文章来源于互联网:Anthropic总结智能体年度经验:最成功的≠最复杂的
高端的食材,往往需要最朴素的烹饪方式。


-
原文链接:https://www.anthropic.com/research/building-effective-agents
-
工作流是通过预定代码路径编排 LLM 和工具的系统 -
智能体则是由 LLM 动态指导自身流程和工具使用的系统,能自主控制任务的完成方式
-
LangChain 的 LangGraph -
亚马逊 Bedrock 的 AI Agent 框架 -
拖放式的大模型工作流构建工具 Rivet -
用于构建和测试复杂工作流的 GUI 工具 Vellum
-
手册链接:https://github.com/anthropics/anthropic-cookbook/tree/main/patterns/agents
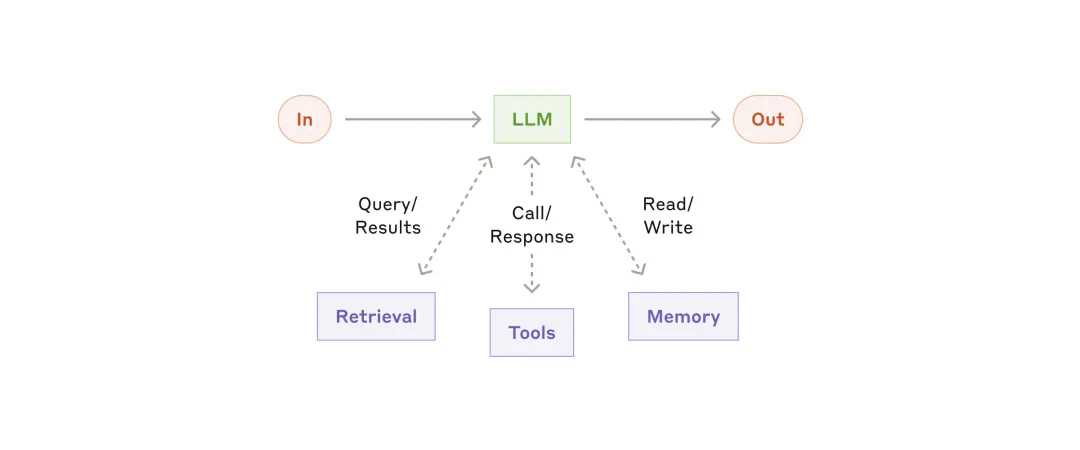
-
根据具体的应用场景来定制功能 -
确保为模型提供简单且文档完备的接口
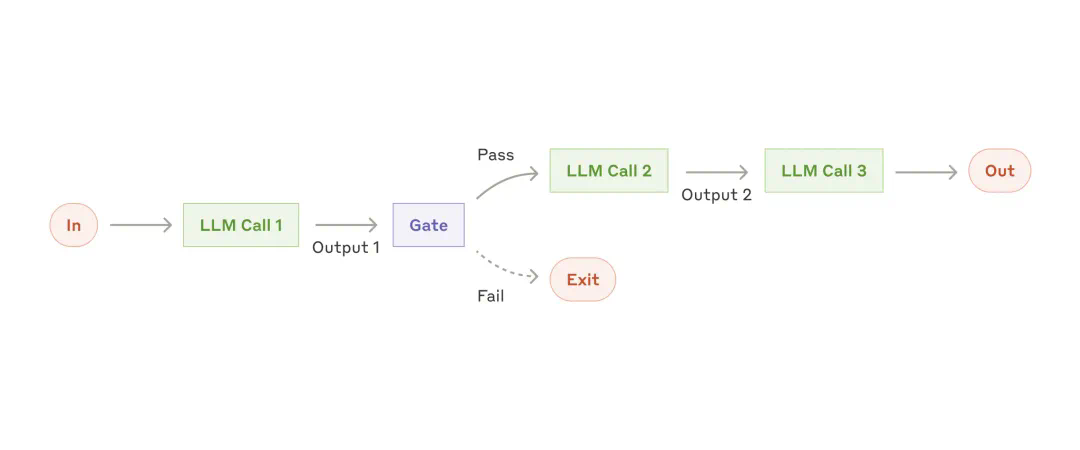 提示链工作流。
提示链工作流。-
先生成营销文案,再将其翻译成其他语言 -
先写文档大纲并进行合规性检查,再基于大纲撰写完整文档
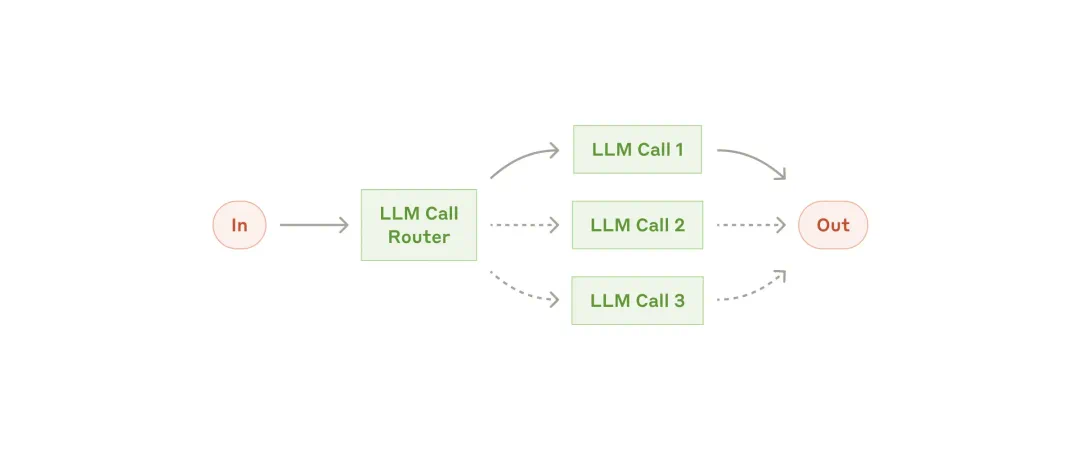
-
在客服系统中,可以将一般咨询、退款申请、技术支持等不同类型的问题,分别引导到相应的处理流程。 -
将简单 / 常见问题分配到 Claude 3.5 Haiku 等较小模型,将困难 / 罕见问题分配到 Claude 3.5 Sonnet 等更强大的模型,以优化成本和速度。
-
任务分段:将任务拆分为可并行运行的独立子任务,每个子任务可以同时进行处理,最后再整合结果。 -
