文章来源于互联网:蚁群、蜂群的智慧,大模型也可以有,谷歌等机构群体智能研究亮相
让大模型依靠群体的智能。


-
论文标题:MODEL SWARMS: COLLABORATIVE SEARCH TO ADAPT LLM EXPERTS VIA SWARM INTELLIGENCE
-
论文链接:https://arxiv.org/pdf/2410.11163

-
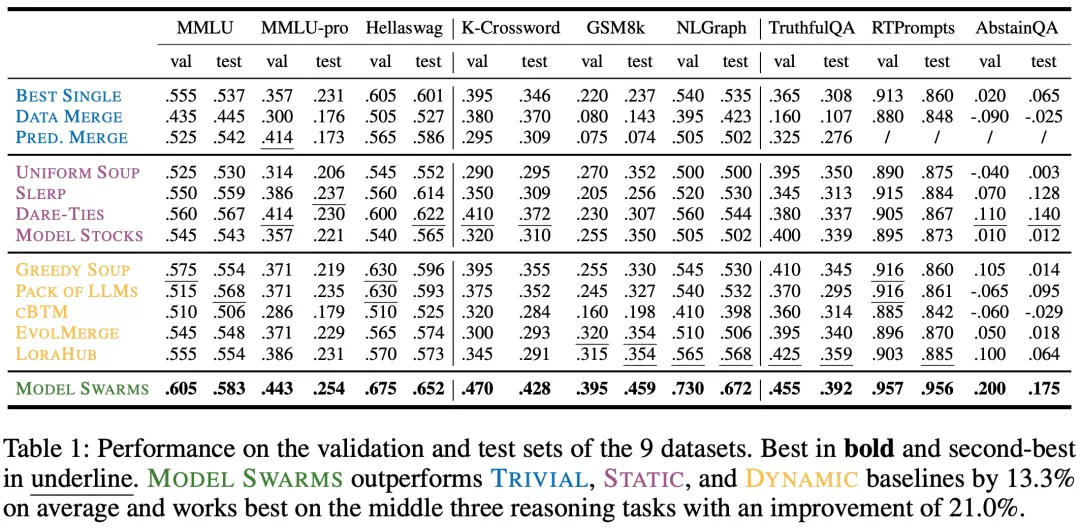
