文章来源于互联网:字节音乐大模型炸场!Seed-Music发布,支持一键生成高质量歌曲、片段编辑等
高质量音乐生成、高灵活音乐编辑,Seed-Music 再次打开了 AI 音乐创作的天花板。
放假期间,本 i 人又领教了被 e 人支配的恐惧。
跟 e 人朋友出门玩,先被拉去饭局尬聊,再和陌生人组队打本,下面这首歌真是唱出了 i 人心声。 后两天假期就舒服多了。通关了黑神话悟空还不过瘾,我在家补经典 86 版的《西游记》。无论多少次重温,还是会被大圣的魅力吸引。
后两天假期就舒服多了。通关了黑神话悟空还不过瘾,我在家补经典 86 版的《西游记》。无论多少次重温,还是会被大圣的魅力吸引。 
Seed-Music 官网:https://team.doubao.com/seed-music
-
音乐信号的复杂性:音乐信号包含多个重叠音轨、丰富的音调和音色以及广泛的频率带宽,不仅要保持短期旋律的连贯性,还要在长期结构上展现出一致性。 -
评估标准的缺乏:音乐作为一种开放、主观的艺术形式,缺乏一套通用的问题表述和用于比较的黄金指标,评估局限性大。 -
用户需求的多样性:不同的用户群体,如音乐小白、音乐初学者、资深音乐人等,对音乐创作的需求差异很大。





-
论文:《Seed-Music: Generating High-Quality Music in a Controlled Way》 -
技术报告地址:https://arxiv.org/pdf/2409.09214
-
提出了一种基于新型 token 和语言模型(LM)的方法,并引入了一种能够根据不同类型用户输入生成专业生成内容(PGC)质量音乐的训练方法。 -
提出了一种全新的基于扩散模型的方法,特别适合音乐编辑。 -
引入了一种在歌唱声音背景下的零样本声音转换的新颖方法。系统可以根据用户短至 10 秒的参考歌唱或甚至普通语音的音色生成完整的声乐混音。
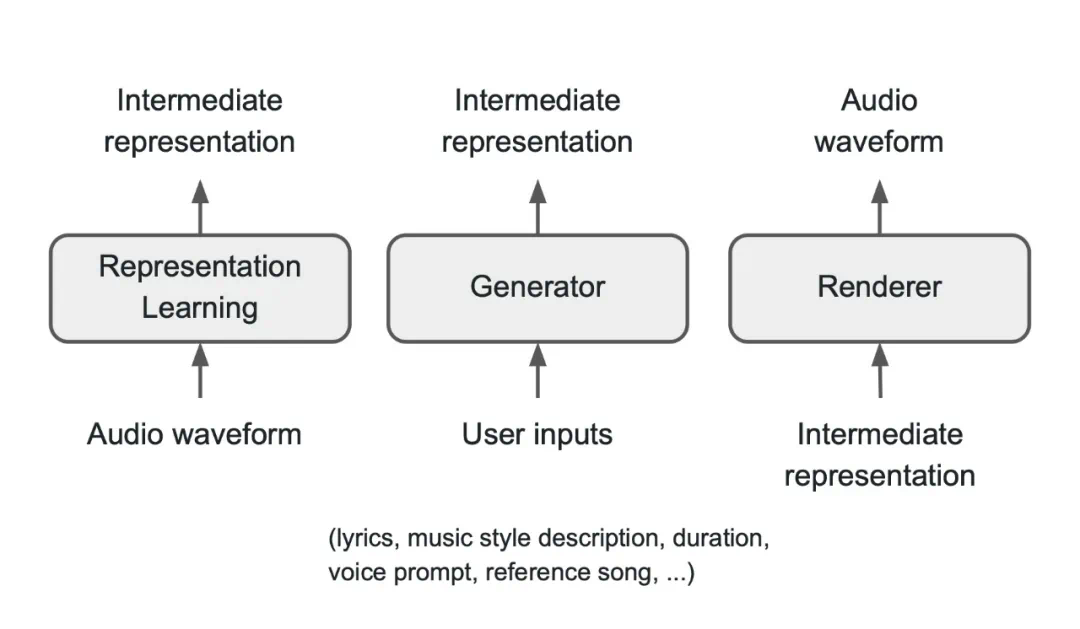
Seed-Music 架构
-
音频 token:通常以低于音频采样率的标记率学习,旨在有效编码语义和声学信息,能轻松桥接不同模态,但不同音乐信息高度纠缠,给生成器带来挑战。 -
符号音乐 token:如 MIDI、ABC 记号或钢琴卷帘记号等,本质上离散,可被大型语言模型操作,具有可解释性,便于用户在辅助音乐创作中交互,但缺乏声学信息,依赖渲染器生成声学细节。 -
声码器 latent:在探索基于扩散模型的音乐音频生成中,可作为中间表征,与量化音频标记相比,信息损失少、渲染器权重更轻,但生成器输出不可解释,且由于仅用波形重建目标训练,可能不够有效作为训练生成器的预测目标。

Seed-Music pipeline
-
基于音频 token 的链路:包括 tokenizer、自回归语言模型、token 扩散模型和声码器,音频 token 有效地存储了原始信号的显著音乐信息,语言模型根据用户控制输入生成音频 token,token 扩散模型处理音频 token 以生成具有增强声学细节的音频波形。 -
基于符号音乐 token 的链路:采用符号音乐 token 作为中间表征,与音频 token 基于的管道类似,但有一些区别,如 lead sheet tokenizer 将信息编码为 token,语言模型学习预测 lead sheet token 序列,lead sheet token 是可解释的,并且允许在训练和推理中注入人类知识,但扩散模型从 lead sheet token 预测声码器 latent 更具挑战性,需要更大的模型规模。 -
基于声码器 latent 的链路:遵循通过 latent 扩散建模从文本直接生成音乐到声学声码器 latent 表征的工作,通过变分自编码器和扩散模型将条件信号映射到归一化和连续的声码器 latent 空间。
