文章来源于互联网:微调时无需泄露数据或权重,这篇AAAI 2025论文提出的ScaleOT竟能保护隐私
蚂蚁数科、浙江大学、利物浦大学和华东师范大学团队:构筑更好的大模型隐私保护。
要让大模型适应各不一样的下游任务,微调必不可少。常规的中心化微调过程需要模型和数据存在于同一位置 —— 要么需要数据所有者上传数据(这会威胁到数据所有者的数据隐私),要么模型所有者需要共享模型权重(这又可能泄露自己花费大量资源训练的模型)。此外,在第二种情况下,模型的参数可能暴露,这可能会增加其微调模型受到攻击的可能性。这些问题都可能阻碍 LLM 的长期发展。
为了有效地保护模型所有权和数据隐私,浙江大学、蚂蚁数科、利物浦大学和华东师范大学的朱建科与王维团队提出了一种全新的跨域微调(offsite-tuning)框架:ScaleOT。该框架可为模型隐私提供多种不同规模的有损压缩的仿真器,还能促进无损微调(相比于完整的微调)。该研究论文已被人工智能顶会 AAAI 2025 录用。第一作者为姚凯(蚂蚁摩斯高级算法工程师,浙大博后),通讯作者为朱建科教授与王维老师。

-
论文标题:ScaleOT: Privacy-utility-scalable Offsite-tuning with Dynamic LayerReplace and Selective Rank Compression -
论文地址:https://arxiv.org/pdf/2412.09812
框架设计和创建过程
-
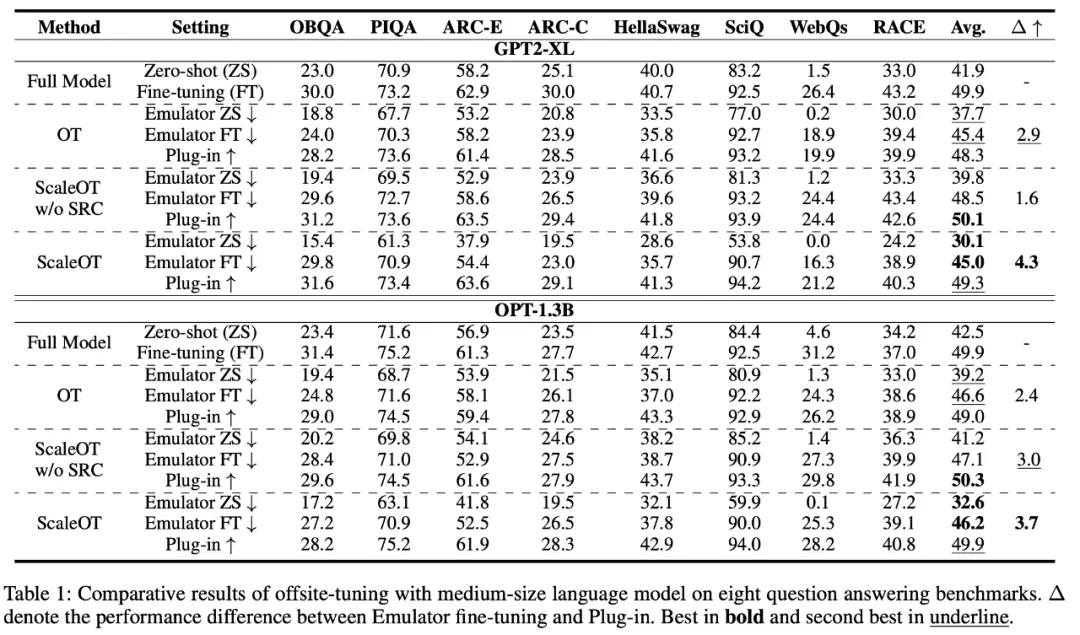
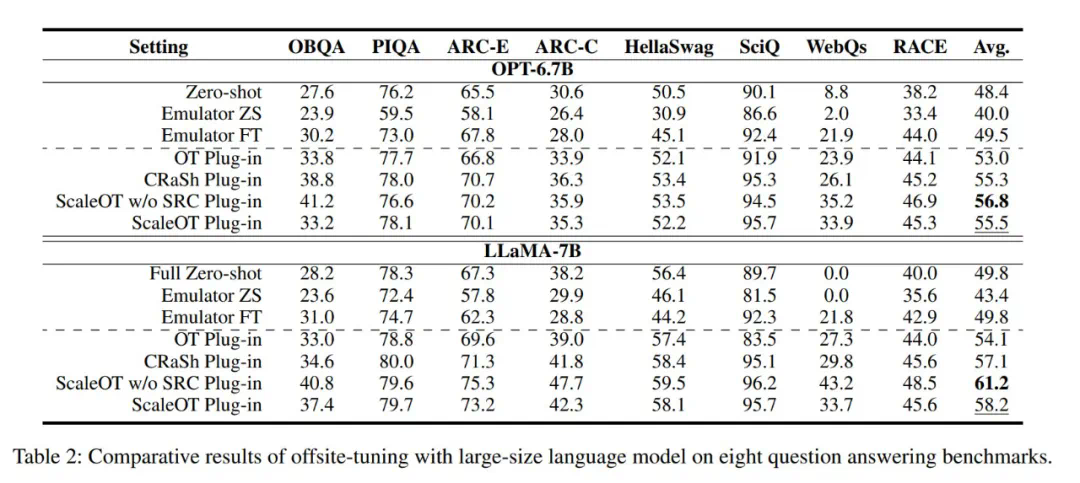
