文章来源于互联网:ECCV 2024 | 像ChatGPT一样,聊聊天就能实现三维场景编辑

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

-
项目地址:https://sk-fun.fun/CE3D/ -
代码:https://github.com/Fangkang515/CE3D/tree/main -
论文:https://arxiv.org/abs/2407.06842 -
机构:北航 & 谷歌 & 旷视
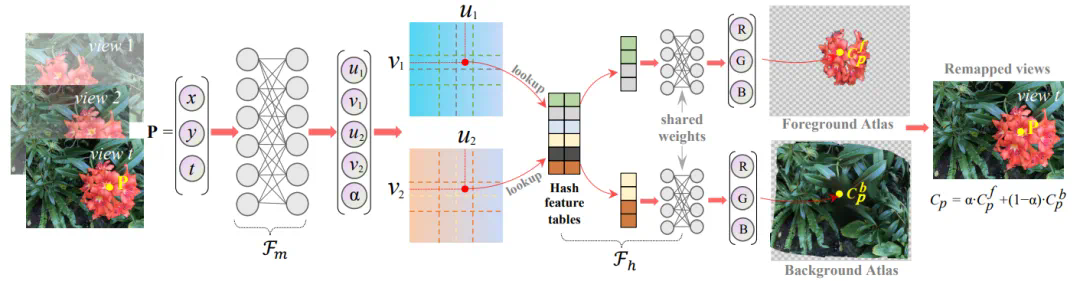
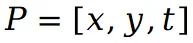 在第 t 个视图中被函数
在第 t 个视图中被函数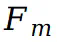 映射到两个不同的 UV 坐标:
映射到两个不同的 UV 坐标: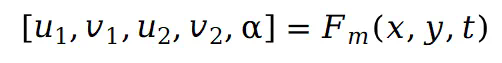
 表示在两个 UV 空间中的坐标。参数
表示在两个 UV 空间中的坐标。参数 在 0 到 1 之间,表示前景图集中像素值权重。然后使用
在 0 到 1 之间,表示前景图集中像素值权重。然后使用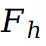 预测在 UV 坐标中对应的前景和背景图集的 RGB 值:
预测在 UV 坐标中对应的前景和背景图集的 RGB 值: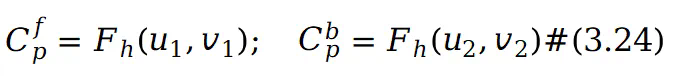
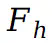 采用哈希结构来捕捉图像中的纹理细节,并实现更快的模型训练和推理。在图集中获得像素值
采用哈希结构来捕捉图像中的纹理细节,并实现更快的模型训练和推理。在图集中获得像素值 后,可以按如下方式重建场景视图中点P的原始像素:
后,可以按如下方式重建场景视图中点P的原始像素: 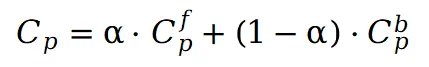
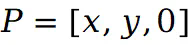 ,此时预训练位置损失定义如下:
,此时预训练位置损失定义如下: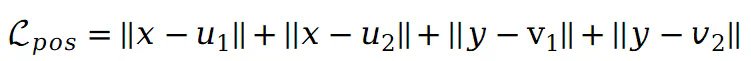
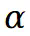 的预训练涉及初步通过 VQA 模型确定场景的前景及其对应的掩码,通过分割模型获得假设前景掩码为
