文章来源于互联网:数据不够致Scaling Law撞墙?CMU和DeepMind新方法可让VLM自己生成记忆
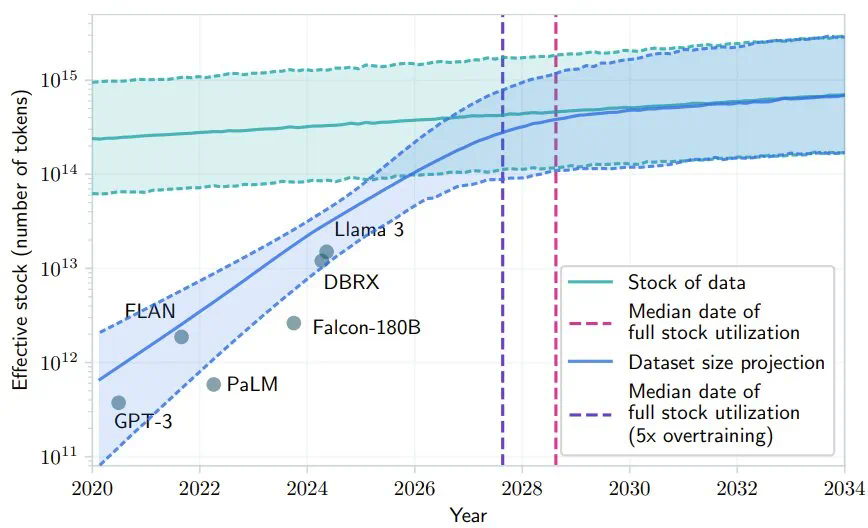
最近 AI 社区很多人都在讨论 Scaling Law 是否撞墙的问题。其中,一个支持 Scaling Law 撞墙论的理由是 AI 几乎已经快要耗尽已有的高质量数据,比如有一项研究就预计,如果 LLM 保持现在的发展势头,到 2028 年左右,已有的数据储量将被全部利用完。

-
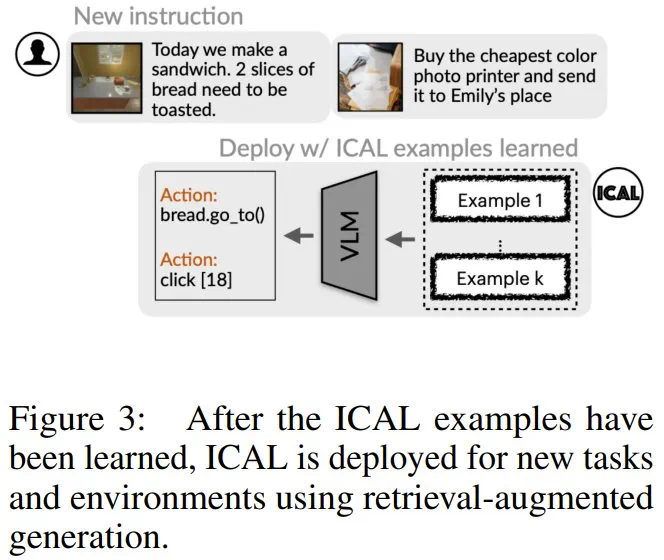
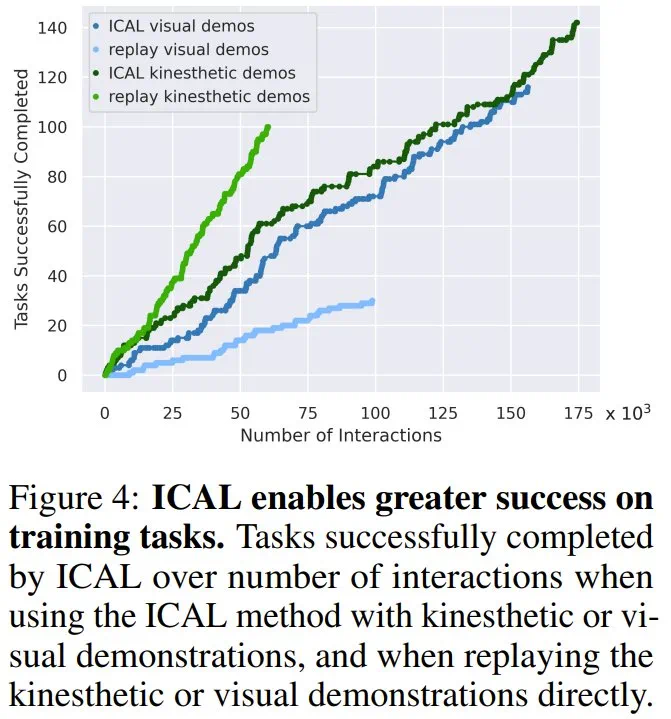
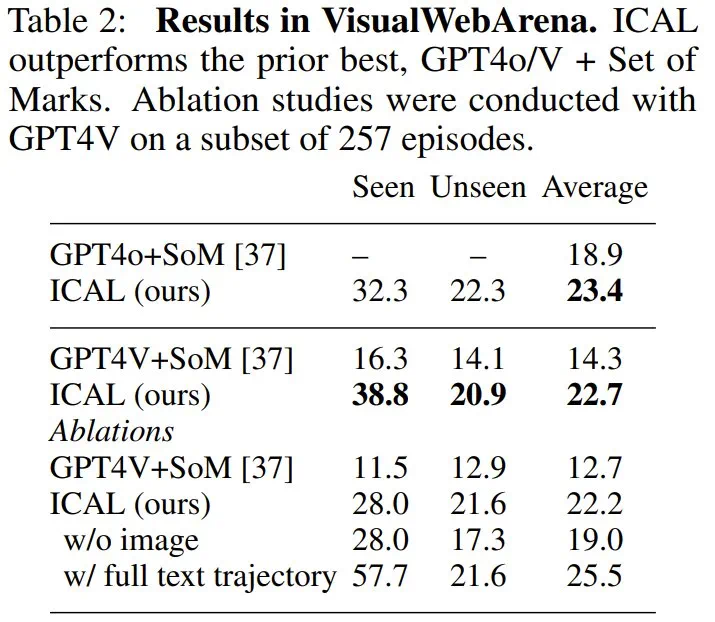