单一任务:在仅有 200 个实例的优化上,MODEL SWARMS 在涵盖知识、推理和安全性的 9 个数据集上超越了 12 个模型组合基线,平均提高了 13.3%。
-
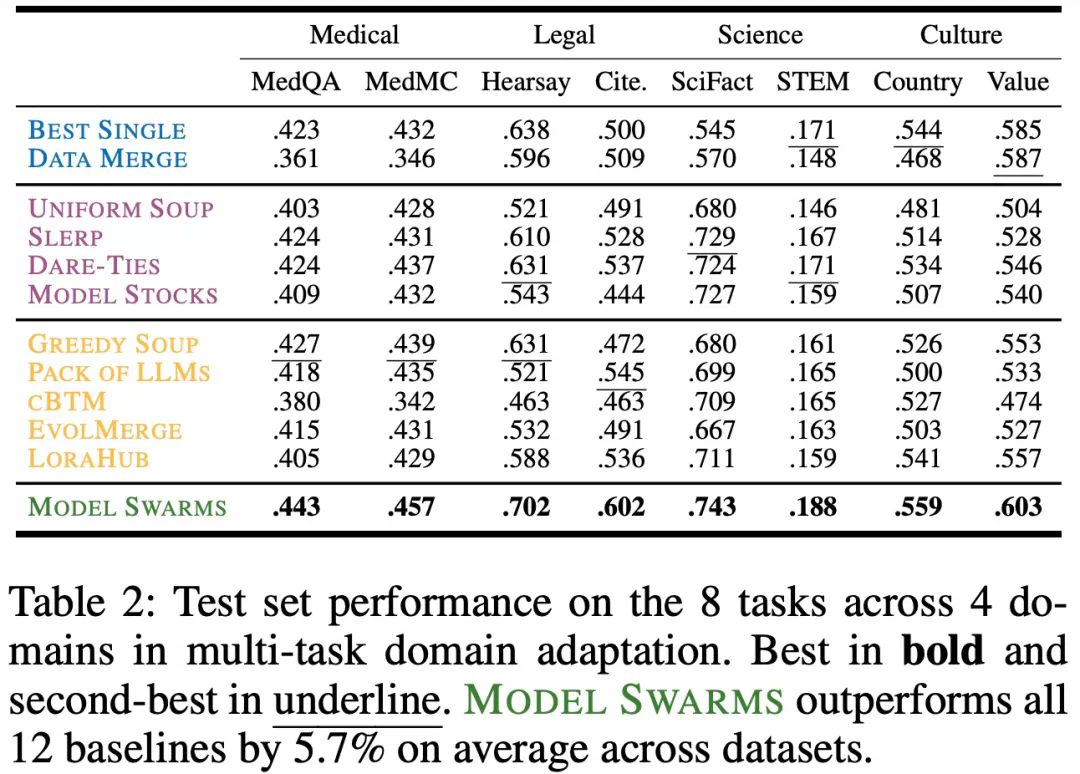
多任务领域:联合优化医疗、法律、科学和文化领域的多个任务,MODEL SWARMS 经常比单独优化单个任务产生更优的帕累托专家。
