
前言
在上一篇【项目实战】基于esp32开发板+大模型实现的陪伴助手-硬件篇中,我们完成了硬件的组装、IDE环境的配置以及程序的测试。
本章,我们将基于上一章的硬件,完成唤醒词训练、唤醒词集成,并将唤醒词识别集成至ESP32开发板。
唤醒词识别
功能简述
唤醒词识别是语音助手的核心功能之一,它使设备能够在用户发出特定指令时进行响应。当用户说出唤醒词后,音箱会立即进入待命状态,准备接收后续的语音指令。
例如,小爱音箱通过"小爱同学"这一唤醒词来激活语音识别系统。
原理实现
graph TD;
A[音频采集] --> B[信号处理];
B --> C[特征提取];
C --> D[模型识别];
D --> E{是否匹配唤醒词?};
E -- 是 --> F[响应执行];
E -- 否 --> A;-
音频采集:设备通过麦克风持续监听周围的声音,采集音频信号。
-
信号处理:对采集到的音频信号进行预处理,包括去噪、增益调整等,以提高后续识别的准确性。
-
特征提取:从处理后的音频信号中提取特征。
-
模型识别:将提取的特征输入到训练好的深度学习模型中,模型会判断是否匹配预设的唤醒词。如果匹配成功,系统将触发相应的响应机制。
-
响应执行:一旦识别到唤醒词,设备将进入待命状态,准备接收用户的后续指令,并执行相应的操作。
1. 模型训练
1.1 数据准备
1.1.1 烧写程序
代码路径: examples/capture_audio_data
操作步骤:
- 打开
capture_audio_data.ino文件 - 开启开启psram,编译程序
- 编译通过后,上传程序至ESP32开发板。
注意:
- 因为录制音频需要将数据保存至SD卡,所以需要将SD卡插入开发板。
1.1.2 录制音频
录制方法:
- 程序运行正常后,打开串口助手工具。
- 录制唤醒词:在串口工具中,发送标签控制指令"danzai",然后发送录制音频指令"rec",录制音频(10s)。
- 录制噪音:发送标签控制指令"noise",然后发送录制音频指令"rec",录制音频(10s)。
- 录制其他声音:发送标签控制指令"unknown",然后发送录制音频指令"rec",录制音频(10s)。
说明:
