
前言
本文将介绍如何在趋动云平台上使用xinference部署对话模型、向量化模型以及多模态模型。
xinference简介
xinference官网
官网说明:https://inference.readthedocs.io/zh-cn/latest/getting_started/installation.html
xinference可以部署的模型类别
- chat对话模型
- embedding向量化模型
- rerank模型
- vl-chat多模态模型
环境准备
选择镜像
- 选择镜像环境
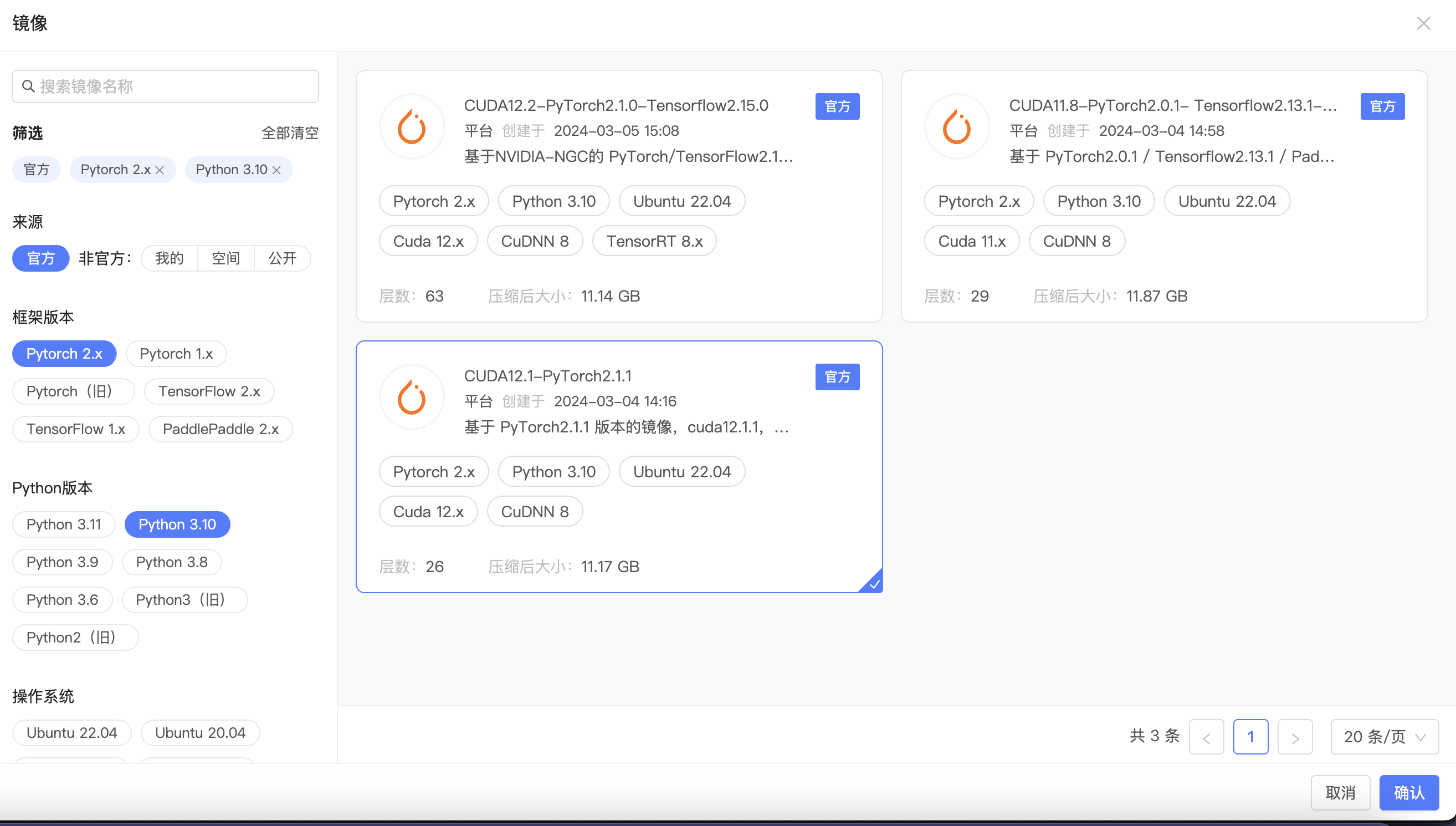
安装xinference
xinference支持的引擎有:
- transformers
- vllm
- llama.cpp
- SGlong引擎
…..
本篇文章,我们尝试使用transformers引擎,部署Qwen2-0.5B-Instruct对话模型。
# 安装transformers引擎
pip install "xinference[transformers]"
# 安装sentence-transformers
pip install sentence-transformers
部署chat对话模型
下载模型
切换至/gemini/code目录下,下载模型:
git lfs install
