文章来源于互联网:让7B千问模型超越o1,微软rStar-Math惊艳登场,网友盛赞
OpenAI o1 给大模型规模扩展 vs 性能的曲线带来了一次上翘。它在大模型领域重现了当年 AlphaGo 强化学习的成功 —— 给越多算力,就输出越多智能,一直到超越人类水平。
但这种突破背后是庞大的算力支持与推理开销:API 的价格上,o1-preview 每百万输入 15 美元,每百万输出 60 美元,而最新版的 o3 在处理复杂推理任务时,单次成本更是高达数千美元。
业界一直在寻找一个更经济、更高效的解决方案。而这个答案可能比预期来得更快一些。
今天登顶 Hugging Face 热门榜一的论文展示了小模型的潜力。来自微软亚洲研究院的研究团队提出了 rStar-Math。rStar-Math 向我们证明,1.5B 到 7B 规模的小型语言模型(SLM)无需从更大模型蒸馏,就能在数学推理能力上媲美甚至超越 OpenAI o1。

-
论文标题:rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking -
论文链接:https://arxiv.org/pdf/2501.04519 -
Github 链接:https://github.com/microsoft/rStar(即将开源)


-
视频链接:https://www.youtube.com/watch?v=cHgHS6Y3QP0
-
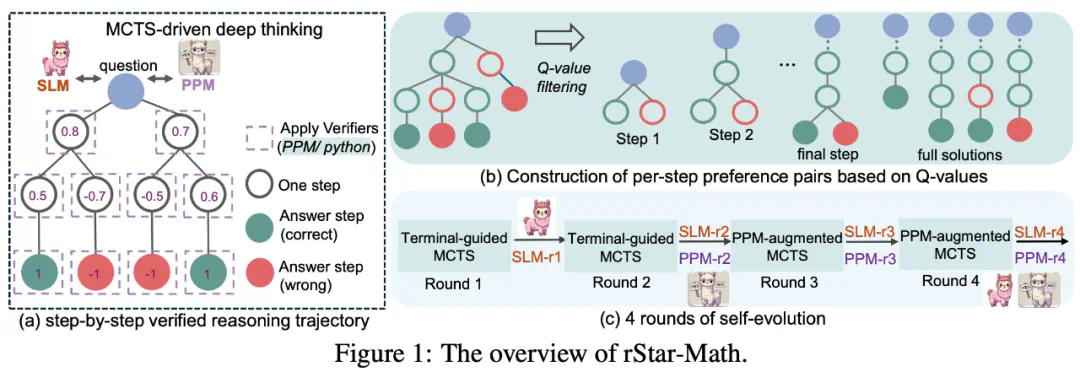
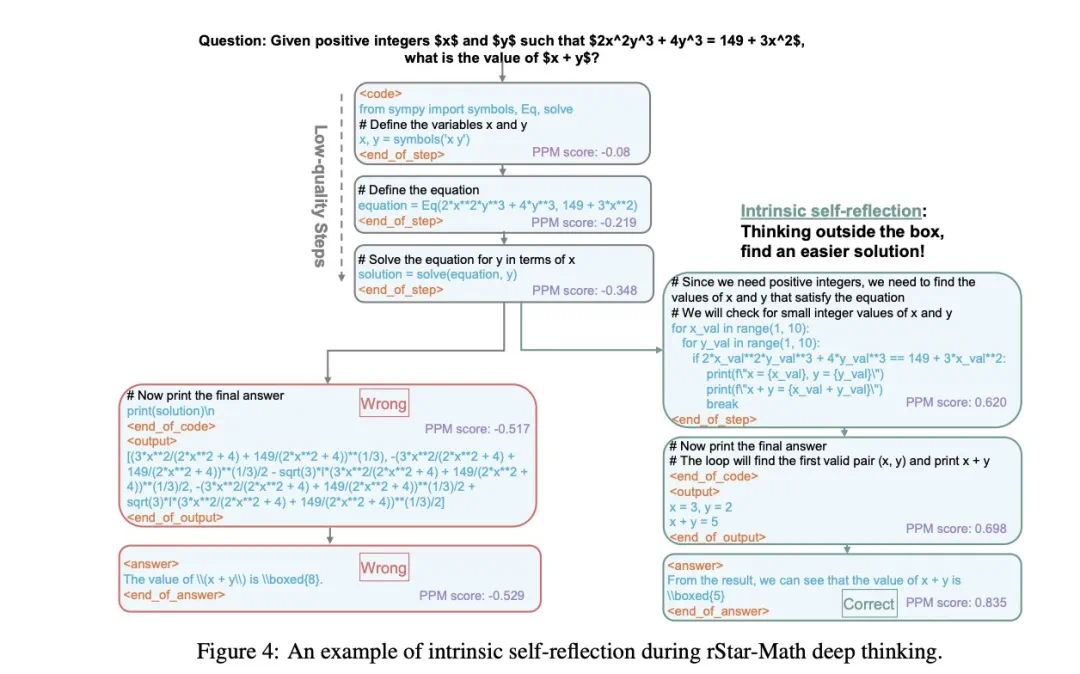
创新的代码增强 CoT 数据合成方法,通过大量 MCTS rollout 生成经过验证的逐步推理轨迹,用于训练策略 SLM;
-
过程奖励模型训练方法也有所改进,避免了简单的步级分数标注,提升了过程偏好模型(PPM)的评估效果;
-
模型会自我进化,采用完全自主训练方案,从零开始构建并训练模型,通过持续的迭代优化来不断提升推理能力。

-
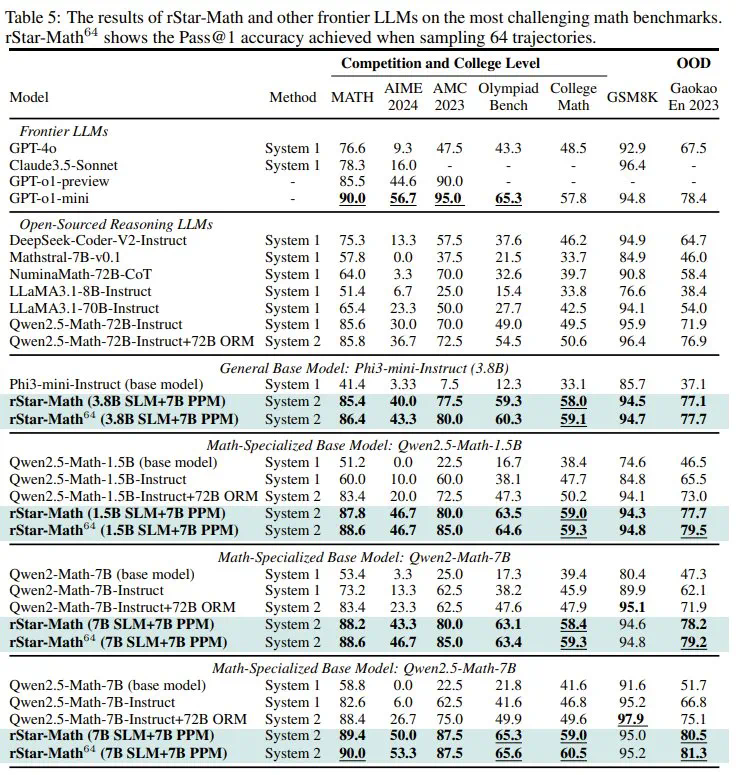
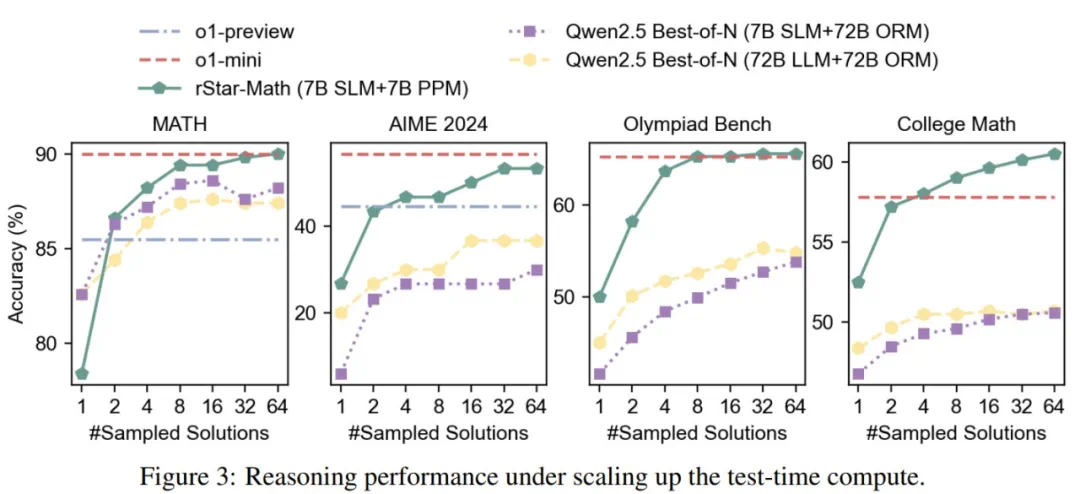
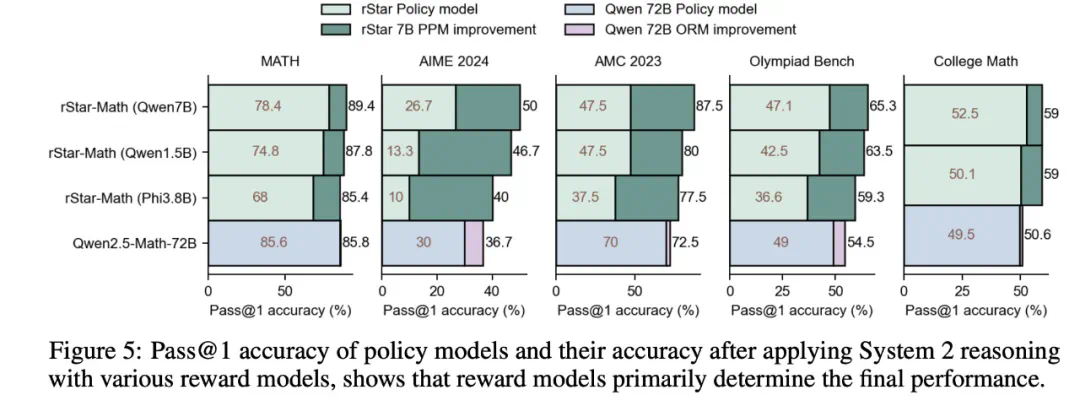
rStar-Math 显著提高了小语言模型(SLM)的数学推理能力,在模型规模显著缩小(1.5B-7B)的情况下,其性能可媲美甚至超越 OpenAI o1。
-
尽管使用了较小的策略模型(1.5B-7B)和奖励模型(7B),rStar-Math 的表现仍明显优于最先进的 System 2 基线。