因为唤醒词识别中,声音的构成有三部分组成:唤醒词、噪音和其他声音。所以,我们在录制音频的时候,分别录制三部分音频,即:(以下标签是自己定义的,以便区分)
- 唤醒词:danzai
- 噪音:noise
- 其他声音:unknown
录制结果:
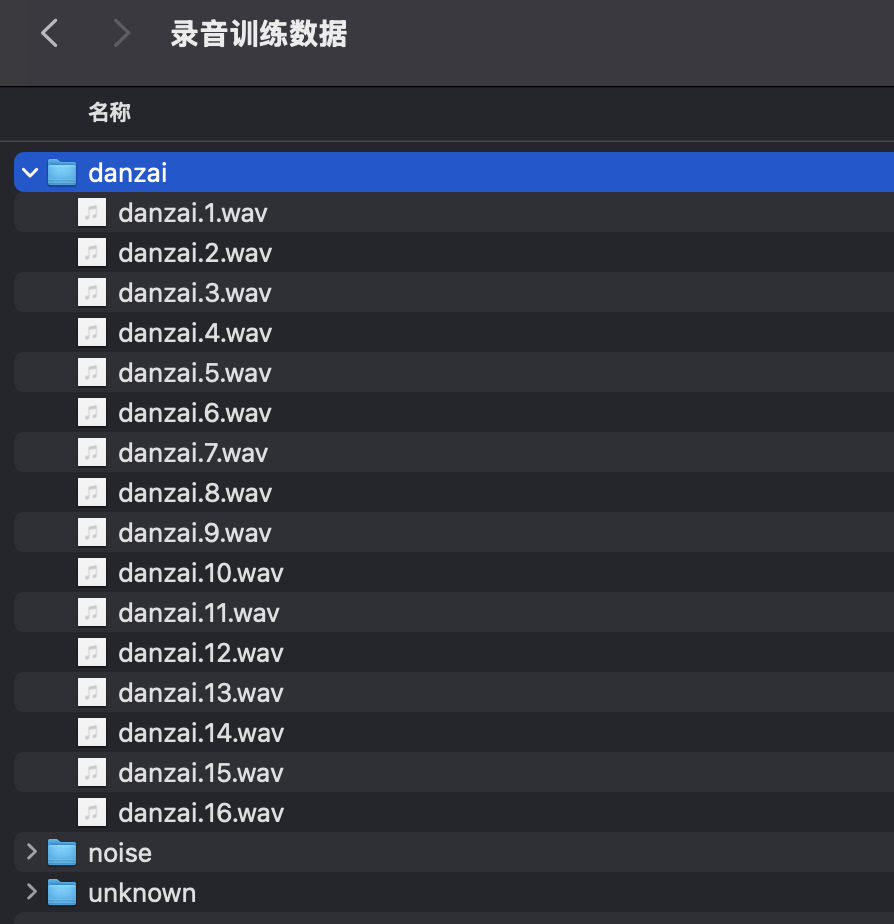
说明:
- 录制音频的数量自行决定,此处我录制了16个唤醒词音频、16个噪音、16个其他声音(每个音频10s)。
- 录制音频的内容中:
- 唤醒词需要在不同方位、不同音量、不同语速、不同音调,重复对着麦克风呼叫唤醒词"蛋仔"(因为儿子喜欢蛋仔,所以唤醒词为蛋仔)。唤醒词样本越丰富,识别的泛化能力越强。
- 噪音需要录制不同环境下的噪音,如:室内没人的情况、室内看电视、打字敲键盘等。
- 其他声音需要录制非唤醒词的声音,如:播放音乐、对话(但是内容不涉及唤醒词)等。
1.2 数据切分
1.2.1 访问Edge Impulse
操作步骤:
- 登录Edge Impulse,https://edgeimpulse.com/
- 注册账号
- 通过
create new project创建工程
1.2.2 数据上传
操作步骤:
-
点击
add exsiting data -
选择
upload data
-
选择SD卡导入到电脑上的音频文件并上传。
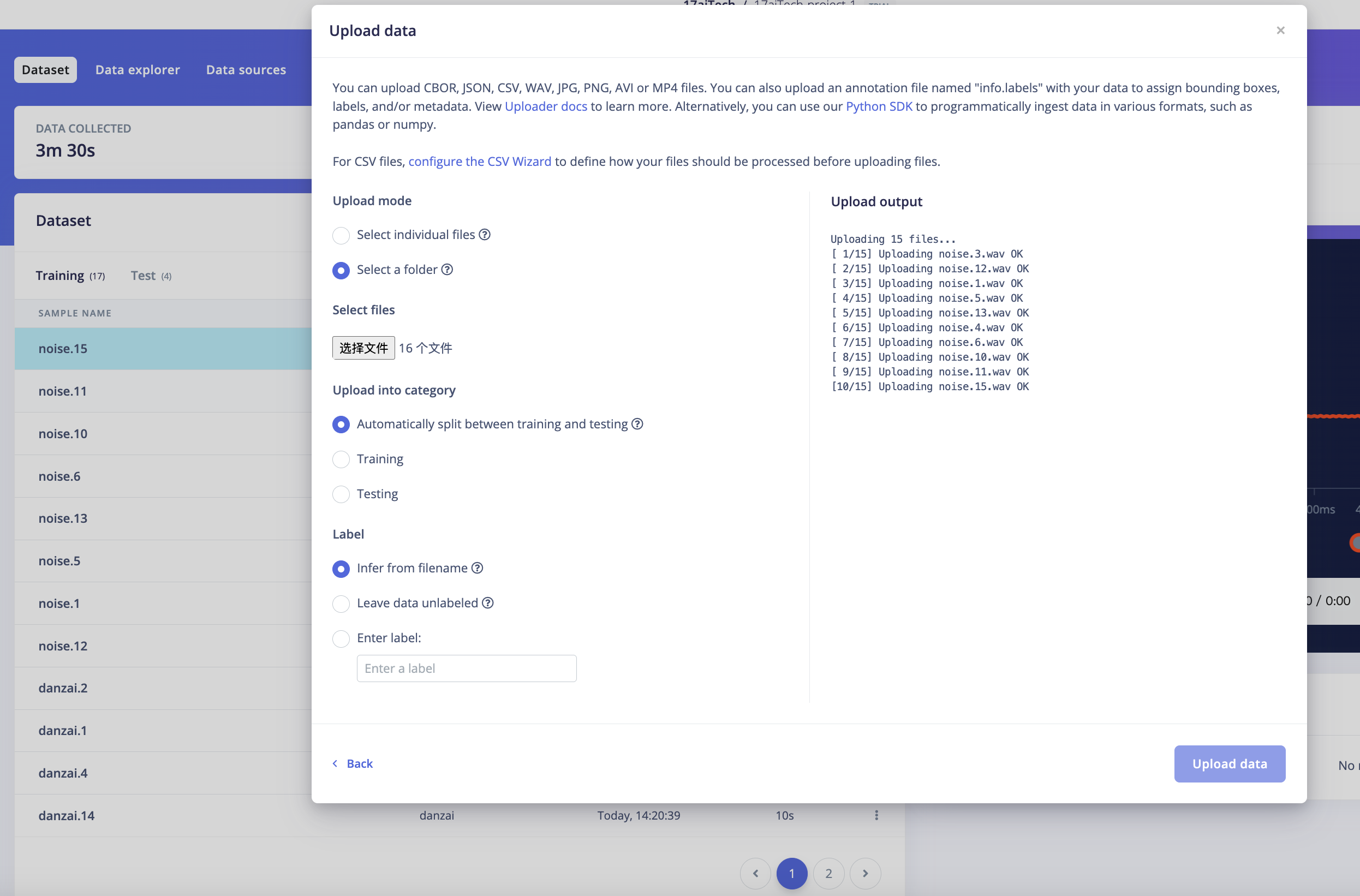
说明:
数据上传完成后,系统会自动将它们分为Training、Test集(按照80% 20%的比例)。
1.2.3 数据分割
操作步骤:
-
选择列表的数据
-
点击右侧的菜单,选择
Split sample,平台会将声音文件切分为大致1s的音频片段
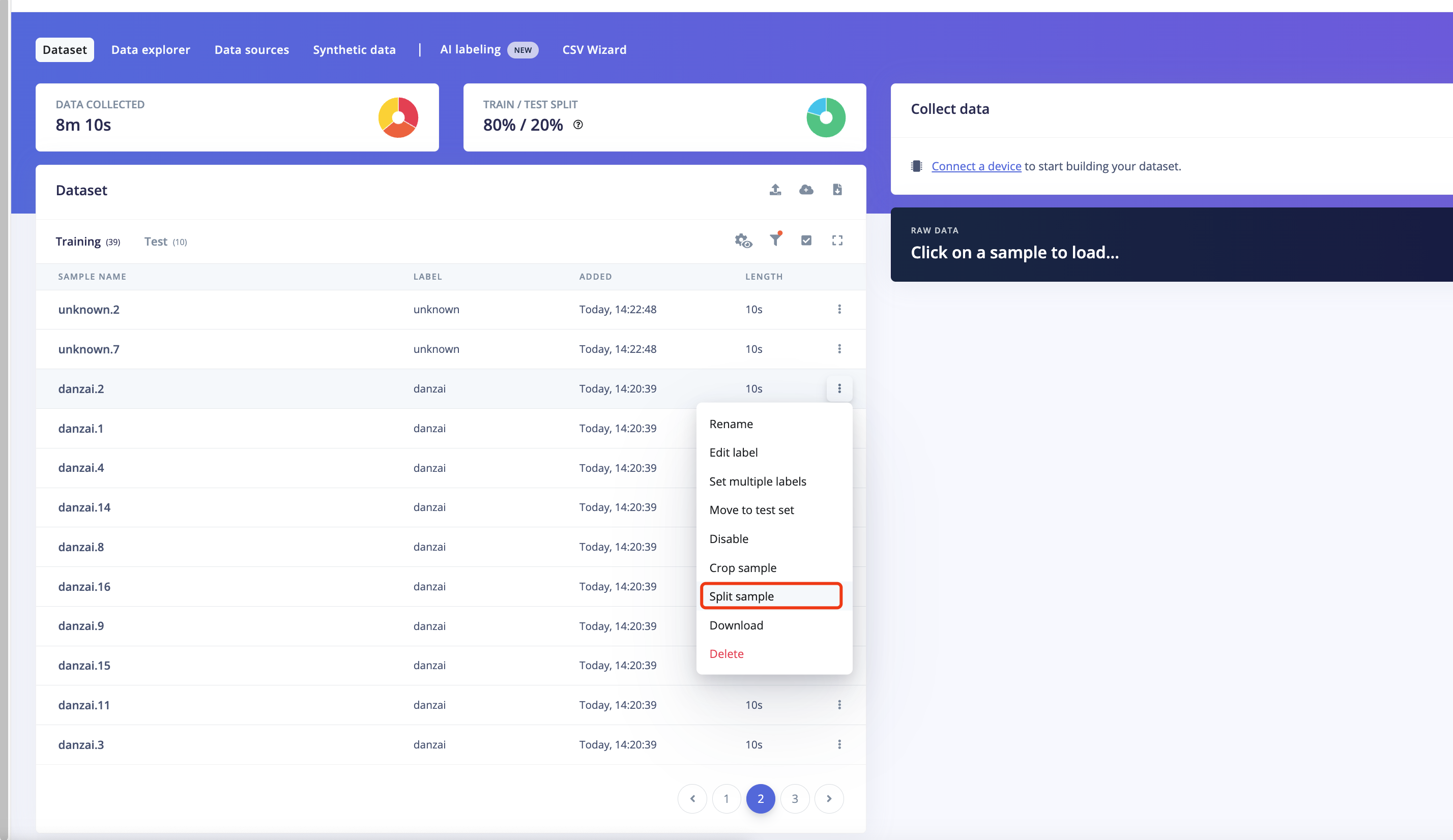
-
在分割音频界面,可以调整音频片段,以覆盖唤醒词的声音内容。

-
选择对应的音频文件,在右侧的播放进行试听和调整

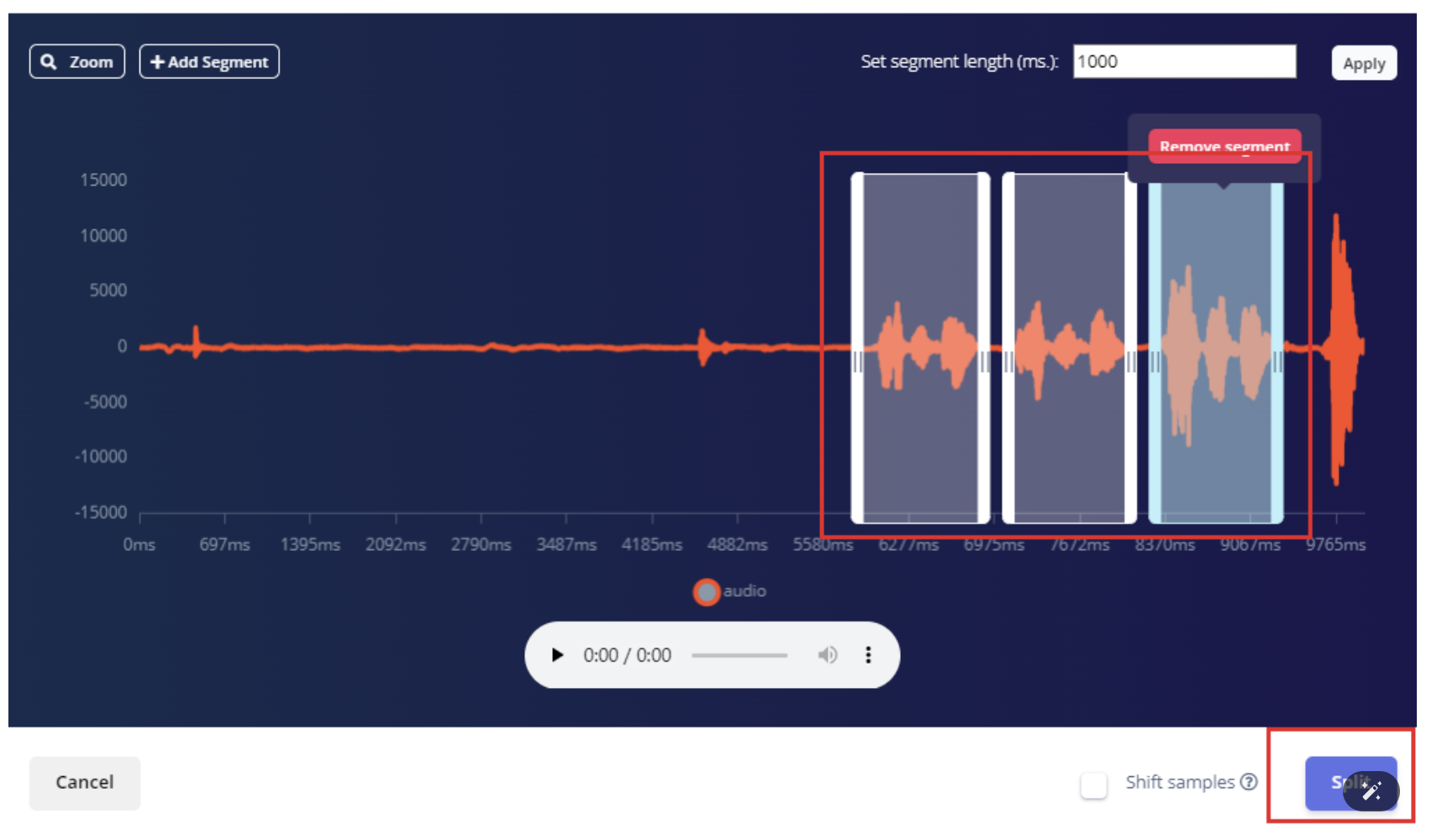
每个矩形框就是拆分提取的一个子模块,如有必要,可以调整矩形的位置,让其完全覆盖住我们的唤醒词音频区,或者也可以做一些添加或删除片段的操作。