投票机制:对同一任务进行多次运行,获得多个不同版本的输出,从而选择最优结果或综合多个答案。
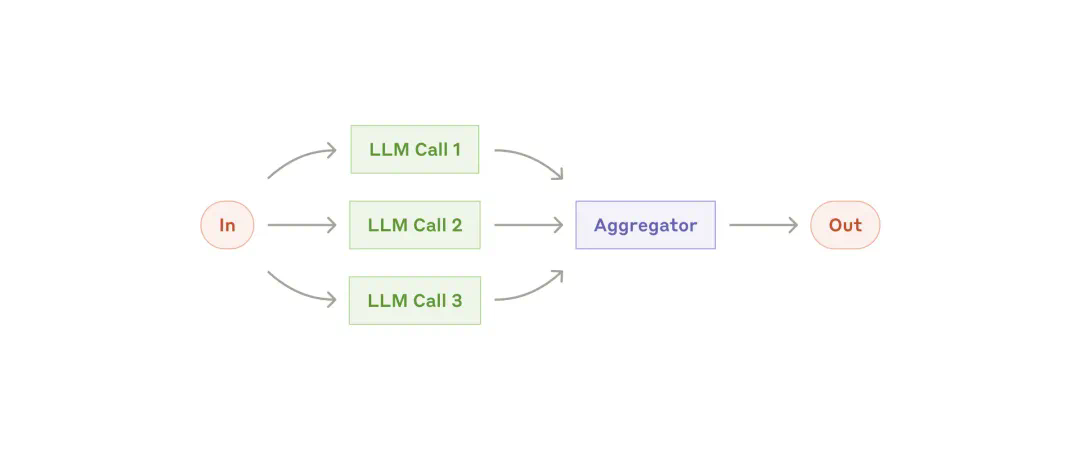
-
安全防护:一个模型负责处理用户请求,另一个专门负责内容审核,这比单个模型同时处理两项任务效果更好。 -
性能评估:让不同的模型分别评估系统的各个性能指标,实现全面的自动化评估。
-
代码安全检查:同时运行多个检测模型,共同发现和标记潜在的代码漏洞。 -
内容审核:通过多个模型从不同角度评估内容安全性,通过调整投票阈值来平衡误判率。

-
需要对多个文件进行复杂修改的编程应用。 -
需要从多个来源收集和分析相关信息的搜索任务。
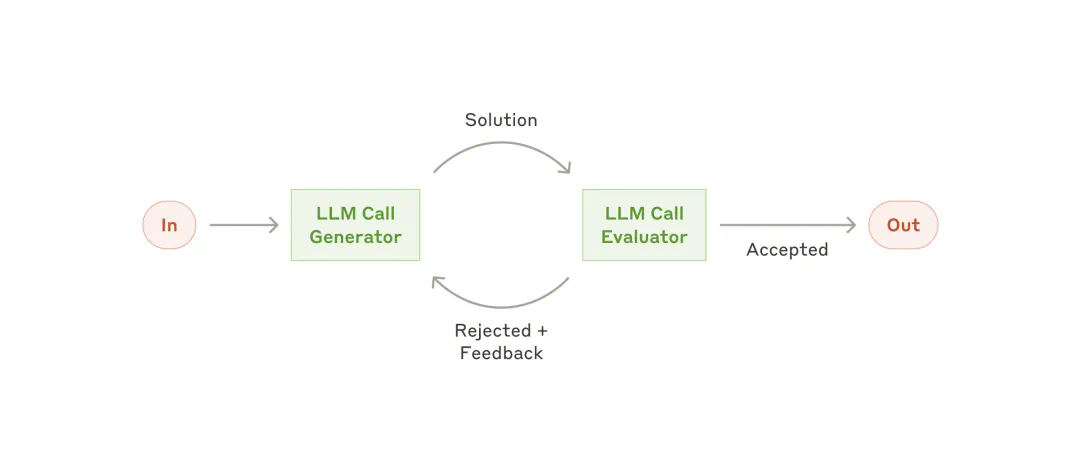
-