git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git注意事项:
此处也可以在启动项目时,选择模型加载,在趋动云的公共模型中选择Qwen2.5-0.5B-Instruct模型。
启动xinference
-
在命令行中启动
supervisor进程:xinference-supervisor -H 0.0.0.0运行结果:
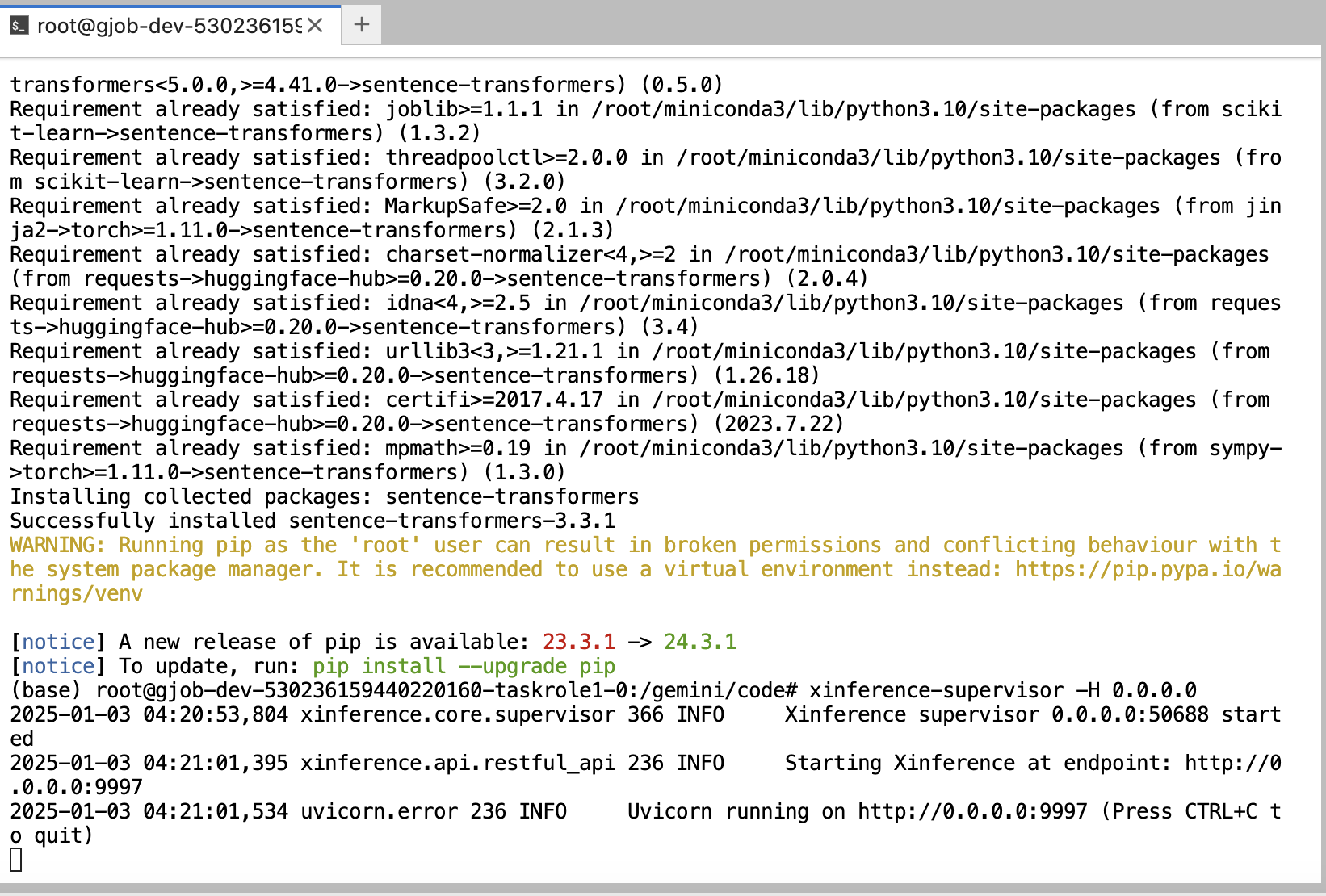
-
新建一个terminal,启动
Worker进程:xinference-worker -e http://127.0.0.1:9997 -H 0.0.0.0运行结果:
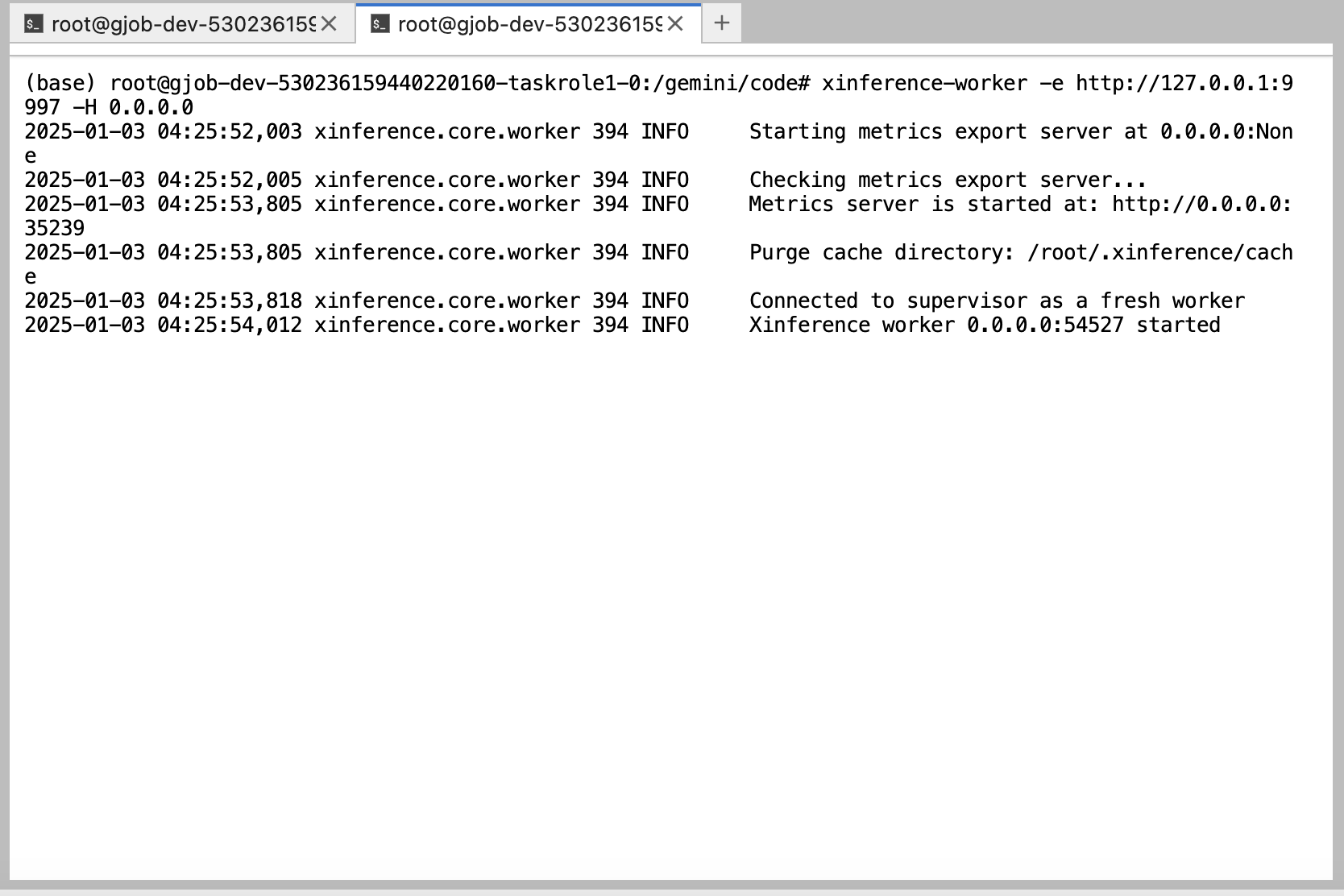
此处的
9997应该与supervisor启动时指定的端口一致。
端口映射
在趋动云控制台的右侧"端口",添加端口映射如下:
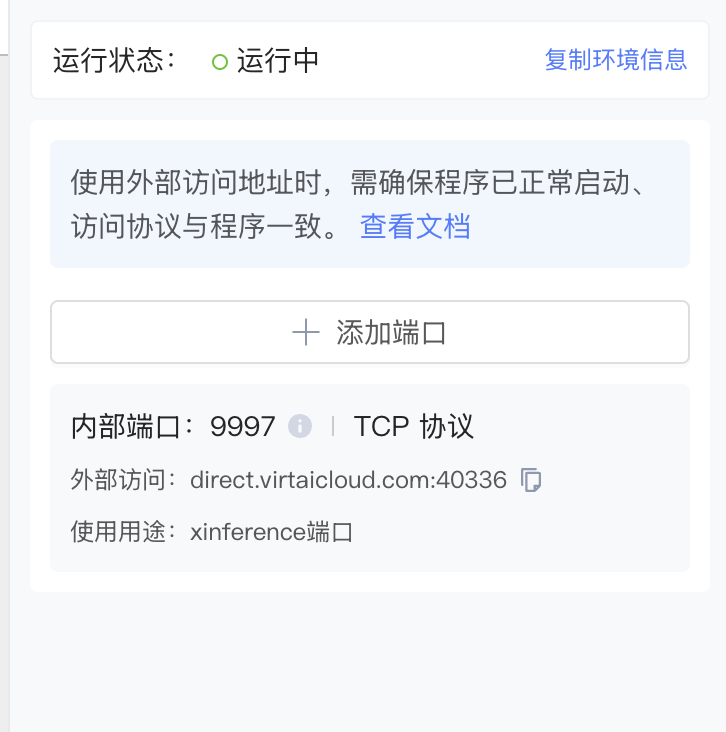
启动对话模型
- 浏览器访问http://direct.virtaicloud.com:40336
http://direct.virtaicloud.com:40336是上一步端口映射后,趋动云提供的外网访问地址。
-
在
language models选择chat模型,并搜索qwen2.5模型