1.3 模型训练
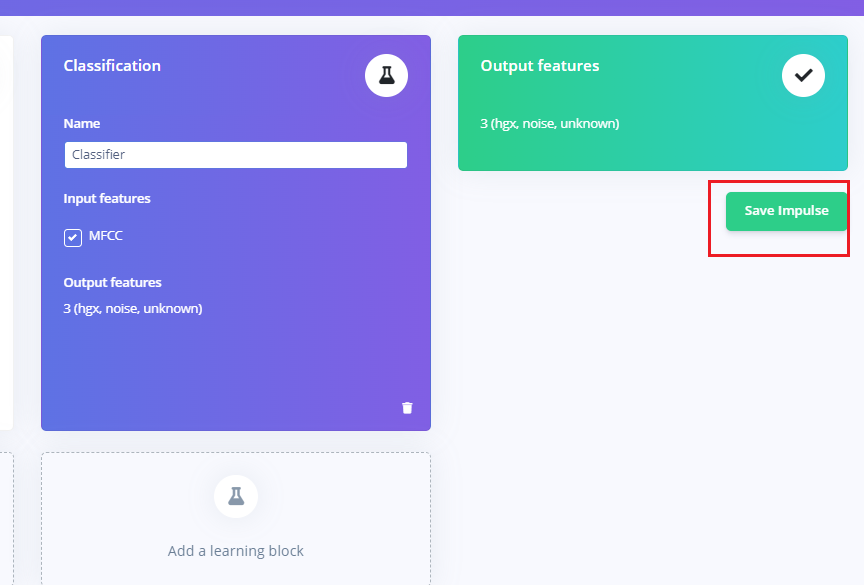
1.3.1 创造脉冲信号(预处理/模型定义)
操作步骤:
-
点击左侧
Create impulse -
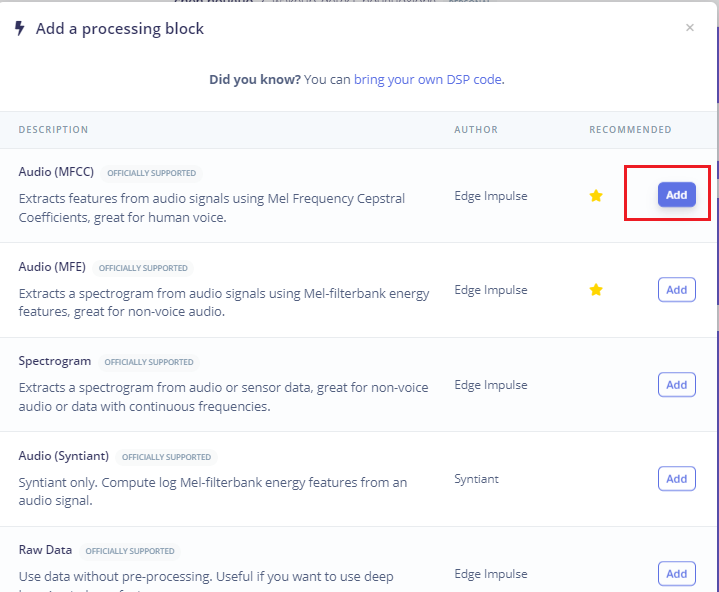
然后点击
Add a processing block添加Audio(MFCC),

-
使用
MFCC,它使用梅尔频率倒谱系数从音频信号中提取特征,这对人类声音非常有用。
-
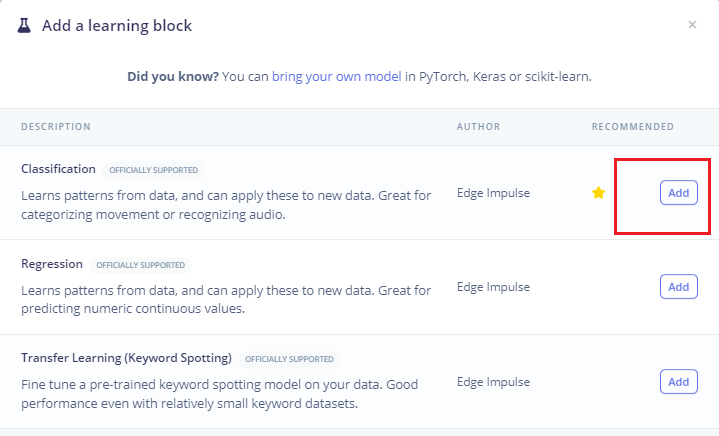
然后点击
Add a learning block添加Classification模块,它通过使用卷积神经网络进行图像分类从头开始构建我们的模型。
-
最后点击save impulse,保存配置。
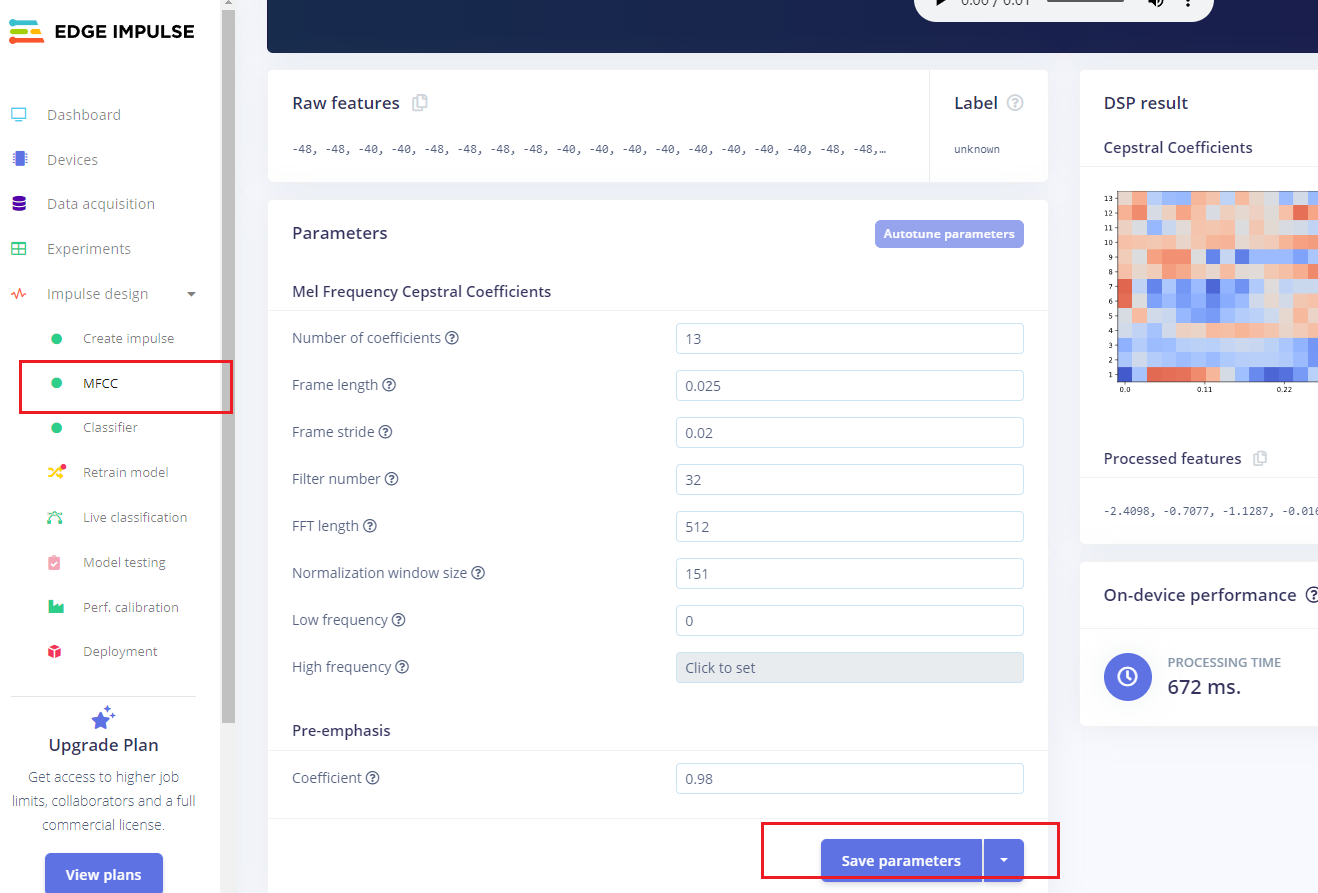
1.3.2 预处理(MFCC)
下一步,我们创建下一阶段要训练的图像。
操作步骤:
-
点击MFCC,我们可以保留默认参数值
-
直接点击Save parameters。
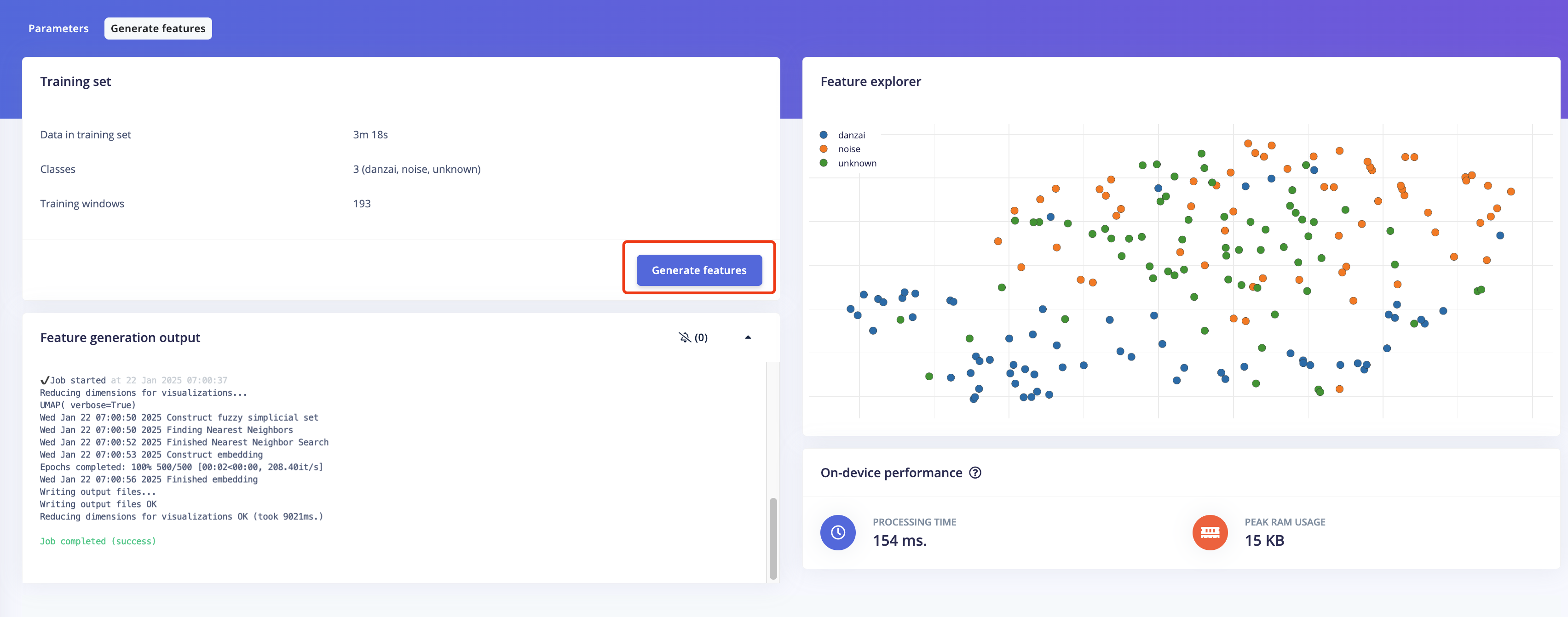
-
点击
Generate features,生成3个标签数据的特征。
1.3.3 模型设计与训练(Classifier)
下一步,我们需要对模型的结构进行设计和开始训练,步骤如下:
操作步骤:
-
点击左侧
Classifier,整个模型的结构设计已经配置好 -
然后点击
save&train,开始训练模型。
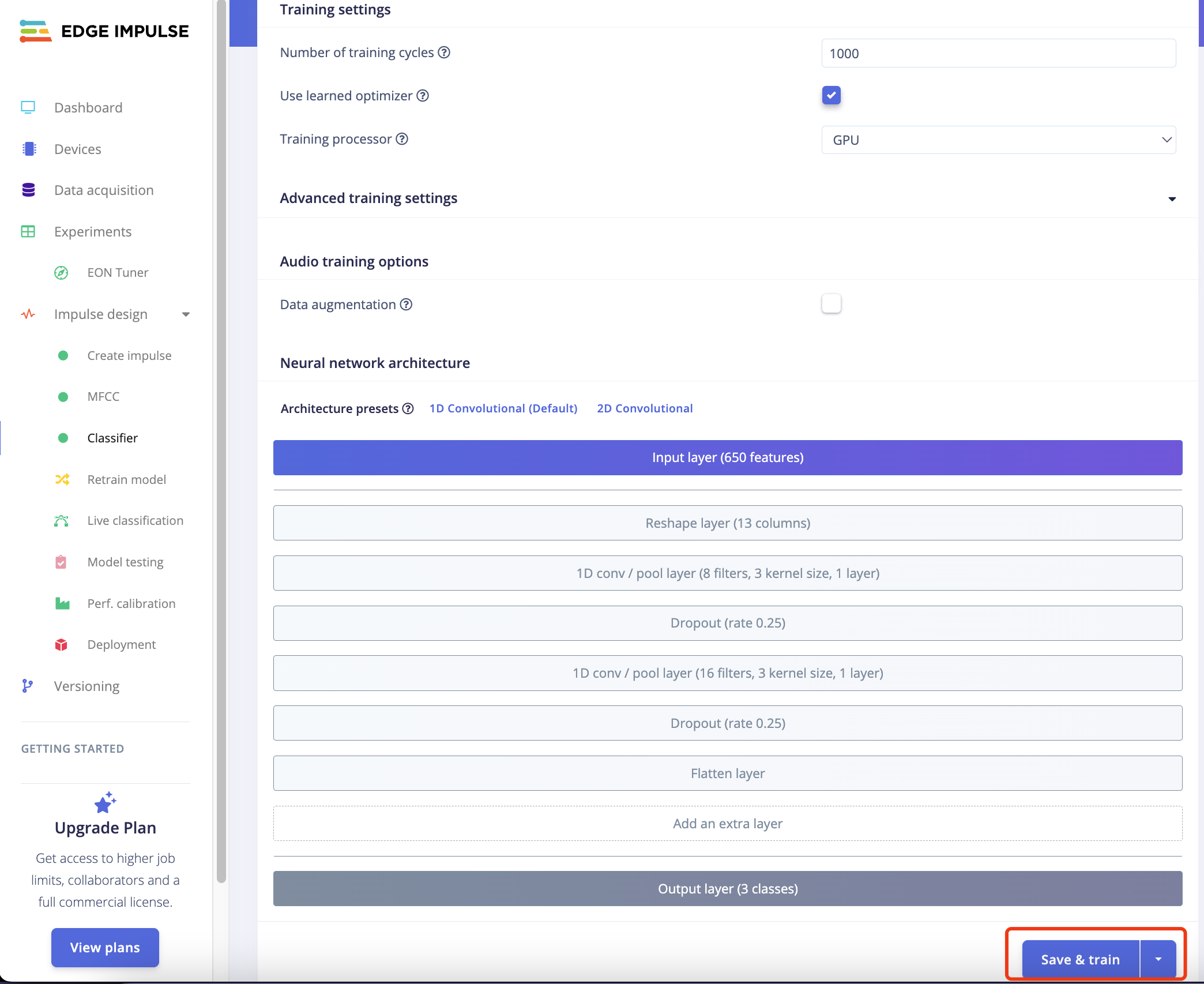
-
训练完成后,会出现如图所示的分类结果。
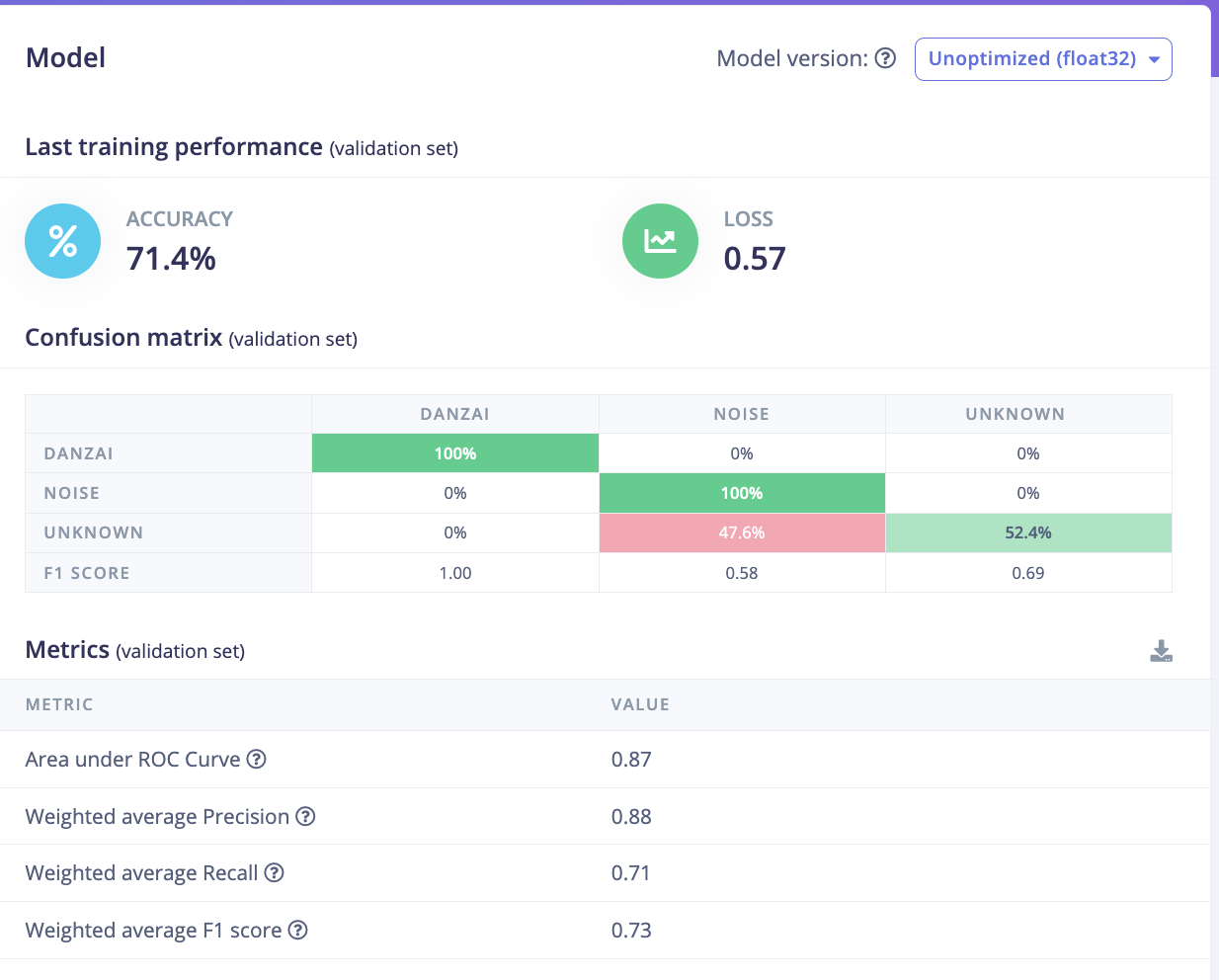
1.3.4 模型评估
操作步骤:
-
点击左侧的
Model testing -
然后点击
Classify all -
开始分类所有的测试集数据。
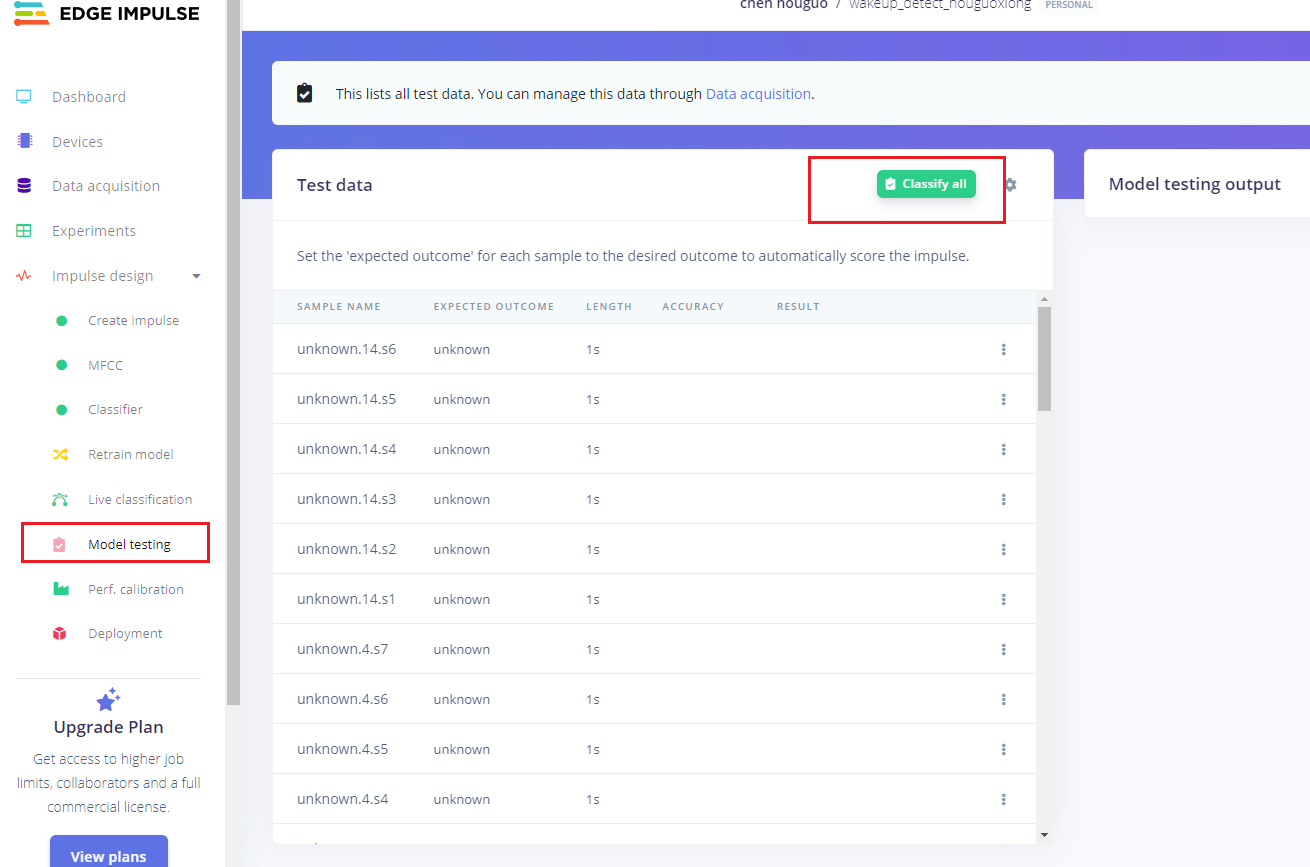
-
测试之后,可以在右侧的
Result查看测试结果。
