
前言
为了更好地理解深度学习,本章我们将以天池大赛的赛事为例实现深度学习的项目实战,同时结合软件的研发流程,梳理形成完整资料,包括:需求设计、概要设计、测试方案、测试报告、用户手册。
文章索引
- 项目目标:简要阐述本次实战的项目目标以及数据集情况
- 项目实战:按照以下四部分介绍项目的实现过程以及代码实现
-
- 数据分析
-
- 数据预处理
-
- 模型训练
-
- 模型推理
-
- 项目资料:为了便于深度学习中级认证考试,梳理相关资料以供参考
-
- 需求设计
-
- 概要设计
-
- 测试方案
-
- 测试报告
-
- 用户手册
-
项目资料仅供参考,请勿直接复制使用。
项目目标
通过深度学习技术,构建一个基于深度学习的二手车价格预测模型,能够根据车辆的各项特征(如品牌、型号、年份、里程等)准确预测其市场价格。
数据集简介
下载地址
https://tianchi.aliyun.com/dataset/175540
内容简介
这是阿里天池上的一个数据集,该数据集为二手车交易价格数据集,数据来自某交易平台的二手车交易记录,总数据量超过40w,包含31列变量信息,其中15列为匿名变量。
数据情况
| 数据名称 | 上传日期 | 大小 |
|---|---|---|
| used_car_testB_20200421.csv | 2024-04-16 | 17.06MB |
| used_car_train_20200313.csv | 2024-04-16 | 51.77MB |
数据字段
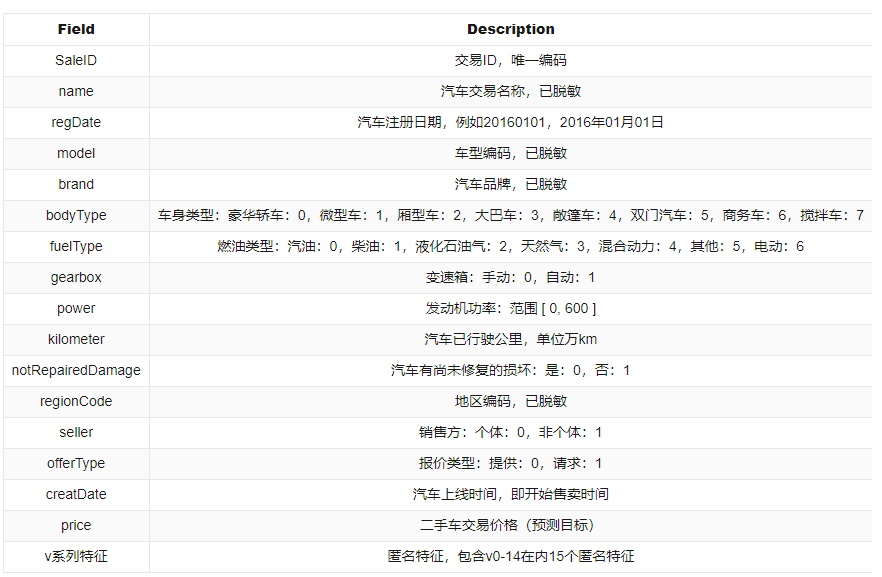
项目实战
1. 数据分析
1.1 数据分析背景
数据集一般情况下会存在多种问题,以二手车数据为例:
- 数据缺失,例如:二手车某个字段的内容为空…
- 数据异常,例如:二手车价格超过1亿…
- 数据格式问题,例如:二手车价格字段为字符串类型,需要转换为数值类型…
因此,在数据分析有一个专业领域叫EDA(Exploratory Data Analysis),即探索性数据分析。
1.2 探索性数据分析
探索性数据分析是有一套方法论的,由于篇幅原因,本篇文章暂不展开,详情请见CSDN:超全总结!探索性数据分析 (EDA)方法汇总!。
通过了解探索性数据分析,其大致步骤为:
- 检查数据
- 是否有缺失值?
- 是否有异常值?
- 是否有重复值?
- 样本是否均衡?
- ….
