文章来源于互联网:ECCV 2024 oral | 首次基于深度聚类的多模态融合,上交、伯克利提出双向结构对齐的融合网络新SOTA!
本文的主要作者来自上海交通大学智能机器人与机器视觉(IRMV)实验室。本文第一作者是实验室硕士生刘久铭,主要研究方向为点云配准,雷达里程计,多模态融合,nerf/3DGS 渲染,3D生成等。曾在CVPR,ICCV,ECCV,AAAI等会议发表论文多篇。

-
论文链接:https://arxiv.org/pdf/2403.18274
-
代码仓库:https://github.com/IRMVLab/DVLO
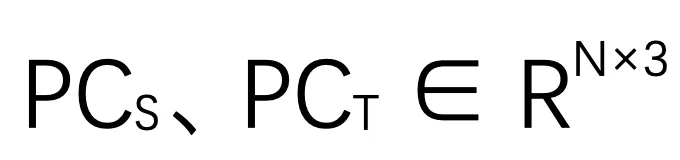 ,及其对应的来自一对连续帧的单目相机图像
,及其对应的来自一对连续帧的单目相机图像 ,里程计目标是估计两个帧之间的相对位姿,包括旋转四元数
,里程计目标是估计两个帧之间的相对位姿,包括旋转四元数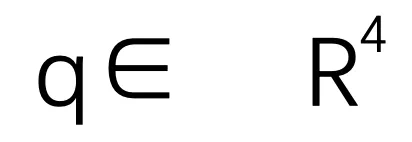 和平移向量
和平移向量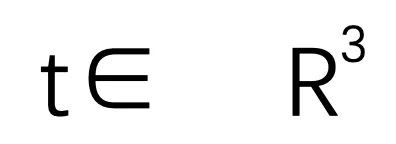 。
。 
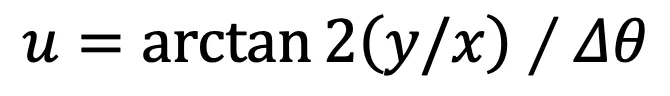
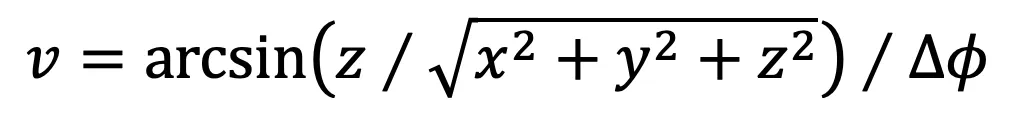
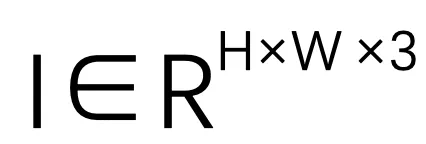 ,利用 [17] 中基于卷积的特征金字塔提取图像特征