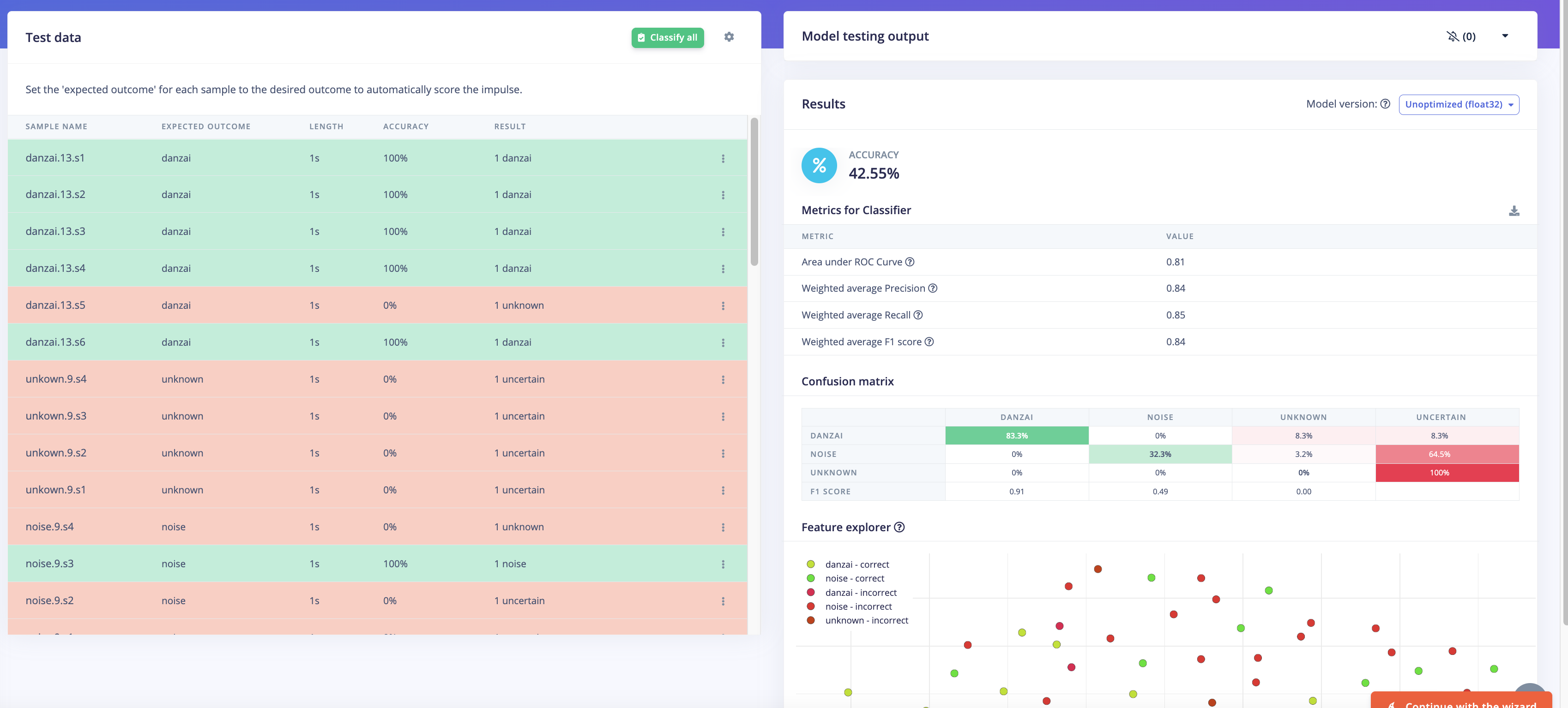
说明:
- 通过多次迭代 1.3.3和1.3.4,可以提升模型泛化能力。
- 经过验证,提升方法包括:优化测试数据集、调整模型结构(如增加更多卷积层)等。
- 平台默认的神经网络是两层卷积,我曾尝试增加到4层卷积,准确率可以从79%提升至94.9%。
- 平台对于训练时间有限制要求,免费用户只能进行训练时间在20分钟以内的训练;如果需要不限时间,需要购买付费服务才可以进行。
- 使用企业邮箱注册有14天不限时间的训练权限,可以薅一把羊毛。
2. 模型集成
2.1 生成模型库文件
模型训练完成后,我们需要生成在arduino esp32平台上运行的库文件。
操作步骤:
-
设置硬件平台
-
点击右上角的
Target, -
选择
Target device为ESP-EYE, -
然后点击
Save。
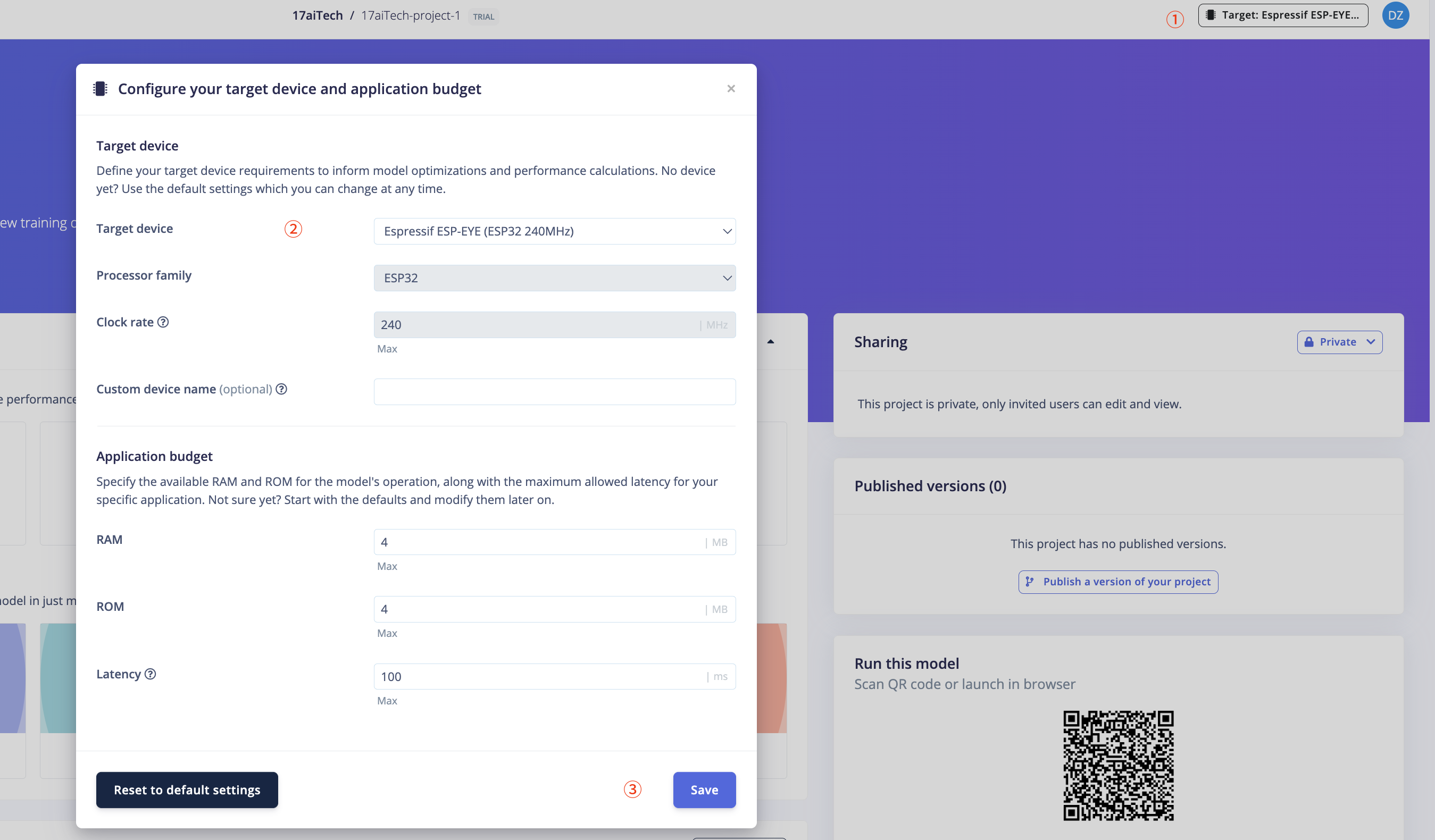
-
点击左侧
Deploment -
搜索
Arduino library -
然后点击
Build,待build完成后,保存下载的库文件。


2.2 模型库测试
代码路径: example/wake_detect
操作步骤:
-
使用arduino IDE打开
wake_detect工程 -
使用项目菜单→导入库→添加.zip库文件,选择上一步保存的文件
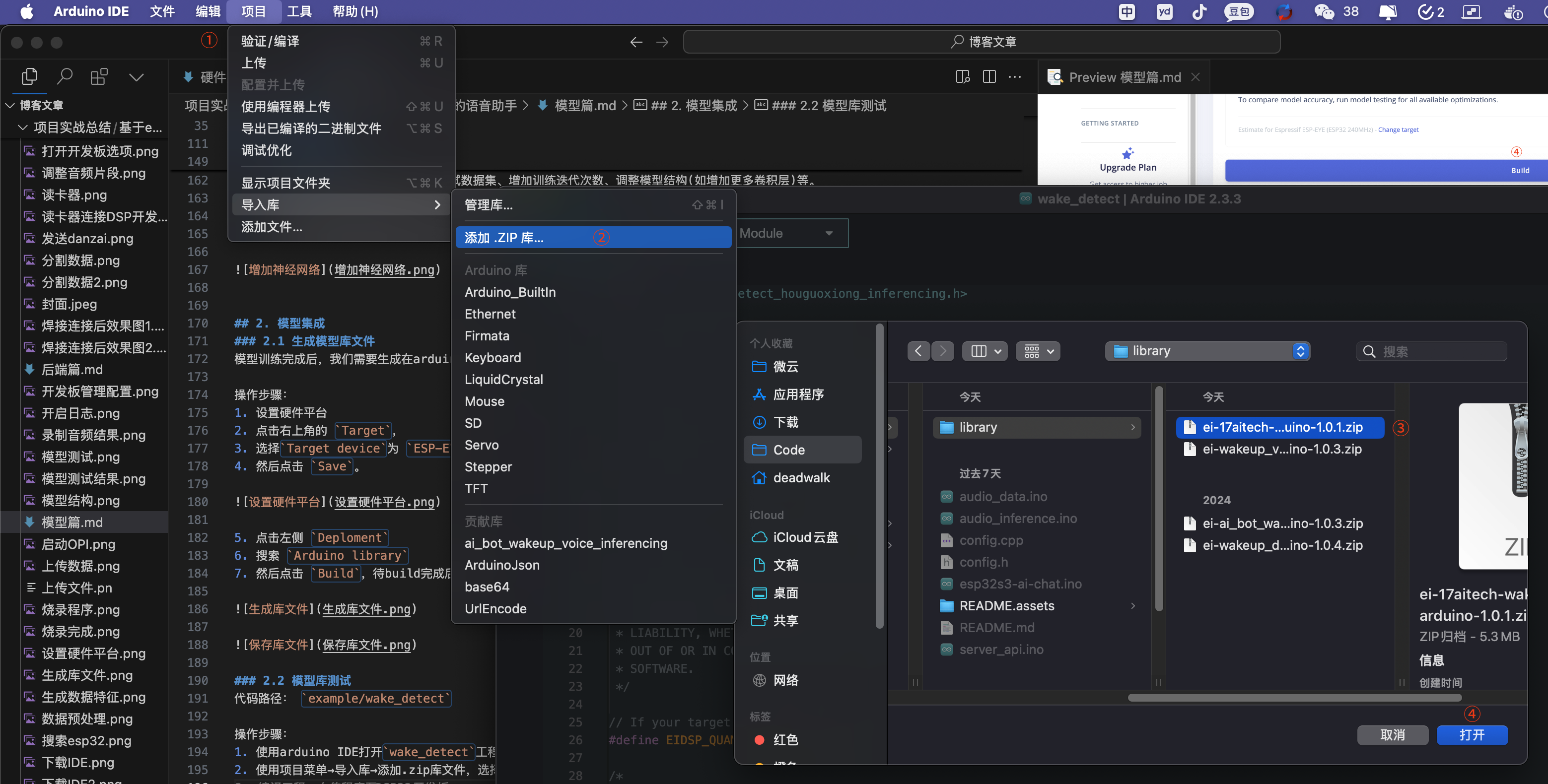
-
使用项目菜单→选择之前导入的库,在代码的头文件会增加如图所示的声明
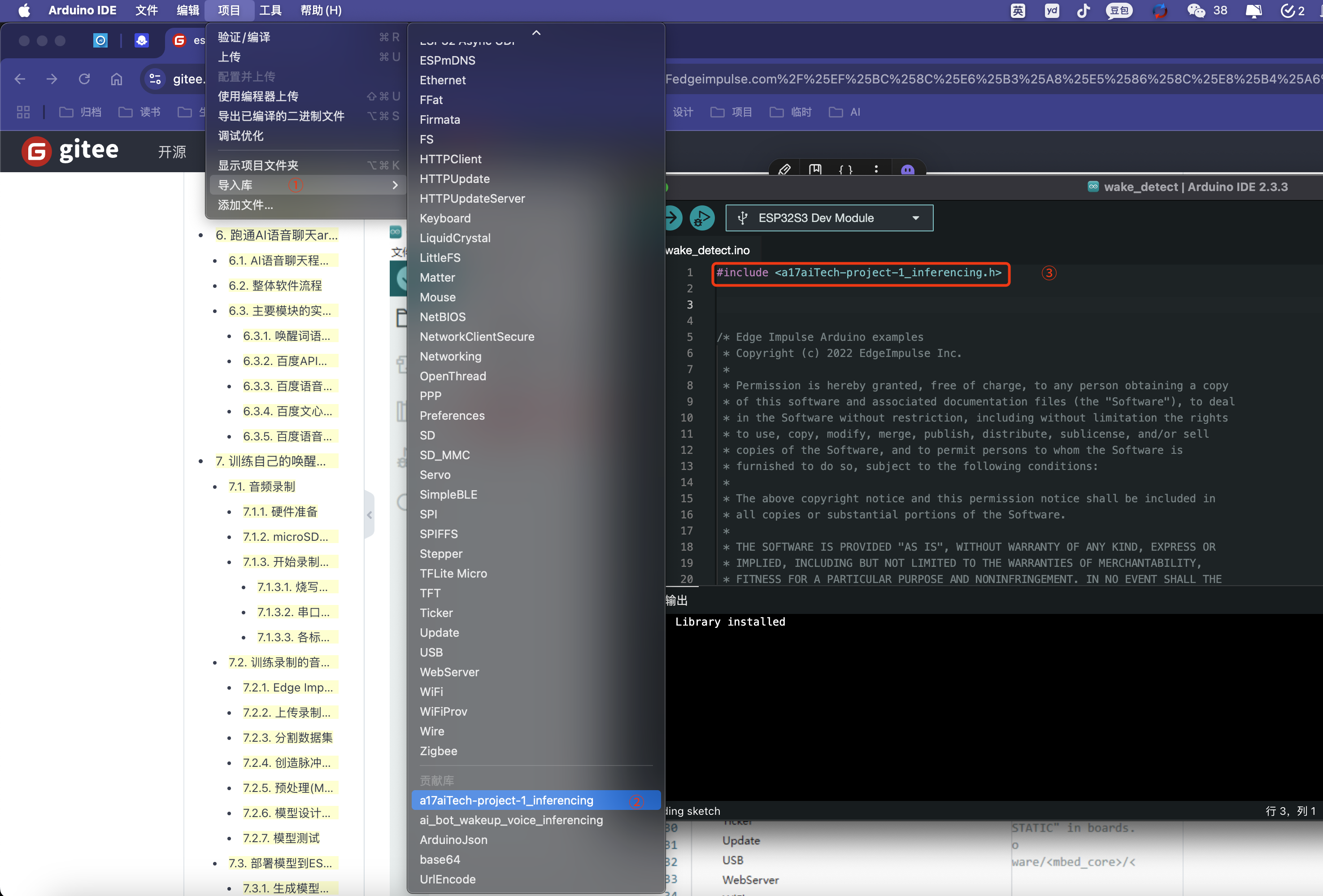
-
编译程序并上传至esp32开发板
-
打开串口助手工具,查看串口输出日志(标签后的数字代表该标签的置信率)。
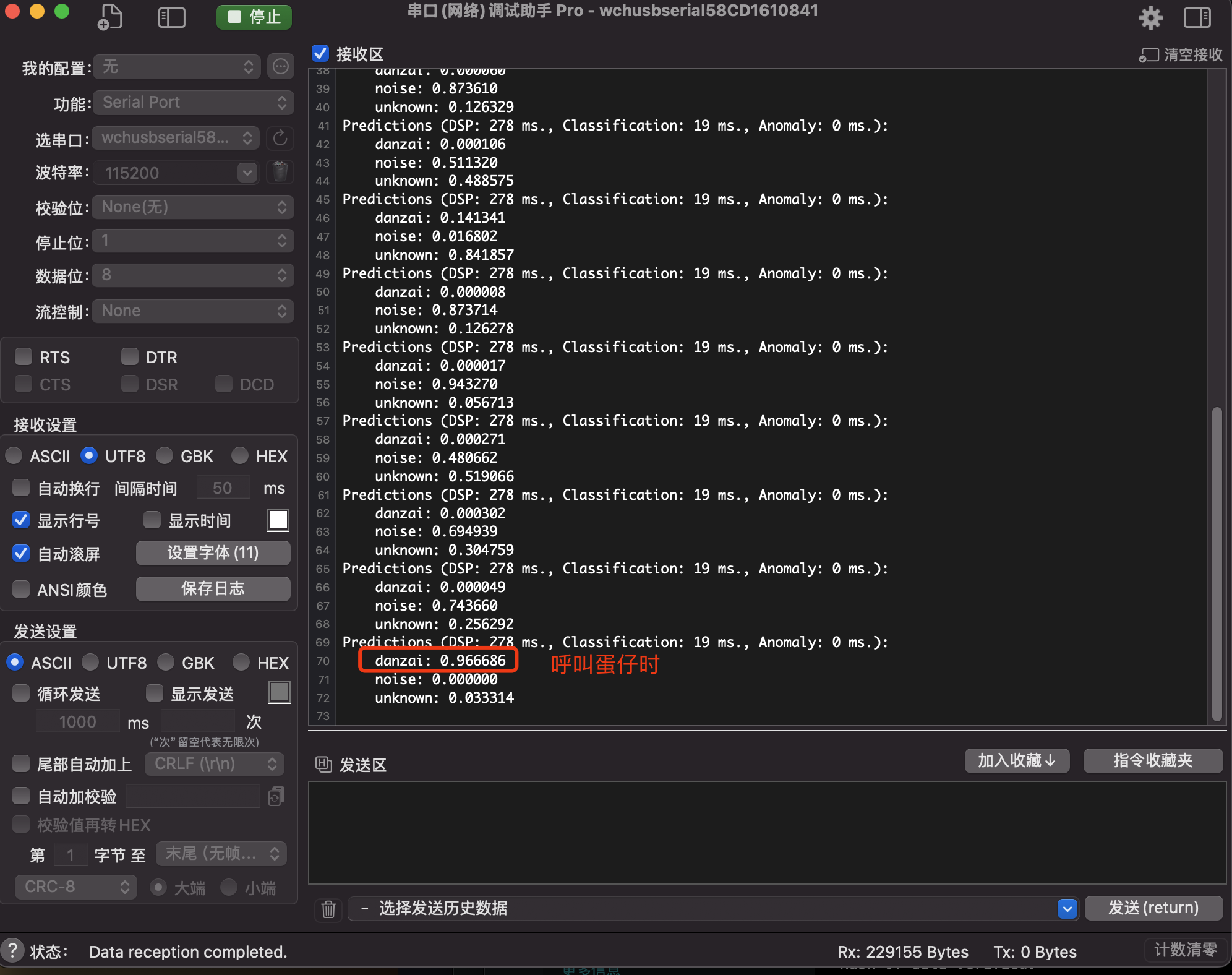
说明:
- 通过串口助手工具的日志,可以看到:没有呼叫蛋仔时,danzai的置信率基本为0;如果呼叫蛋仔,置信率会大于0.9。
- 实现上述的准确率,需要反复进行模型训练和验证,具体内容将在第3部分详细介绍。
- 添加.zip库文件后,Arduino IDE会保存库文件到
