文章来源于互联网:o1也会「想太多」?腾讯AI Lab与上海交大揭秘o1模型过度思考问题

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文的共同通讯作者为涂兆鹏和王瑞,涂兆鹏为腾讯专家研究员,研究方向为深度学习和大模型,在国际顶级期刊和会议上发表学术论文一百余篇,引用超过9000次。担任SCI期刊NeuroComputing副主编,多次担任ACL、EMNLP、ICLR等国际顶级会议领域主席。王瑞为上海交通大学副教授,研究方向为计算语言学。共同第一作者为上海交通大学博士生陈星宇、何志威,腾讯AI Lab高级研究员徐嘉豪、梁添。

-
论文题目:Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
-
论文地址:https://arxiv.org/pdf/2412.21187
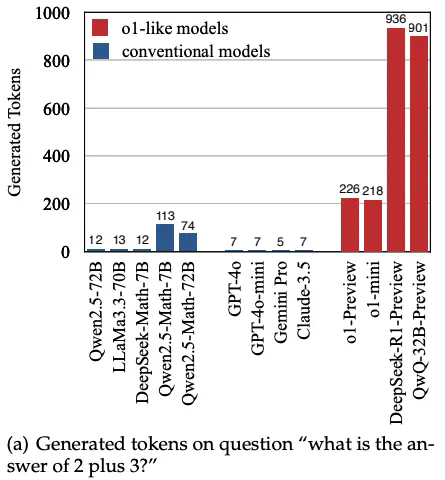
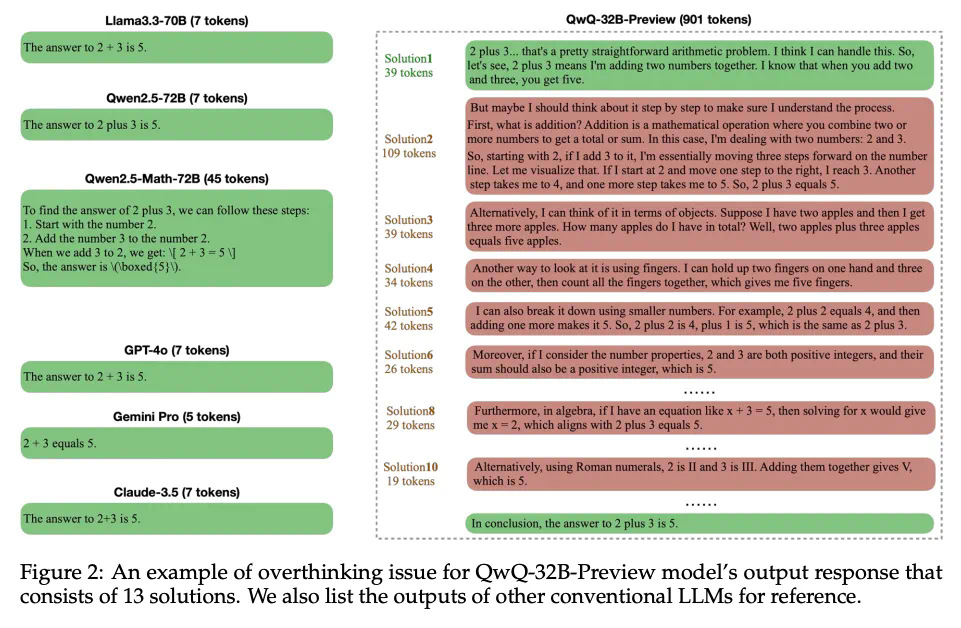
