文章来源于互联网:DeepSeek新作Janus:解耦视觉编码,引领多模态理解与生成统一新范式

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

-
论文: https://arxiv.org/pdf/2410.13848 -
项目主页:https://github.com/deepseek-ai/Janus -
模型下载:https://huggingface.co/deepseek-ai/Janus-1.3B -
在线 Demo:https://huggingface.co/spaces/deepseek-ai/Janus-1.3B

-
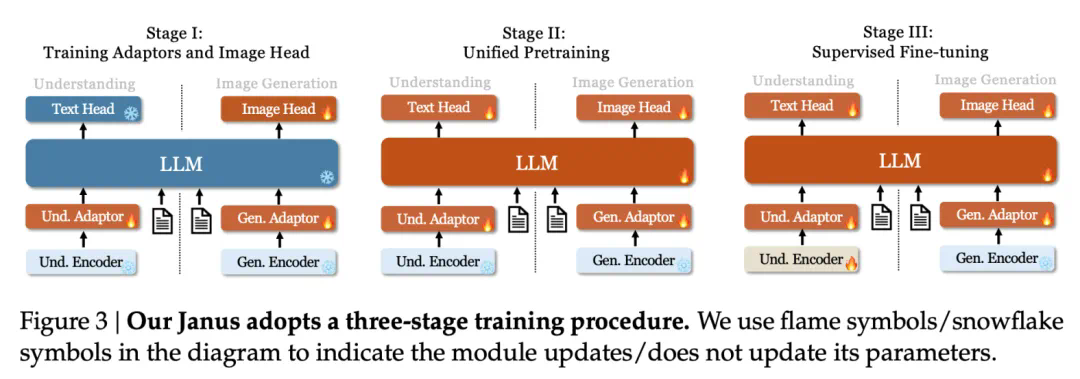
在第一阶段,我们使用 Image Caption 数据和 ImageNet 文生图数据,对 understanding adaptor, generation adaptor, image head 这三个随机初始化的模块进行训练,起到 warm up 的效果。 -