~/Documents/Arduino/libraries目录下,如果想删除菜单中的库文件,可以使用terminal切换到上述目录后,通过rm命令删除。
3. 模型调优
分组1:
训练参数:
- 训练次数(Number of training cycles):
300 - 神经网络层数(Number of layers):
2 - 神经网络每层过滤器数量(Number of filters):
1D(8filters)+ 1D(16filters)
训练结果:
- 验证集准确率(validation Accuracy):
76.9% - 验证集损失(validation Loss):
0.46 - F1 score:
danzai:0.80, noise:0.83, unknown:0.67 - 推理时间(Inference time):
4ms - 峰值RAM(Peak RAM):
3.8K - Flash使用量(Flash Usage):
31.9K
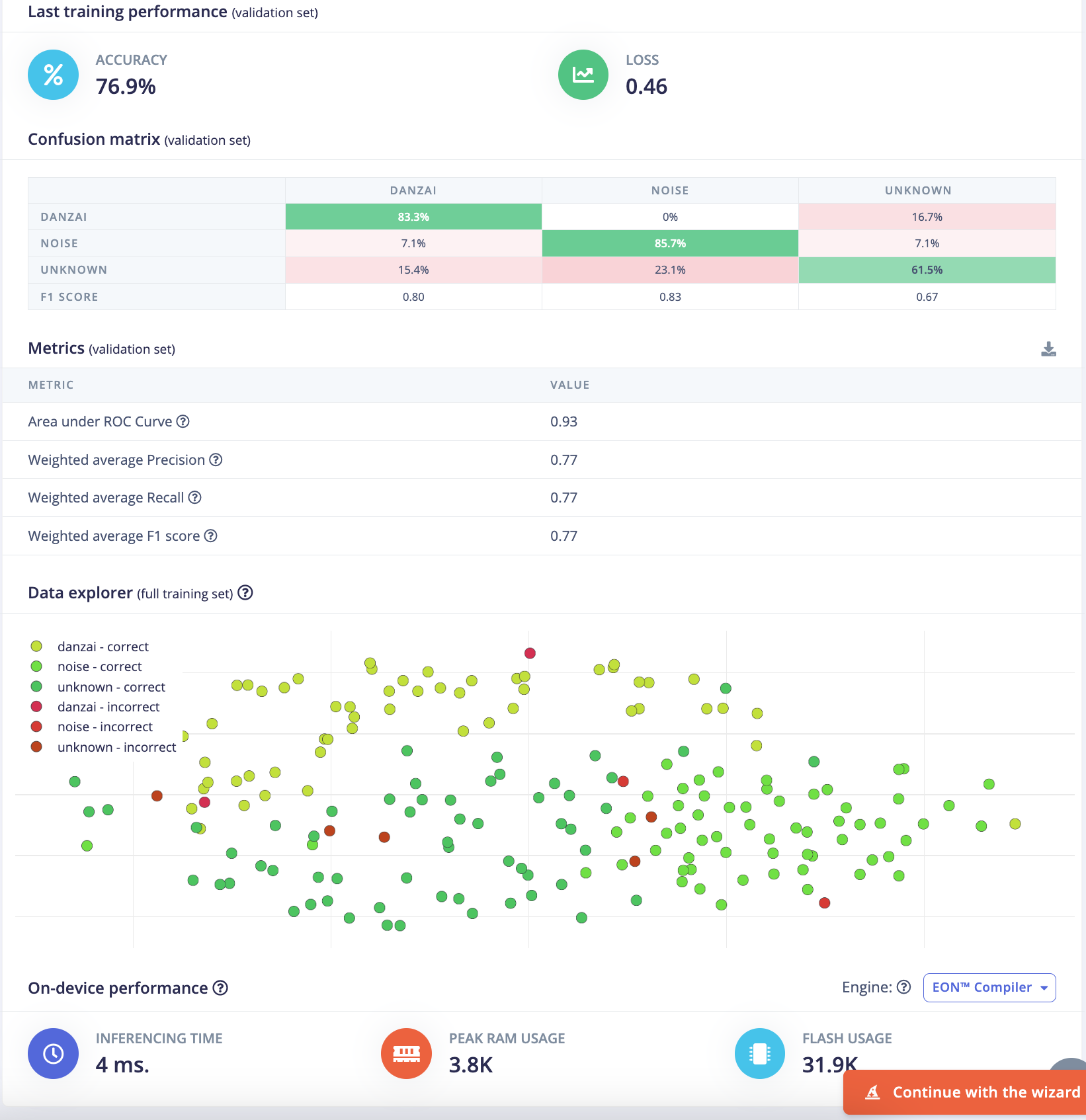
分组2:
训练参数:
- 训练次数(Number of training cycles):
3000 - 神经网络层数(Number of layers):
2 - 神经网络每层过滤器数量(Number of filters):
1D(8filters)+ 1D(16filters)
训练结果:
- 验证集准确率(validation Accuracy):
79.5% - 验证集损失(validation Loss):
0.46 - F1 score:
danzai:0.83, noise:0.87, unknown:0.67 - 推理时间(Inference time):
4ms - 峰值RAM(Peak RAM):
3.8K - Flash使用量(Flash Usage):
31.9K
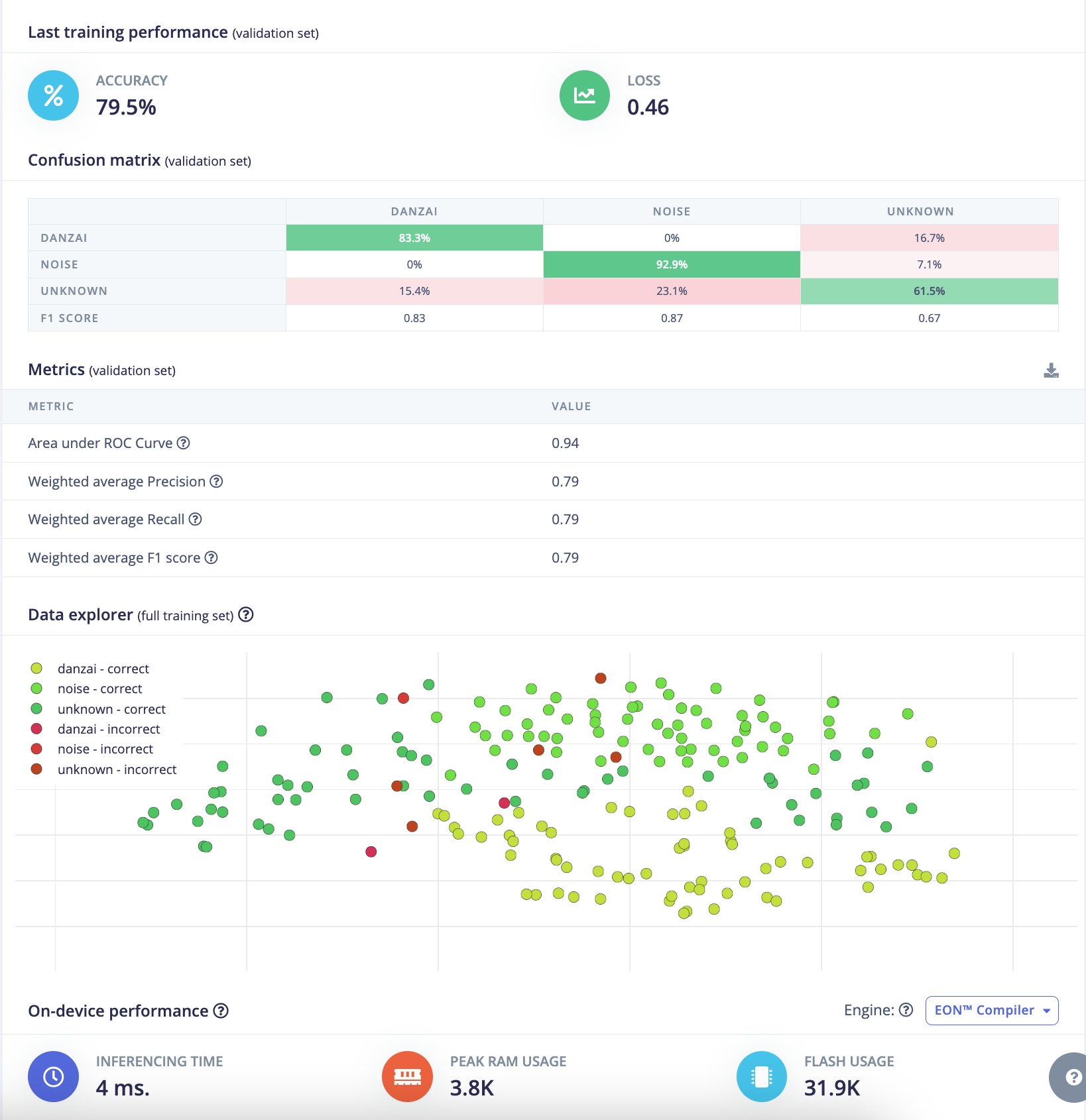
分组3:
训练参数
- 训练次数(Number of training cycles):
3000 - 神经网络层数(Number of layers):