- 数据可视化
- 连续量:
- 图表:直方图、盒图、密度图、箱线图等…
- 统计量:均值、中位数、众数、最大值、最小值等…
- 离散量:
- 图表:柱状图、饼图、条形图等…
- 统计量:各个变量的频数、占比等…
- 连续量:
- 考察变量之间的关系
- 连续量与连续量的关系
- 离散量与离散量的关系
- 离散量与连续量的关系
…
由上可见,数据分析是一门比较专业的学科,是需要专业的理论和方法论来支撑的。
现在有一个开源工具,可以方便我们进行数据的自动化分析:ydata-profiling。
1.3 ydata-profiling
简介
ydata-profiling 是一个数据分析包,只需要几行代码,就可以自动化生成数据集的详细报告,报告包含统计信息和数据摘要。
安装方法
pip install ydata-profiling
pip install ipywidgets使用方法
import pandas
from ydata_profiling import ProfileReport
# 以下file_train_path是一个文件路径,限于篇幅原因,路径的获取以及赋值在此处省略
df = pandas.read_csv(file_train_path, sep=' ')
# 生成报告
profile = ProfileReport(df, title='Pandas Profiling Report', html={'style':{'full_width':True}})
# 报告输出到jupyter notebook
profile.to_notebook_iframe()
运行结果:
报告解析
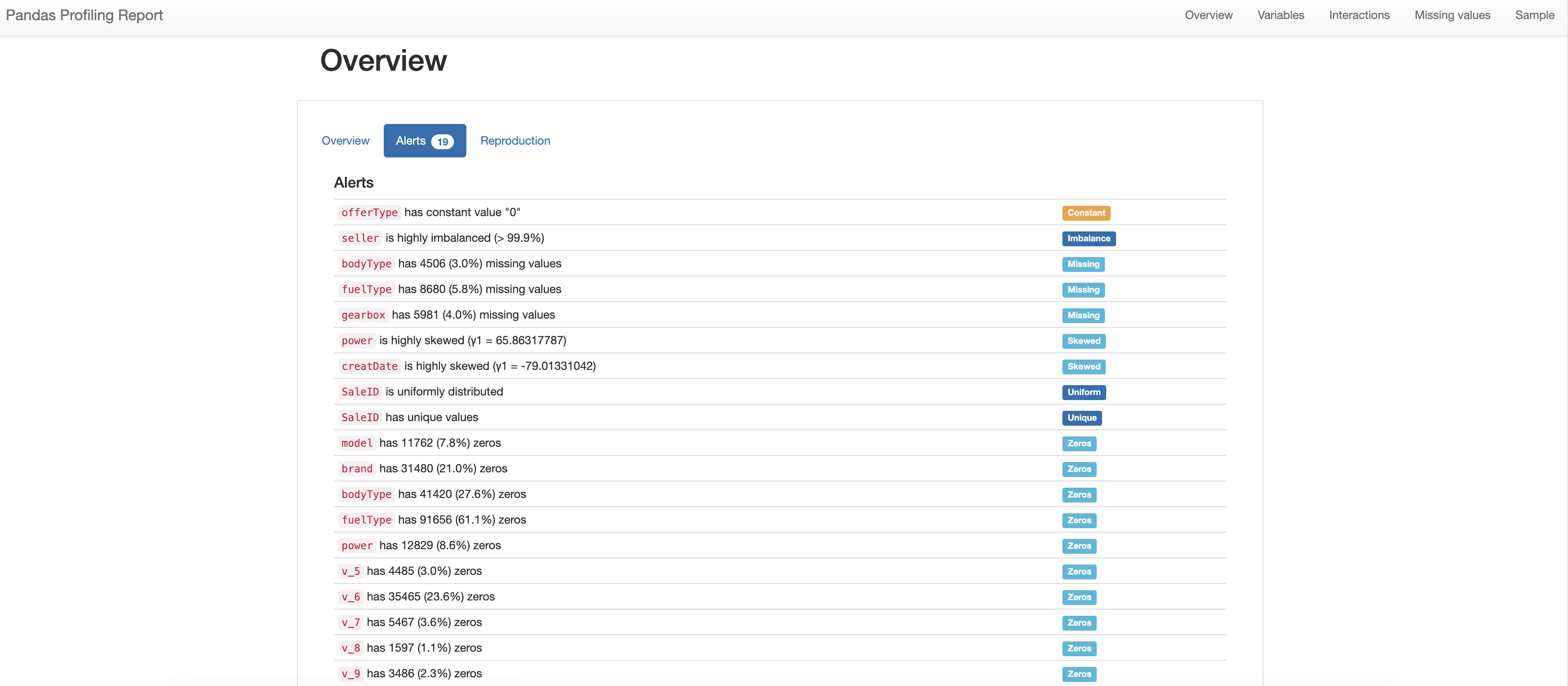
在报告的Overview总览的Alert中,我们可以看到数据集的统计情况,包括:
- offerType has constant value "0"
offerType 存在数值为0的常量(通过查看数据字段中offerType字段主要就是0和1,这应该是合理的)
- seller is highly imbalanced (> 99.9%)
seller 提示存在严重不均衡(通过查看seller字段含义为个体或非个体,大多数情况下都是个体,这也是合理的)
- bodyType has 4506 (3.0%) missing values
- fuelType has 8680 (5.8%) missing values
- gearbox has 5981 (4.0%) missing values
bodyType、fuelType、gearbox存在数据缺失情况(稍后进行排查)
- power is highly skewed (γ1 = 65.86317787)
- creatDate is highly skewed (γ1 = -79.01331042)
power、creatDate字段,特征的分布是高度偏斜的(稍后进行排查)
- SaleID is uniformly distributed
- SaleID has unique values
SaleID字段,数据唯一(因为该字段是ID号,所以数据唯一是合理的)
- model has 11762 (7.8%) zeros
- brand has 31480 (21.0%) zeros
- …
model、brand、bodyType、fuelType、power字段都存在0值(这是合理的)
通过以上的分析,我们可以看到数据集主要存在两个问题:
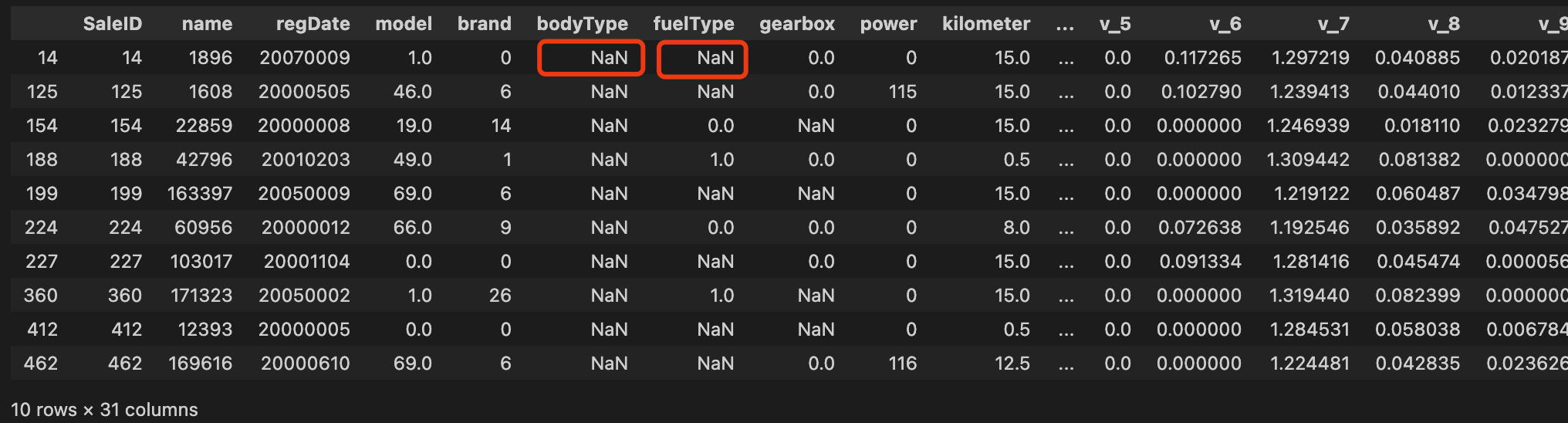
问题1:bodyType、fuelType、gearbox存在数据缺失情况
# 查看data中bodyType列Missing的数据
df['bodyType'].isnull().sum()
# 查看10条bodyType列Missing的数据
df[df['bodyType'].isnull()].head(10)运行结果:的确存在内容为空的问题
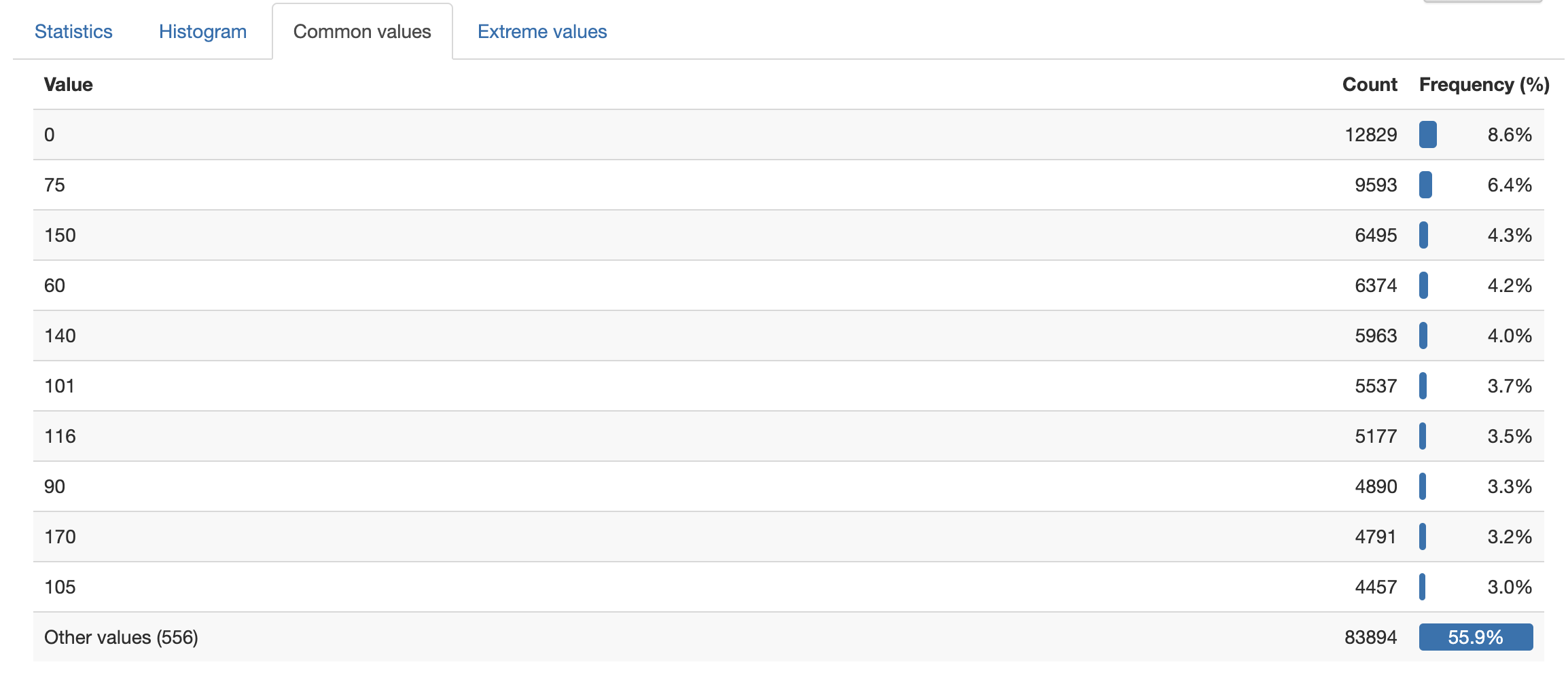
问题2:power、creatDate字段,特征的分布是高度偏斜的
