文章来源于互联网:告别CUDA无需Triton!Mirage零门槛生成PyTorch算子,人均GPU编程大师?

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

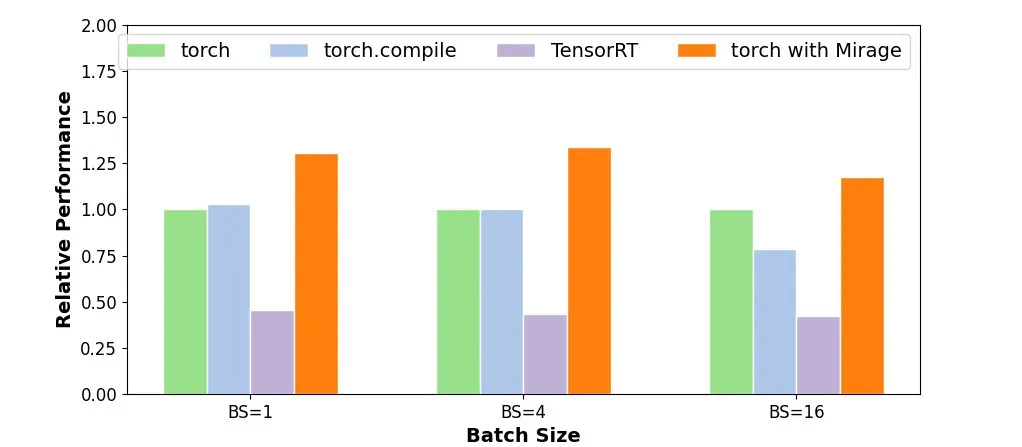
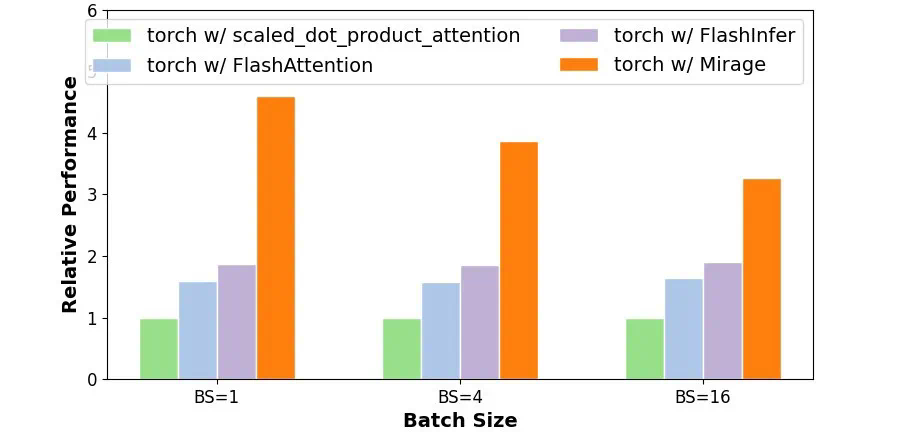
# Use Mirage to generate GPU kernels for attentionimport mirage as migraph = mi.new_kernel_graph ()Q = graph.new_input (dims=(64, 1, 128), dtype=mi.float16)K = graph.new_input (dims=(64, 128, 4096), dtype=mi.float16)V = graph.new_input (dims=(64, 4096, 128), dtype=mi.float16)A = graph.matmul (Q, K)S = graph.softmax (A)O = graph.matmul (S, V)optimized_graph = graph.superoptimize ()
import torchinput_tensors = [torch.randn (64, 1, 128, dtype=torch.float16, device='cuda:0'),torch.randn (64, 128, 