2 - 神经网络每层过滤器数量(Number of filters):
1D(8filters)+ 1D(16filters) 开启数据增强(Data augmentation)
训练结果:
- 验证集准确率(validation Accuracy):
84.6% - 验证集损失(validation Loss):
0.50 - F1 score:
danzai:0.96, noise:0.84, unknown:0.75 - 推理时间(Inference time):
10ms - 峰值RAM(Peak RAM):
3.8K - Flash使用量(Flash Usage):
31.9K
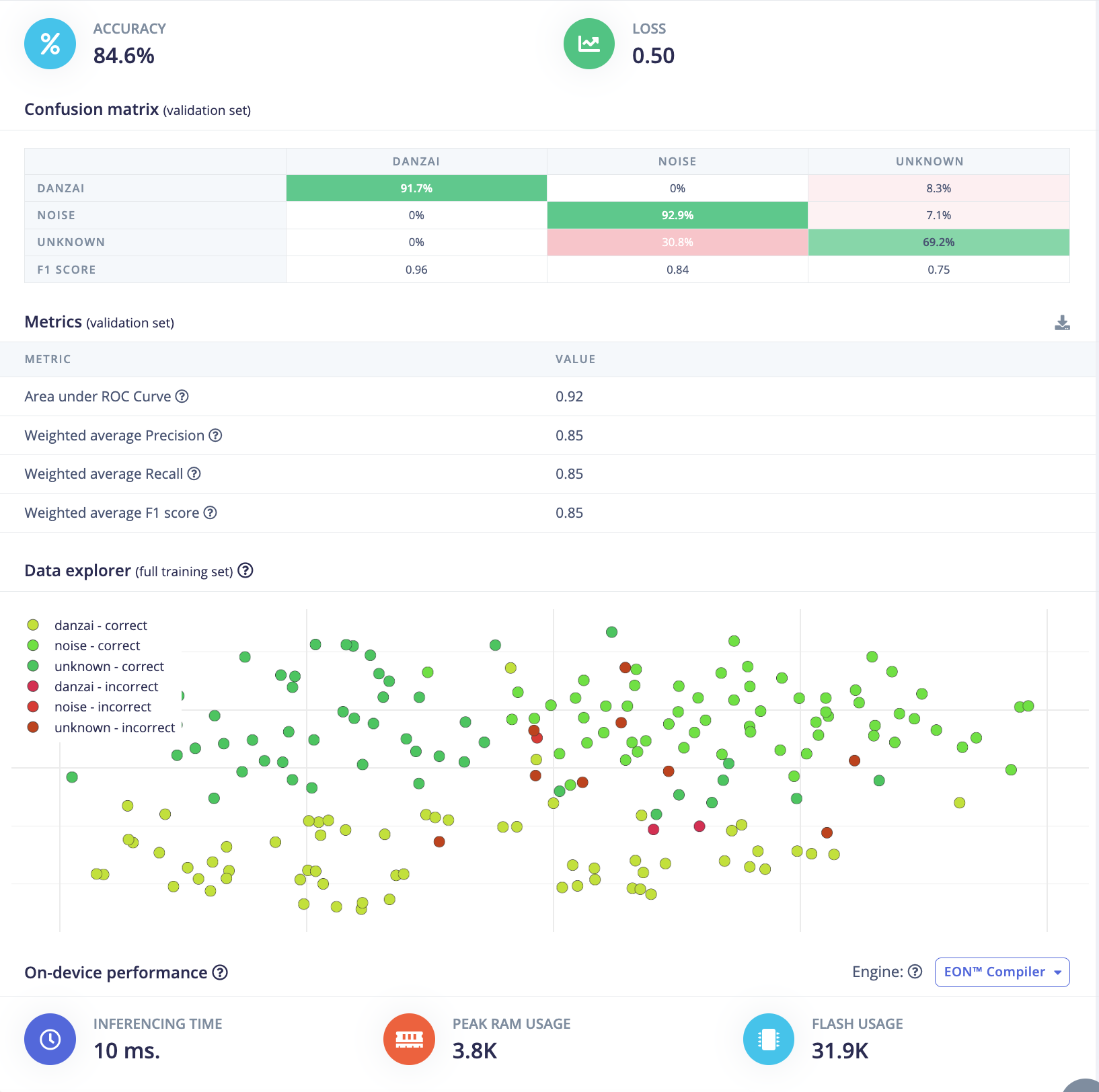
分组4:
训练参数
- 训练次数(Number of training cycles):
3000 - 神经网络层数(Number of layers):
2 - 神经网络每层过滤器数量(Number of filters):
1D(16filters)+ 1D(32filters) 关闭数据增强(Data augmentation)
训练结果:
- 验证集准确率(validation Accuracy):
82.1% - 验证集损失(validation Loss):
0.50 - F1 score:
danzai:0.87, noise:0.87, unknown:0.72 - 推理时间(Inference time):
10ms - 峰值RAM(Peak RAM):
4.4K - Flash使用量(Flash Usage):
34.4K
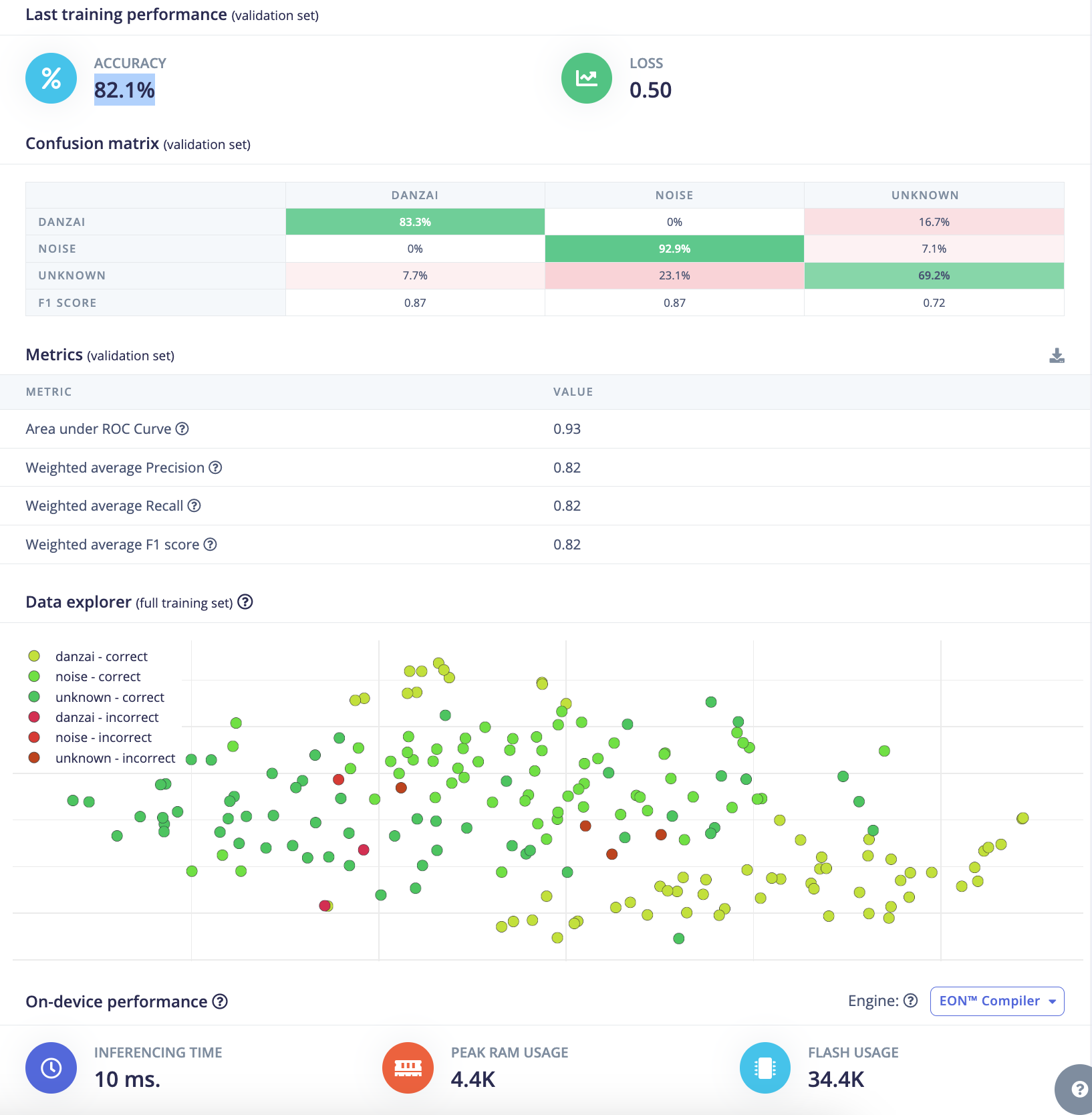
分组5:
训练参数
- 训练次数(Number of training cycles):
3000 - 神经网络层数(Number of layers):
3 - 神经网络每层过滤器数量(Number of filters):
1D(16filters)+ 1D(32filters)+ 1D(64filters) 关闭数据增强(Data augmentation)
训练结果:
- 验证集准确率(validation Accuracy):
