文章来源于互联网:从2019年到现在,是时候重新审视Tokenization了
2019 年问世的 GPT-2,其 tokenizer 使用了 BPE 算法,这种算法至今仍很常见,但这种方式是最优的吗?来自 HuggingFace 的一篇文章给出了解释。


from transformers import AutoTokenizerfrom tokenizers import pre_tokenizers, Regex# Initialize all tokenizerstokenizer = AutoTokenizer.from_pretrained ("meta-llama/Meta-Llama-3-8B")# Add an extra step to the existing pre-tokenizer stepstokenizer._tokenizer.pre_tokenizer = pre_tokenizers.Sequence ([# Added step: split by R2L digitspre_tokenizers.Split (pattern = Regex (r"d {1,3}(?=(d {3})*b)"),behavior="isolated", invert = False),# Below: Existing steps from Llama 3's tokenizerpre_tokenizers.Split (pattern=Regex (r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^rnp {L}p {N}]?p {L}+|p {N}{1,3}| ?[^sp {L}p {N}]+[rn]*|s*[rn]+|s+(?!S)|s+"),behavior="isolated", invert=False),pre_tokenizers.ByteLevel (add_prefix_space=False, trim_offsets=True, use_regex=False)])print (tokenizer.tokenize ("42069")) # [42, 069]