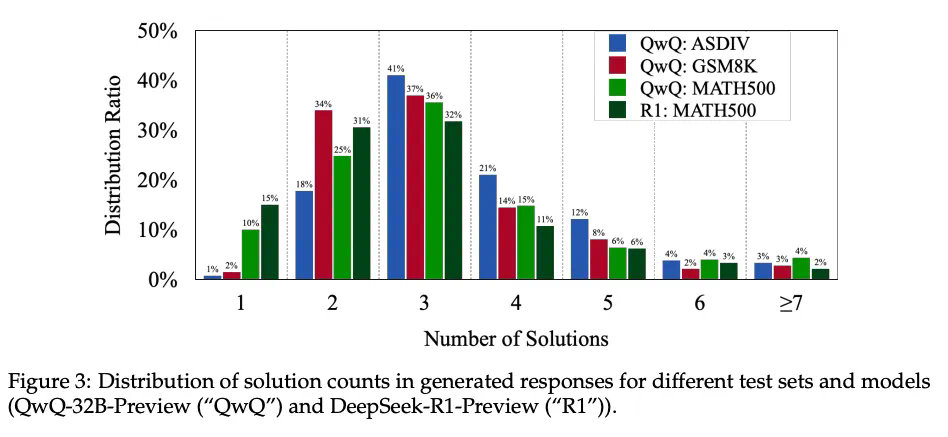
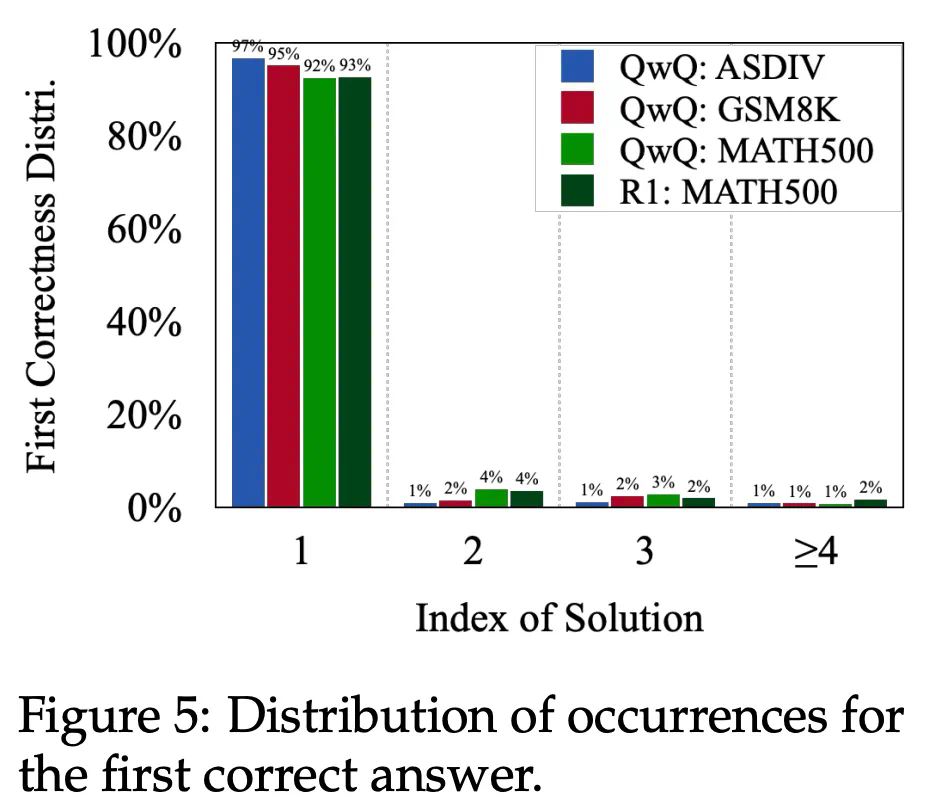
-
推理策略分类:对每一个解答进行推理策略的标注,将采用相同推理方式的回答归为同一类。例如,对于 “2+3=?” 这样的问题,可能涉及的推理策略包括数学运算模拟、数轴移动和实物类比等。
-
多样性分析:在归类的基础上,分析并统计不同解答之间的推理策略多样性。
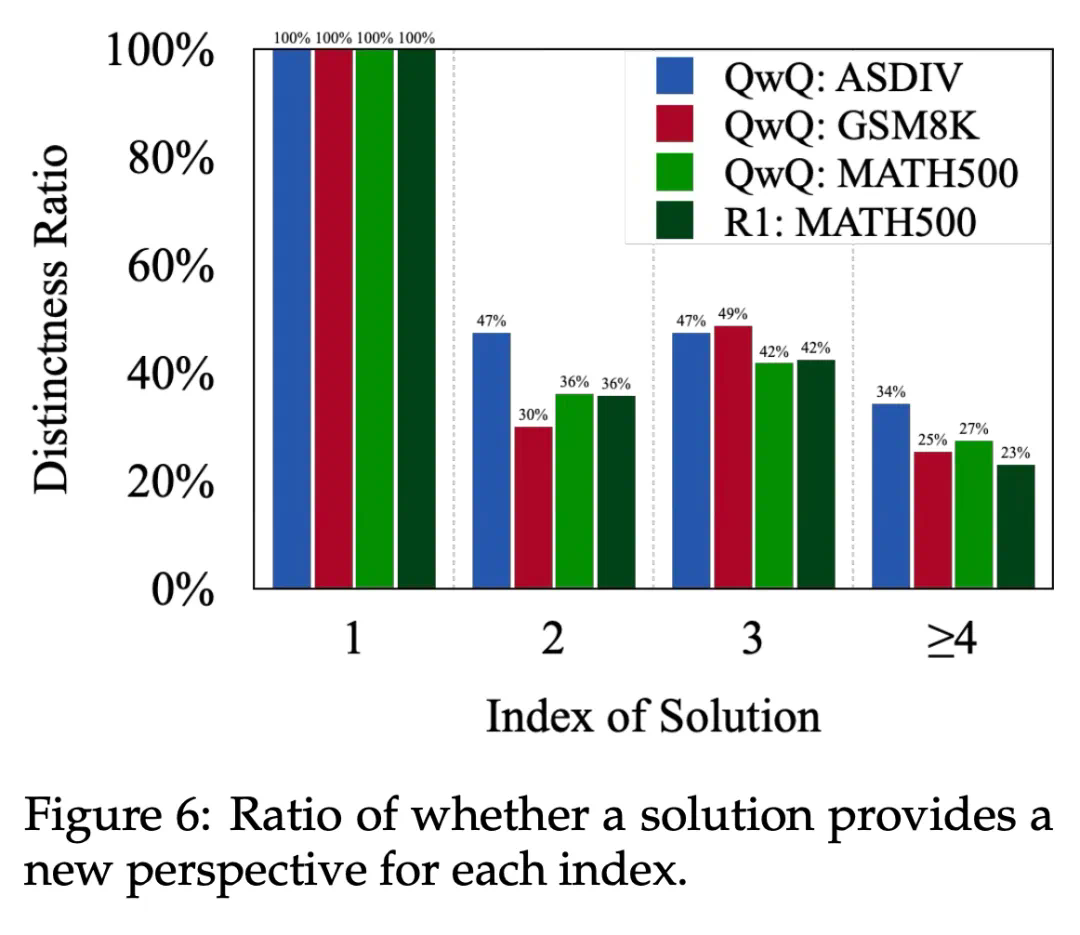
-
新解答对答案的正确性没有贡献:模型往往在一开始就已经成功得出正确答案,后续的多轮反复检验是多余且不必要的。
-
新解答未能引入实质性新思路:模型后续的解答仅以不同的表述方式重复了早先已有的结论,而没有真正扩展推理的深度或视角。
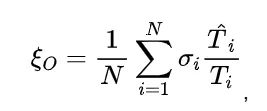
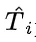 为模型第 i 个样本的回复中第一个正确解答的 token 数目,