文学翻译:翻译模型可能在第一次翻译时遗漏一些细微的语言差异,而评估模型能够发现这些问题并提供有价值的修改建议。 -
复杂搜索:某些信息收集任务需要多轮搜索和分析才能获得全面的结果,评估模型可以判断是否需要继续深入搜索。
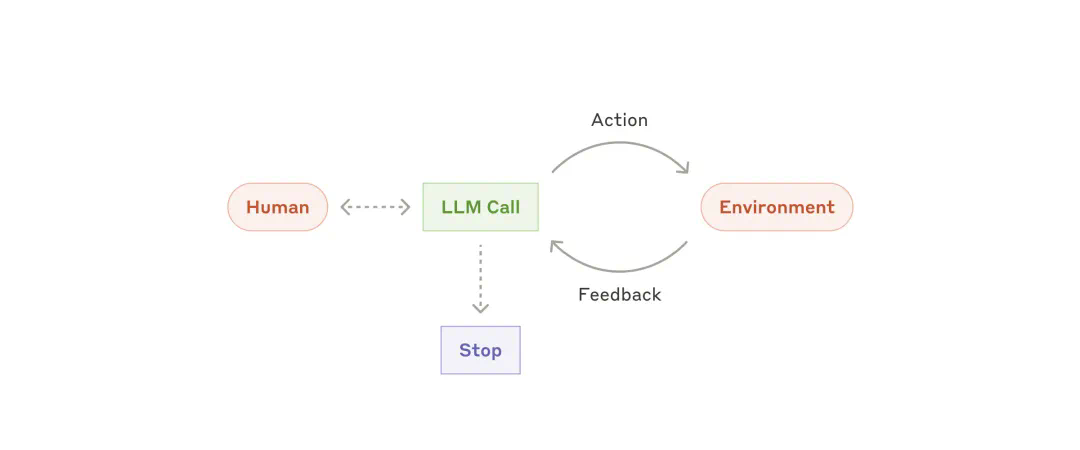
-
一个代码智能体,用于解决涉及根据任务描述编辑多个文件的 SWE-bench 任务 -
Anthropic 的「Computer use」功能,其中 Claude 使用计算机完成任务。
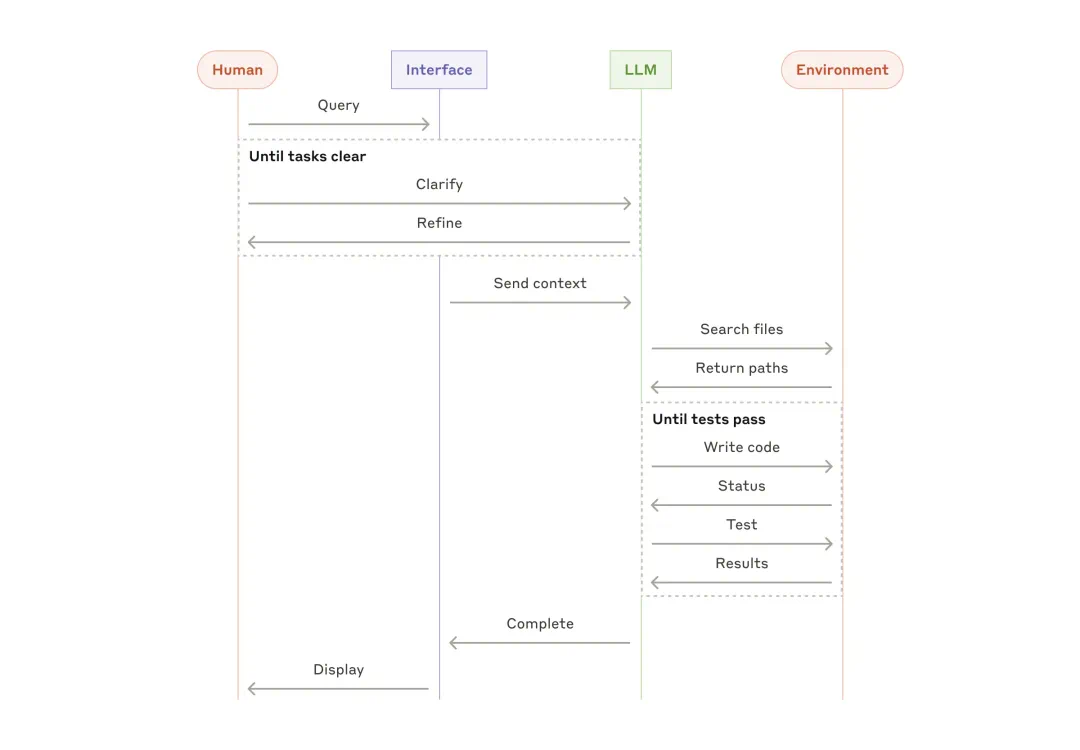
-
在智能体设计中保持简单; -
要优先确保智能体的透明度,方法是清楚地展示它计划中的每一步; -
通过全面的工具文档和测试精心打造你的智能体 – 计算机界面(ACI)。
文章来源于互联网:Anthropic总结智能体年度经验:最成功的≠最复杂的