的预训练涉及初步通过 VQA 模型确定场景的前景及其对应的掩码,通过分割模型获得假设前景掩码为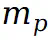 ,则
,则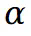 的预训练损失定义如下:
的预训练损失定义如下:
 和前景图集的稀疏性,这有助于前景和背景图集内容的明确分离。完成预训练后,可以通过监督图集重建视图来训练整个模型。但直接进行训练会导致背景图集中明显的区域遗漏,影响了后续的编辑任务。为了解决这个问题,本文引入了修补损失。具体而言,利用 ProPainter 模型对遮罩背景进行初步修补,生成一组新的修补视图。假设原始视图中的点 P 在修补视图中对应于
和前景图集的稀疏性,这有助于前景和背景图集内容的明确分离。完成预训练后,可以通过监督图集重建视图来训练整个模型。但直接进行训练会导致背景图集中明显的区域遗漏,影响了后续的编辑任务。为了解决这个问题,本文引入了修补损失。具体而言,利用 ProPainter 模型对遮罩背景进行初步修补,生成一组新的修补视图。假设原始视图中的点 P 在修补视图中对应于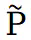 ,则重建损失可以表示如下:
,则重建损失可以表示如下: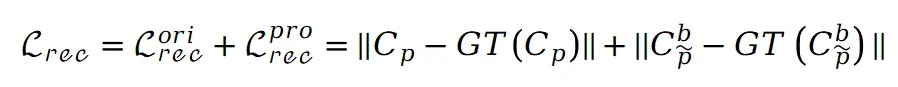
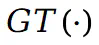 表示从场景的原始视图或修补视图中获得的真实值。此外在场景上引入刚性和流动约束:其中
表示从场景的原始视图或修补视图中获得的真实值。此外在场景上引入刚性和流动约束:其中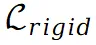 的目的是保持不同点之间的相对空间位置不发生剧烈变化。与此同时
的目的是保持不同点之间的相对空间位置不发生剧烈变化。与此同时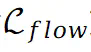 鼓励将不同视图的对应点映射到图集上的同一位置。因此,总损失可以表示如下:
鼓励将不同视图的对应点映射到图集上的同一位置。因此,总损失可以表示如下: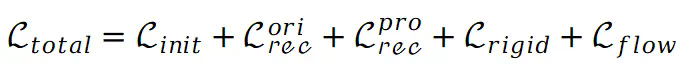
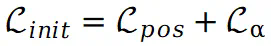 仅在初始训练阶段使用。
仅在初始训练阶段使用。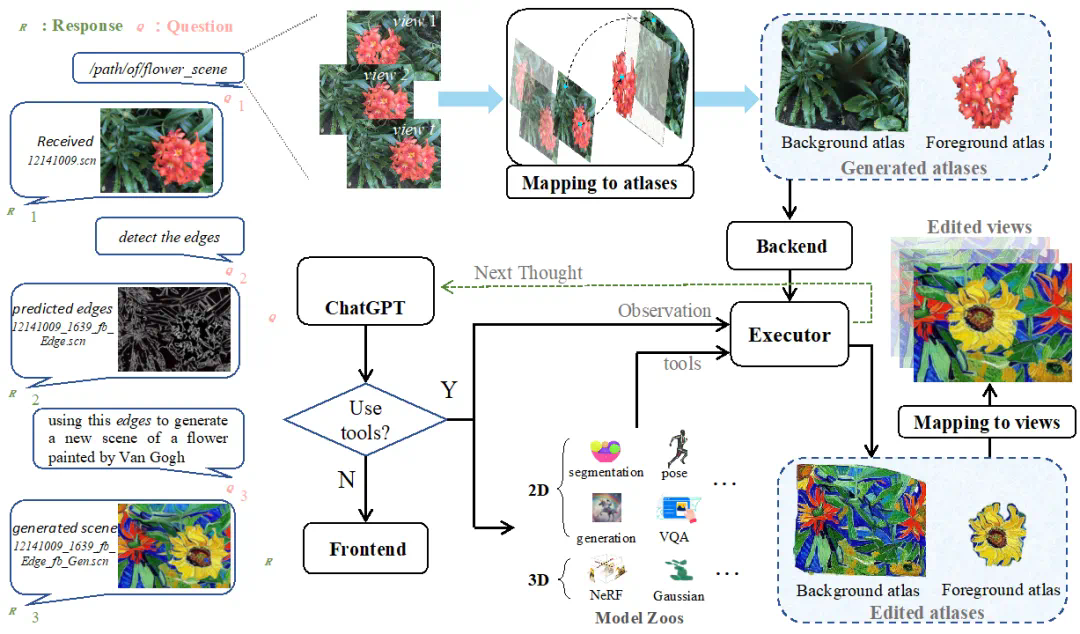


文章来源于互联网:ECCV 2024 | 像ChatGPT一样,聊聊天就能实现三维场景编辑