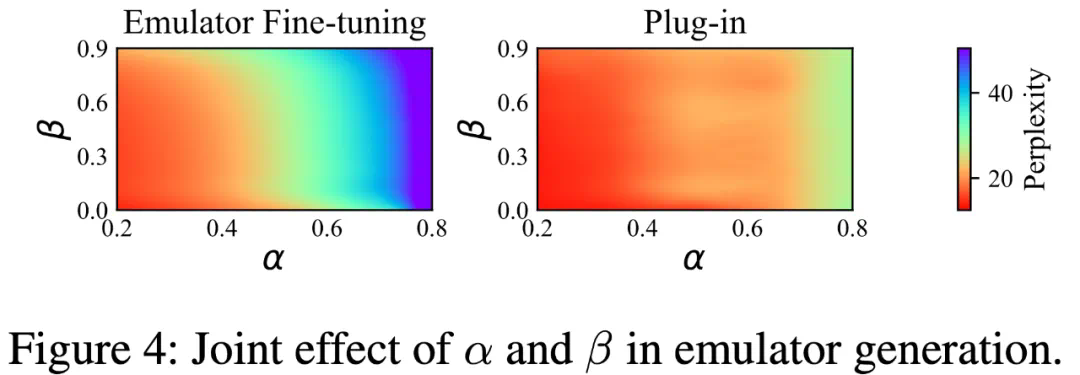
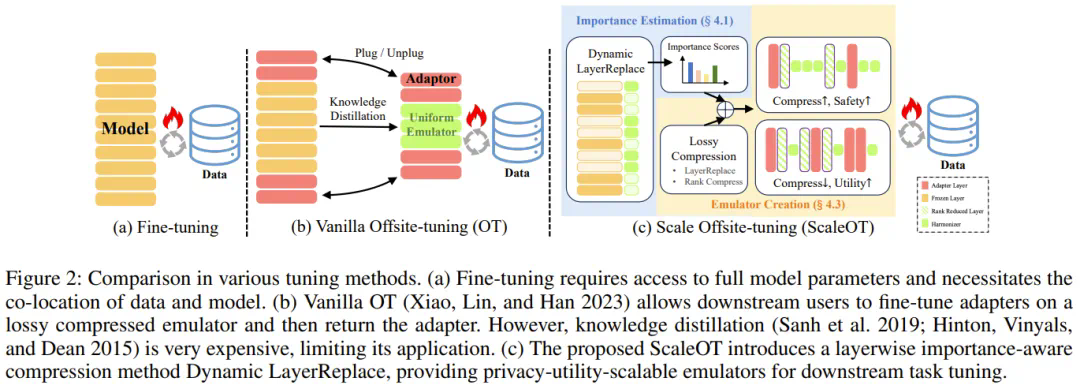
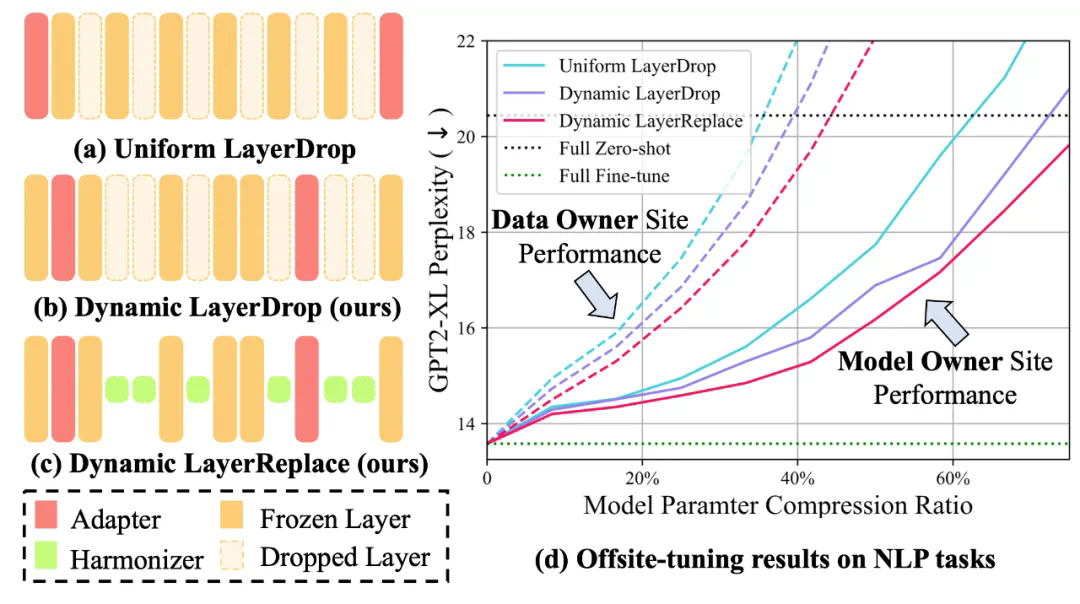
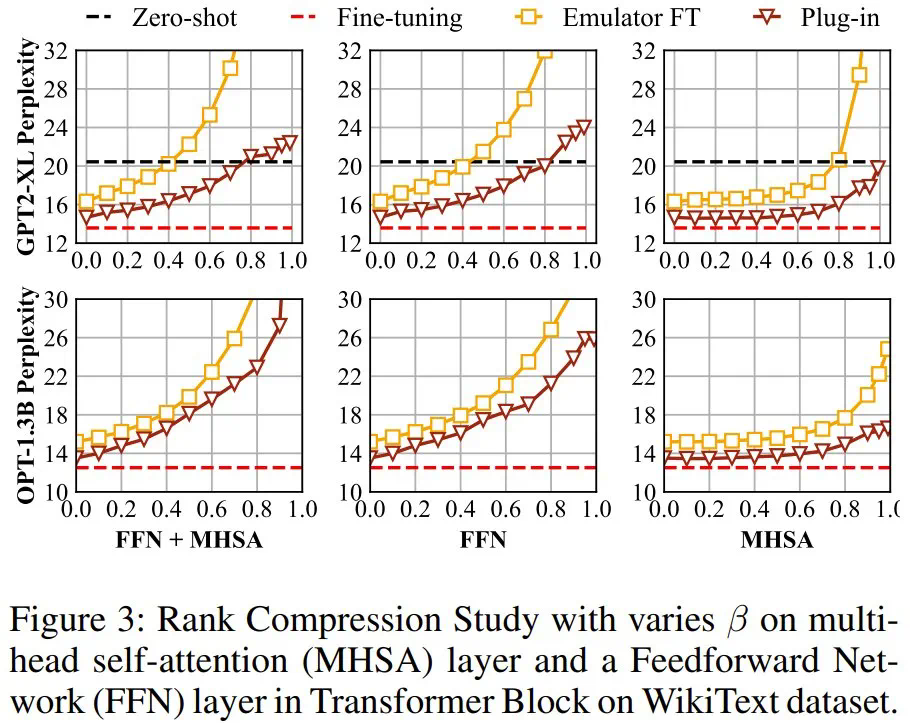
提出了一种灵活的方法,可为跨域微调得到多种大小的压缩版模型:提出了一种重要性感知型有损压缩算法 Dynamic LayerReplace,该算法面向使用 LLM 的跨域微调,可通过强化学习和协调器来扩展仿真器。这些组件可以实现灵活的多种规模的压缩模型生成。 -
仅需一点点微调性能下降,就能通过进一步的压缩获得更好的隐私:新提出的选择性秩压缩策略仅需少量性能损失就能进一步提升模型隐私。 -
全面的实验表明,新提出的 ScaleOT 优于当前最佳方法。
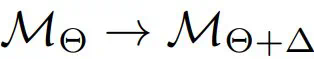 ,其中
,其中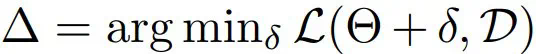 。
。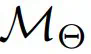 更小、更弱的替代模型
更小、更弱的替代模型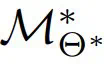 (称为仿真器),来促进隐私迁移学习。这种方法可确保与下游用户共享
(称为仿真器),来促进隐私迁移学习。这种方法可确保与下游用户共享 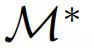 不会威胁到 LLM 的所有权。然后,数据所有者使用他们的数据集对替代模型进行微调,得到