在报告中点击查看power字段,由于该字段是表示发动机攻略,大部分攻略为556类型,所以看着应该是合理的。
小结:
- 通过ydata_profiling分析之后,数据集中主要的问题是bodyType、fuelType、gearbox存在数据缺失情况,需要后续进行清洗处理。
2. 数据预处理
2.1 离散量和连续量
| 字段 | 描述 | 类型 | 处理方法 |
|---|---|---|---|
| SaleID | 样本ID | 连续量 | 无 |
| name | 汽车交易名称(0~196793) | 连续量 | 无 |
| regDate | 汽车注册日期,例如:20160101 | 连续量 | 无 |
| model | 车型编码(0~250) | 连续量 | 无 |
| brand | 品牌编码(0~39) | 连续量 | 无 |
| bodyType | 车型(豪华轿车:0,微型车:1;…) | 离散量 | 去除空值 |
| fuelType | 燃油类型(汽油:0,柴油:1,液化石油气:2;…) | 离散量 | 去除空值 |
| gearbox | 变速箱(手动:0,自动:1) | 离散量 | 去除空值 |
| power | 发动机功率(0~600) | 连续量 | 无 |
| kilometers | 行驶里程 | 连续量 | 无 |
| notRepaired | 是否修复过(是:0,否:1) | 离散量 | 无 |
| regionCode | 地区编码(0~8100) | 连续量 | 无 |
| seller | 卖家类型(个体:0,非个体:1) | 离散量 | 无 |
| offerType | 卖家类型(提供:0,请去:1) | 离散量 | 无 |
| creatDate | 发布时间(例如:20160403) | 连续量 | 无 |
| v系列特征 | V系列特征 | 连续量 | 无 |
| price | 售价 | 连续量 | 无 |
2.2 处理空值
空值的处理方法有多种:
- 删除空值
- 使用0填充空值
- 使用中位数填充空值
在本次实战中,我们选择较为简单粗暴的方式:直接剔除空值的相应行。
代码文件:src/data_processing/data_processor.py
def _preprocess_features(X: pd.DataFrame, y: pd.Series) -> tuple:
"""
预处理特征数据,包括数据类型转换和处理缺失值
Args:
X (pd.DataFrame): 特征数据
y (pd.Series): 目标变量
Returns:
tuple: (处理后的特征X, 处理后的目标变量y)
"""
# 数据类型转换
for column in X.columns:
X[column] = pd.to_numeric(X[column], errors='coerce')
# 剔除包含缺失值的行
combined_df = pd.concat([X, pd.Series(y, name='target')], axis=1)
combined_df = combined_df.dropna()
X = combined_df.drop('target', axis=1)
y = combined_df['target']
return X, y说明:
- 为了便于代码维护,我们创建一个DataProcessor类,用于处理数据,包括数据类型转换和处理缺失值。
- 该类中定义了_preprocess_features方法,用于处理数据,包括数据类型转换和处理缺失值。
- 由于在剔除空值时,需要同时剔除目标变量y,所以需要将X和y合并,然后剔除空值。
2.3 数据标准化
为了提升模型的训练效果,我们需要对数据进行标准化处理。
代码文件:src/data_processing/data_processor.py
def prepare_data(self,X, y, test_size=0.2, random_state=0) -> tuple:
"""
准备训练集和测试集,包括数据标准化
Args:
X: 特征数据
y: 目标变量
test_size: 测试集比例
random_state: 随机种子
Returns:
tuple: (X_train_normalized, X_test_normalized, y_train_normalized, y_test_normalized)
"""
# 预处理数据
X, y = DataProcessor._preprocess_features(X, y)
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=test_size, random_state=random_state
)
# 转换为numpy数组
X_train_np = X_train.values
X_test_np = X_test.values
y_train_np = y_train.values
y_test_np = y_test.values
# 计算并保存统计量
mean_X = X_train_np.mean(axis=0)
std_X = X_train_np.std(axis=0)
std_X[std_X == 0] = 1e-9
mean_y = y_train_np.mean()
std_y = y_train_np.std()
if std_y == 0:
std_y = 1e-9
# 将统计量保存为类属性
self.mean_X = mean_X
self.std_X = std_X
self.mean_y = mean_y
self.std_y = std_y
X_train_normalized = (X_train_np - mean_X) / std_X
X_test_normalized = (X_test_np - mean_X) / std_X
# y标签标准化
y_train_normalized = (y_train_np - mean_y) / std_y
y_test_normalized = (y_test_np - mean_y) / std_y
return X_train_normalized, X_test_normalized, y_train_normalized, y_test_normalized 说明:
- 我们在DataProcessor类中定义了prepare_data方法,用于准备训练集和测试集,包括数据标准化。
- 该方法调用_preprocess_features方法,用于处理数据,包括数据类型转换和处理缺失值。
3. 模型训练
3.1 模型定义
我们通过搭建一个全链接的模型,用于预测二手车价格。
代码文件:src/models/car_price_model.py
import torch.nn as nn
class CarPriceModel(nn.Module):
"""
二手车价格预测模型
"""
def __init__(self, in_features=13, out_features=1):
"""
初始化模型
Args:
in_features (int): 输入特征维度
out_features (int): 输出维度
"""
super(CarPriceModel, self).__init__()
self.linear1 = nn.Linear(in_features, 64)
self.relu1 = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.linear2 = nn.Linear(64, 32)
self.relu2 = nn.ReLU()
self.bn2 = nn.BatchNorm1d(32)
self.linear3 = nn.Linear(32, out_features)
def forward(self, x):
"""
前向传播
"""
x = self.linear1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.linear2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.linear3(x)
return x 3.2 数据集定义
我们创建一个CarPriceDataset类,用于定义数据集,以便后续模型训练时使用。
代码文件:src/datasets/car_price_dataset.py