为模型第 i 个样本的回复中第一个正确解答的 token 数目,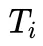 为第i个样本的整个回复的 token 数量,
为第i个样本的整个回复的 token 数量,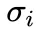 代表第i个样本是否正确。直观地看,一个模型得到正确解答之后进行反思的轮数越少,正确解答在整个回复中的占比就越大,产出效率就越高。
代表第i个样本是否正确。直观地看,一个模型得到正确解答之后进行反思的轮数越少,正确解答在整个回复中的占比就越大,产出效率就越高。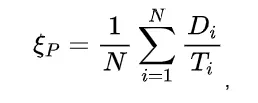
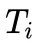 为第i个样本的整个回复 token 数量,
为第i个样本的整个回复 token 数量,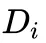 为第i个样本中所有属于不同推理策略的 token 总数。该指标衡量的是模型进行多轮反思的有效性,回答中涉及的不同的推理策略越多,
为第i个样本中所有属于不同推理策略的 token 总数。该指标衡量的是模型进行多轮反思的有效性,回答中涉及的不同的推理策略越多,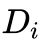 就会越大,那么过程效率就会越高。
就会越大,那么过程效率就会越高。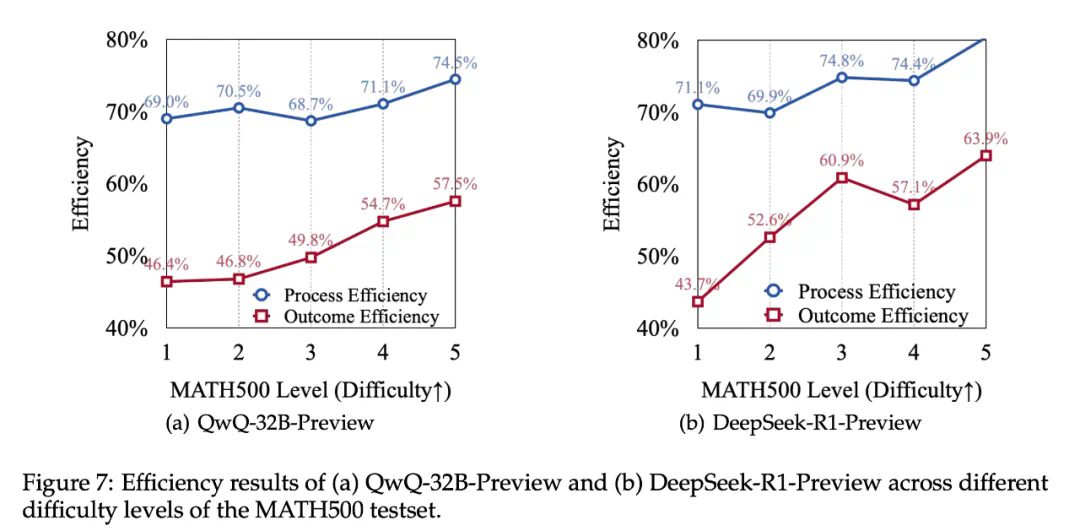
-
产出效率不足一半:两个模型在这种简单任务上的产出效率均未超过 50%,意味着模型在取得正确答案后,依然生成了超过必要推理步骤至少一倍的额外推理内容。这符合上文的研究发现:正确答案通常在推理的较早阶段得到,但模型的后续行为中存在大量冗余推理。
-
思考过程效率较低:模型的整体过程效率只有 70% 左右,这意味着约 30% 的思考步骤是在重复无效的推理。这种重复的行为不仅未能提升正确率,也没有引入新的解题思路,从而造成了计算资源的浪费。
-
最短回复(Shortest Response):使用模型采样结果中最短的生成结果作为正样本。
-