不会威胁到 LLM 的所有权。然后,数据所有者使用他们的数据集对替代模型进行微调,得到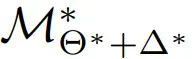 。该团队希望,通过将训练好的权重∆^∗重新整合到原始模型中(表示为
。该团队希望,通过将训练好的权重∆^∗重新整合到原始模型中(表示为 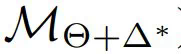 ),几乎可以复制直接在数据集上优化 M 时观察到的性能(表示为
),几乎可以复制直接在数据集上优化 M 时观察到的性能(表示为 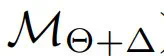 ),从而消除了直接访问 M 的需求。
),从而消除了直接访问 M 的需求。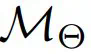 表示零样本(ZS)性能;
表示零样本(ZS)性能;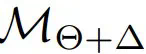 表示微调(FT)性能;
表示微调(FT)性能;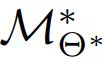 和
和 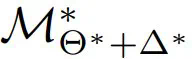 分别表示仿真器 ZS 和 FT 的性能;
分别表示仿真器 ZS 和 FT 的性能;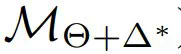 表示插件性能。
表示插件性能。更具实用性
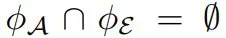 。
。 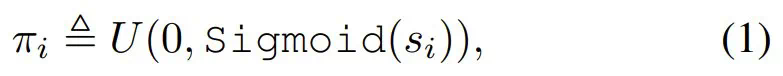