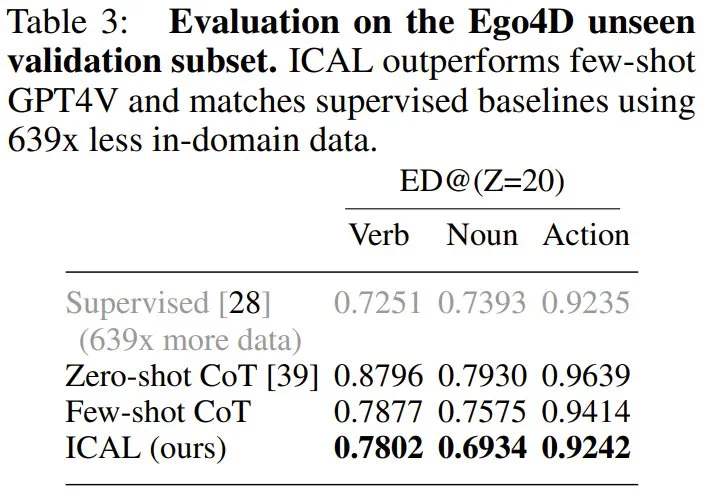
论文标题:VLM Agents Generate Their Own Memories: Distilling Experience into Embodied Programs of Thought -
论文地址:https://openreview.net/pdf?id=5G7MRfPngt -
项目地址:https://ical-learning.github.io/ -
代码地址:https://github.com/Gabesarch/ICAL

-
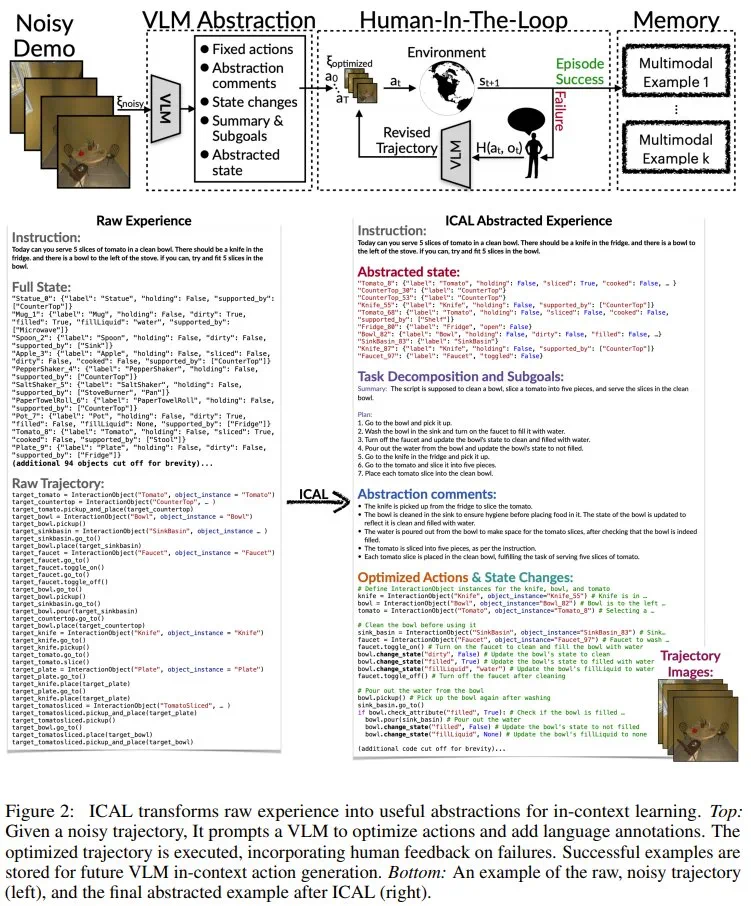
任务和因果关系,确定实现目标所需的基本原则或行动,以及要素如何通过因果关系相互关联; -