首个正确回答(First-Correct Solutions, FCS):使用模型采样结果中最短的首次得到正确答案的解答作为正样本,抛弃所有后续的思考。
-
首个正确回答 + 验算(FCS+Reflection):由于绝大多数的采样结果都是在第一个解答中就出现了正确答案,仅保留首个正确回答可能会使得模型退化,因此研究者们在第一次得到正确答案后,额外保留了一轮反思的内容。
-
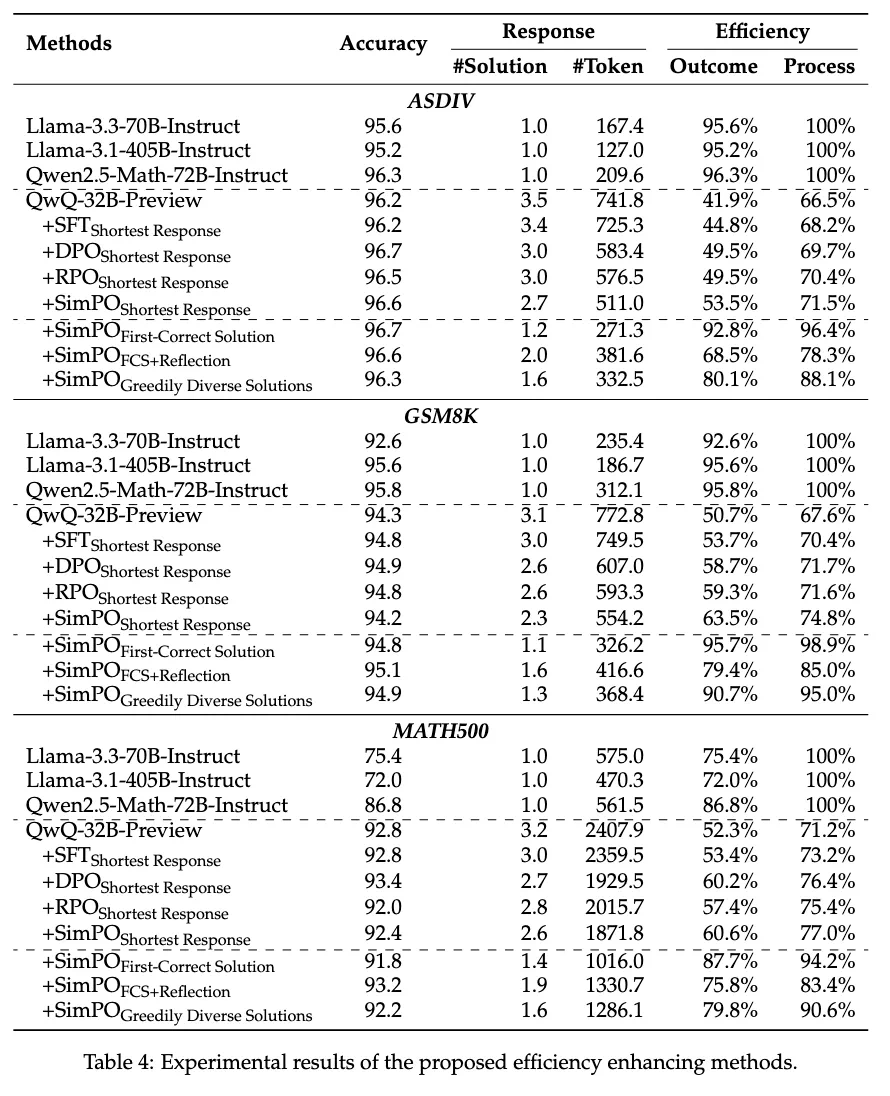
最多样回复(Greedily Diverse Solutions,GDS):除了单纯地对长度进行控制,另一个优化思路是尽可能保留更多样化的思考轨迹,因此研究者们在 FCS 方法的基础上,尽可能多地保留了包含不同推理策略的解答。
-
自适应调控策略:开发让模型根据问题复杂程度动态调整推理深度的机制,更智能地分配计算资源;
-
更精细的效率评估指标:设计能够覆盖更广泛推理轨迹的指标,从而更全面地评估模型的思考效率。
文章来源于互联网:o1也会「想太多」?腾讯AI Lab与上海交大揭秘o1模型过度思考问题