94.9% - 验证集损失(validation Loss):
1.10 - F1 score:
danzai:1.00, noise:0.93, unknown:0.92 - 推理时间(Inference time):
16ms - 峰值RAM(Peak RAM):
5.8K - Flash使用量(Flash Usage):
42.2K
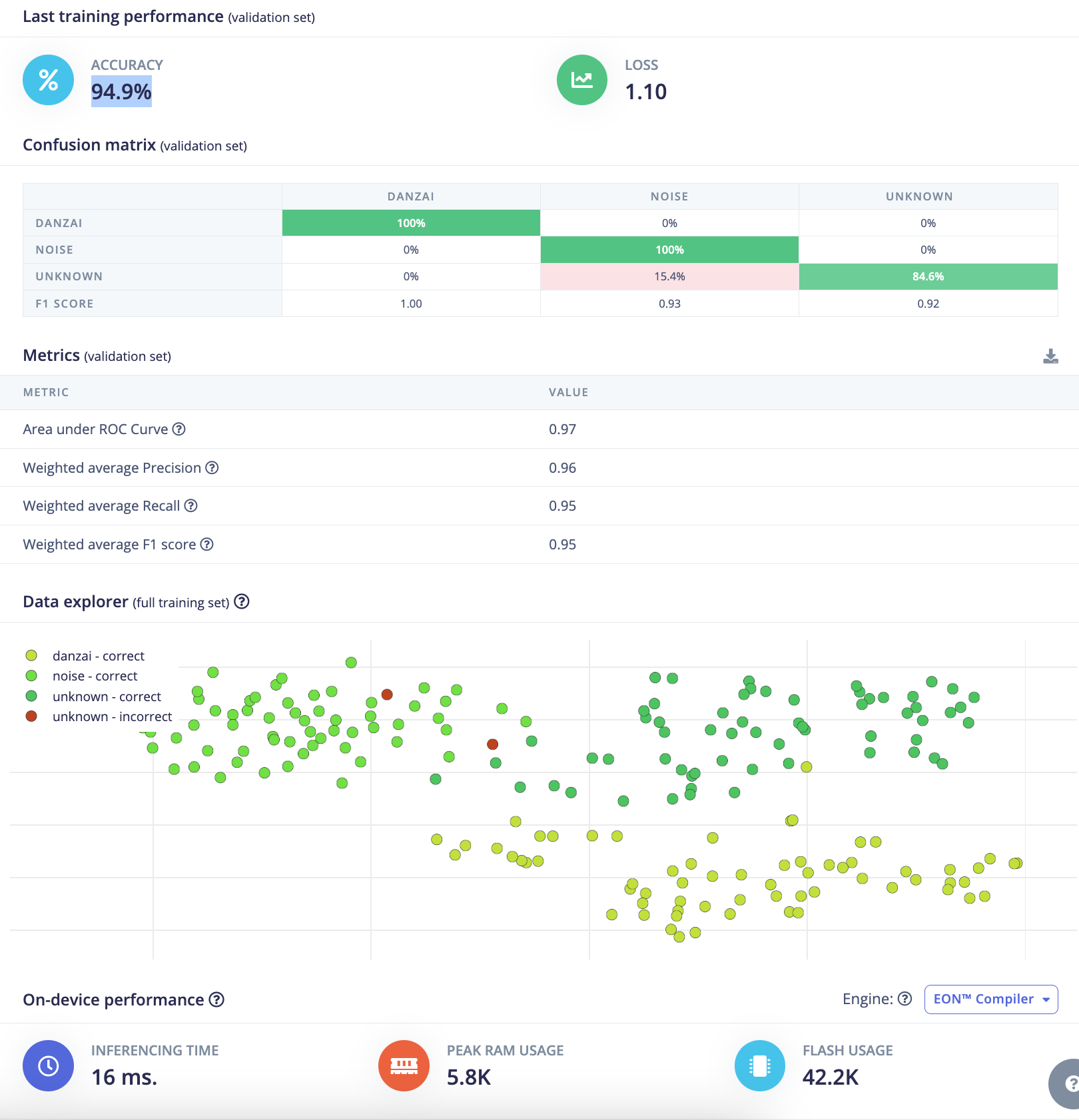
分组6:
训练参数
- 训练次数(Number of training cycles):
3000 - 神经网络层数(Number of layers):
5 - 神经网络每层过滤器数量(Number of filters):
1D(16filters)+ 1D(32filters)+ 1D(64filters)+ 1D(128filters)+ 1D(256filters) - 关闭数据增强(Data augmentation)
训练结果:
- 验证集准确率(validation Accuracy):
94.9% - 验证集损失(validation Loss):
0.30 - F1 score:
danzai:1.00, noise:0.93, unknown:0.92 - 推理时间(Inference time):
31ms - 峰值RAM(Peak RAM):
13.4K - Flash使用量(Flash Usage):
171.0K
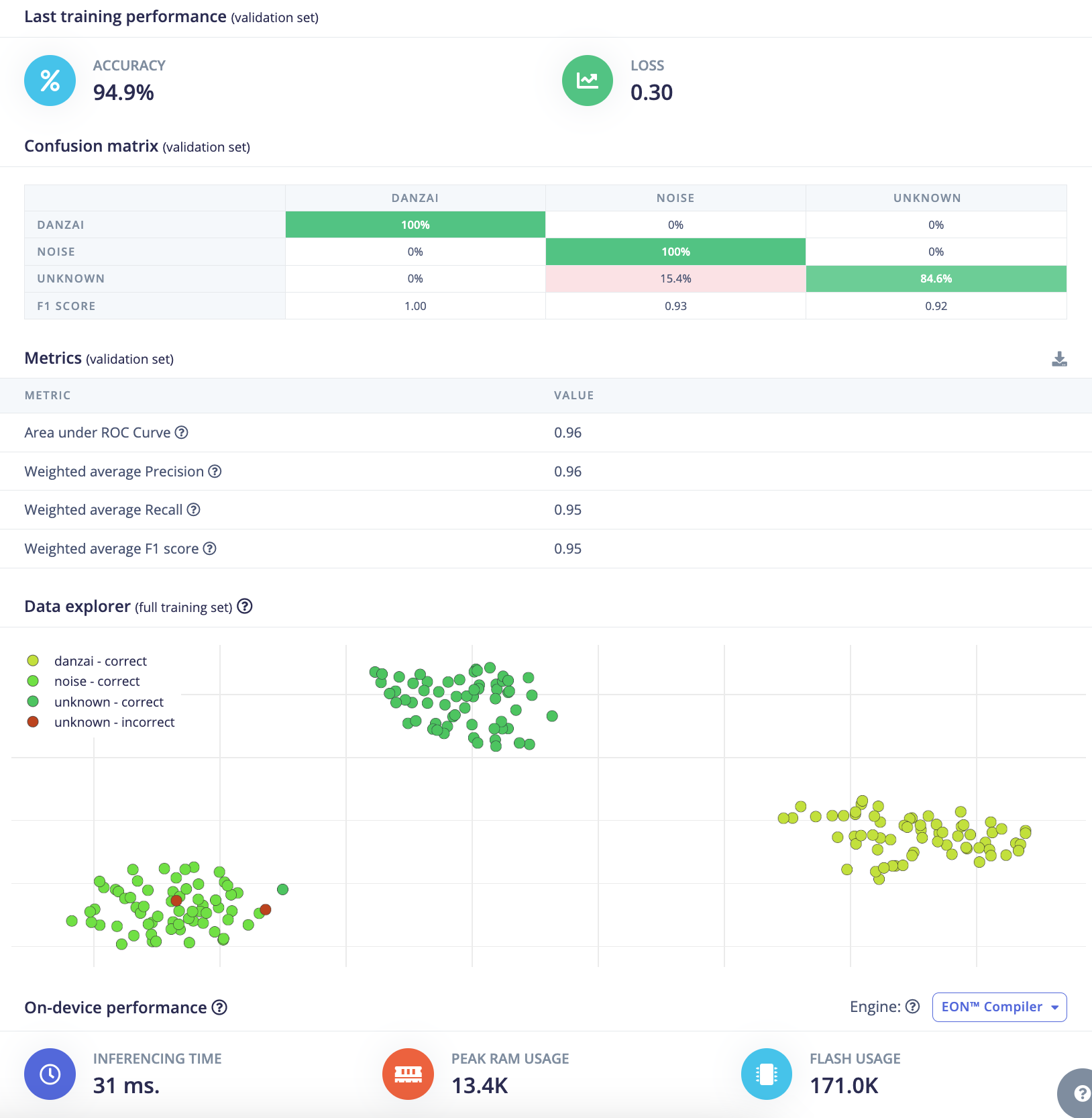
分组7:
训练参数
- 训练次数(Number of training cycles):
3000 - 神经网络层数(Number of layers):
5 - 神经网络每层过滤器数量(Number of filters):
1D(16filters)+ 1D(32filters)+ 1D(64filters)+ 1D(128filters)+ 1D(256filters) 开启数据增强(Data augmentation)
训练结果:
- 验证集准确率(validation Accuracy):
