文章来源于互联网:一文看懂LLM推理,UCL汪军教授解读OpenAI ο1的相关方法
OpenAI 最近发布的 o1 系列模型堪称迈向强人工智能的一次飞跃,其强大的推理能力为我们描绘出了下一代人工智能模型的未来图景。近日,伦敦大学学院(UCL)人工智能中心汪军教授撰写了一份「LLM 推理教程」,深入详细地介绍了 OpenAI ο1 模型背后的相关方法。
他将在 10 月 12 号本周星期六早上于香港科技大学(广州)RLChina 2024 大会(http://rlchina.org/rlchina_2024/)上作相关内容的主题报告,并发布其团队开发的 LLM 推理开源框架以推动 o1 相关模型的发展。


图 1:推理时间计算。(a) 自回归 LLM 是直接基于给定问题生成答案。(b) 思维链和逐步思考的概念则涉及到在得到最终答案之前,整合中间推理步骤。这些重复步骤操作允许 1) 不断重复访问之前的输出,2) 逐步推进到后续推理阶段,3) 探索多个推理路径或轨迹。
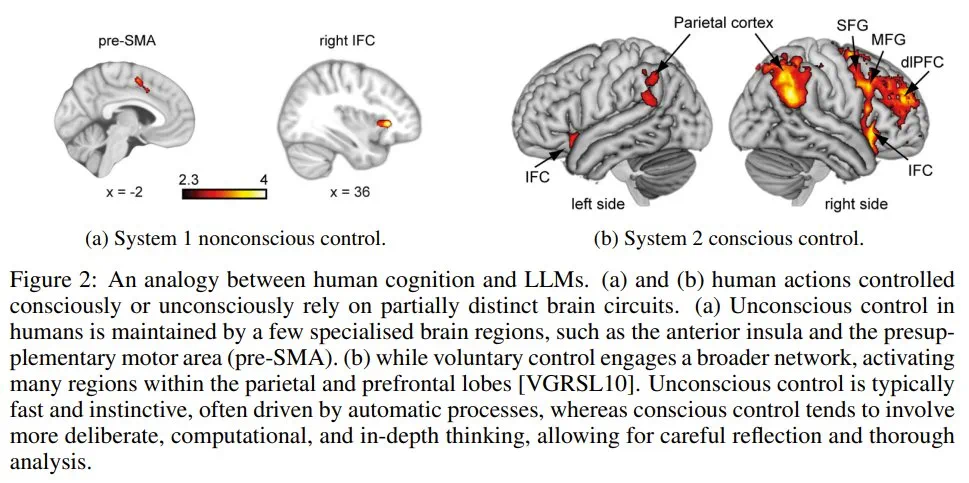
图 2:人类认知和 LLM 的类比。(a) 和 (b) 人类有意识或无意识控制的行为依赖于部分不同的大脑回路。(a) 人类的无意识控制由一些专门的大脑区域维持,例如前脑岛和前补充运动区(pre-SMA)。(b) 而自主控制则涉及更大的网络,激活顶叶和前额叶内的许多区域。无意识控制通常快速而本能,通常由自动过程驱动,而有意识控制往往涉及更审慎、计算和深入的思考,需要仔细的反思和透彻的分析。
-
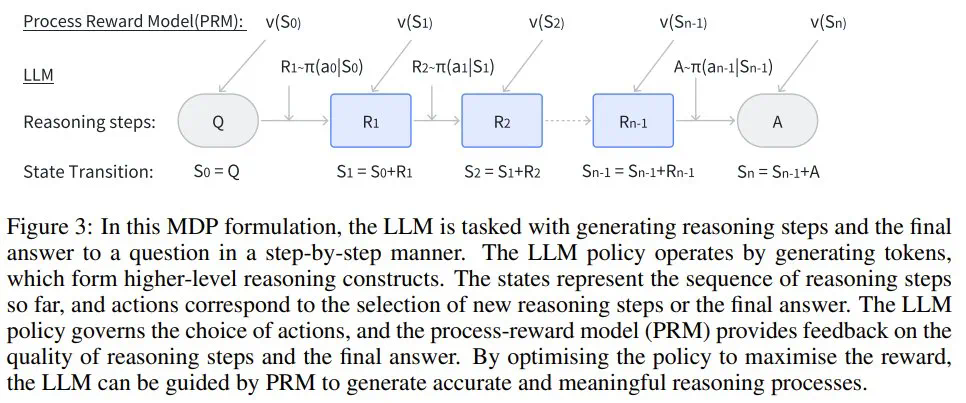
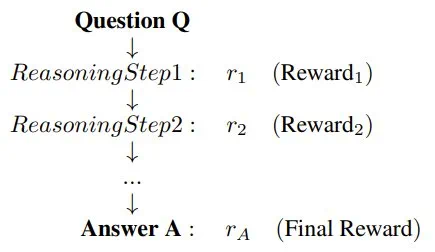
Q:表示启动推理过程的问题或提示词; -
R:表示为了得到解答,模型生成的中间推理步骤的序列; -
A:表示推理步骤完成后得到的最终答案或解。
-
𝒯 (s_t, a_t) 是转换模型,它是确定性的,因为当前状态 s_t 和动作 a_t 仅能定义唯一下一状态 s_(t+1) ,因此 s_(t+1) = s_t + a_t。 -
𝒱 (s_t, a_t) 是过程奖励模型(PRM),用于评估在状态 s_t 下动作 a_t 的质量。它能反映生成的推理步骤或 token 在得到最终答案过程中的合适程度和有效性:𝒱 (s_t, a_t)=𝑣_t。
-
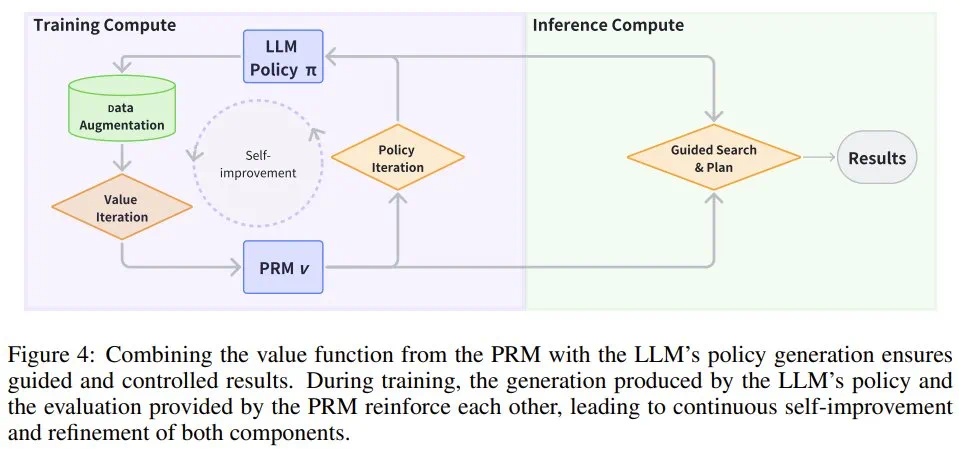
PRM 的价值迭代
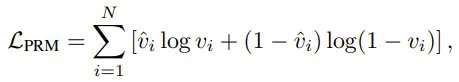
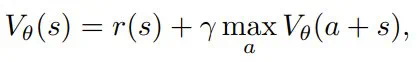
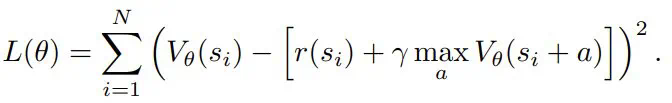
-
LLM 策略的策略迭代

-
S 是状态空间,表示生成到给定位置处的 token 序列或推理步骤; -