-
奖励模型:在优化一般和冲突偏好的奖励模型分数时,MODEL SWARMS 提供了可控性更高的专家,与基线相比在可控性上提高了高达 14.6%。
-
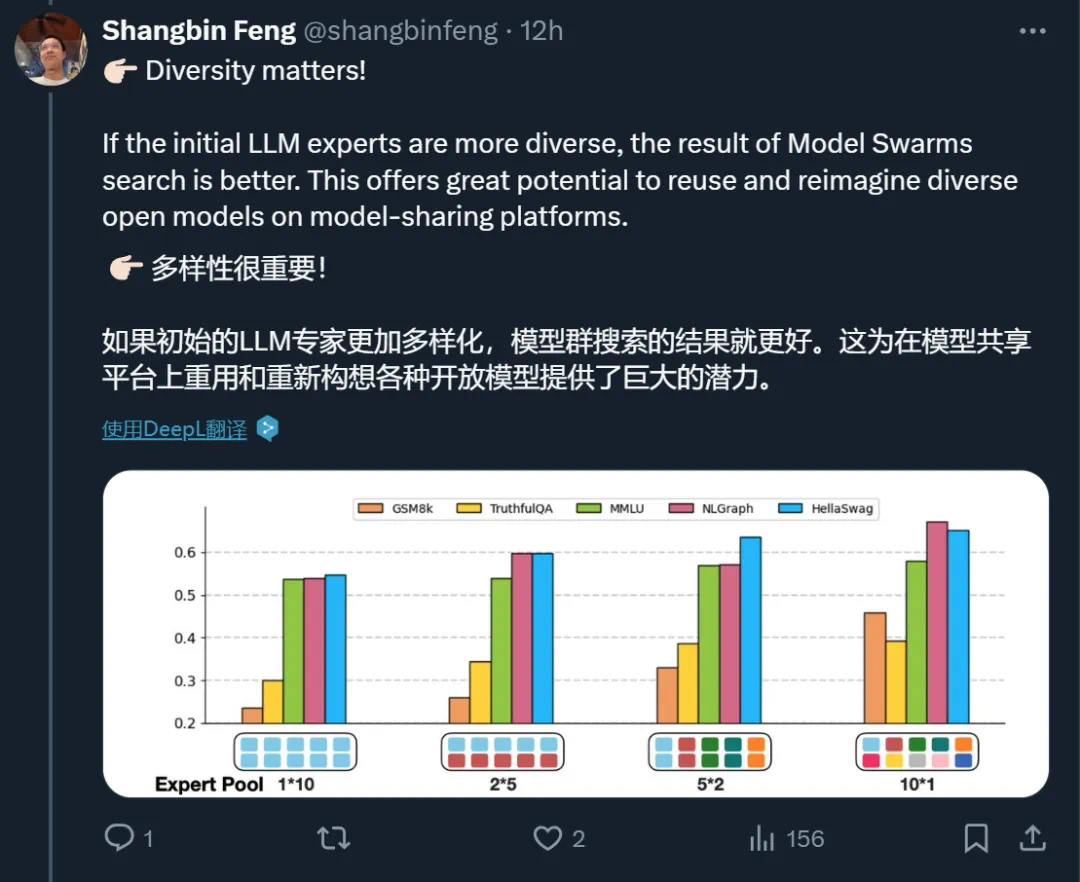
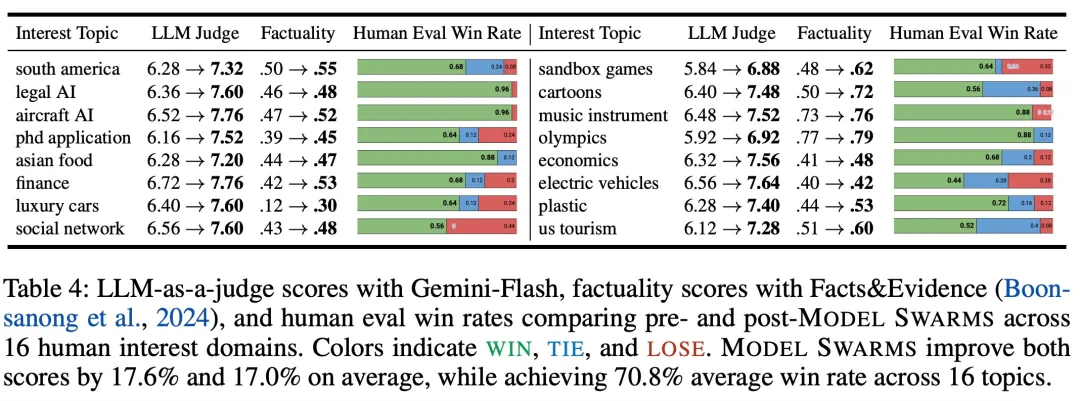
人类兴趣:在人类评估的 16 个主题(例如,电动汽车和博士申请)上,MODEL