文章来源于互联网:与OpenAI o1技术理念相似,TDPO-R算法有效缓解奖励过优化问题

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本论文作者主要包括澳大利亚科学院院士、欧洲科学院外籍院士、IEEE Fellow陶大程,现任南洋理工大学杰出教授;新加坡工程院院士、IEEE Fellow文勇刚,现为南洋理工大学计算机科学与工程学院校长讲席教授,同时担任IEEE Transactions on Multimedia主编;张森,曾在悉尼大学从事博士后研究工作,现任TikTok机器学习工程师;詹忆冰,京东探索研究院算法科学家。本文的通讯作者是武汉大学计算机学院教授、博士生导师、国家特聘青年专家罗勇。第一作者为张子屹,目前在武汉大学计算机学院攻读博士二年级,研究方向为强化学习、扩散模型和大模型对齐。

-
论文链接:https://openreview.net/forum?id=v2o9rRJcEv -
代码链接:https://github.com/ZiyiZhang27/tdpo

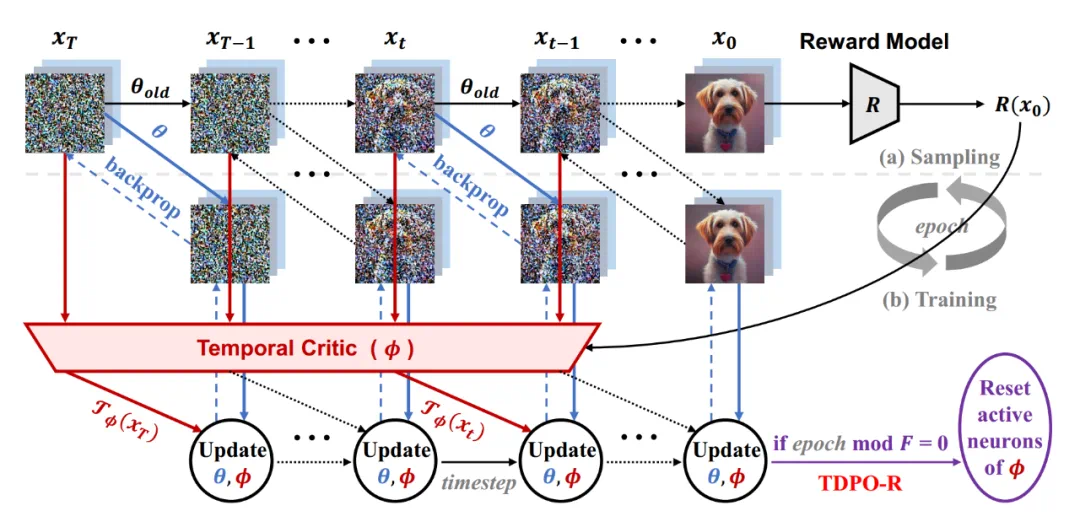
-
活跃神经元:在训练过程中频繁被激活的神经元,通常与当前任务的主要模式相关。 -
休眠神经元:在训练中很少被激活的神经元,通常被认为对当前任务贡献较少,甚至被认为会阻碍模型的学习能力。
-
活跃神经元更易受到首要偏置的影响:由于活跃神经元频繁参与早期训练任务,它们倾向于过拟合早期的学习模式。因此,这些神经元在模型的优化过程中可能会过度强化某一特定奖励目标,导致奖励过优化问题的加剧。例如,模型可能因为过度优化早期阶段的奖励信号,导致后续的生成结果表现不佳,甚至在其他奖励函数上的泛化能力下降。 -
休眠神经元作为自适应正则化手段:与活跃神经元相反,休眠神经元由于较少参与训练任务,反而可以作为一种对抗奖励过优化的自适应正则化手段。这是因为,休眠神经元的低激活状态意味着它们没有过度依赖早期的奖励信号,从而在模型后期的训练中可以起到平衡的作用。另外,它们还能够提供一种类似于 “潜力储备” 的功能,在奖励函数发生变化或模型过拟合早期奖励信号时,休眠神经元可以重新被激活,以补充模型的适应能力,增强模型的泛化性能。
-
周期性神经元重置:在训练过程中,TDPO-R 会定期对评判器(critic)模型中过度活跃的神经元进行重置,降低它们的激活频率,从而打破它们在早期阶段对特定奖励信号的过拟合。通过这一操作,模型可以避免过度强化某一奖励目标,确保生成过程的多样性和泛化能力。 -
重新激活休眠神经元:随着活跃神经元被重置,模型的其他神经元,包括那些此前处于休眠状态的神经元,会被激活,以参与新的学习任务。这种神经元的 “轮替” 确保了模型的学习能力不会因为早期训练经验的固定化而受到限制,从而缓解了奖励过优化的问题。
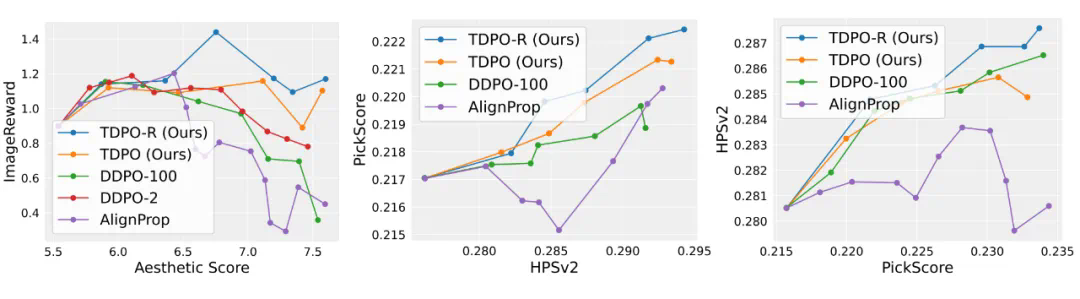


文章来源于互联网:与OpenAI o1技术理念相似,TDPO-R算法有效缓解奖励过优化问题