4096, dtype=torch.float16, device='cuda:0'),torch.randn (64, 4096, 128, dtype=torch.float16, device='cuda:0')]# Launch the Mirage-generated kernel to perform attentionoutput = optimized_graph (input_tensors)
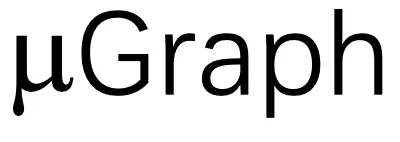

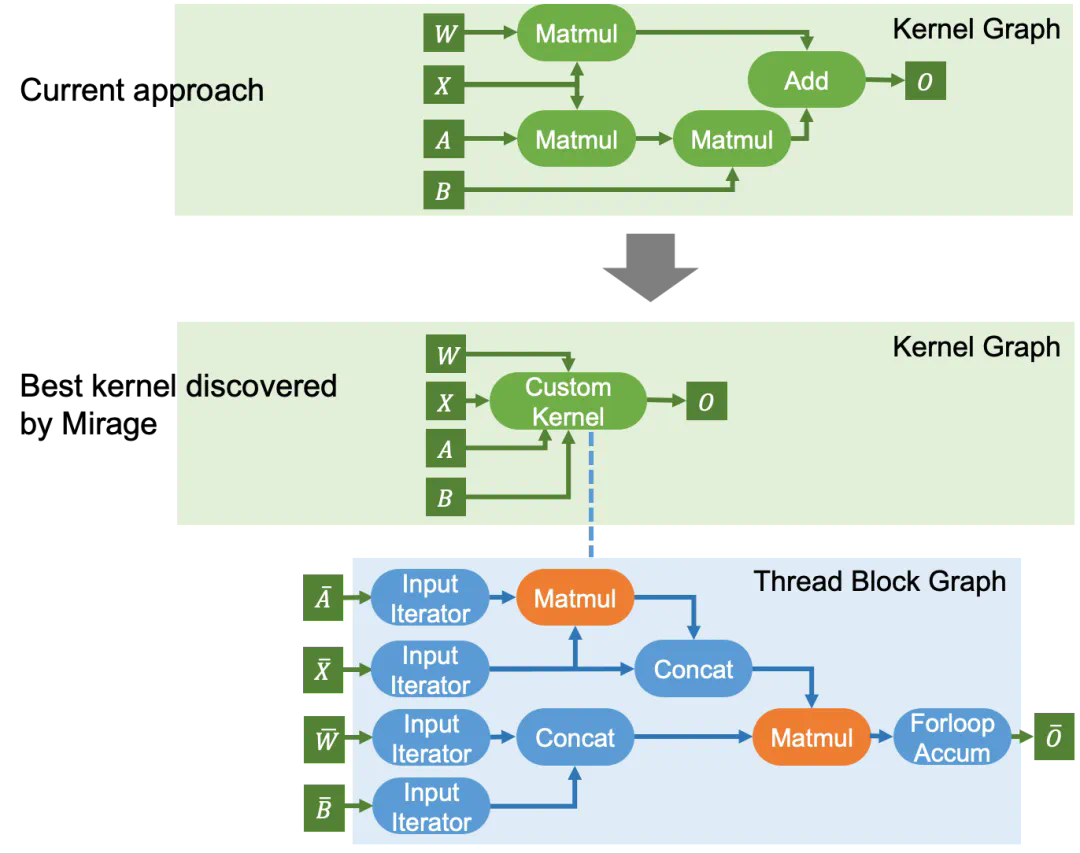
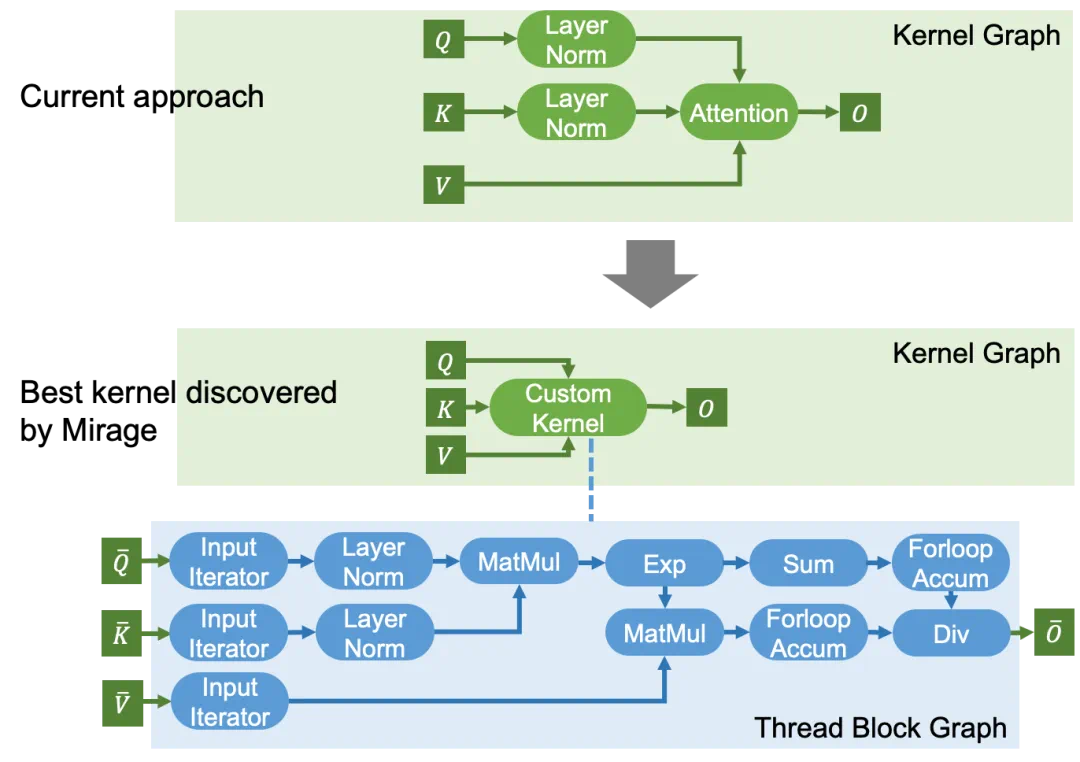
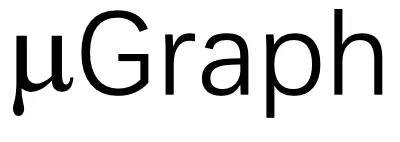 来描述 GPU 内核,
来描述 GPU 内核,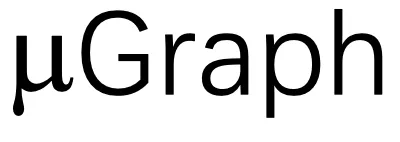 包含多个层次,代表内核、线程块和线程级别的计算。大体上,Kernel Graph、Thread Block Graph 和 Thread Graph 分别代表整个 GPU、一个流处理器(SM)和一个 CUDA/tensor 核心上的计算。
包含多个层次,代表内核、线程块和线程级别的计算。大体上,Kernel Graph、Thread Block Graph 和 Thread Graph 分别代表整个 GPU、一个流处理器(SM)和一个 CUDA/tensor 核心上的计算。 细节感兴趣的读者可以参考:
细节感兴趣的读者可以参考:-
https://mirage-project.readthedocs.io/en/latest/mugraph.html