,利用 [17] 中基于卷积的特征金字塔提取图像特征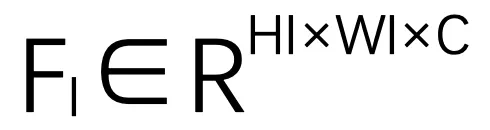 。其中,
。其中,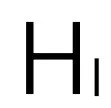 、
、 是特征图的高度和宽度。C 是图像特征的通道数。
是特征图的高度和宽度。C 是图像特征的通道数。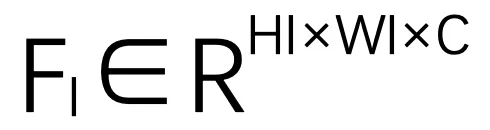 后,首先将其重塑为伪点集合
后,首先将其重塑为伪点集合 ,其中
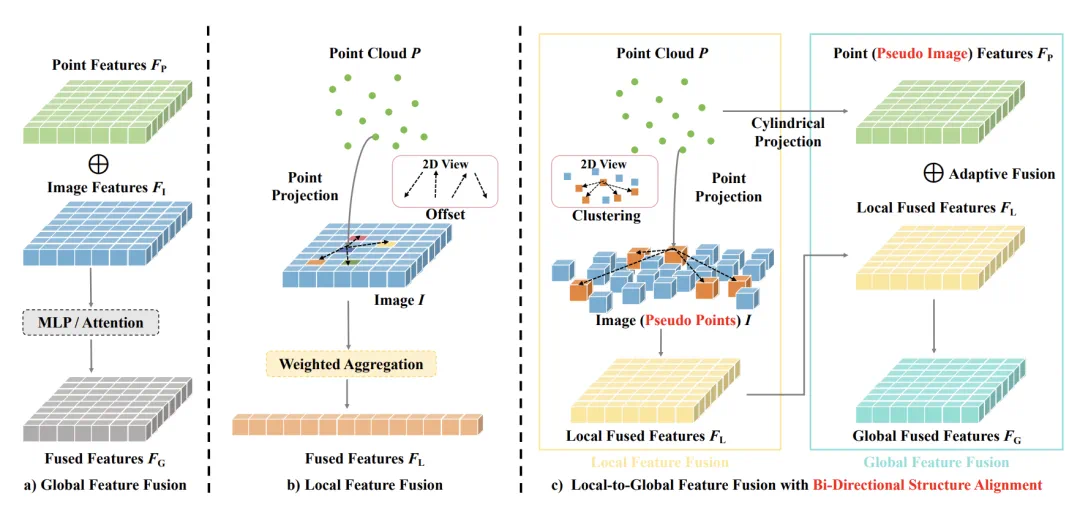
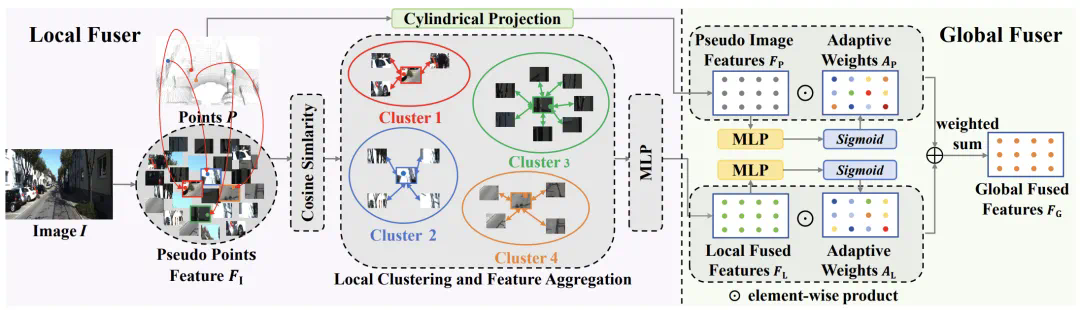
,其中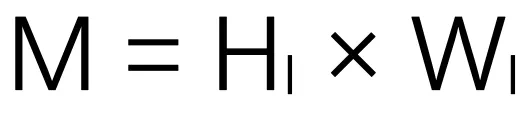 为伪点个数。在这种情况下,图像具有与激光雷达点相同的数据结构,这有利于建立局部像素与点的对应关系,并进一步进行基于聚类的特征聚合。
为伪点个数。在这种情况下,图像具有与激光雷达点相同的数据结构,这有利于建立局部像素与点的对应关系,并进一步进行基于聚类的特征聚合。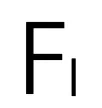 进行双线性插值,计算出中心特。
进行双线性插值,计算出中心特。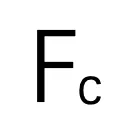 和伪点特征