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
class CarPriceDataset(Dataset):
"""二手车数据集类"""
def __init__(self, X, y):
"""
初始化数据集
Args:
X: 特征数据
y: 目标变量
"""
self.X = X
self.y = y.to_numpy() if not isinstance(y, np.ndarray) else y
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return (torch.tensor(self.X[idx], dtype=torch.float32),
torch.tensor(self.y[idx], dtype=torch.float32))3.3 数据加载器
代码文件:src/datasets/car_price_dataset.py
def create_data_loaders(X_train, X_test, y_train, y_test, batch_size_train=12, batch_size_test=32):
"""
创建数据加载器
Args:
X_train: 训练集特征
X_test: 测试集特征
y_train: 训练集标签
y_test: 测试集标签
batch_size_train: 训练批次大小
batch_size_test: 测试批次大小
Returns:
tuple: (训练数据加载器, 测试数据加载器)
"""
# 在 create_data_loaders 函数中,确保 y 值被重塑为 2D 张量
y_train = y_train.reshape(-1, 1)
y_test = y_test.reshape(-1, 1)
train_dataset = CarPriceDataset(X_train, y_train)
test_dataset = CarPriceDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=batch_size_train, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size_test, shuffle=False)
return train_loader, test_loader 3.4 模型训练器
为了方便模型训练,我们创建一个ModelTrainer类,管理训练过程中的模型、损失函数、优化器、设备等。
代码文件:src/training/trainer.py
import torch
import logging
import matplotlib.pyplot as plt
class ModelTrainer:
"""
模型训练器类
"""
def __init__(self, model, loss_fn, optimizer, device):
"""
初始化训练器
Args:
model: 神经网络模型
loss_fn: 损失函数
optimizer: 优化器
device: 训练设备
"""
self.model = model
self.loss_fn = loss_fn
self.optimizer = optimizer
self.device = device
def evaluate_model(self, dataloader):
"""
评估模型
Args:
dataloader: 数据加载器
Returns:
float: 平均损失值
"""
self.model.eval()
losses = []
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(self.device), y.to(self.device)
y_pred = self.model(X)
loss = self.loss_fn(y_pred, y)
losses.append(loss.item())
return round(sum(losses) / len(losses), 5)