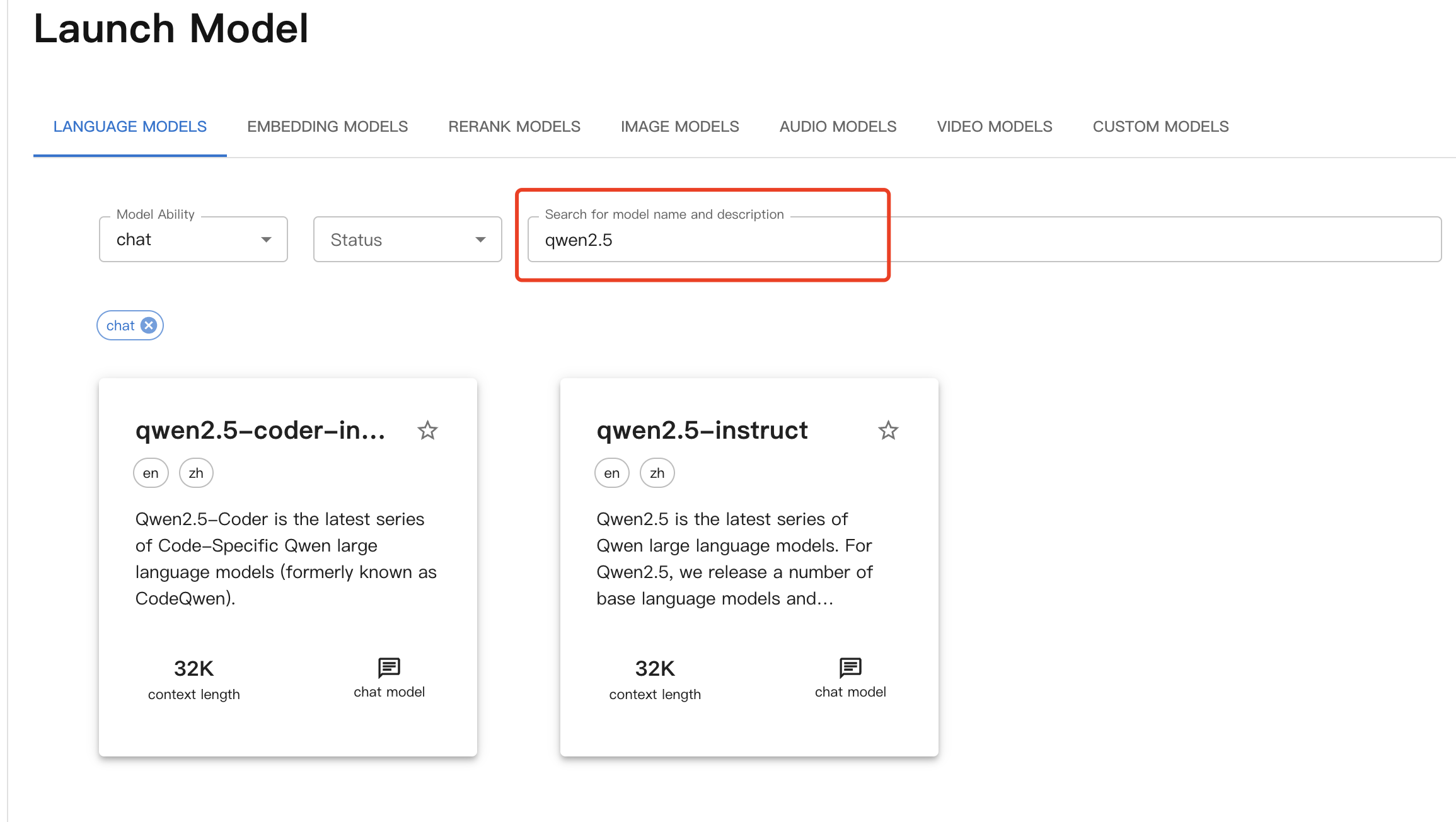
-
使用pwd命令获取趋动云上已下载Qwen模型的的绝对路径
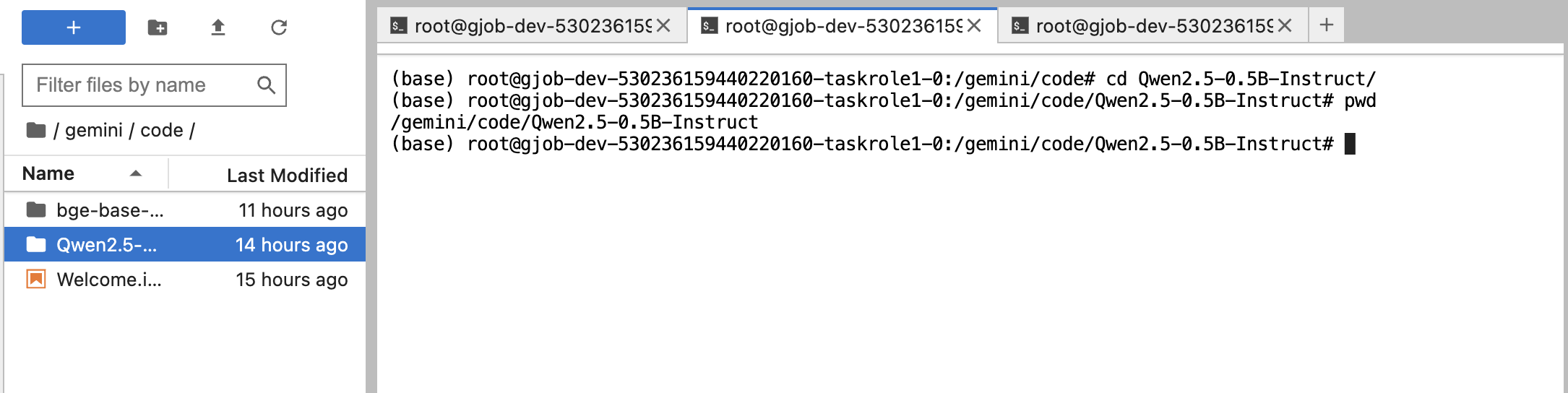
-
配置模型必选参数
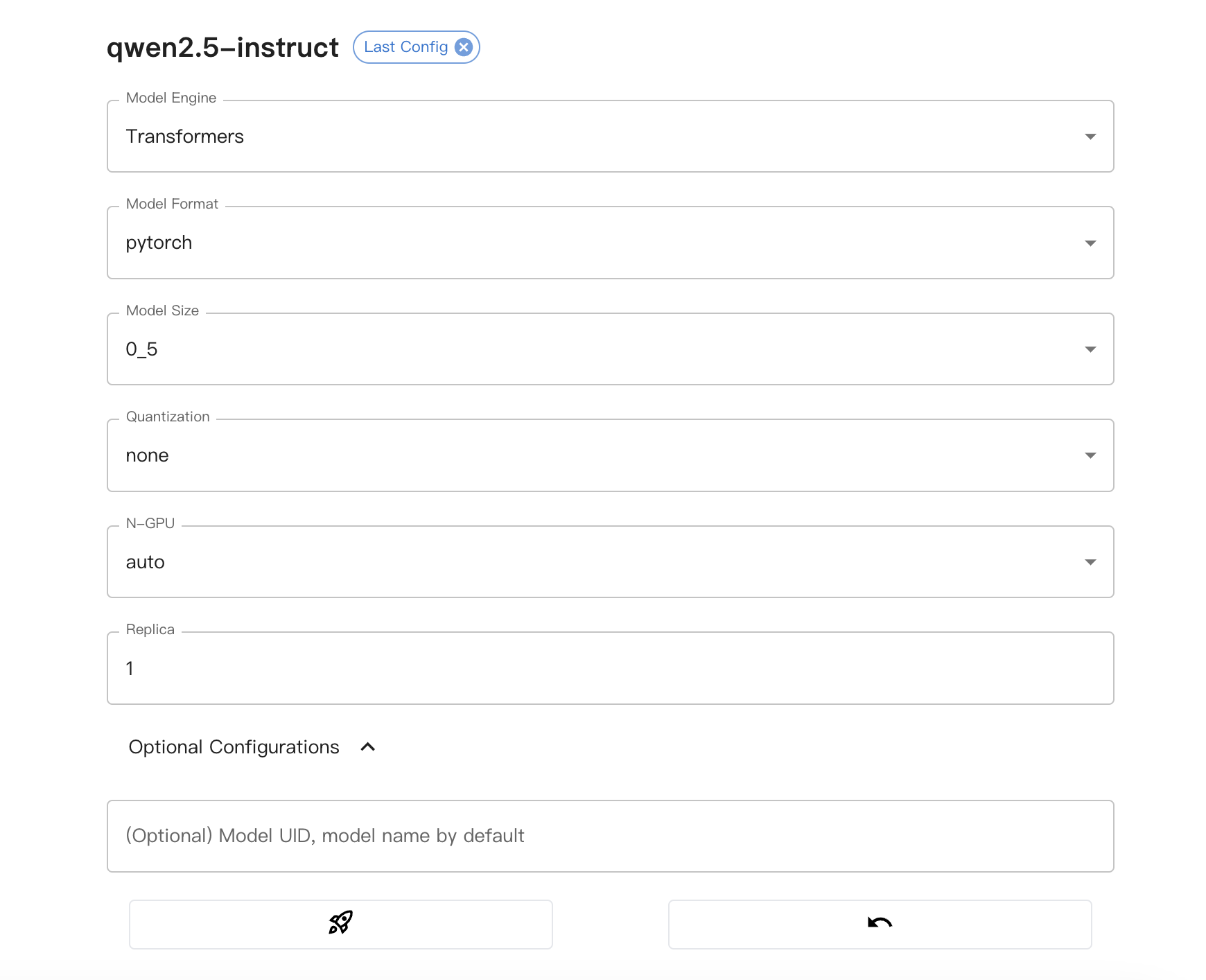
注意事项:
因为我们下载的模型为Qwen2.5-0.5B-Instruct,所以Model size为0_5,此处应根据实际情况选择。
- 配置模型路径
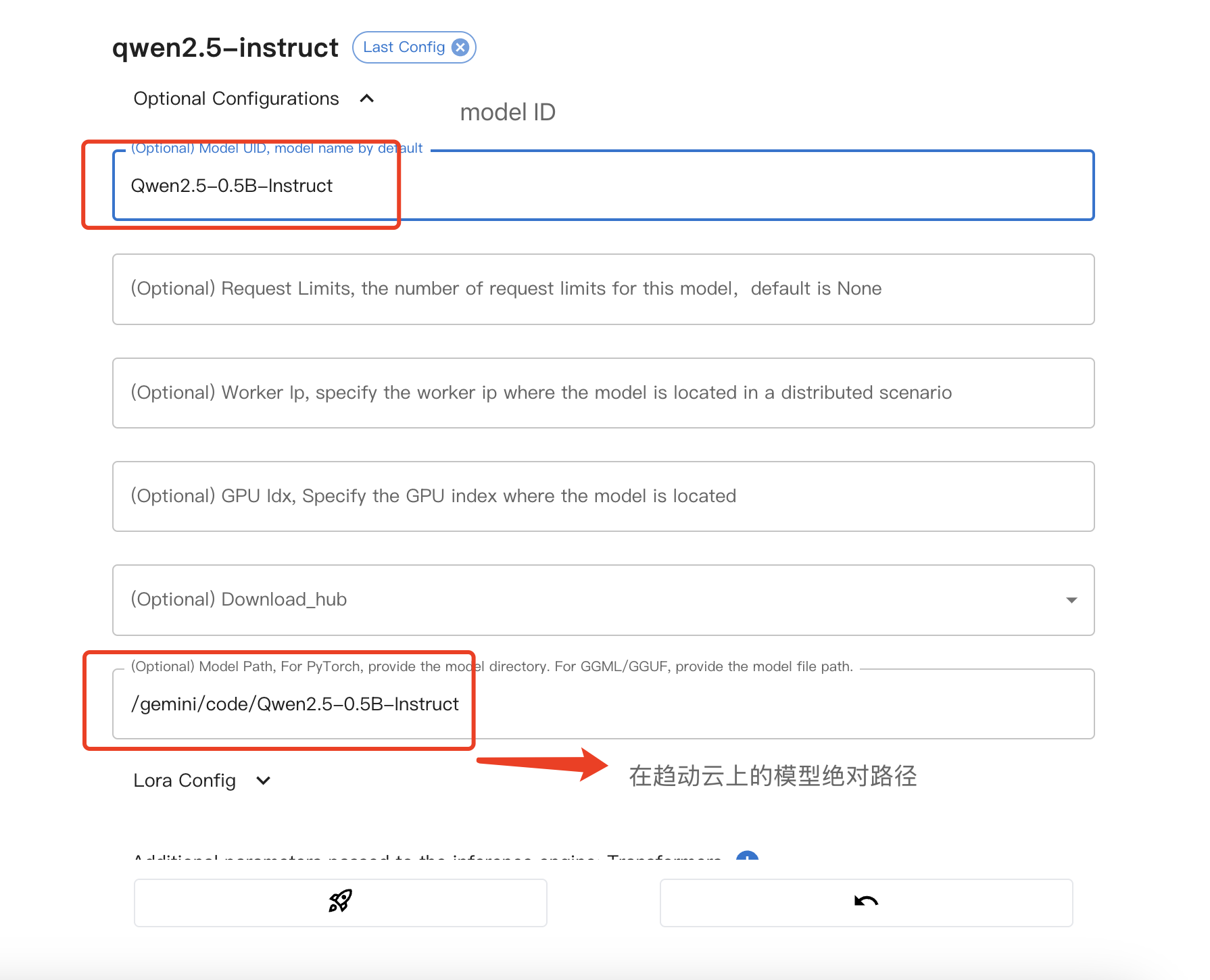
注意事项:
- Model path为上述第3步中获取的模型在趋动云上的绝对路径。
- Model UID用于后续调用使用,此处我们配置为
Qwen2.5-0.5B-Instruct。如果不配置的话,会使用默认的Model UID,在后续调用时注意调用代码中的传参内容。
- 点击启动,稍后片刻,页面会显示启动成功后的内容。

调用验证
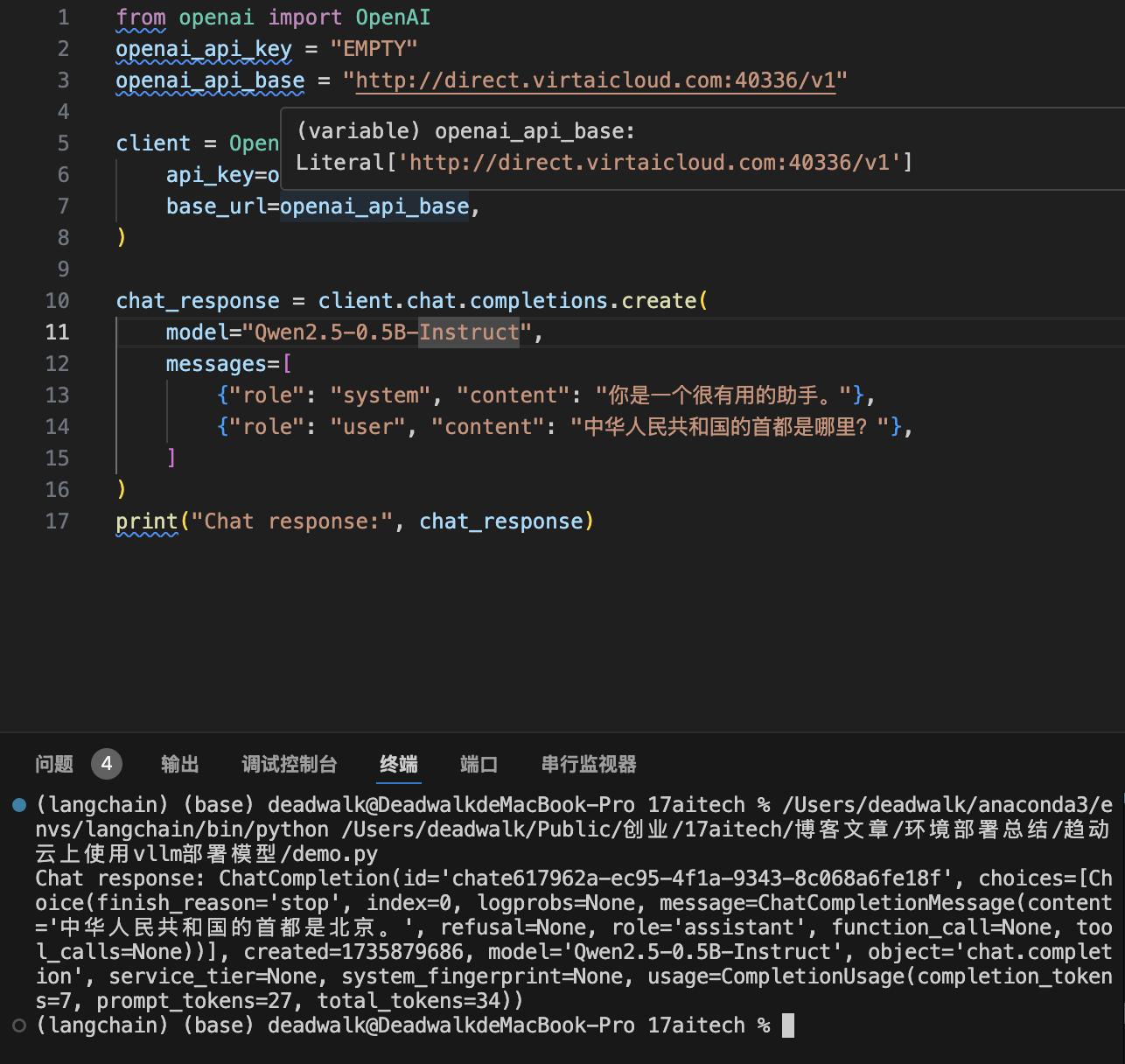
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://direct.virtaicloud.com:40336/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen2.5-0.5B-Instruct",