A 是动作空间,由潜在推理步骤 R_t 或最终答案 A 组成; -
π_LLM (a_t | s_t) 是控制动作选择的策略(也是 LLM),其可根据当前状态 s_t 确定下一个推理步骤或最终答案; -
R (s_t a_t) 是过程奖励模型(PRM,其作用是根据所选动作 a_t 的质量和相关性分配奖励 r_t,以引导推理过程。
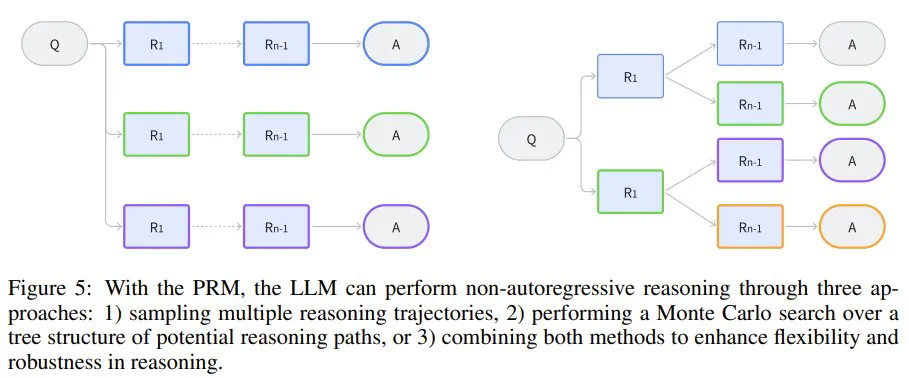
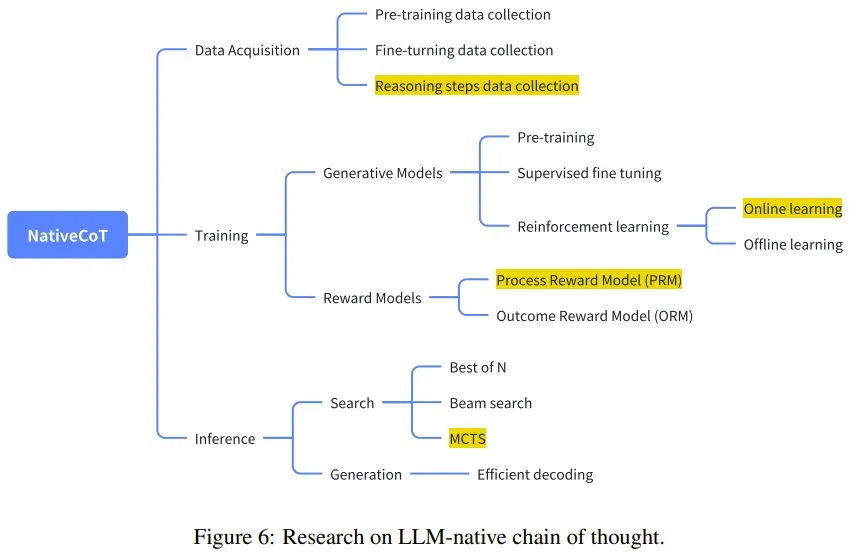
-
论文《Alphazero-like tree-search can guide large language model decoding and training》提出了一种将蒙特卡洛树搜索(MCTS)与 LLM 解码整合起来的方法,研究证明这种组合能够有效地引导推理,尤其是复杂的多步骤任务。 -
论文《Scaling llm test-time compute optimally can be more effective than scaling model parameters》强调了优化测试时间计算的重要性,其通过实证研究表明,推理时间推理增强通常可以比简单地扩展模型参数产生更实质性的改进。这反映了人们日益增长的理解,即可以利用推理过程中的更多计算来实现更高质量的推理,而不必增加模型的大小。 -
论文《Think before you speak: Training language models with pause tokens》提出了另一种方法:在推理阶段使用暂停 token 强迫模型暂停并「思考」。该方法会引入一个隐式的推理模型,从而鼓励 LLM 对信息进行分块,模仿人类的思考。
-
论文《Training verifiers to solve math word problems》最早尝试在数学推理任务中使用验证器(仅结果奖励),为后续研究奠定了基础。 -
论文《Solving math word problems with process-and outcome-based feedback》扩展了验证器的概念,整合了基于过程的推理机制。 -
论文《Let’s verify step by step》 研究了过程奖励模型,亦可参阅机器之心报道《OpenAI 要为 GPT-4 解决数学问题了:奖励模型指错,解题水平达到新高度》。 -
论文《Making large language models better reasoners with step-aware verifier》将验证器模型与大多数投票机制组合到了一起,以在推理任务中得到更可靠的输出。为了增强验证过程的稳健性,该方法会交叉检查多条推理路径并过滤掉不正确的步骤。
-
论文《Star: Bootstrapping reasoning with reasoning》探索了自动获取与推理步骤相关的数据的方法。STaR 提出了一种自学习范式,让模型可通过生成和批评自己的步骤来提高其推理能力,从而产生更可靠的中间步骤。 -