89.7% - 验证集损失(validation Loss):
0.20 - F1 score:
danzai:0.96, noise:0.90, unknown:0.85 - 推理时间(Inference time):
31ms - 峰值RAM(Peak RAM):
13.4K - Flash使用量(Flash Usage):
171.0K
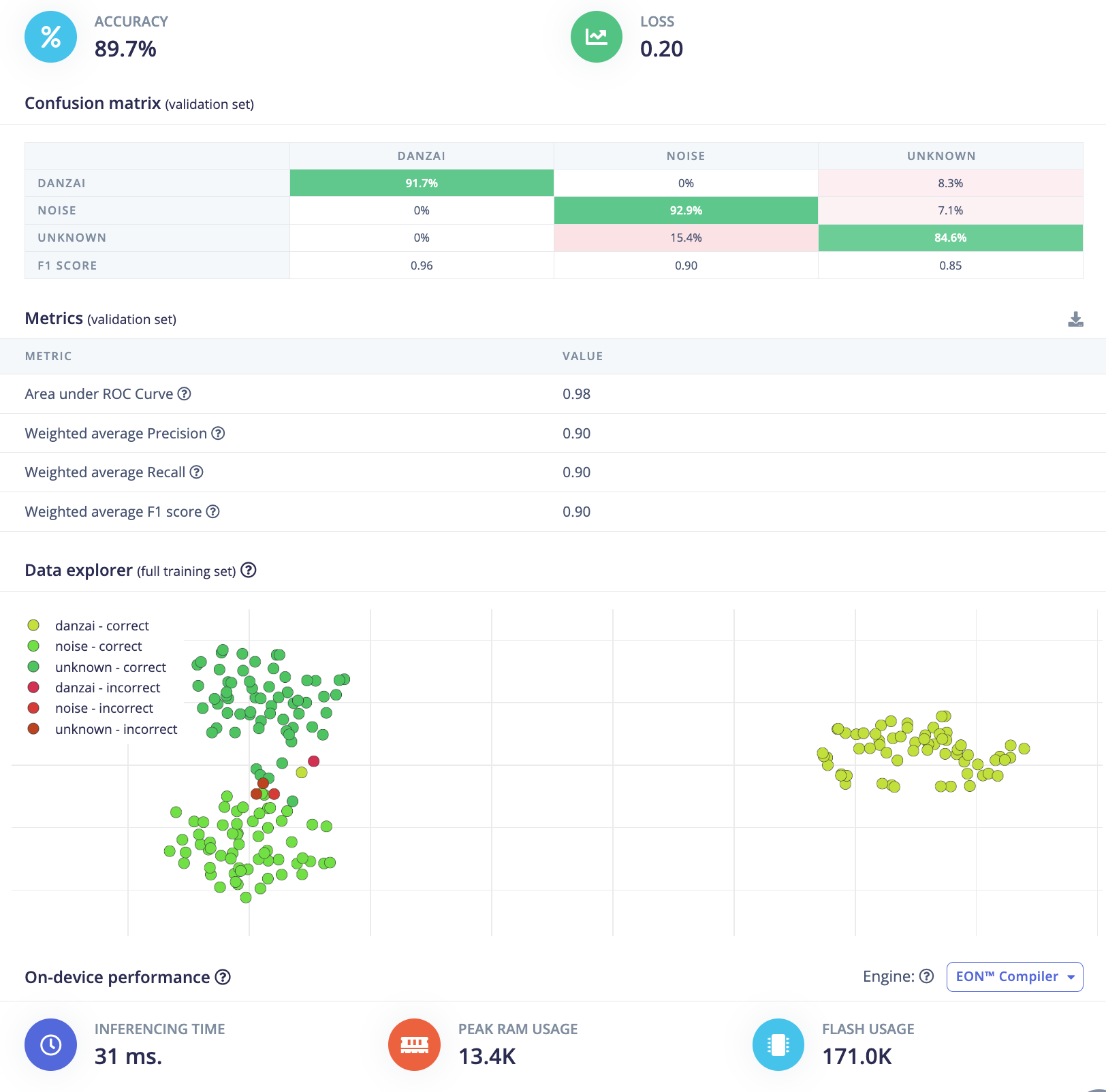
分组8:
训练参数
- 训练次数(Number of training cycles):
3000 - 神经网络层数(Number of layers):
3 - 神经网络每层过滤器数量(Number of filters):
2D(16filters)+ 2D(32filters)+ 1D(64filters) 关闭数据增强(Data augmentation)
训练结果:
- 验证集准确率(validation Accuracy):
84.6% - 验证集损失(validation Loss):
0.35 - F1 score:
danzai:0.92, noise:0.86, unknown:0.77 - 推理时间(Inference time):
86ms - 峰值RAM(Peak RAM):
17.6K - Flash使用量(Flash Usage):
57.4K
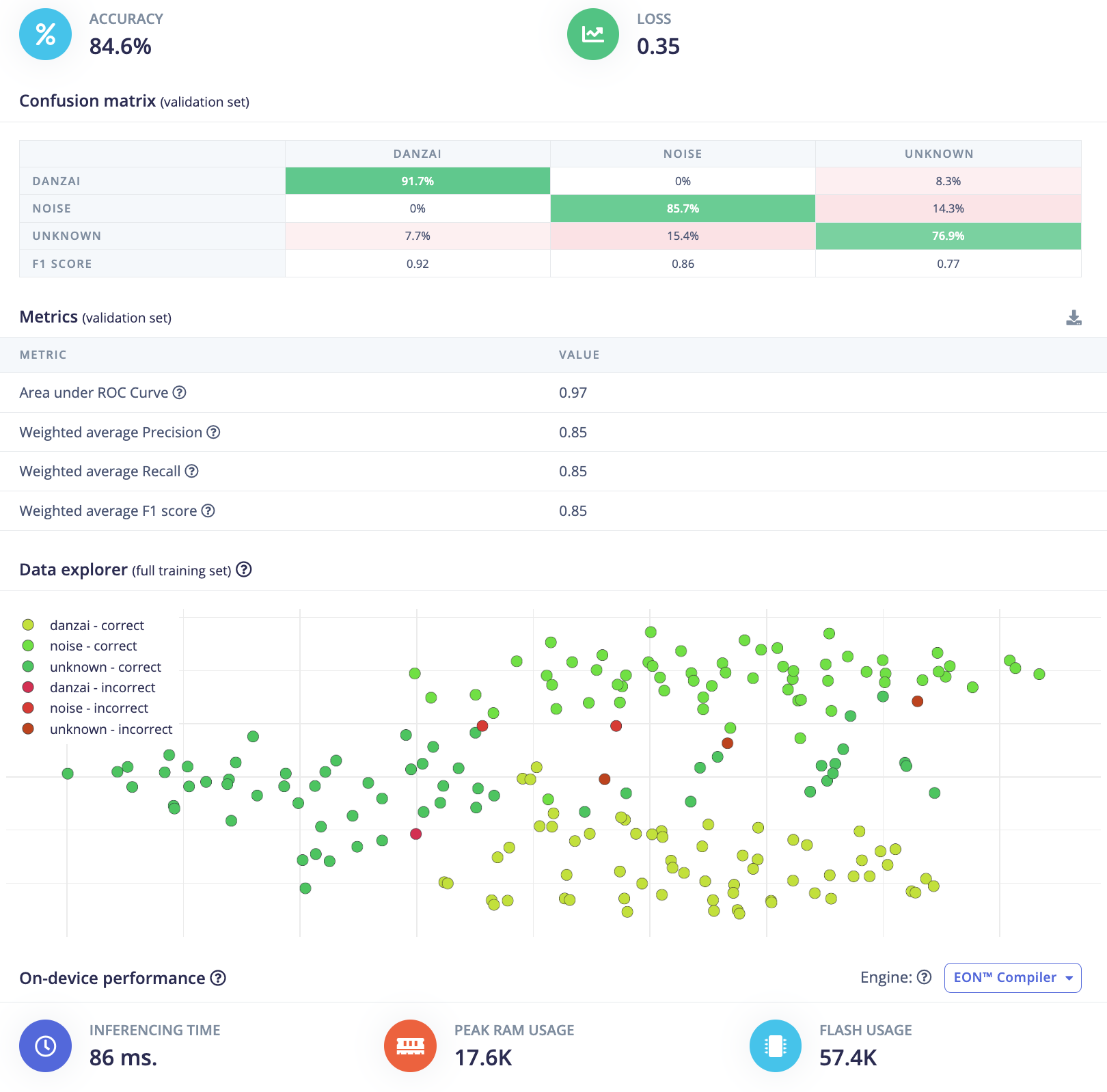
总结
通过8组不同参数的模型训练实验,我们可以得到以下对比数据:
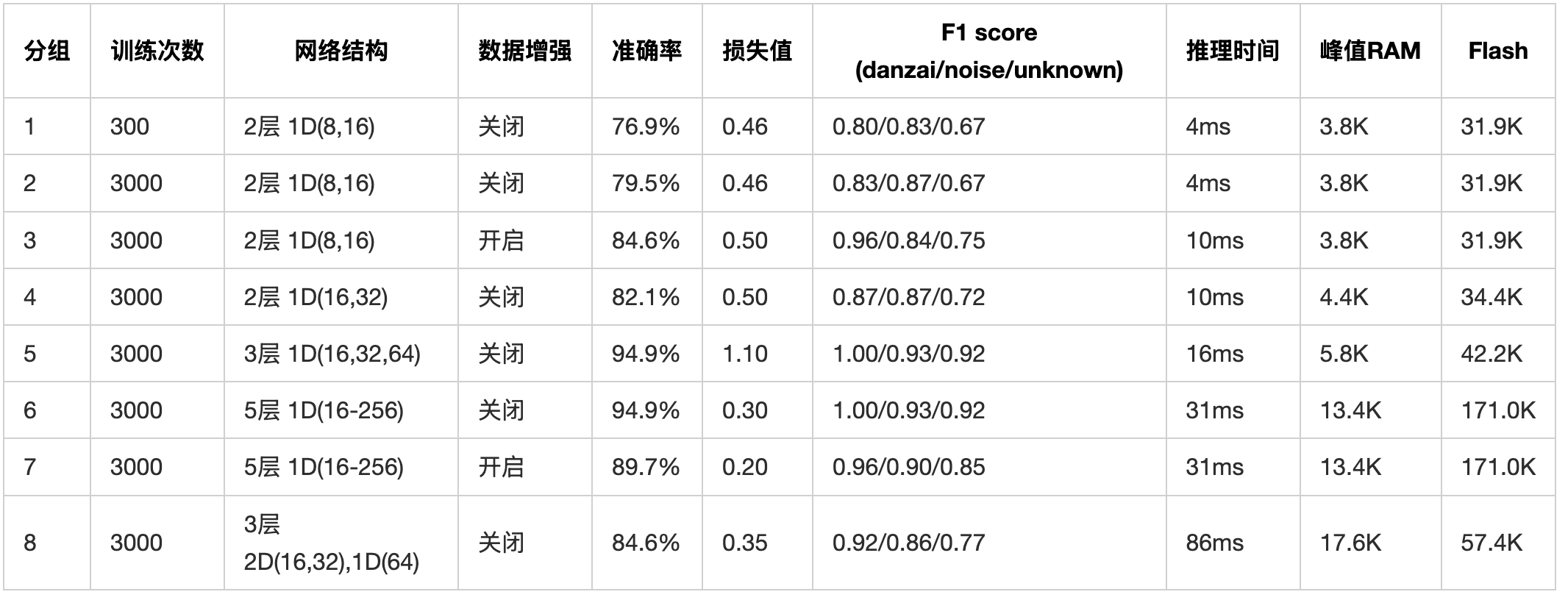
从表格数据可以看出:
- 增加训练次数(分组1 vs 分组2)可以提升准确率
- 数据增强(分组2 vs 分组3)能显著提升模型性能
- 增加网络深度和宽度(分组5)可以达到最佳准确率,同时保持较低的资源消耗
- 过度增加网络复杂度(分组6、7、8)会导致资源消耗显著增加,但准确率提升有限;同时随着网络深度和复杂度的增加,推理速度也会增加。
综合ESP开发板的推理速度要快,结合准确率和资源消耗,分组5的模型配置(3层1D卷积)是最佳选择。
该系列其他文章
欢迎关注公众号以获得最新的文章和新闻