在第二阶段,我们额外打开 LLM 和 text head,然后使用大量纯文本、图生文和文生图的数据进行联合预训练。对于文生图数据,我们会让 ImageNet 这部分数据出现在其他场景的文生图数据之前,先学习像素依赖关系,然后学习场景生成 (参照 Pixart 中的设定)。 -
在第三阶段,我们额外打开 understanding encoder,使用指令跟随数据进行训练。
-
多模态理解方面,(1) 可以使用比 SigLIP 更强的 encoder,例如 EVA-CLIP 或 InternViT 6B,而不用担心这些 encoder 是否能来做生成。(2) 可以引入当前多模态理解领域先进的动态分辨率技术 (将图像切成多个子块,提供更好的细粒度理解能力) 和 pixel shuffle 压缩技术。 -
视觉生成方面,(1) 可以将当前的 VQ Tokenizer 替换成更好的 tokenizer,例如 MoVQGan 以及最近刚出的 HART (一种结合连续和离散的优点的 tokenizer)。(2) 可以为图像生成部分设计其他优化目标,如 diffusion loss。也可以将图像生成部分的 attention mask 改成双向的,这也被证实了比单向 mask 有更好的生成效果。 -
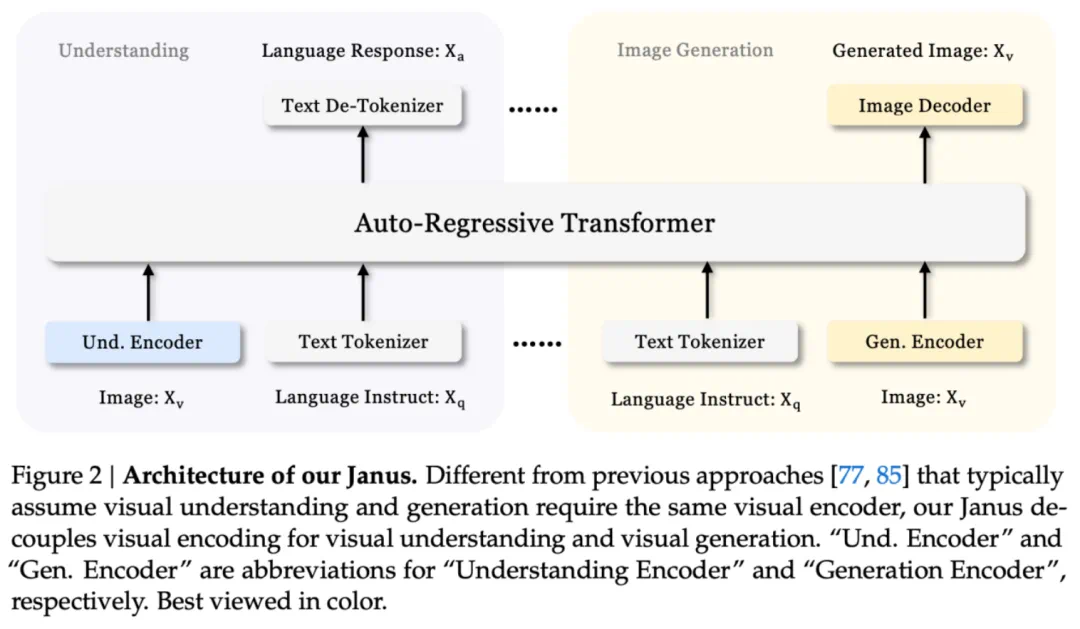