def train(self, train_loader, test_loader, epochs, progress_callback=None):
"""
训练模型
Args:
train_loader: 训练数据加载器
test_loader: 测试数据加载器
epochs: 训练轮数
progress_callback: 进度回调函数
"""
train_losses = []
test_losses = []
for epoch in range(epochs):
self.model.train()
epoch_losses = []
for batch_idx, (X, y) in enumerate(train_loader):
X, y = X.to(self.device), y.to(self.device)
y_pred = self.model(X)
loss = self.loss_fn(y_pred, y)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
epoch_losses.append(loss.item())
train_loss = self.evaluate_model(train_loader)
test_loss = self.evaluate_model(test_loader)
train_losses.append(train_loss)
test_losses.append(test_loss)
# 使用回调函数更新进度
if progress_callback:
progress_callback(epoch, train_loss, test_loss)
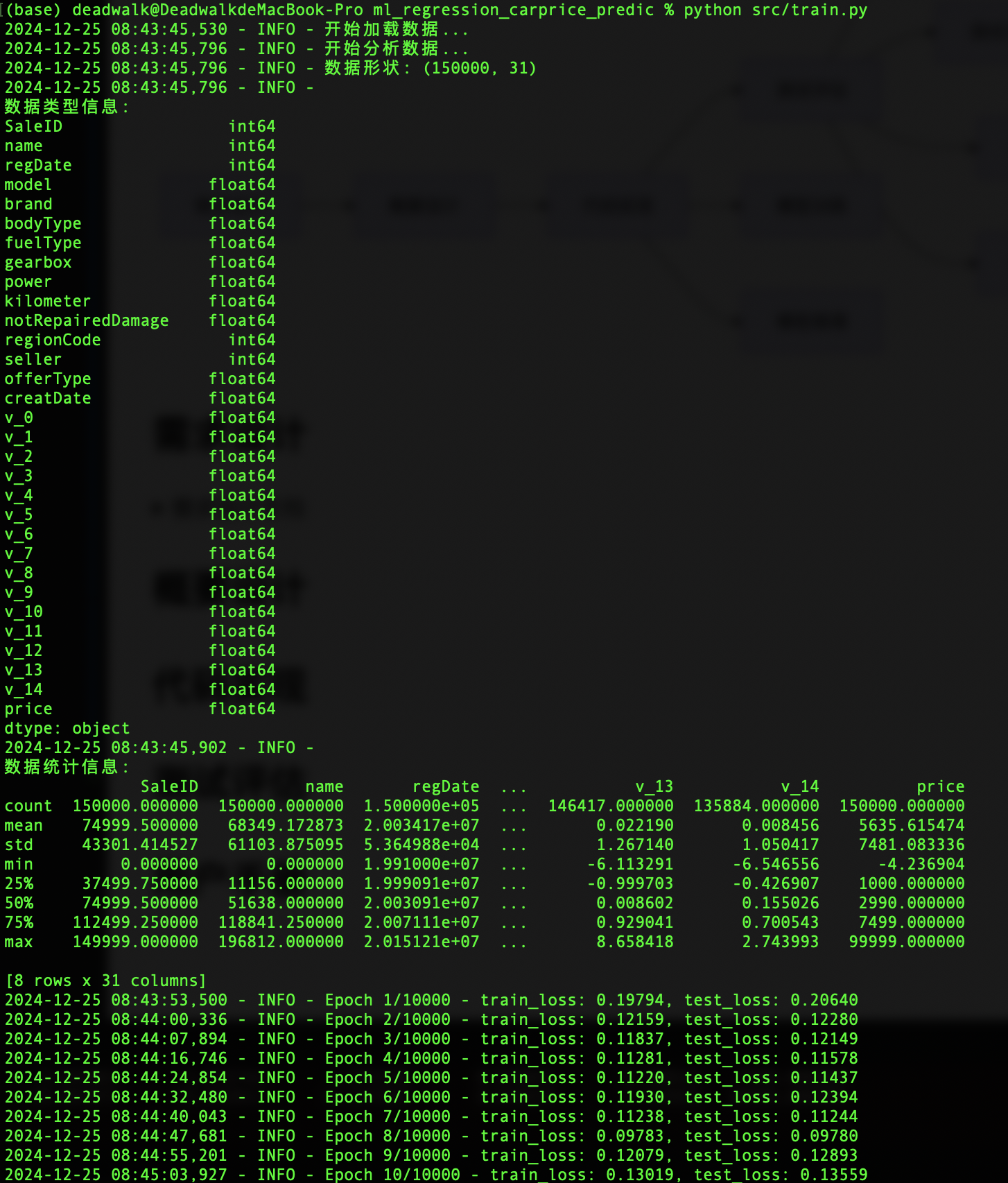
logging.info(f'Epoch {epoch+1}/{epochs} - train_loss: {train_loss:.5f}, test_loss: {test_loss:.5f}')
return train_losses, test_losses3.5 模型训练
在准备好相关的模型、数据集、数据加载器、训练器之后,我们就可以开始训练模型了。
训练过程主要是:
- 设置日志
- 数据处理
- 创建数据加载器
- 设置设备
- 初始化模型
- 设置训练参数
- 创建训练器并训练模型
代码文件:src/train.py
import os
import torch
import torch.nn as nn
from data_processing.data_processor import DataProcessor
from models.car_price_model import CarPriceModel
from datasets.car_price_dataset import create_data_loaders
from training.trainer import ModelTrainer
def train_car_price_model(data_input: str,
model_save_path: str = 'model.pth',
plot_save_path: str = 'loss_curve.png',
epochs: int = 10000,
learning_rate: float = 1e-4,
progress_callback=None):
# 数据处理
processor = DataProcessor()
# 根据输入类型处理数据
if isinstance(data_input, str):
# 如果输入是文件路径
X, y = processor.load_and_analyze_data(data_input)
else:
# 如果输入是DataFrame
X, y = processor.load_and_analyze_data(data_input)
X_train, X_test, y_train, y_test = processor.prepare_data(X, y)
# 创建数据加载器
train_loader, test_loader = create_data_loaders(X_train, X_test, y_train, y_test)