messages=[
{"role": "system", "content": "你是一个很有用的助手。"},
{"role": "user", "content": "中华人民共和国的首都是哪里?"},
]
)
print("Chat response:", chat_response)
运行结果:
注意事项:
- 示例中,
openai_api_base需要配置映射端口后的地址,读者需要根据实际情况修改。- 示例中,
model="Qwen2.5-0.5B-Instruct"要与在xinference中配置Model UID的内容一致。
部署chat对话模型(微调训练过的)
下载模型
此处,我们在趋动云启动时,选择曾经微调的一个医疗大模型Qwen2-7B-final并加载。
备注说明:
该模型是之前我微调过的一个医疗大模型,具体微调过程请见【课程总结】day24(上):大模型三阶段训练方法(LLaMa Factory)。
启动模型
-
在Launch页面,选择
chat并搜索qwen2,选择qwen2-instruct。 -
配置模型必选参数:
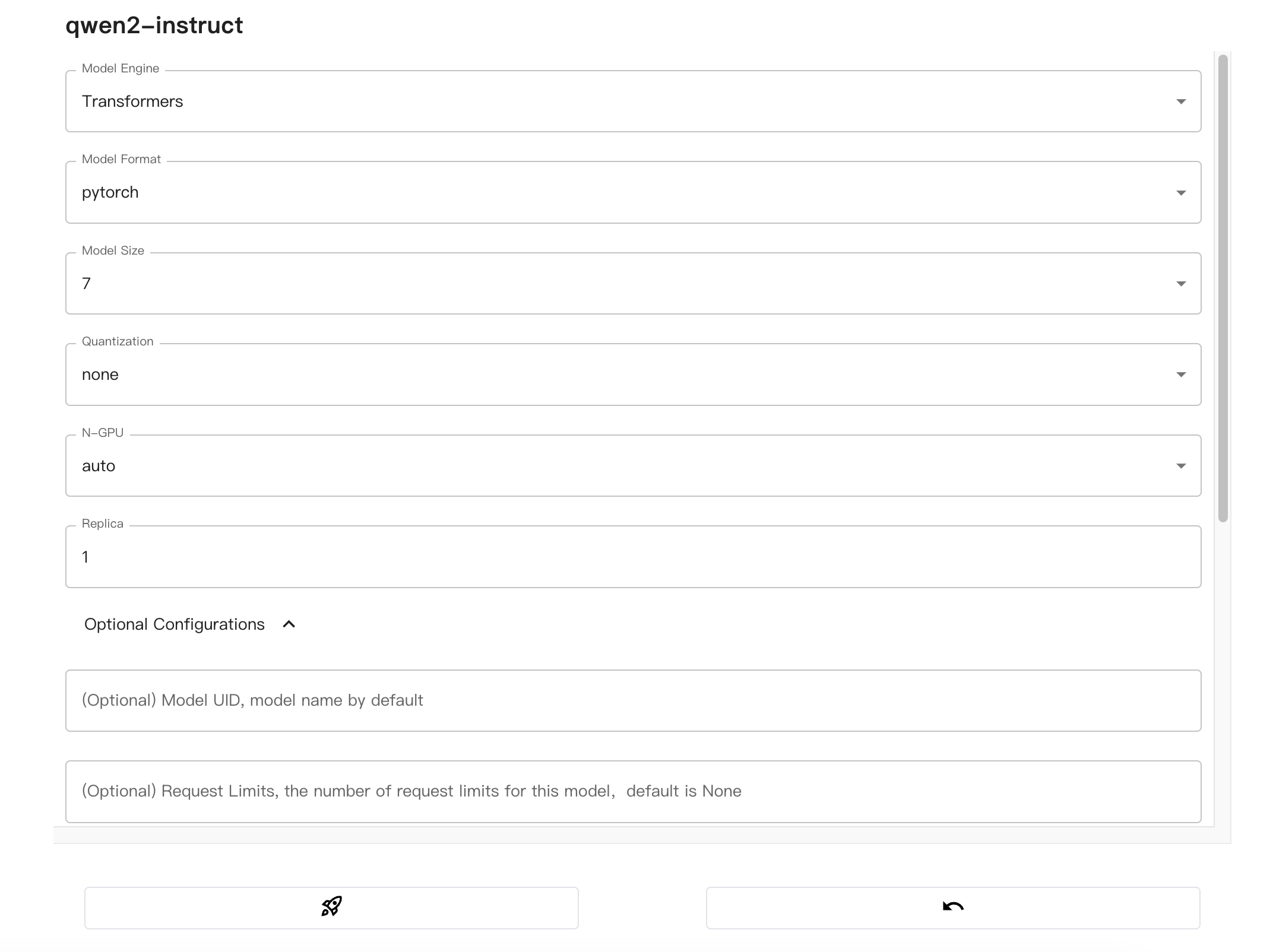
-
配置模型路径:
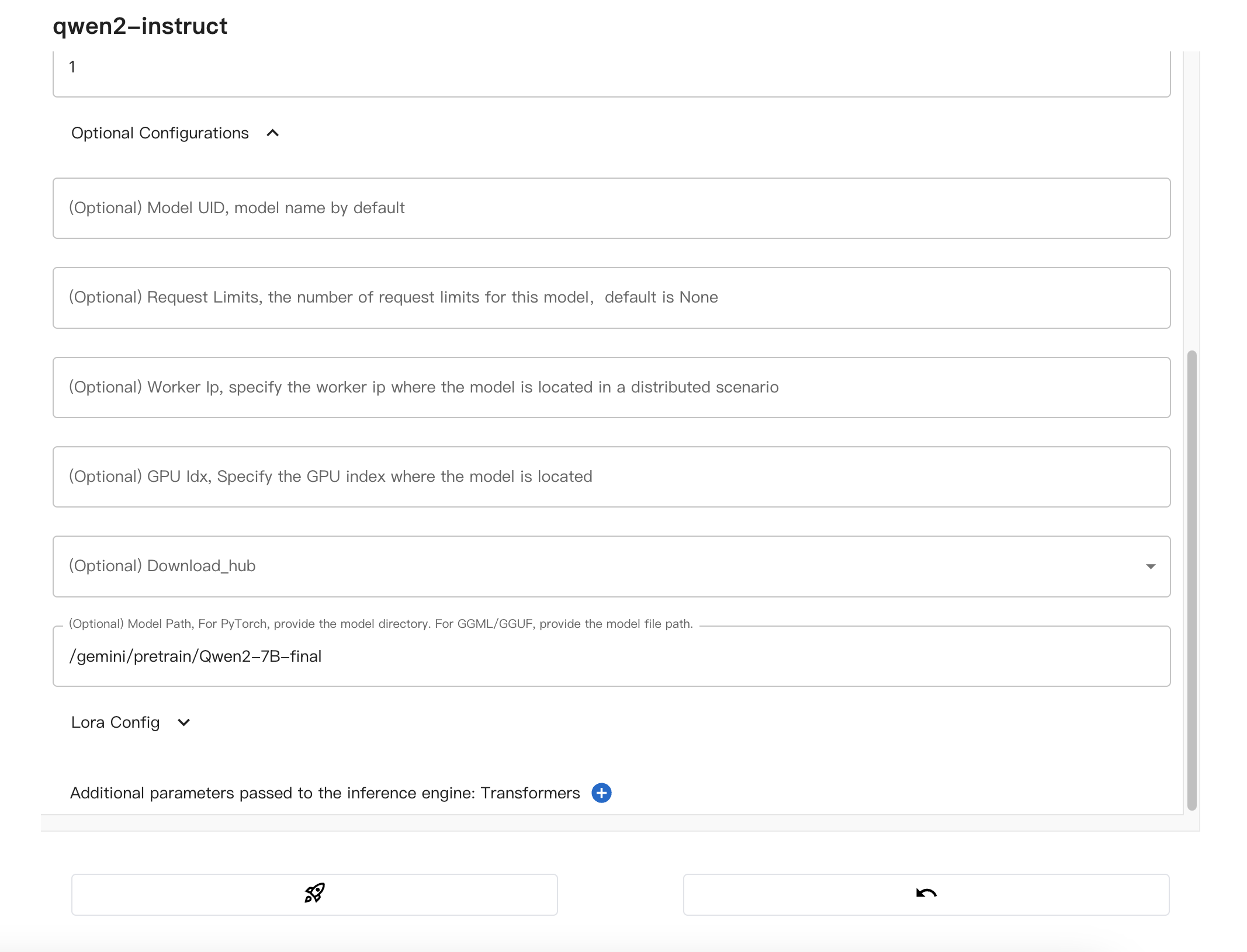
注意事项:
- 该模型是基于