SWARMS 在 85% 的情况下产生了与现有模型相当或更好的专家。


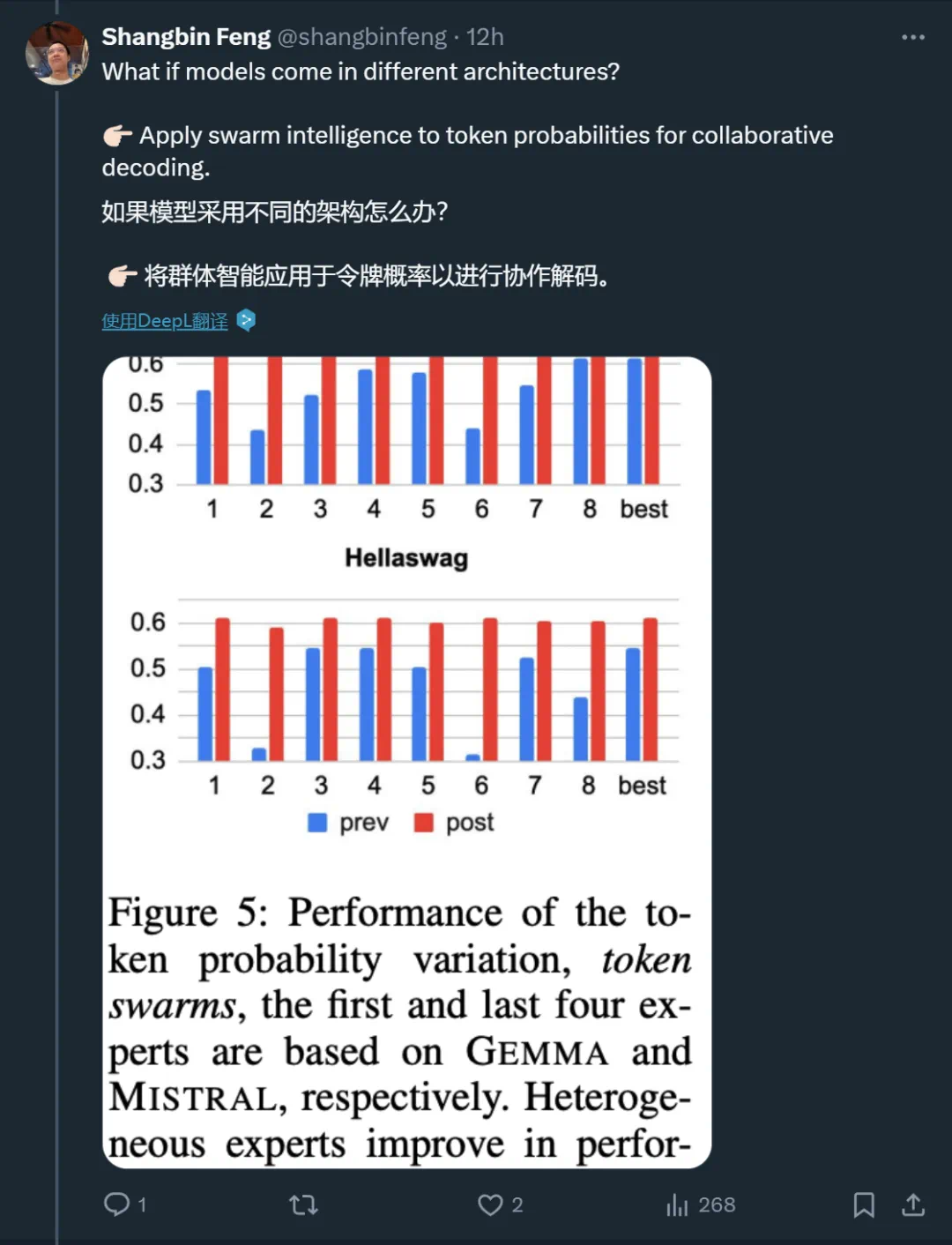
-
步骤 0. 初始化
-
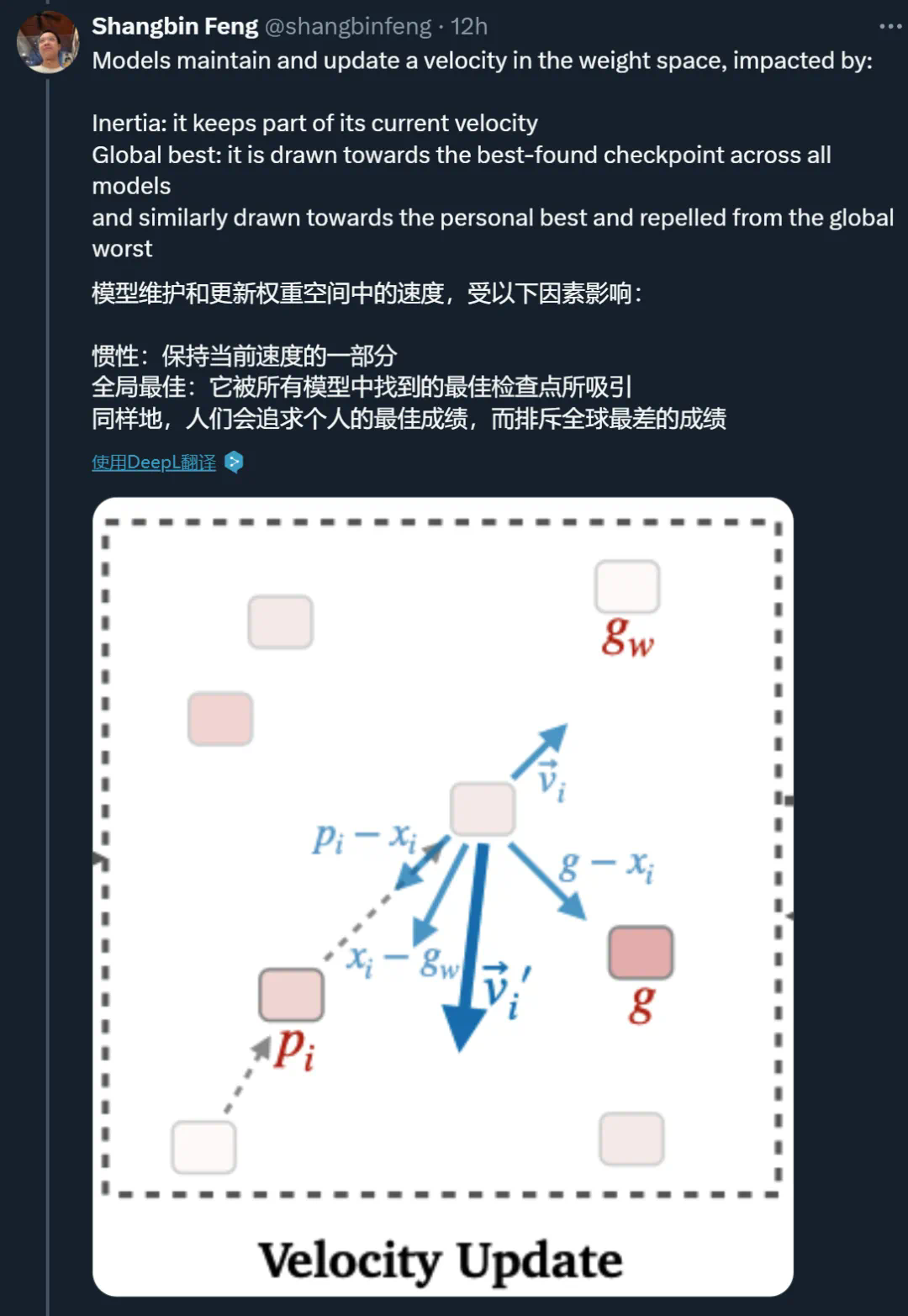
步骤 1. 速度更新
-
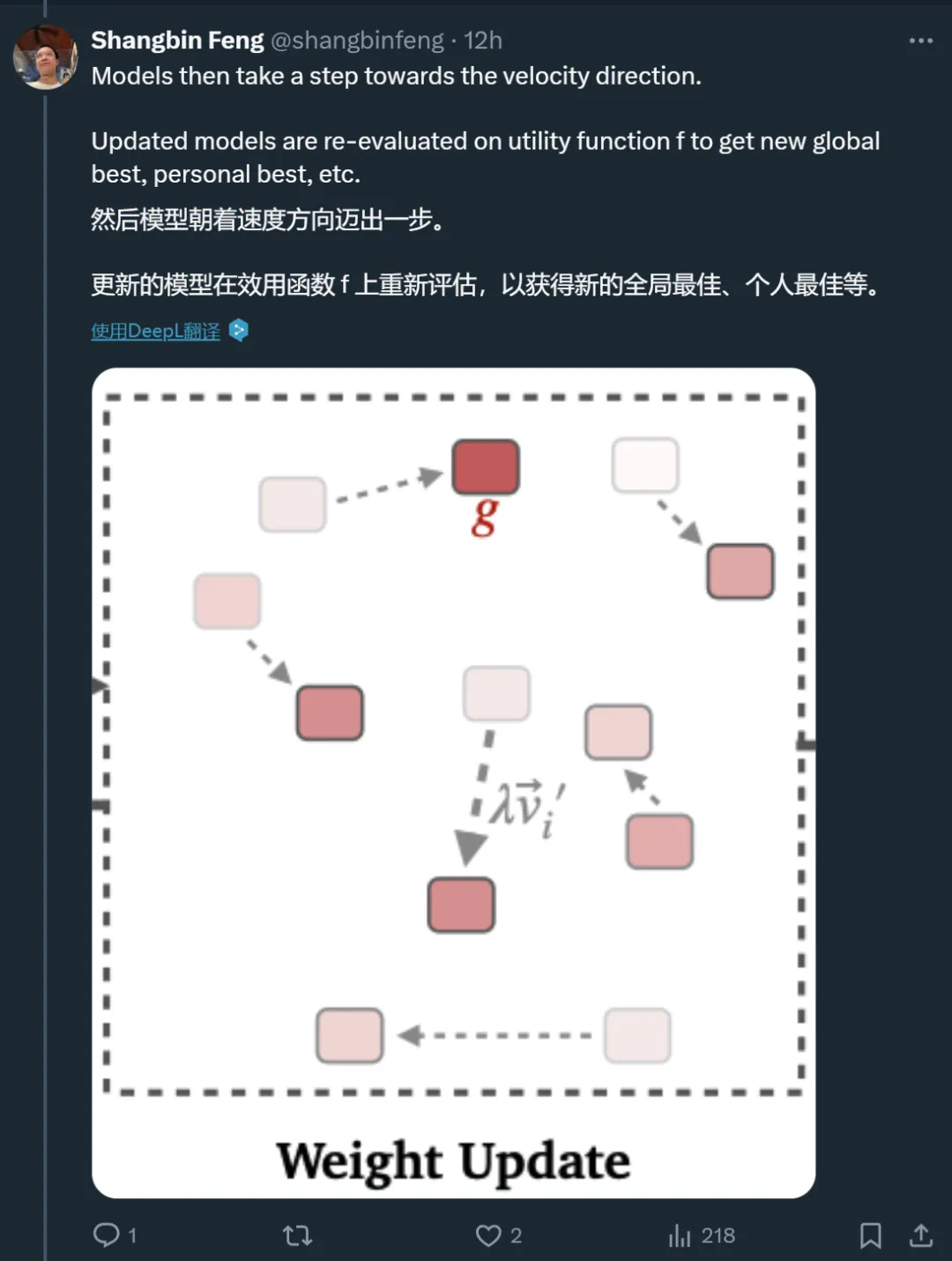
步骤 2. 权重更新
-
