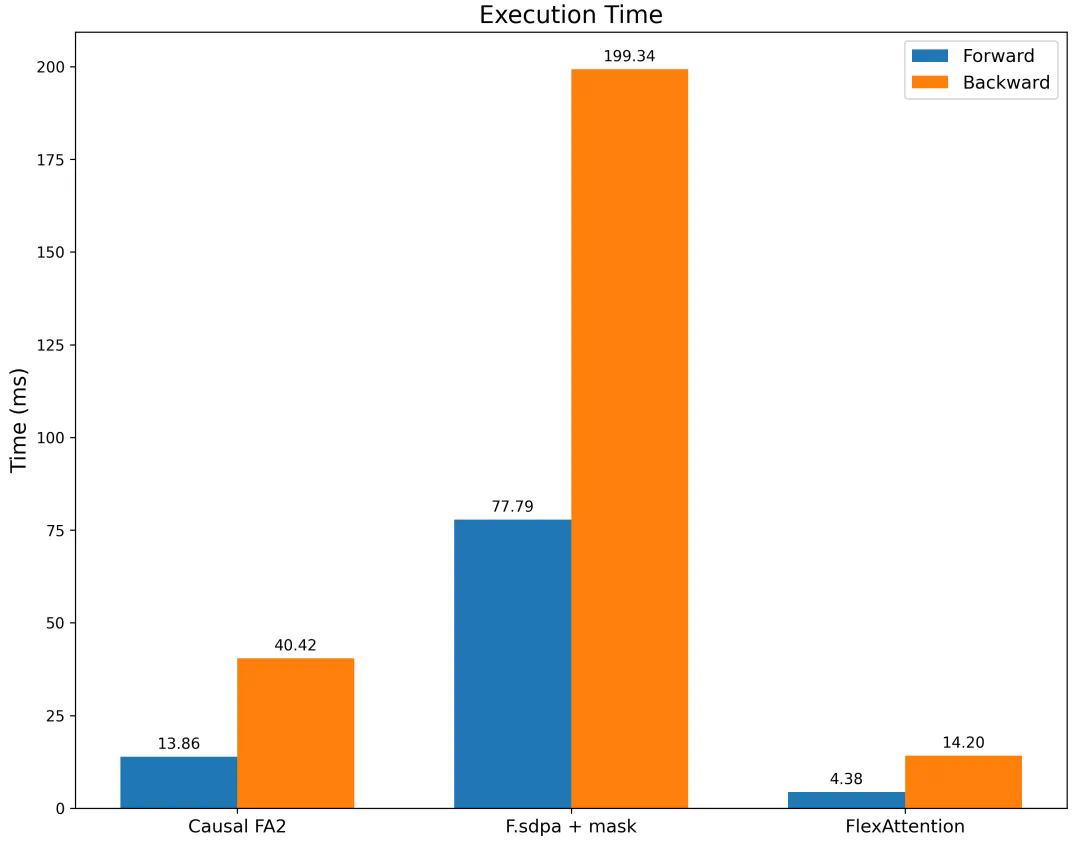
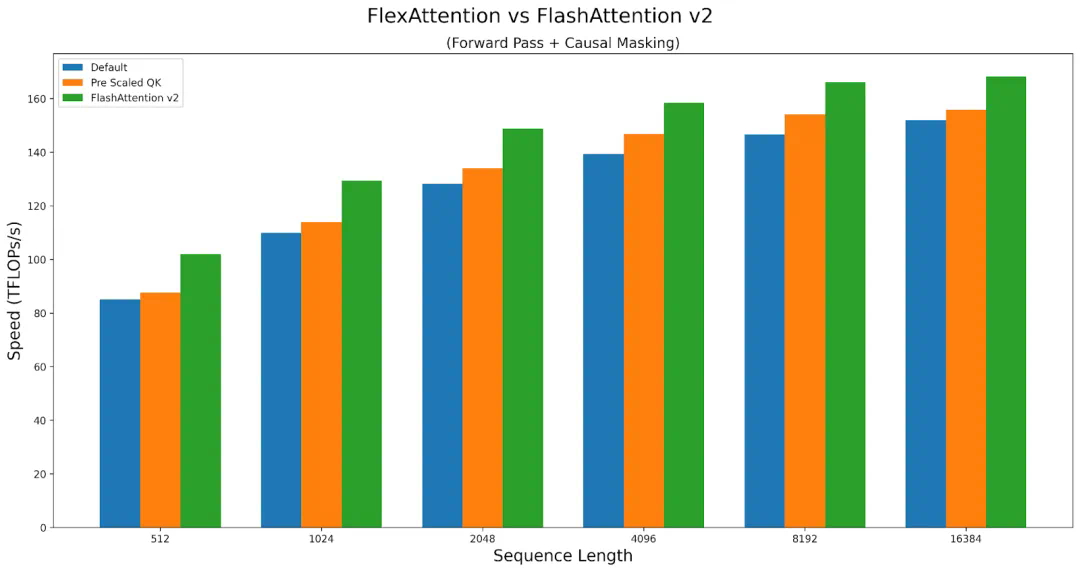
文章来源于互联网:新PyTorch API:几行代码实现不同注意力变体,兼具FlashAttention性能和PyTorch灵活性