论文《Math-shepherd: Verify and reinforce llms step-by-step without human annotations》进一步推进了该方法,表明无需成本高昂的标注也能逐步训练 LLM,其为推理数据问题提供更具可扩展性的解决方案。 -
论文《Multi-step problem solving through a verifier: An empirical analysis on model-induced process supervision》强调了实际数据采集对于推理任务的重要性,特别是对于编程问题。 -
论文《Alphazero-like tree-search can guide large language model decoding and training》使用了 MCTS 来获取数据。 -
论文《Improve mathematical reasoning in language models by automated process supervision》则在此基础上使用了线性搜索来提升效率。
-
也有不少研究者致力于理解 LLM 逐步推理背后的机制,如论文《Why can large language models generate correct chain-of-thoughts?》和《Why think step by step? reasoning emerges from the locality of experience》。 -
论文《Llama: Open and efficient foundation language models》则是从图模型角度来分析思维链机制。 -
论文《Why think step by step? reasoning emerges from the locality of experience》探索了推理作为 LLM 的一种自然能力的内在原因。其认为推理是语言模型处理本地化经验和知识的一个副产物。 -
论文《Critique ability of large language models》对 LLM 批评自己的能力进行实证评估,结果表明自我批评往往很有限,并且通常只有当模型足够大时才会涌现这种能力。 -
论文《Pangu-agent: A fine-tunable generalist agent with structured reasoning》从系统角度提出了超越传统模型的结构化推理机制,类似于 OpenAI ο1 模型。这项研究反映了向更通用的推理智能体的转变,这些智能体能以更高的精度和灵活性处理更广泛的任务,描绘了下一代推理模型的愿景。
文章来源于互联网:一文看懂LLM推理,UCL汪军教授解读OpenAI ο1的相关方法