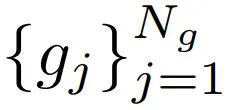 ,剩下层的索引集的结构为:
,剩下层的索引集的结构为: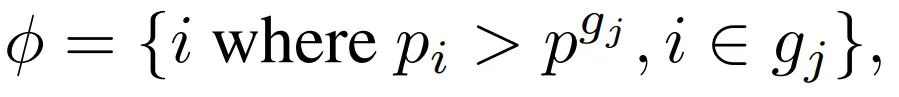 其中 p^gj 是第 j 组中的中位数概率,N_g 根据经验默认设置为 4。根据 φ,采样得到的 LayerReplace 候选网络可以写成:
其中 p^gj 是第 j 组中的中位数概率,N_g 根据经验默认设置为 4。根据 φ,采样得到的 LayerReplace 候选网络可以写成: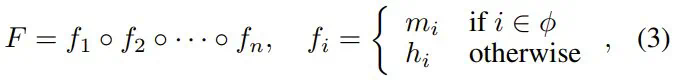
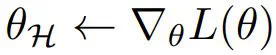 。这里,该团队使用了负对数似然损失,这是一个被广泛使用的下一 token 预测标准。随后,通过反向传播得出更新协调器所需的梯度。
。这里,该团队使用了负对数似然损失,这是一个被广泛使用的下一 token 预测标准。随后,通过反向传播得出更新协调器所需的梯度。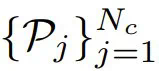 采样 N_c 个 LayerReplace 候选网络。然后,使用留存的验证集 D^V 生成索引集
采样 N_c 个 LayerReplace 候选网络。然后,使用留存的验证集 D^V 生成索引集 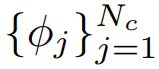 和它们相应的损失
和它们相应的损失 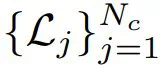 。
。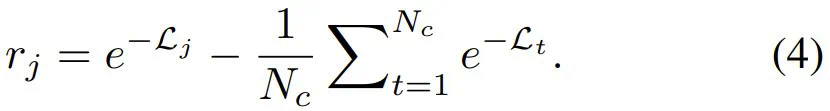