和伪点特征 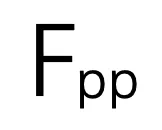 的成对余弦相似度,将所有伪点划分为若干个聚类。在此,将每个伪点分配到最相似的聚类中心,从而得到 N 个聚类。为了提高效率,按照 Swin Transformer,在计算相似度时使用区域分割。
的成对余弦相似度,将所有伪点划分为若干个聚类。在此,将每个伪点分配到最相似的聚类中心,从而得到 N 个聚类。为了提高效率,按照 Swin Transformer,在计算相似度时使用区域分割。 的计算公式为:
的计算公式为: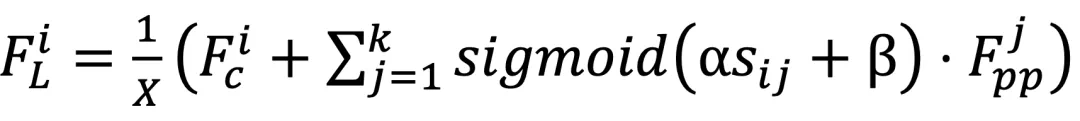
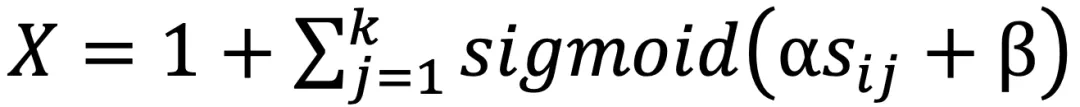
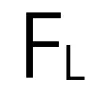 和点(伪图像)特征
和点(伪图像)特征 之间引入了全局自适应融合机制。
之间引入了全局自适应融合机制。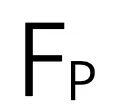 的大小为
的大小为 。这一过程将原本稀疏的非结构化点重组为密集的结构化伪图像,从而实现了下面的密集特征图与图像特征的融合。
。这一过程将原本稀疏的非结构化点重组为密集的结构化伪图像,从而实现了下面的密集特征图与图像特征的融合。 和点特征
和点特征 ,按以下方式进行自适应全局融合:
,按以下方式进行自适应全局融合: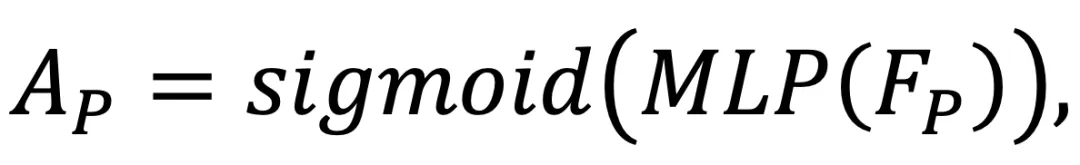