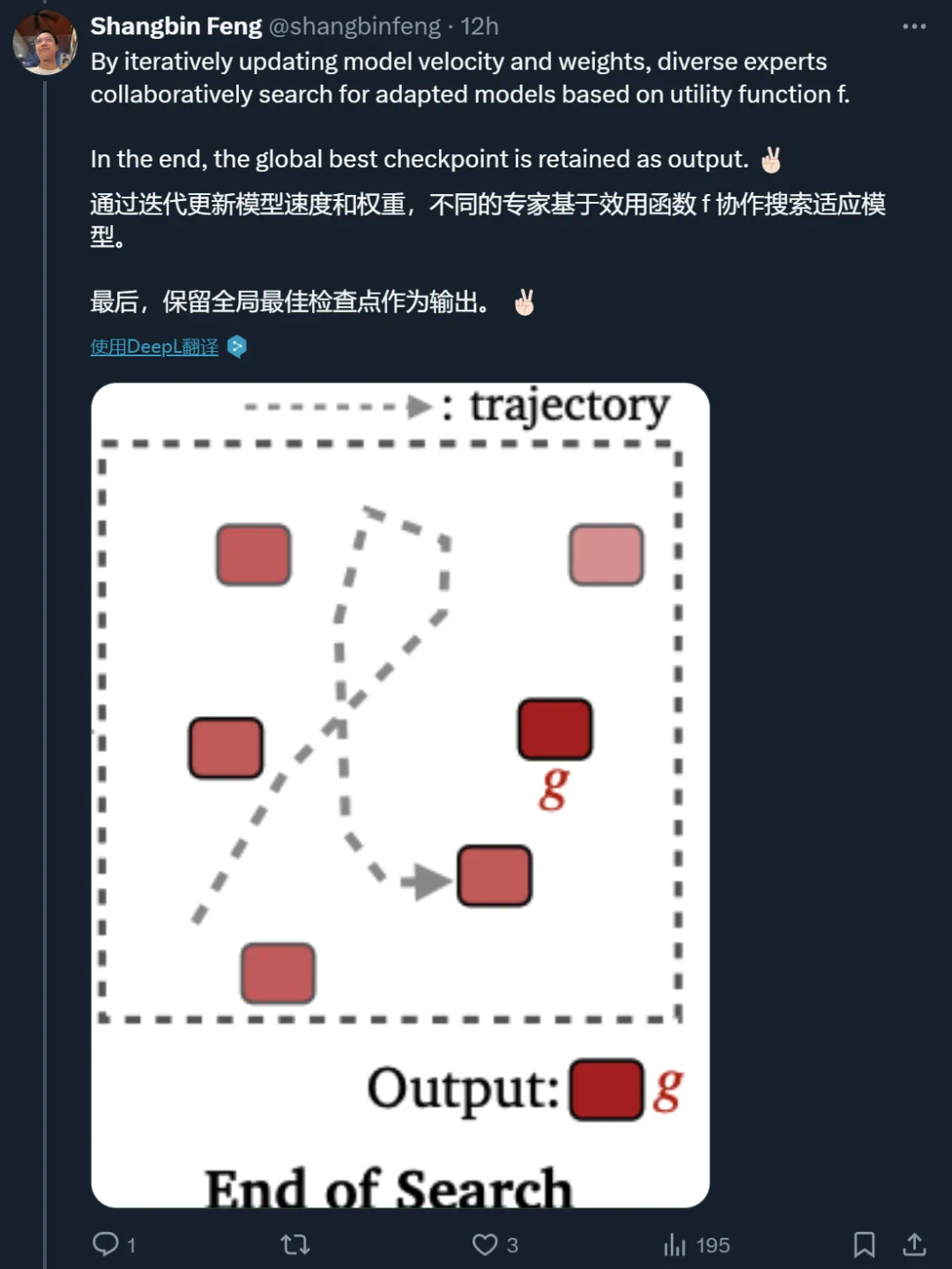
步骤 3. 迭代结束
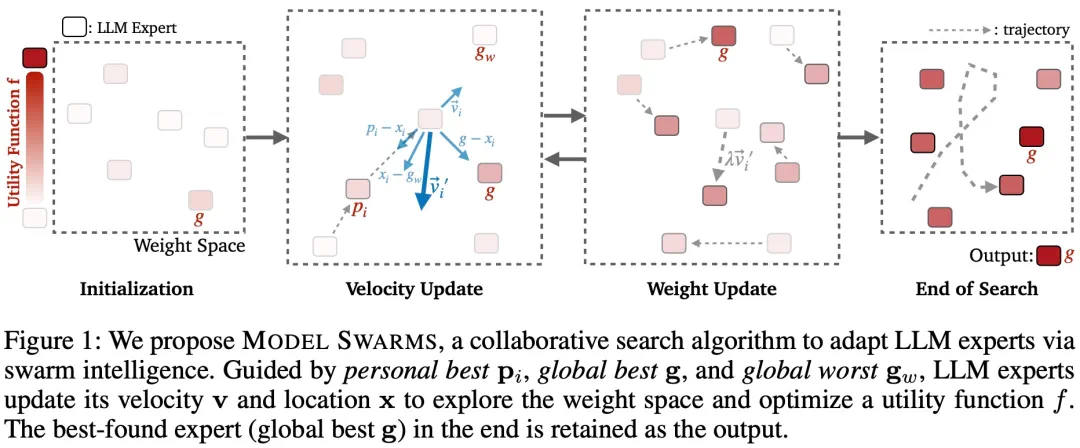

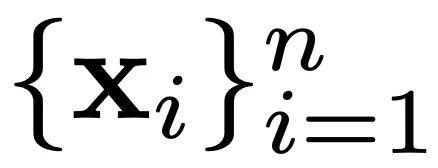 ,可以是完整模型或经过微调的 LoRA 适配器。MODEL SWARMS 还需要一个效用函数 f : x → R,将每个专家映射到一个应针对模型适应进行优化的标量值。效用函数可以是数据集性能、奖励模型分数或人类偏好。
,可以是完整模型或经过微调的 LoRA 适配器。MODEL SWARMS 还需要一个效用函数 f : x → R,将每个专家映射到一个应针对模型适应进行优化的标量值。效用函数可以是数据集性能、奖励模型分数或人类偏好。-
每个 LLM 专家,或者 MODEL SWARMS 中的「粒子」,都有一个由模型权重表征的位置;
-
每个粒子都有一个速度、模型权重空间中应该朝下一个粒子移动的方向;
-
个体最佳 p_i :基于效用函数 f 在其搜索历史中找到的 x_i 的最佳位置;
-
全局最佳和最差 g 和 g_w:所有
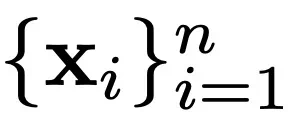 的搜索历史中最佳 / 最差位置。
的搜索历史中最佳 / 最差位置。

文章来源于互联网:蚁群、蜂群的智慧,大模型也可以有,谷歌等机构群体智能研究亮相