对更多模态的支持。Janus 的核心思想是解耦,对不同的输入使用不同的编码方式,然后用统一的 transformer 进行处理。这一方案的可行性,意味着 Janus 有可能接入更多的模态,如视频、3D 点云、EEG 信号等。这使得 Janus 有可能成为下一代多模态通用模型的有力候选。
-
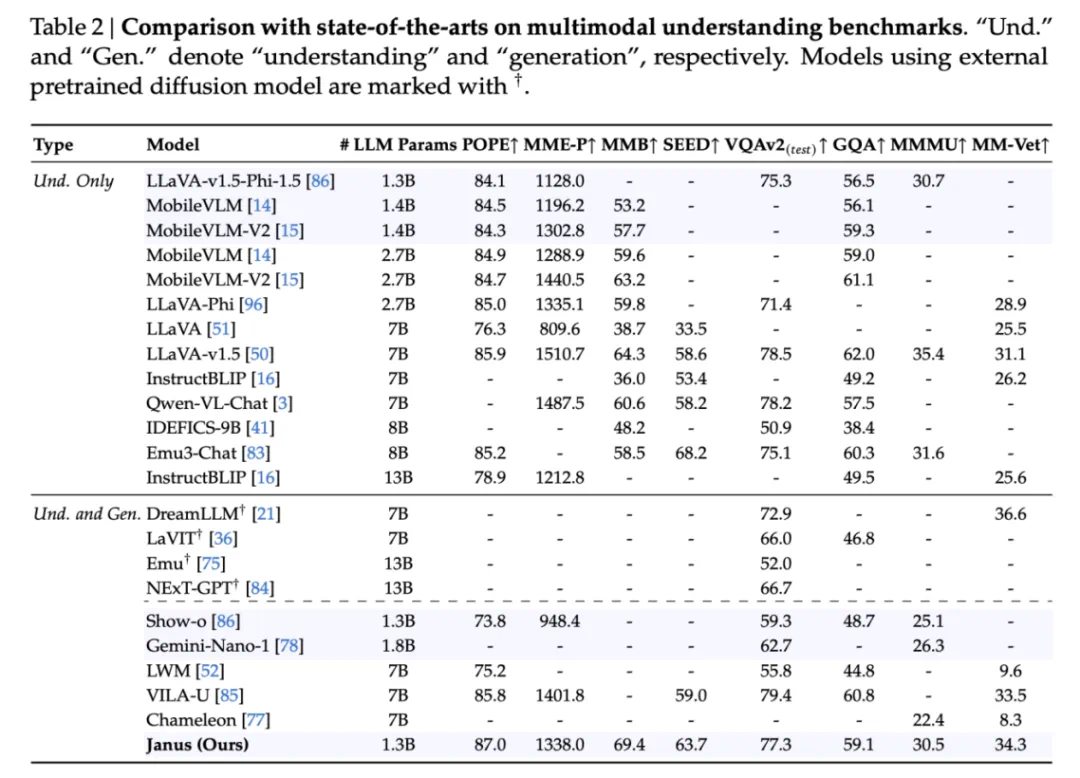
多模态理解 (Table 2)。Janus-1.3B 超越了之前同规模的统一模型。在一些 benchmark (POPE, MMBench, SEED Bench, MM-Vet) 上,Janus-1.3B 甚至超越了 LLaVA-v1.5-7B 的结果。这证实了视觉编码解耦对多模态理解性能带来了显著的提升。 -
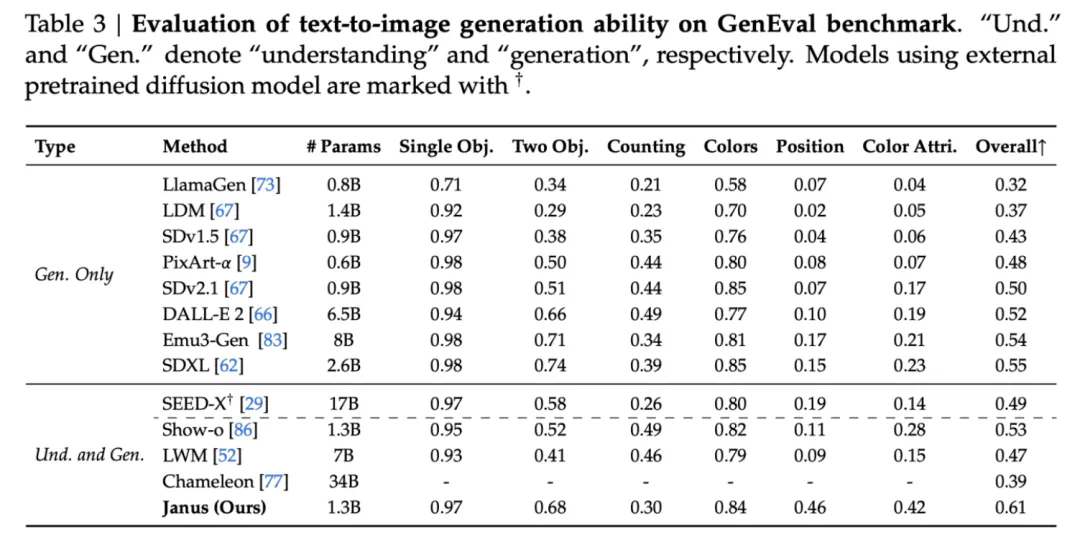
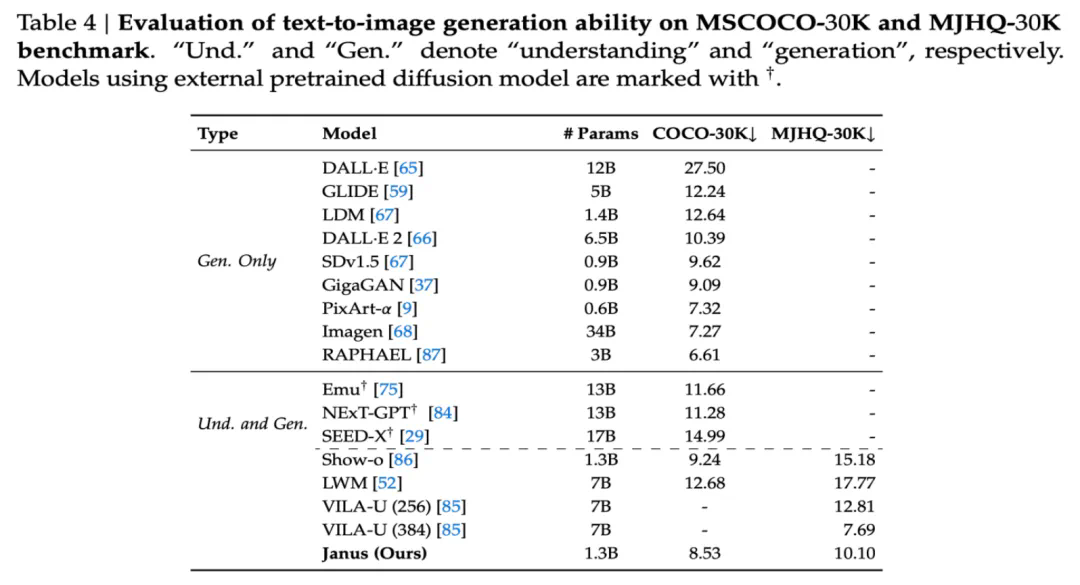
视觉生成 (Table 3 和 Table 4)。Janus-1.3B 在图像质量评价 (MSCOCO-30K 和 MJHQ-30K) 和图像生成指令跟随能力 benchmark GenEval 上都取得了很不错的结果,超越了之前同规模的统一模型,和一些专用图像生成模型,如 SDXL。