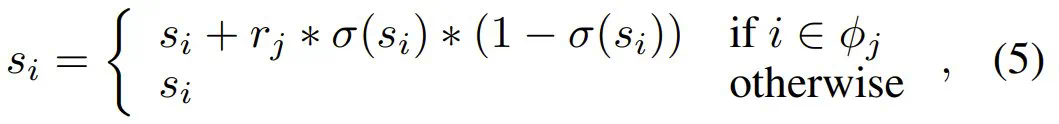
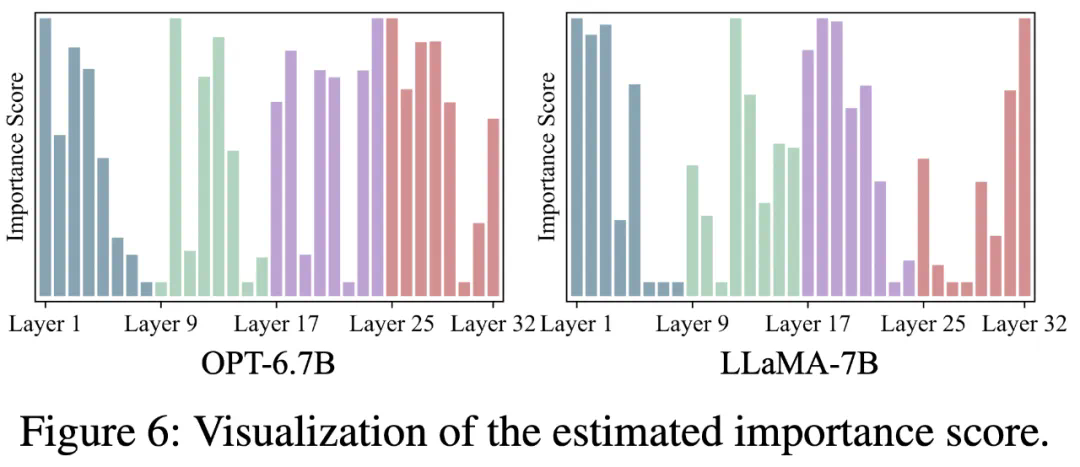
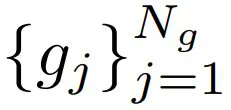 到 N_g,把模型中的所有层按以下指标规定的重要性分成两组:
到 N_g,把模型中的所有层按以下指标规定的重要性分成两组: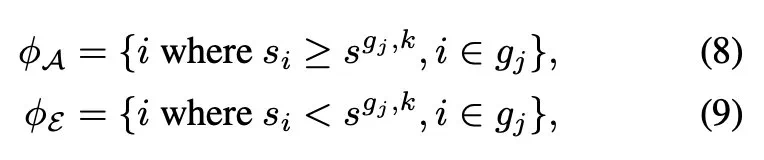
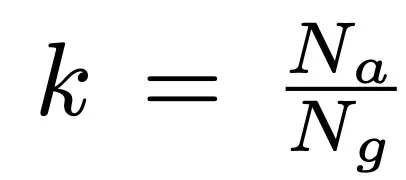 ,其中
,其中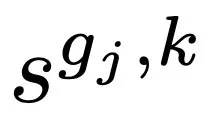 代表每组中第 k 大的重要性分数。
代表每组中第 k 大的重要性分数。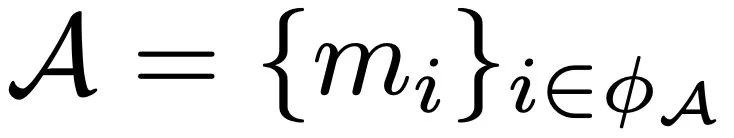 ,
,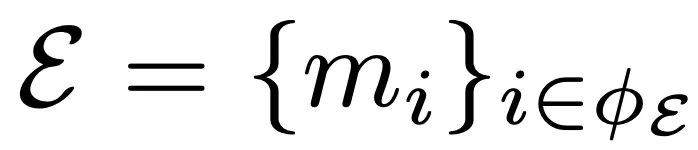 。既而,协调器的指标集定义如下:
。既而,协调器的指标集定义如下: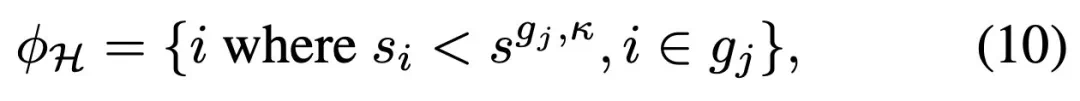
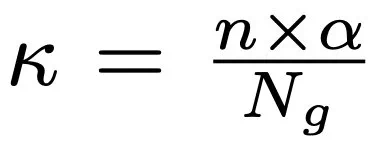 ,
, 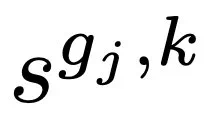 是第 j 组中第 κ 个最大的重要性分数,φH ∈ φE。仿真器 E∗可以表示为:
是第 j 组中第 κ 个最大的重要性分数,φH ∈ φE。仿真器 E∗可以表示为: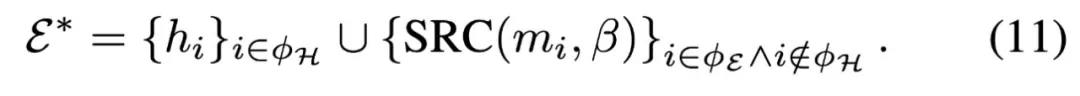
更好的性能,更优的模型隐私