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 初始化模型
model = CarPriceModel(in_features=X_train.shape[1], out_features=1)
model = model.to(device)
# 设置训练参数
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 创建训练器并训练模型
trainer = ModelTrainer(model, loss_fn, optimizer, device)
train_losses, test_losses = trainer.train(
train_loader,
test_loader,
epochs,
progress_callback=progress_callback
)
# 保存模型和损失曲线
trainer.save_model(model_save_path)
trainer.plot_losses(train_losses, test_losses, plot_save_path)
return model, train_losses, test_losses, processor
if __name__ == "__main__":
current_dir = os.getcwd()
data_path = os.path.join(current_dir, 'data', 'used_car_train_20200313_cleaned.csv')
model, train_losses, test_losses = train_car_price_model(data_path)备注:
used_car_train_20200313_cleaned.csv是经过数据处理后的数据,包含特征和目标变量。model.pth是训练完成之后,保存的模型,保存了模型的参数。loss_curve.png是训练过程中,训练损失和测试损失的变化曲线图。
运行结果:
4. 模型推理
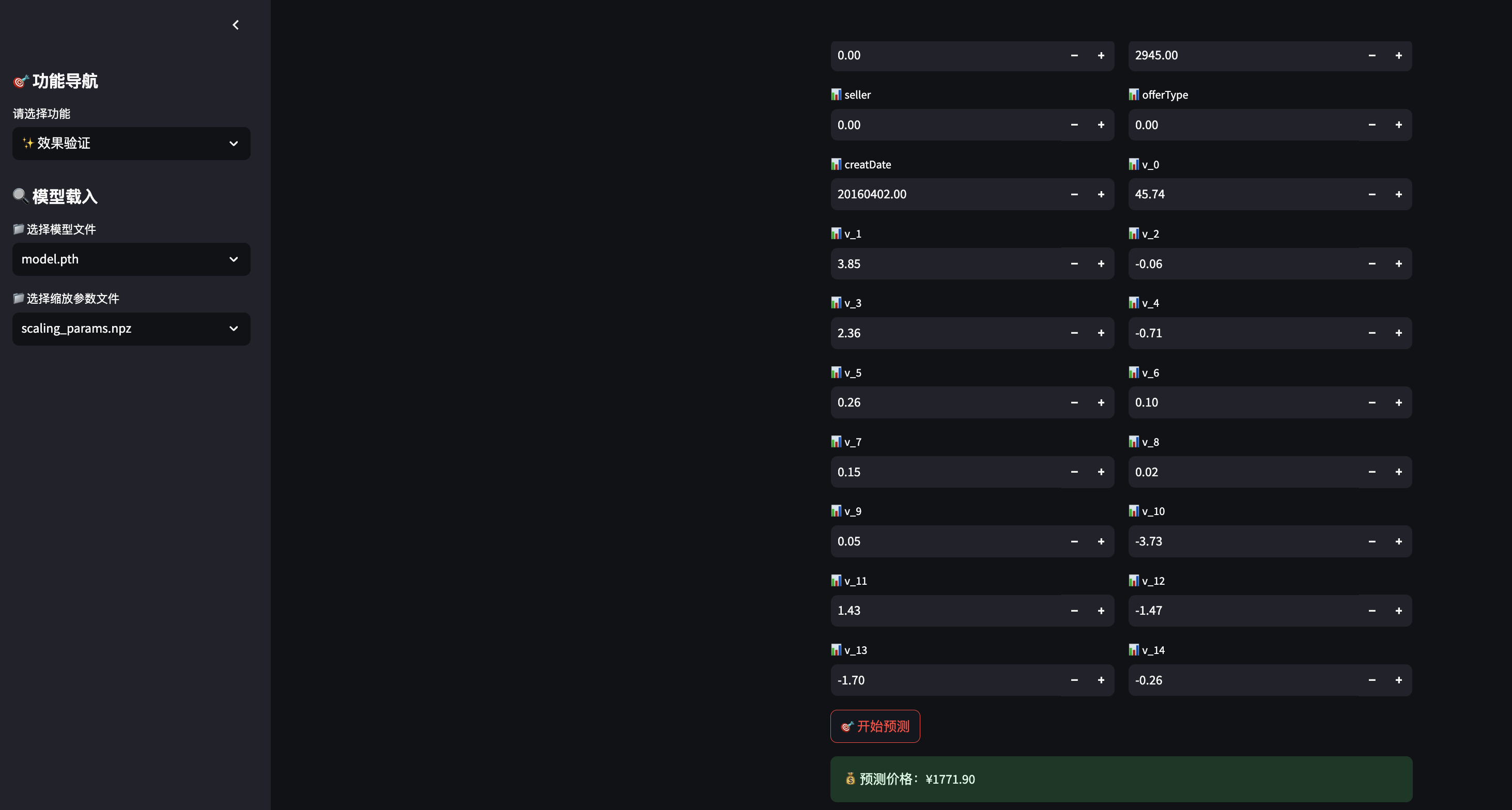
为了便于模型推理演示,我们通过streamlit创建一个web应用,用于展示模型推理过程。
由于该过程涉及较为繁琐的代码重构以及streamlit调试,详细过程不再赘述。
运行效果:
项目资料
为了便于后续的深度学习中级认证考试,本次我们也将项目相关资料进行梳理,以供参考。
- 需求设计文档
- 概要设计文档
- 测试方案文档
- 测试报告文档
- 用户手册文档
需求设计文档
引言
编写目的
本需求规格说明书旨在明确二手车价格预测模型项目的目标、需求和实现方案。通过详细描述项目的背景、功能需求、非功能需求及相关约束条件,为项目的开发、测试和后续维护提供清晰的指导。文档将作为项目团队、利益相关者和用户之间的沟通桥梁,确保各方对项目目标和实施方案的理解一致。
项目背景
随着二手车市场的快速发展,消费者在购买二手车时面临着价格不透明的问题。传统的价格评估方法往往依赖于经验和市场行情,缺乏科学依据。通过深度学习技术,可以有效地分析历史交易数据,提取车辆特征与价格之间的关系,从而实现对二手车价格的准确预测。该项目旨在构建一个基于深度学习的二手车价格预测模型,帮助消费者做出更明智的决策,提升二手车交易的透明度和效率。
术语定义和缩写语
- 深度学习(Deep Learning):一种机器学习方法,通过多层神经网络对数据进行特征提取和模式识别。
- 二手车(Used Car):已经被购买并再次出售的汽车。
- 价格预测(Price Prediction):根据输入特征(如品牌、型号、年份等)预测商品的市场价格。
- 数据预处理(Data Preprocessing):对原始数据进行清洗、转换和整理的过程,以便于后续分析和建模。
- 探索性数据分析(Exploratory Data Analysis, EDA):对数据集进行初步分析,以发现数据的特征、模式潜在问题。
- 模型训练(Model Training):使用训练数据对机器学习模型进行学习的过程,以优化模型参数。
参考资料
- 在线资源:
- CSDN:超全总结!探索性数据分析 (EDA)方法汇总!
