文章来源于互联网:人类自身都对不齐,怎么对齐AI?新研究全面审视偏好在AI对齐中的作用

-
论文标题:Beyond Preferences in AI Alignment -
论文地址:https://arxiv.org/pdf/2408.16984


-
人类在行事时甚至都不能大致遵循理性选择理论; -
没有理由认为高级 AI 必定会最大化某个效用函数; -
人类偏好是推断出来的或构建起来的,因此将 AI 的行为与我们表述出来的偏好对齐是错误的方向;相反,我们可以将 AI 直接与「优秀助手 / 程序员 / 司机等」规范性理想目标对齐; -
聚合人类的偏好充满哲学和数学困难;我们的目标不应该是让 AI 与「人类的集体意志」对齐。
-
将理性选择理论作为描述性框架。人类行为和决策被很好地建模为近似地满足最大化偏好,这可以表示为效用或奖励函数。 -
将预期效用理论作为规范标准。理性可以被描述为预期效用的最大化。此外,应根据这一规范标准设计和分析 AI 系统。 -
将单主体对齐作为偏好匹配。对于要与单个人类主体对齐的 AI 系统,它应尽可能地满足该人类的偏好。 -
将多主体对齐作为偏好聚合。为了使 AI 系统与多个人类主体对齐,它们应以最大限度地满足其总体偏好。
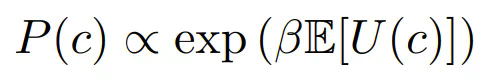 。
。-
人类决策的带噪理性模型; -
将奖励和效用函数用作人类偏好的表征; -
将偏好用作人类价值和理性的表征。
-
将预期效用理论用作一个分析视角; -
将全局一致性智能体作为设计目标; -
偏好作为动作的规范基础。
-
标量和非情境奖励的对齐; -
静态和非社交偏好的对齐; -
偏好作为对齐的目标。
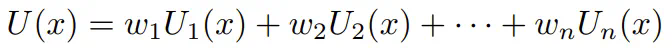
-
简单的效用主义偏好聚合; -
将总体偏好用作对齐目标。
文章来源于互联网:人类自身都对不齐,怎么对齐AI?新研究全面审视偏好在AI对齐中的作用