-
除了 MATH、GSM8K 和 AIME 等可能存在过度优化风险的知名基准之外,rStar-Math 在其他具有挑战性的数学基准上表现出很强的通用性,包括 Olympiad Bench、College Math 和 Chinese College Entrance Math Exam(Gaokao),创下了新的最高分。
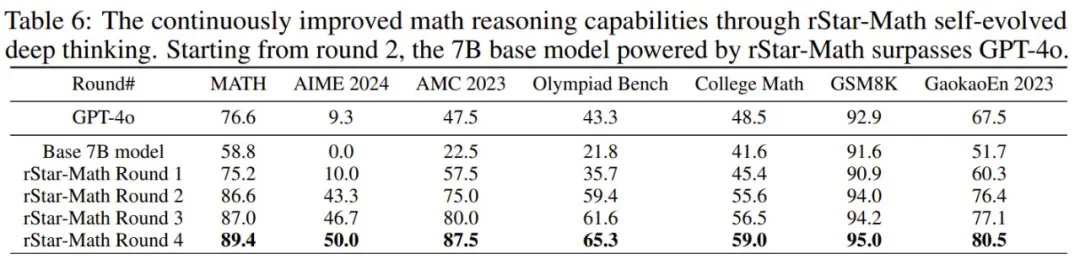
-
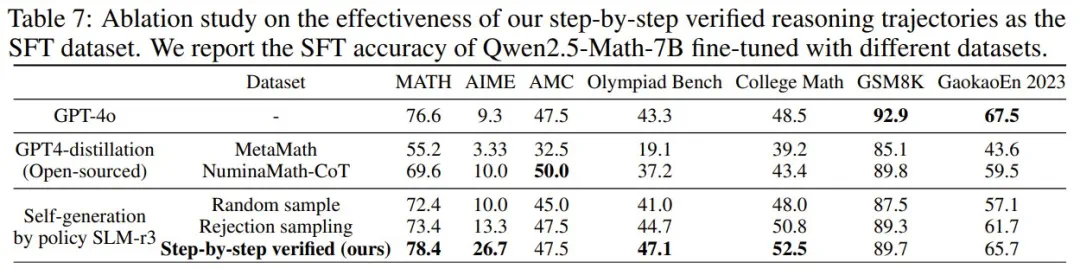
使用新提出的逐步验证的轨迹进行微调明显优于所有其他基线。这主要归功于用于代码增强型 CoT 合成的 PPM 增强型 MCTS,它能在数学解答生成期间提供更密集的验证。 -
使用该团队的小语言模型,即使随机采样代码增强型 CoT 解答,得到的结果也可媲美或优于 GPT-4 合成的 NuminaMath 和 MetaMath 数据集。这表明,经过几轮自我进化后,新的策略 SLM 可以生成高质量的数学解答。这些结果证明新方法在不依赖高级 LLM 蒸馏的情况下,就具备自我生成更高质量推理数据的巨大潜力。

文章来源于互联网:让7B千问模型超越o1,微软rStar-Math惊艳登场,网友盛赞