Qwen2-7B-instruct微调的,所以Model size选择7_0。- 该模型在趋动云上的绝对路径为:
/gemini/pretrain/Qwen2-7B-final。
- 点击启动,稍后片刻,页面会显示启动成功后的内容。

调用验证
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://direct.virtaicloud.com:40336/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="qwen2-instruct",
messages=[
{"role": "system", "content": "你是一个很有用的助手。"},
{"role": "user", "content": "我最近失眠比较厉害,请问应该如何诊治?"},
]
)
print("Chat response:", chat_response)运行结果:
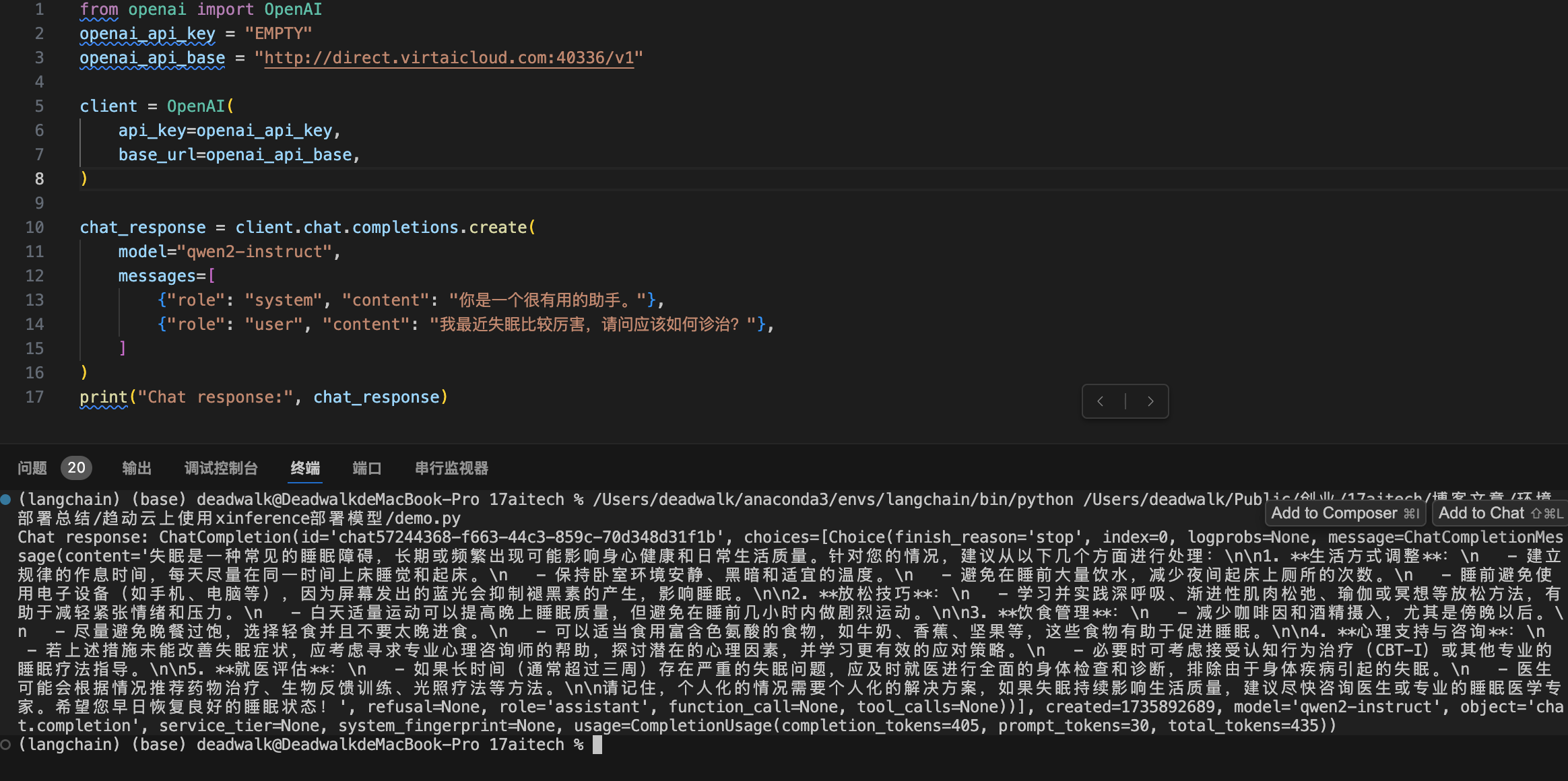
注意事项:
示例中,model="qwen2-instruct"要与在xinference中配置Model UID的内容一致。
部署embeddign模型
- 前置步骤与部署chat模型的操作一致,只是配置Model UID和Model Path时 略有不同。