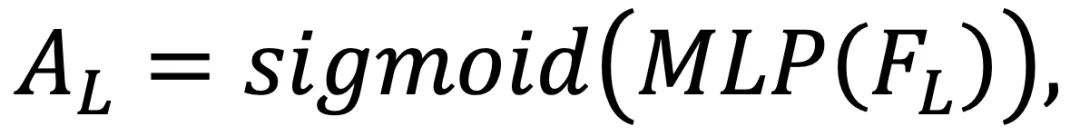
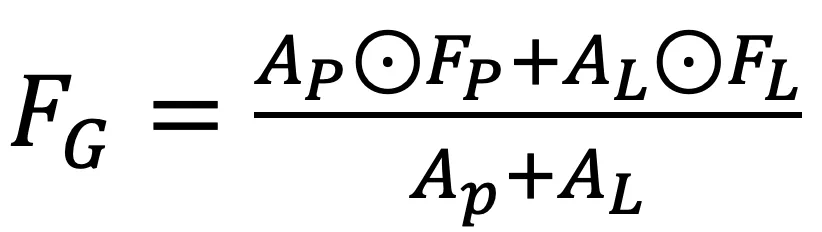
 和
和 是点(伪图像)特征和局部融合特征的自适应权重,由 sigmoid 函数和 MLP 层获得。⊙表示元素与元素之间的乘积。然后,将全局融合特征
是点(伪图像)特征和局部融合特征的自适应权重,由 sigmoid 函数和 MLP 层获得。⊙表示元素与元素之间的乘积。然后,将全局融合特征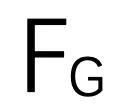 重塑为 N ×D 的大小,作为迭代姿态估计的输入。
重塑为 N ×D 的大小,作为迭代姿态估计的输入。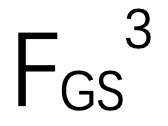 和
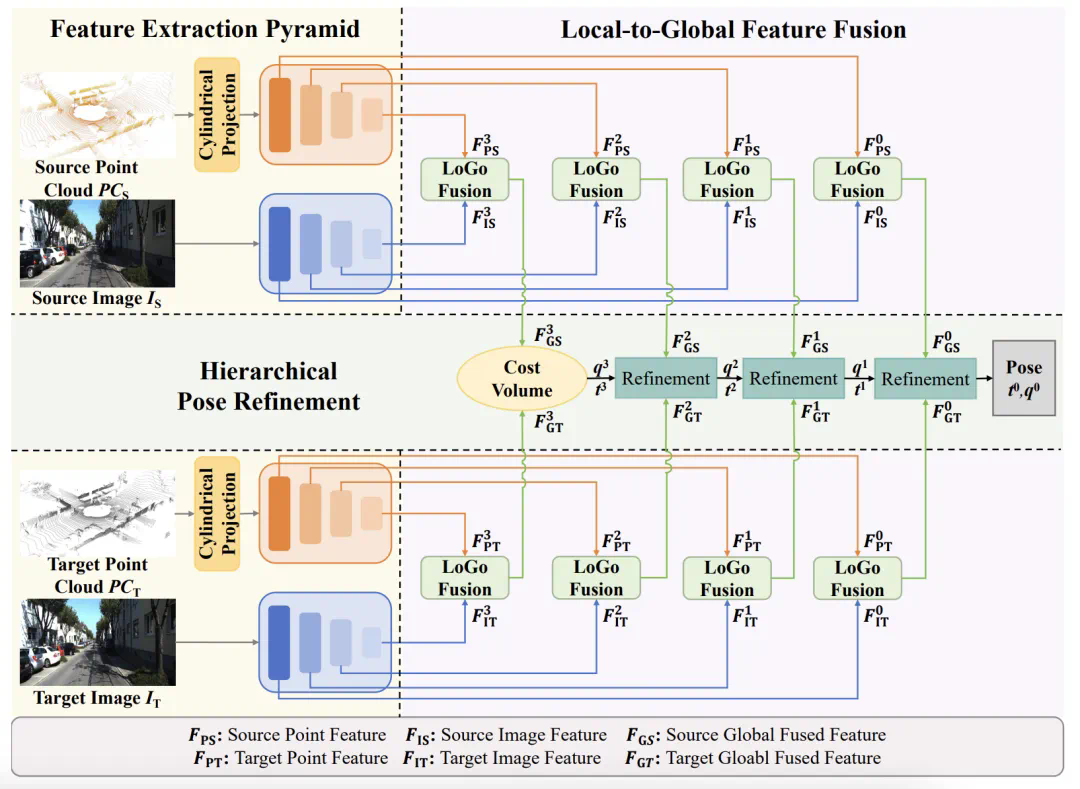
和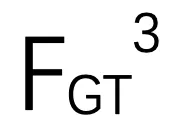 联系起来,利用代价卷生成粗嵌入特征
联系起来,利用代价卷生成粗嵌入特征 。嵌入特征包含两个连续帧之间的相关信息。
。嵌入特征包含两个连续帧之间的相关信息。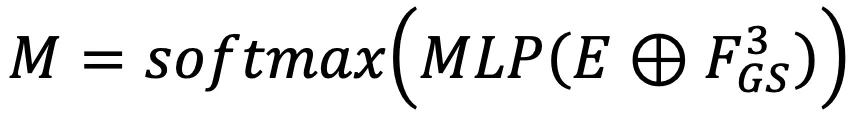
 是可学习的掩码。
是可学习的掩码。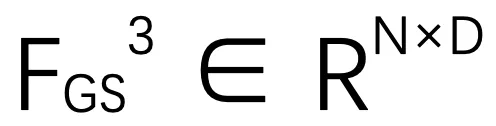 是源帧中的全局融合特征。然后,通过对嵌入特征和 FC 层加权,生成四元数