- 阿里天池数据集下载
- 工具和库:
- ydata-profiling:用于自动化生成数据集的详细报告的Python库。
- pandas:用于数据处理和分析的Python库。
- PyTorch:用于深度学习的开源框架。
任务概述
建设目标
本项目旨在构建一个基于深度学习的二手车价格预测模型,能够根据车辆的各项特征(如品牌、型号、年份、里程等)准确预测其市场价格。
建设内容
本项目旨在构建一个基于深度学习的二手车价格预测模型,具体建设内容包括:
-
数据处理:
- 二手车交易数据,进行可视化数据分析、数据清洗、缺失值处理和异常值检测。
- 进行数据预处理,包括特征选择、特征工程和数据标准化。
-
模型构建与训练:
- 设计并实现深度学习模型,选择合适的网络结构(如全连接神经网络)。
- 使用训练集对模型进行训练,并通过验证集调整超参数。
-
模型评估与优化:
- 评估模型性能,使用均方误差(MSE)等指标进行评估。
- 根据评估结果进行模型优化,提升预测准确性。
-
模型推理与应用:
- 实现模型推理功能,能够根据用户输入的车辆特征预测价格。
- 开发Web应用(如使用Streamlit)展示模型推理结果,提供用户友好的界面。
-
文档与用户手册:
- 编写项目文档,包括需求规格说明书、设计文档和用户手册。
- 提供详细的使用说明和示例,帮助用户理解和使用模型。
功能需求
-
需求编号:FR1
需求内容:数据处理功能
需求描述:- 能够读取多种格式的二手车数据(如CSV)。
- 自动检测并处理缺失值和异常值。
- 提供数据可视化功能,展示数据分布和特征关系。
-
需求编号:FR2
需求内容:模型训练功能
需求描述:- 支持全连接神经网络深度学习模型的训练。
- 提供超参数调整功能,支持不同的学习率、批次大小等设置。
- 能够保存和加载训练好的模型。
- 能够保存训练过程中的损失曲线。
- 能够实时显示训练过程中的损失变化。
-
需求编号:FR3
需求内容:模型推理功能
需求描述:- 根据用户输入的车辆特征(如品牌、型号、年份等)进行价格预测。
- 提供预测结果的可视化展示,帮助用户理解预测结果。
-
需求编号:FR4
需求内容:用户界面功能
需求描述:- 提供友好的Web界面,用户可以方便地输入车辆特征并获取预测结果。
- 显示模型的性能指标和预测结果的置信区间。
性能需求
-
需求编号:PR1
需求内容:预测准确性
需求描述:-
本项目的预测准确性将通过均方误差(Mean Squared Error, MSE)来评估。MSE是衡量预测值与实际值之间差异的常用指标,其计算公式为:
MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2其中,(y_i) 是实际值,(\hat{y}_i) 是预测值,(n) 是样本数量。
-
在本项目中,MSE的取值范围设定在0.01到0.1之间。具体来说:
- 当MSE小于0.01时,表示模型的预测非常准确,能够很好地拟合数据。
- 当MSE在0.01到0.1之间时,表示模型的预测效果良好,能够接受。
- 当MSE大于0.1时,表示模型的预测效果较差,需要进一步优化。
-
为了确保模型的预测准确性,我们将采用以下评估方法:
- 交叉验证:使用K折交叉验证方法,将数据集分为K个子集,依次使用每个子集作为测试集,其余子集作为训练集,计算每次的MSE,最终取平均值作为模型的评估指标。
- 训练集与测试集划分:将数据集划分为训练集和测试集,通常采用80%作为训练集,20%作为测试集。训练模型后,在测试集上计算MSE,以评估模型的泛化能力。
- 可视化分析:通过绘制预测值与实际值的散点图,观察模型的预测效果,进一步分析MSE的合理性。
-
通过以上评估方法,我们将确保模型的预测准确性达到预期标准,并为后续的模型优化提供依据。
-
-
需求编号:PR2
需求内容:响应时间
需求描述:- 模型推理的响应时间应小于2秒,确保用户体验流畅。
-
需求编号:PR4
需求内容:可扩展性
需求描述:- 系统应支持后续功能扩展,如增加新的特征、支持更多数据源等。
用户界面需求
-
需求编号:UIR1
需求内容:输入界面
需求描述:- 提供简洁明了的输入表单,用户可以输入车辆的各项特征(如品牌、型号、年份、里程等)。
- 输入框应具备数据验证功能,确保用户输入的格式正确。
-
需求编号:UIR2
需求内容:结果展示
需求描述:- 显示预测结果,包括预测价格和相关的置信区间。
- 提供可视化图表,展示预测结果与实际价格的对比。
-
需求编号:UIR3
需求内容:用户反馈
需求描述:- 提供反馈机制,用户可以对预测结果进行评价,帮助改进模型。
-
需求编号:UIR4
需求内容:帮助文档
需求描述:- 提供在线帮助文档,用户可以随时查看使用说明和常见问题解答。