- 此处内容在Xinference部署向量化模型已做详细说明,不再赘述。
部署vl-chat多模态模型
前置步骤与部署chat模型的操作一致,此处不再赘述。
下载模型
此处,我们在趋动云启动时,在模型广场搜索Qwen-VL-chat并加载。
备注说明:
该模型是在趋动云模型广场搜索的一个Qwen的多模态大模型。
启动模型
-
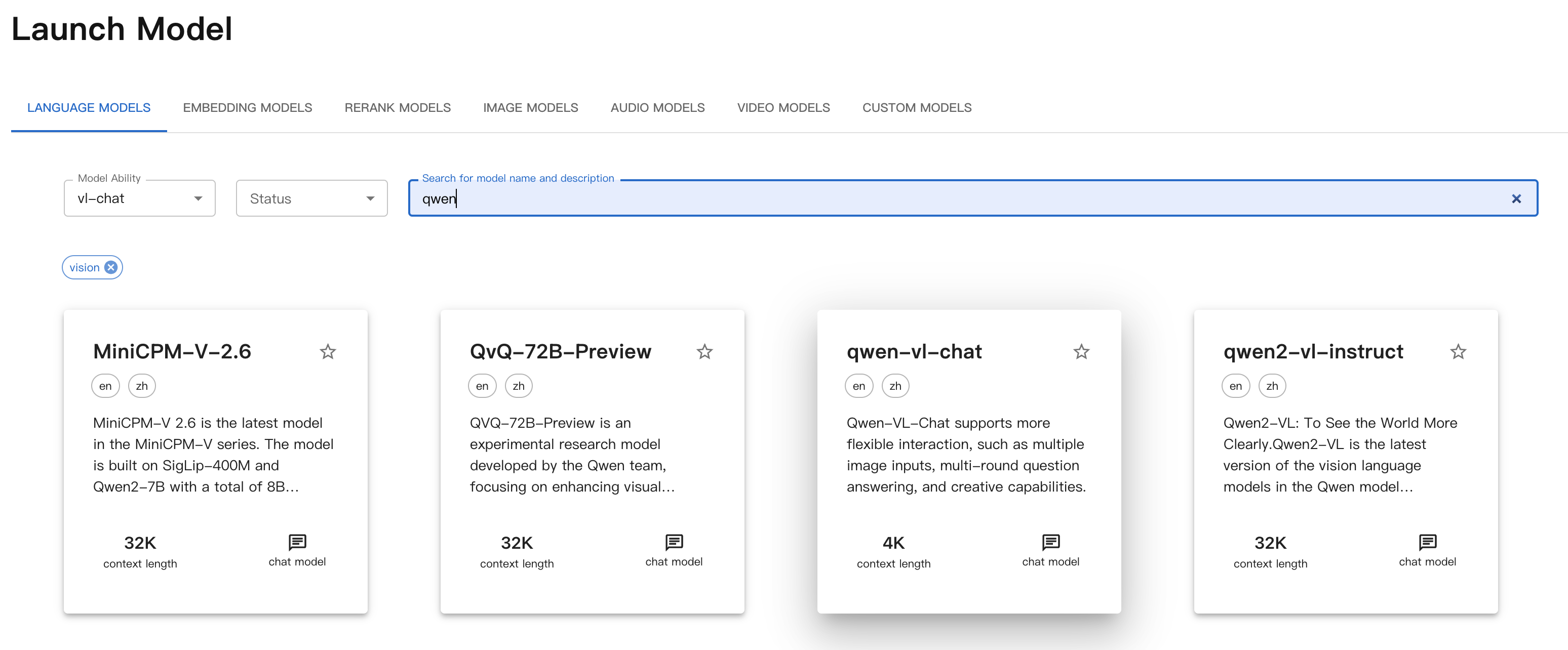
在Launch页面,选择
vl-chat并搜索qwen。
-
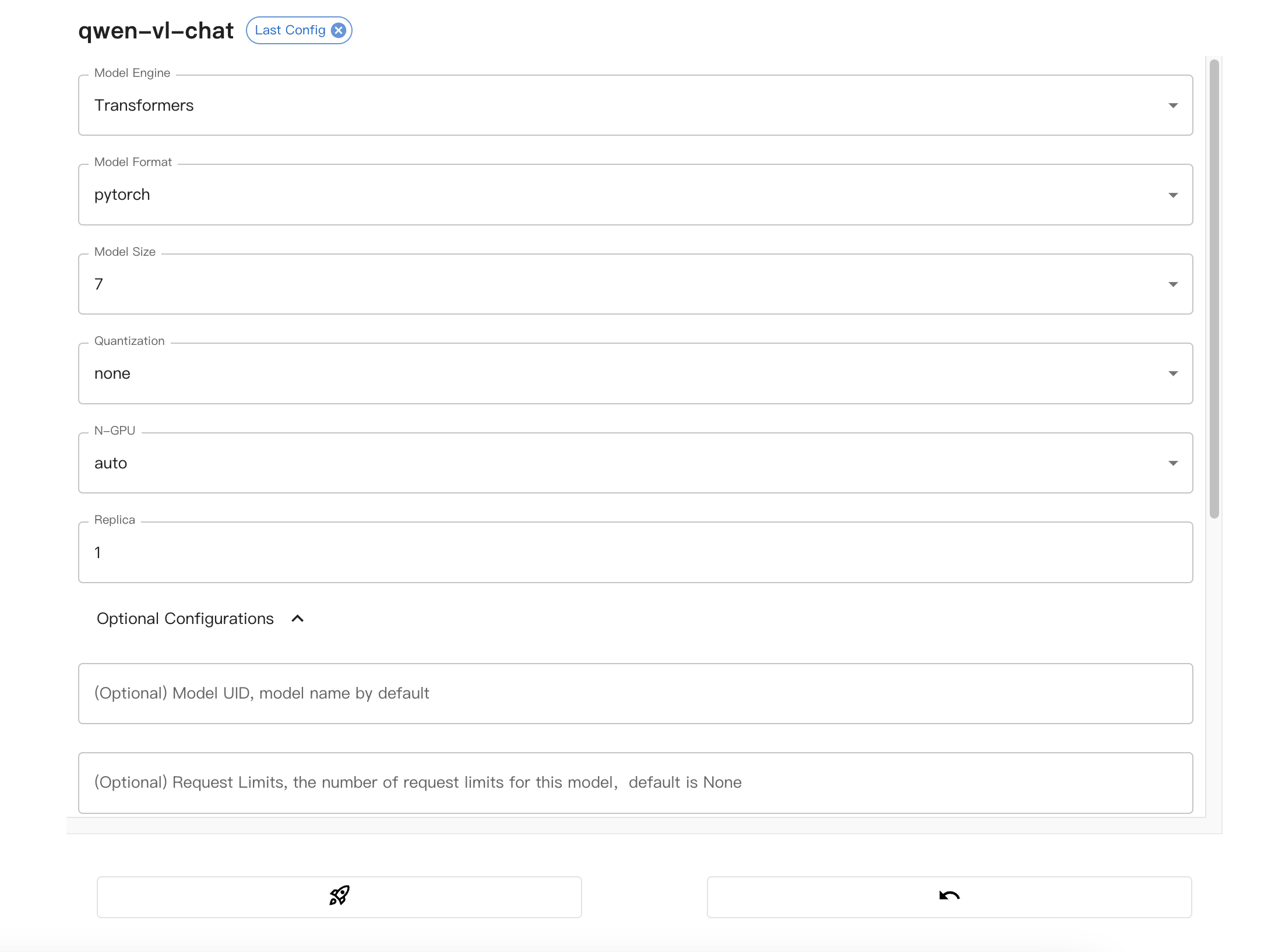
配置模型必选参数:
-
配置模型路径:
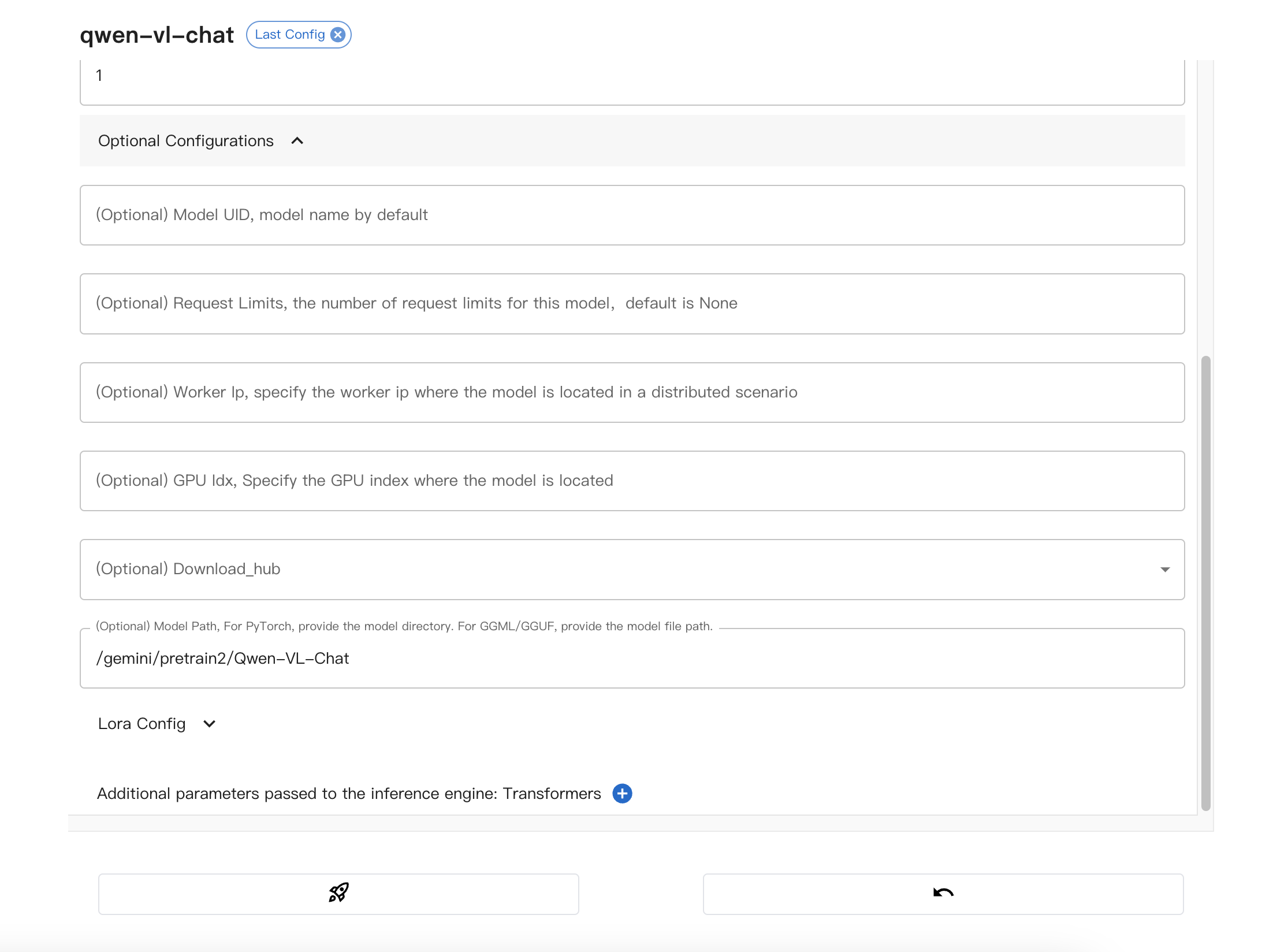
注意事项:
该模型在趋动云上的绝对路径为:/gemini/pretrain2/Qwen-VL-Chat。
- 点击启动,稍后片刻,页面会显示启动成功后的内容。

调用验证
from openai import OpenAI
import base64
# 配置OpenAI客户端
openai_api_key = "EMPTY"
openai_api_base = "http://direct.virtaicloud.com:40336/v1" # 请根据实际端口映射地址修改
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