是源帧中的全局融合特征。然后,通过对嵌入特征和 FC 层加权,生成四元数 和平移向量
和平移向量 :
: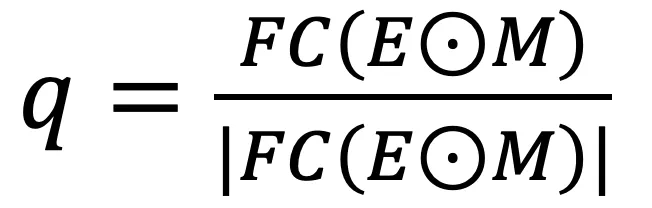
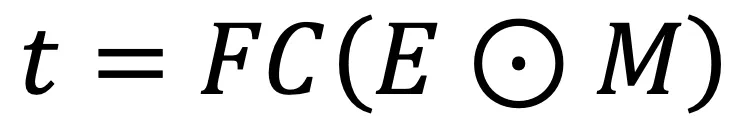
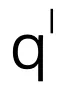 和平移矢量
和平移矢量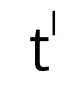 的计算公式为:
的计算公式为: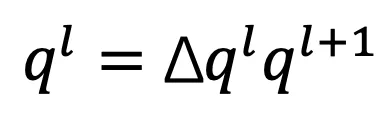
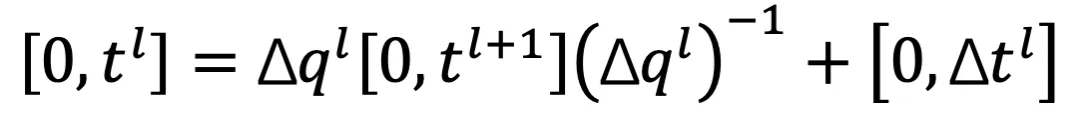
 和
和 可根据论文中的公式在最粗糙层中通过类似过程获得。
可根据论文中的公式在最粗糙层中通过类似过程获得。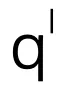 和
和 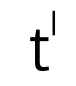 将用于计算监督损失
将用于计算监督损失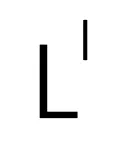 。第 l 层的训练损失函数为:
。第 l 层的训练损失函数为: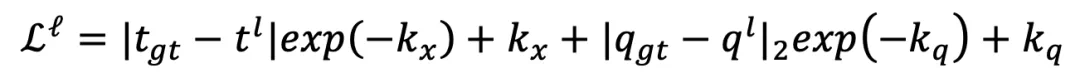
 和