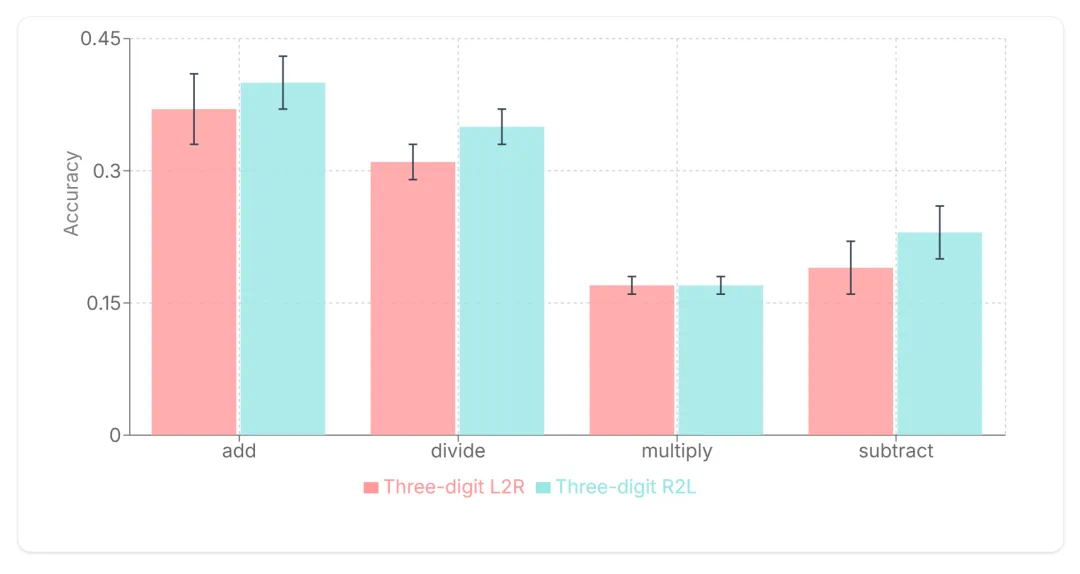
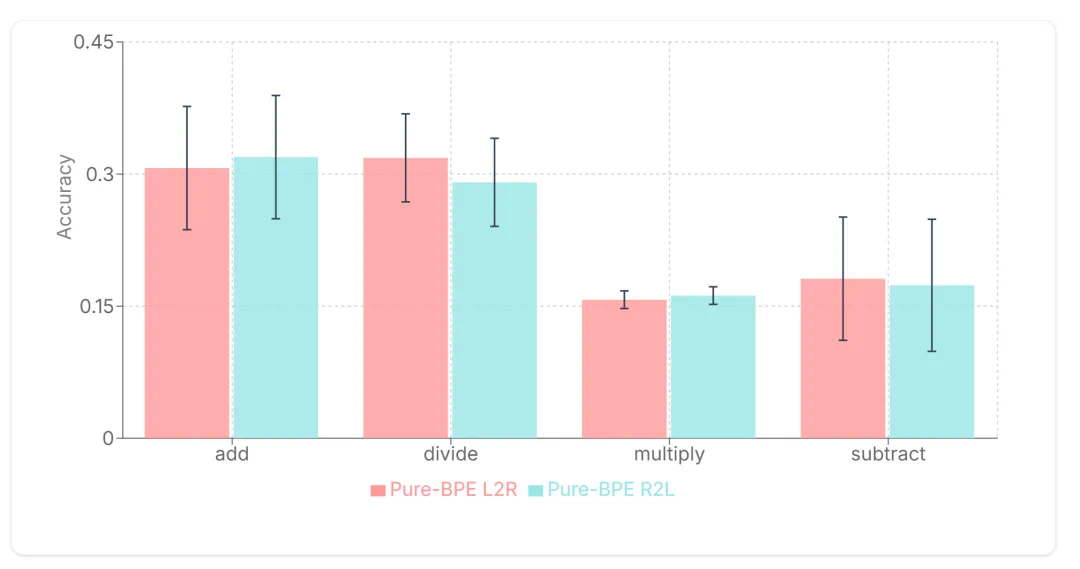
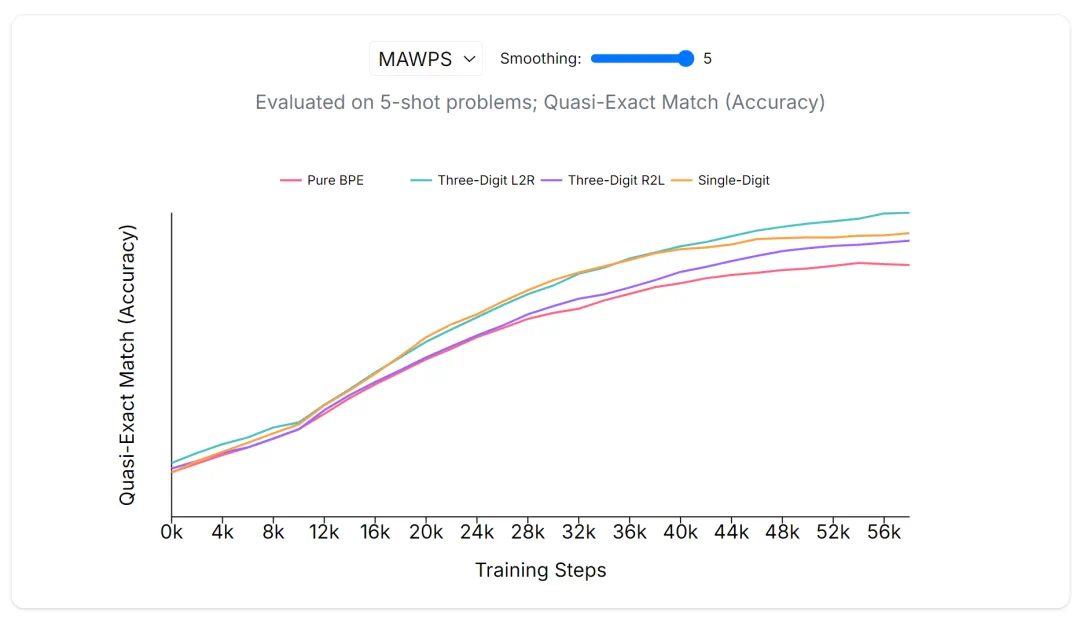
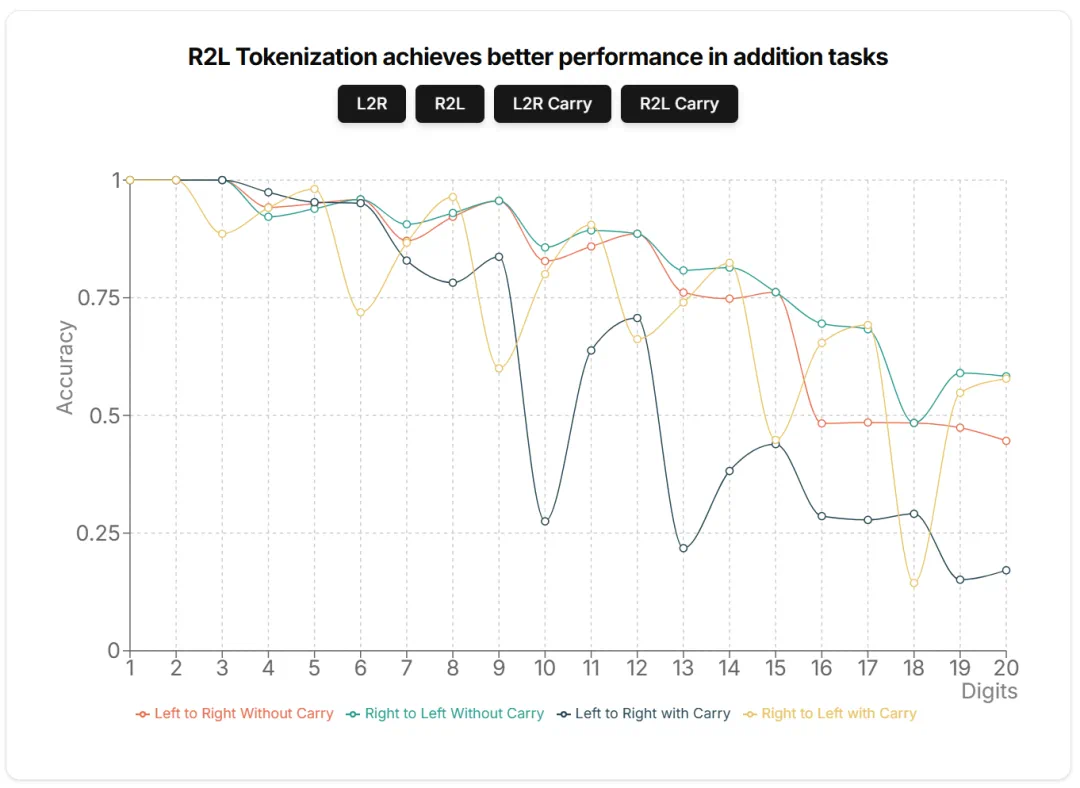
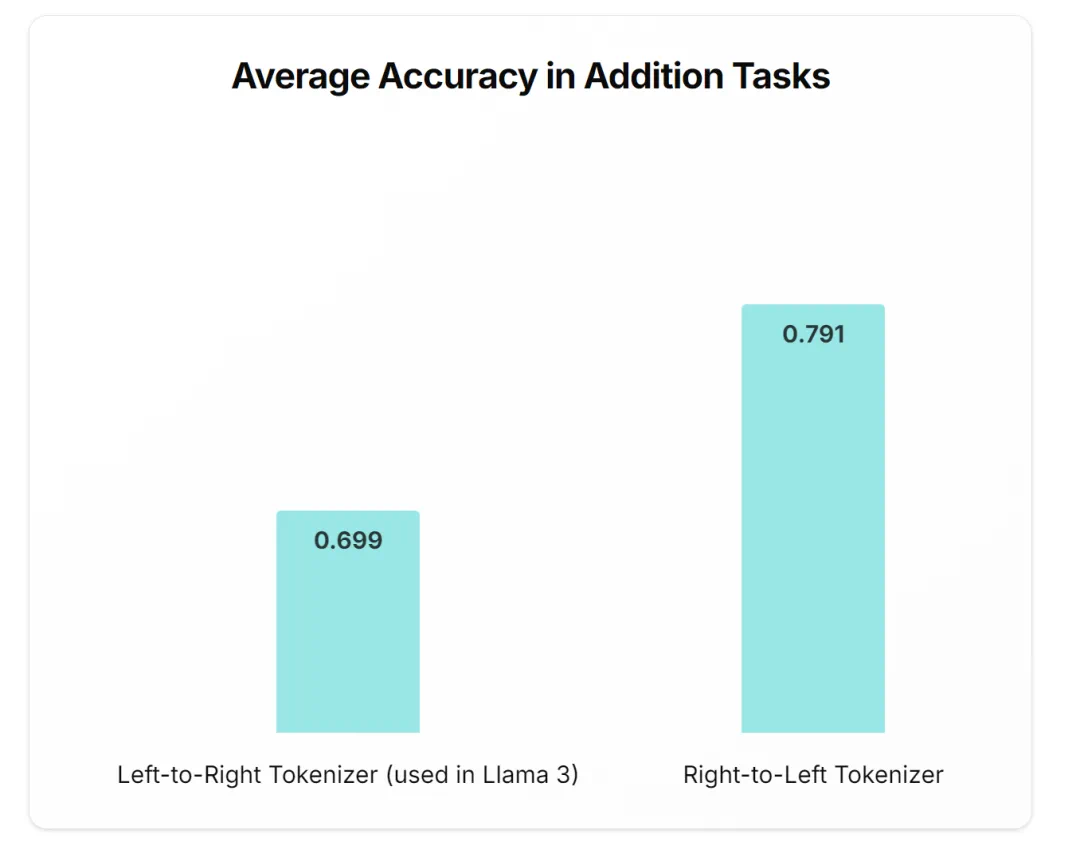
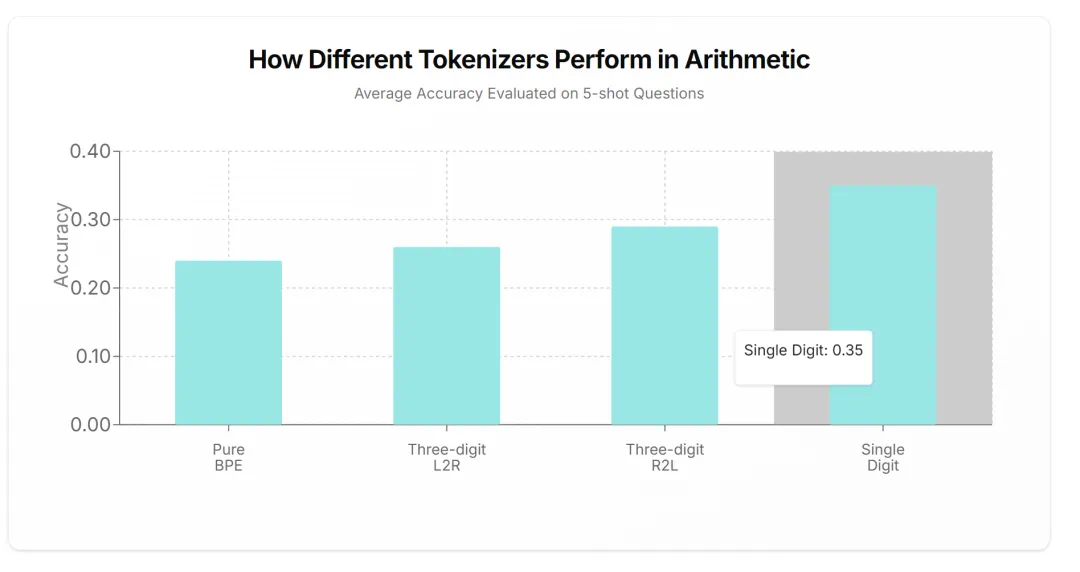
文章来源于互联网:从2019年到现在,是时候重新审视Tokenization了