对象状态的变化,描述对象将采取的各种形式或条件; -
时间抽象,将任务分解为子目标; -
任务建构(task construals),突出任务中的关键视觉细节。
-
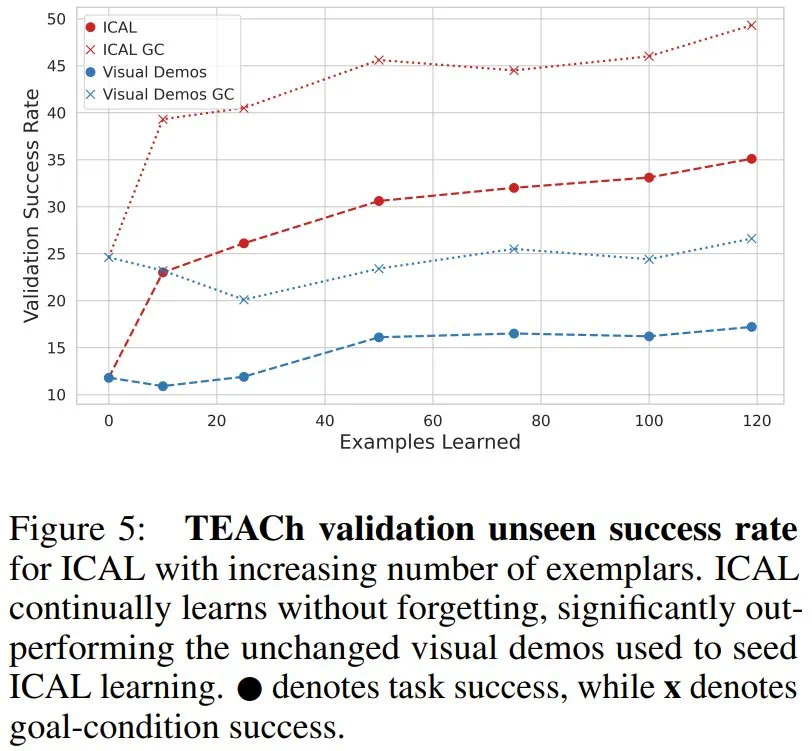
抽象阶段(F_abstract):VLM 会借助语言评论来纠正错误,并让序列更加丰富。这一阶段处理的抽象前文已有介绍,而相关的具体提示词等请参看原论文附录部分。 -
有人类参与的阶段(human-in-the-loop,记为 F_hitl):在此阶段,序列会在环境中执行,其抽象过程由以自然语言传达的人类反馈指导。这一阶段的具体流程可分为 6 步:优化轨迹的执行、监控与干预、反馈整合与轨迹修正、环境重置与重试、成功标准与反馈限度、保存示例。具体详情请访问原论文。