和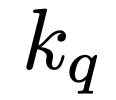 是可学习的标量,用于缩放损失。
是可学习的标量,用于缩放损失。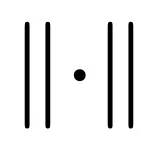 和
和 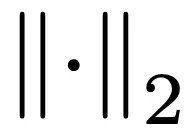 分别是 L1 和 L2 准则。那么,总训练损失为
分别是 L1 和 L2 准则。那么,总训练损失为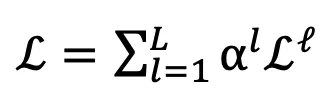
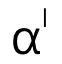 是代表第 l 层权重的超参数。
是代表第 l 层权重的超参数。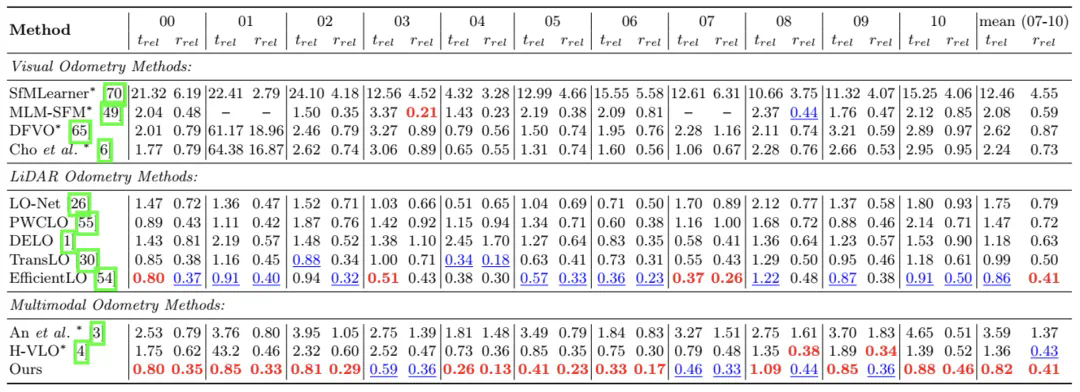

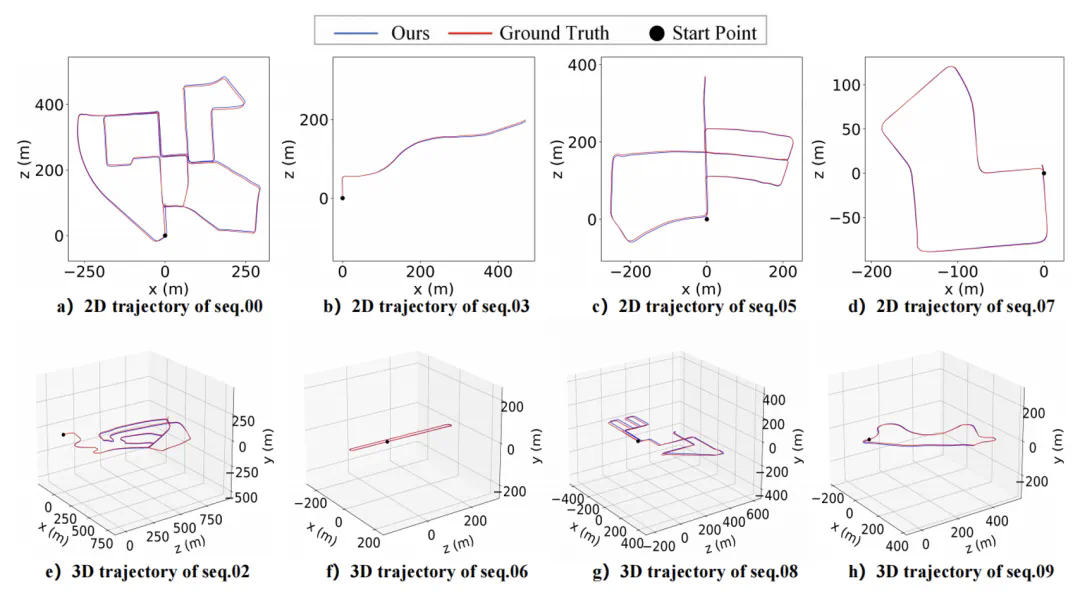
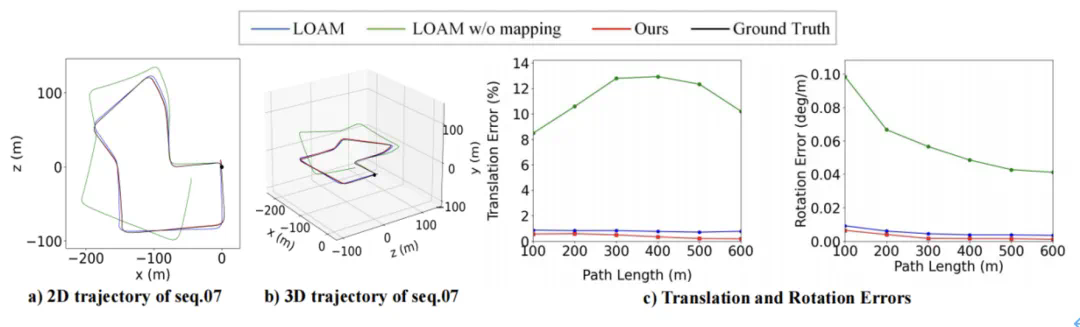
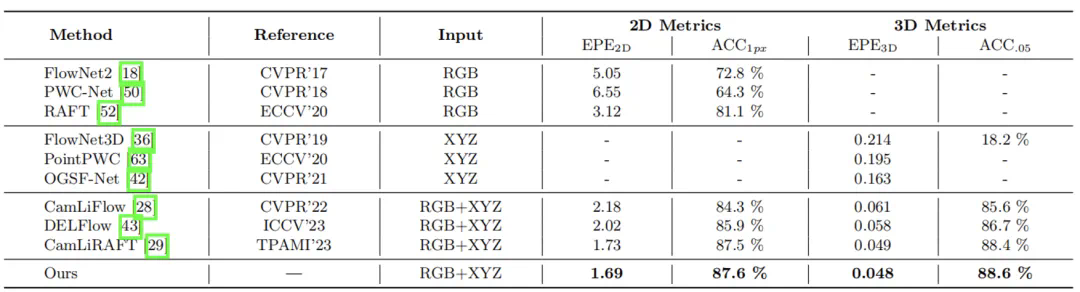
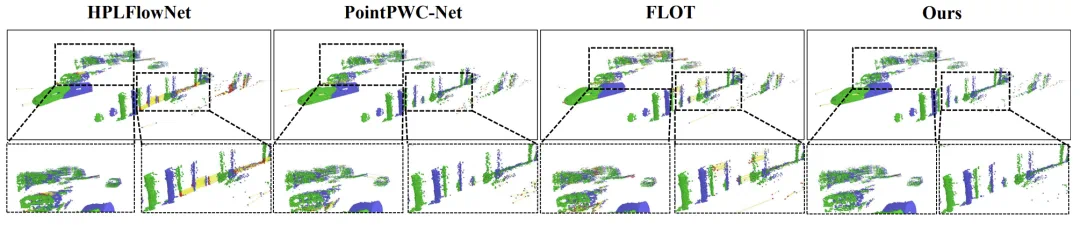
 表 3:在 KITTI 09-10 序列上与基于学习的多模态里程计的比较。
表 3:在 KITTI 09-10 序列上与基于学习的多模态里程计的比较。




文章来源于互联网:ECCV 2024 oral | 首次基于深度聚类的多模态融合,上交、伯克利提出双向结构对齐的融合网络新SOTA!