def encode_image_to_base64(image_path):
"""将图片转换为base64编码"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def chat_with_image(image_path, prompt):
"""与多模态模型对话"""
# 将图片转换为base64
base64_image = encode_image_to_base64(image_path)
messages=[
{
"role": "user",
"content": [
{"type":"text", "text":prompt},
{
"type":"image_url",
"image_url":{
"url":f"data:image/png;base64,{base64_image}"
}
}
]
}
]
# 调用模型
# try:
response = client.chat.completions.create(
model="qwen-vl-chat", # 使用部署的多模态模型名称
messages=messages,
max_tokens=1024,
temperature=0.7,
response_format={"type": "text"} # 指定响应格式为文本
)
return response.choices[0].message.content
# except Exception as e:
# return f"调用出错: {str(e)}"
if __name__ == "__main__":
# 测试调用
image_path = "./脑部CT.png" # 替换为实际的图片路径
prompt = "这张图片中有什么内容?请详细描述。"
result = chat_with_image(image_path, prompt)
print("模型回复:", result)
图片内容:
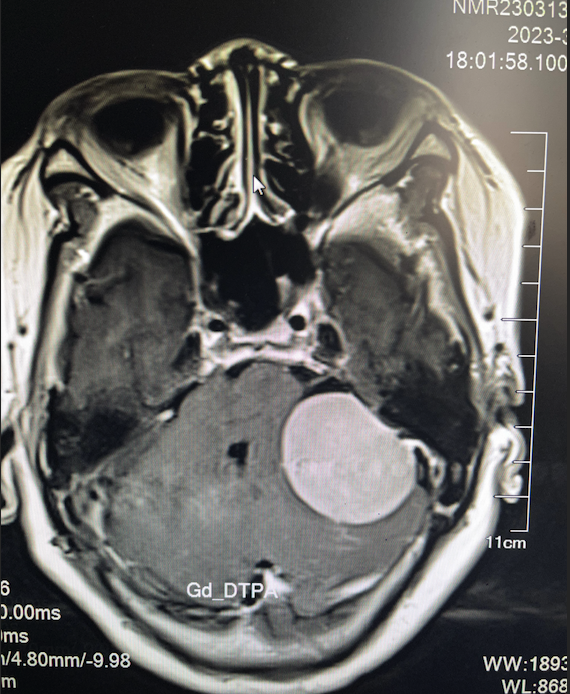
运行结果:
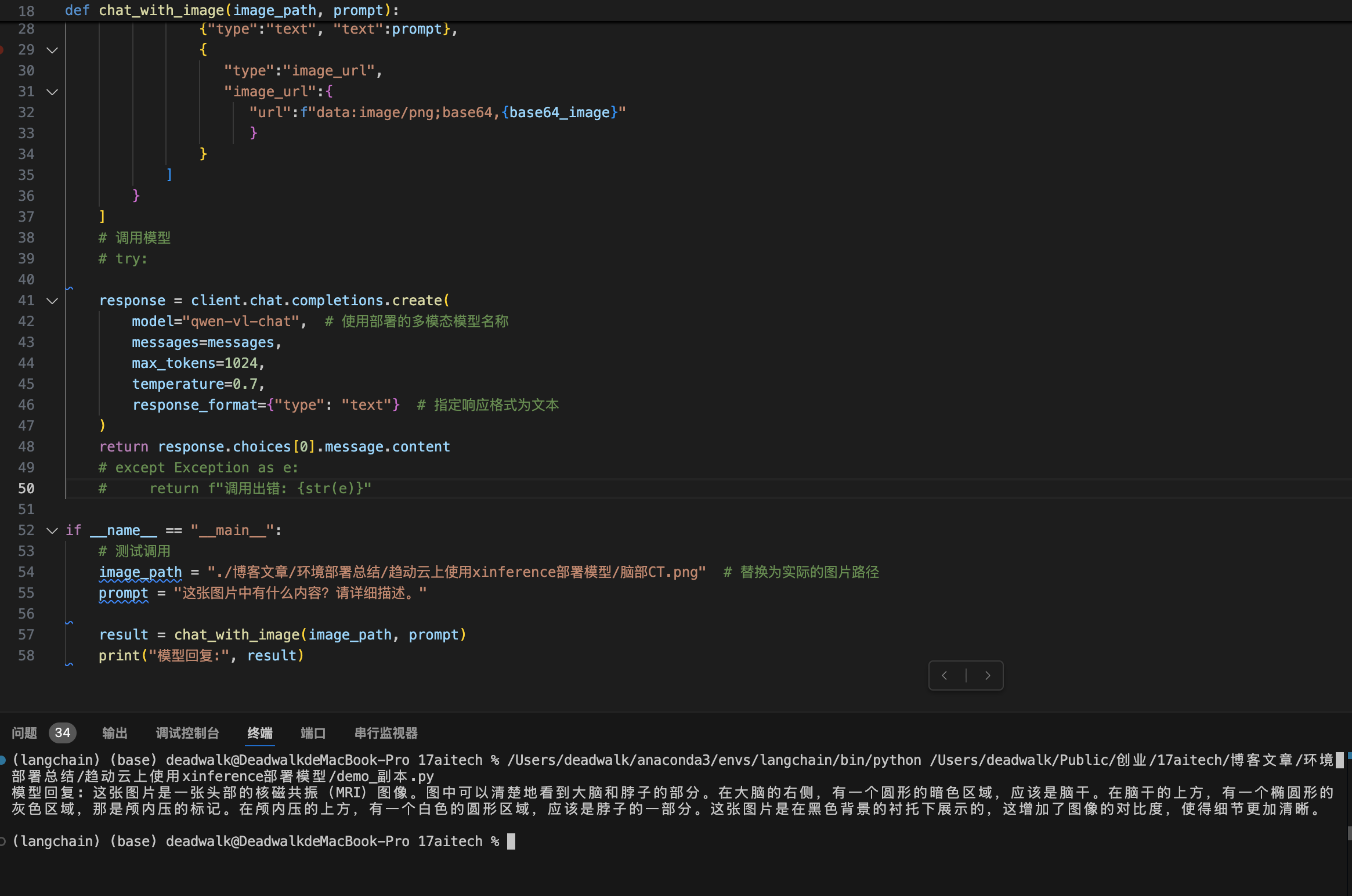
常见问题
- 问题1:Qwen2-vl-chat模型部署后,调用时报错:
ValueError: No chat template is set for this processor.。
问题原因:查看Xinference的日志,提示不支持Qwen2-vl模型。
该系列文章
- 【模型部署】在AutoDL上使用Xinference部署模型
- 【模型训练】在AutoDL上使用LLamaFactory进行模型训练
- 【模型部署】在趋动云上使用xinference部署模型
- 【模型部署】在趋动云上使用vllm部署模型
欢迎关注公众号以获得最新的文章和新闻