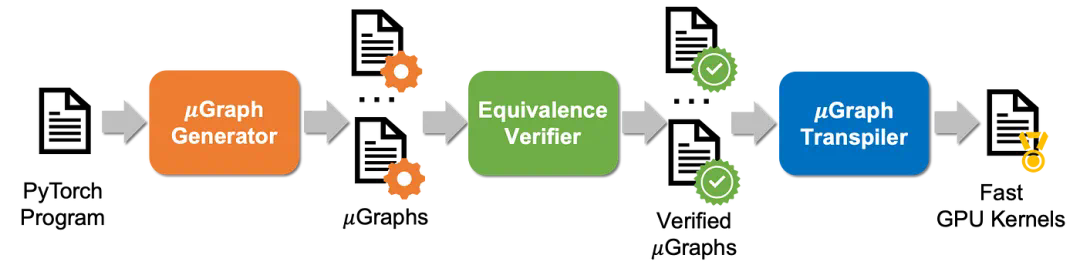
 生成器自动搜索与输入程序功能等价的其他
生成器自动搜索与输入程序功能等价的其他 ,搜索空间涵盖了内核、线程块和线程级别的各种 GPU 优化。所有生成的
,搜索空间涵盖了内核、线程块和线程级别的各种 GPU 优化。所有生成的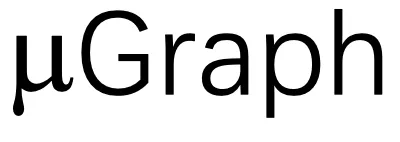 都被发送到等价性验证器,该验证器自动检查每个
都被发送到等价性验证器,该验证器自动检查每个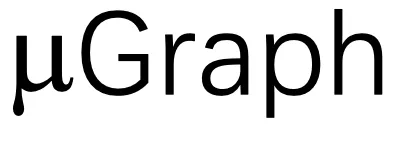 是否与所需程序等价。最后,
是否与所需程序等价。最后,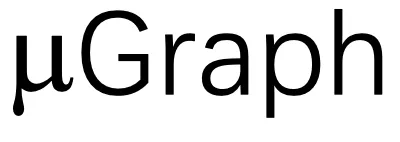 转译器将所有经过验证的
转译器将所有经过验证的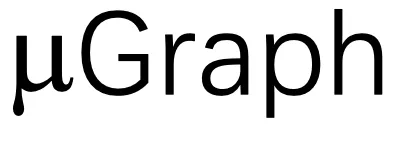 转译为 CUDA 内核。最后,Mirage 会从中返回性能最佳的 CUDA 内核。
转译为 CUDA 内核。最后,Mirage 会从中返回性能最佳的 CUDA 内核。-
项目成员:Mengdi Wu (CMU), Xinhao Cheng (CMU), Shengyu Liu (PKU), Chuan Shi (PKU), Jianan Ji (CMU), Oded Padon (VMWare), Xupeng Miao (Purdue), Zhihao Jia (CMU) -
项目地址:https://github.com/mirage-project/mirage