文章来源于互联网:一行代码Post-Train任意长序列!360智脑开源360-LLaMA-Factory

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
sequence_parallel_size: 16
sequence_parallel_size: 16
-
预训练阶段,英伟达的 Megatron-LM 凭借丰富高效的并行策略与出色的 GPU 显存优化,成为主流框架,基于它的定制开发往往是最通用的解法, Megatron-LM 本身已实现了序列并行(Megatron-LM 称之为 context parallelism,其他工作一般称为 sequence parallelism)。
-
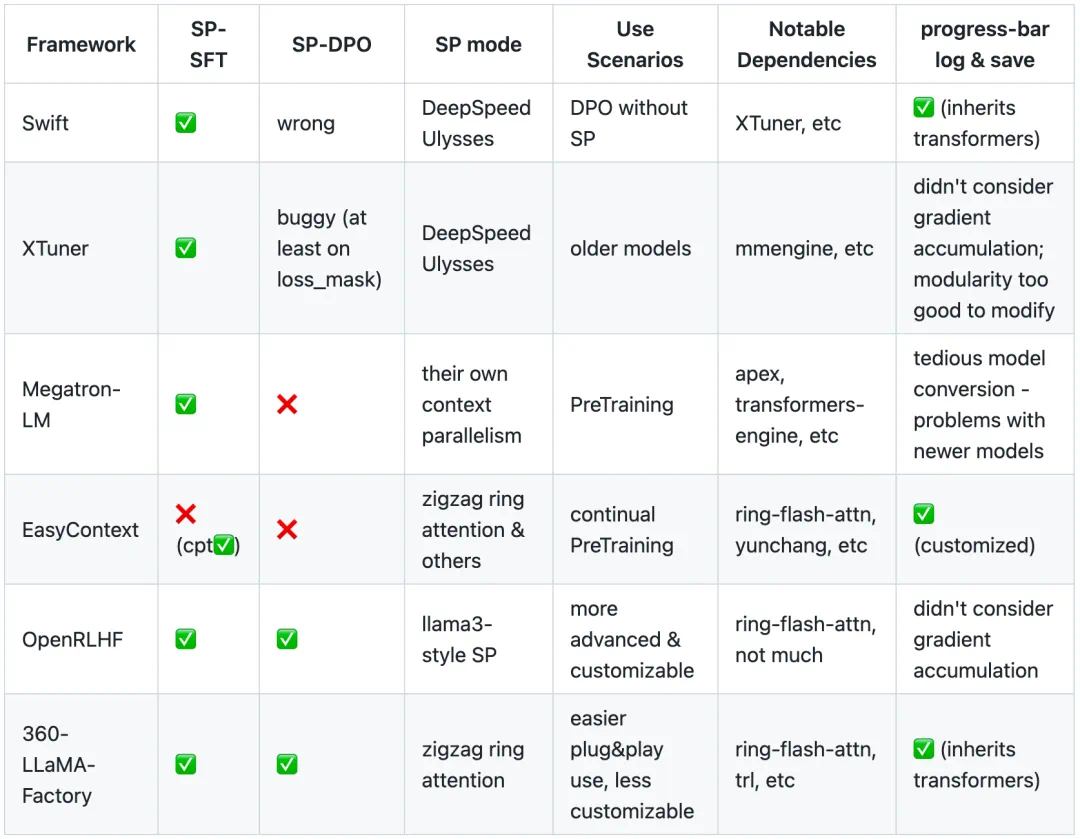
后训练阶段情况相对复杂。后训练算法多样,如 DPO 就有诸多变种,且训练需求灵活多变,不同场景对算法、资源、并行性等要求各异。因此,至今没有一个框架能在并行策略、后训练算法、GPU 显存优化和易用性这四个关键方面做到近乎完美的兼容。虽有框架在部分方面表现尚可,但总体仍存在短板,这也限制了模型在长序列数据后训练上的进一步发展。
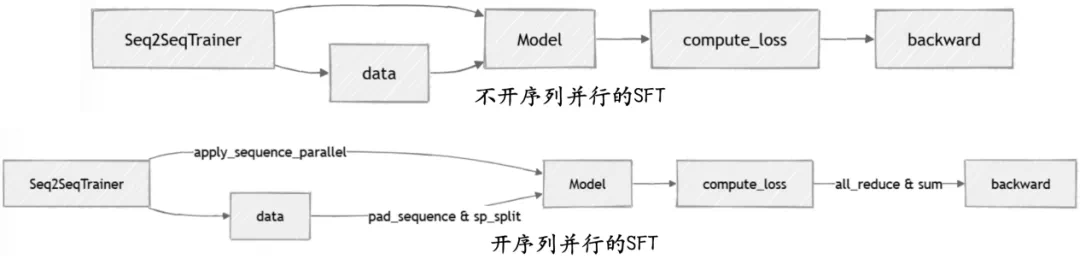
# src/llamafactory/model/loader.pysequence_parallel_group = apply_sequence_parallel(model_args) # 序列并行monkey patch,改动attention计算...model.sequence_parallel_group = sequence_parallel_group # 维护模型的序列并行组,不开则为None
# src/llamafactory/data/loader.py@sequence_parallel_decoratordef get_dataset(...)
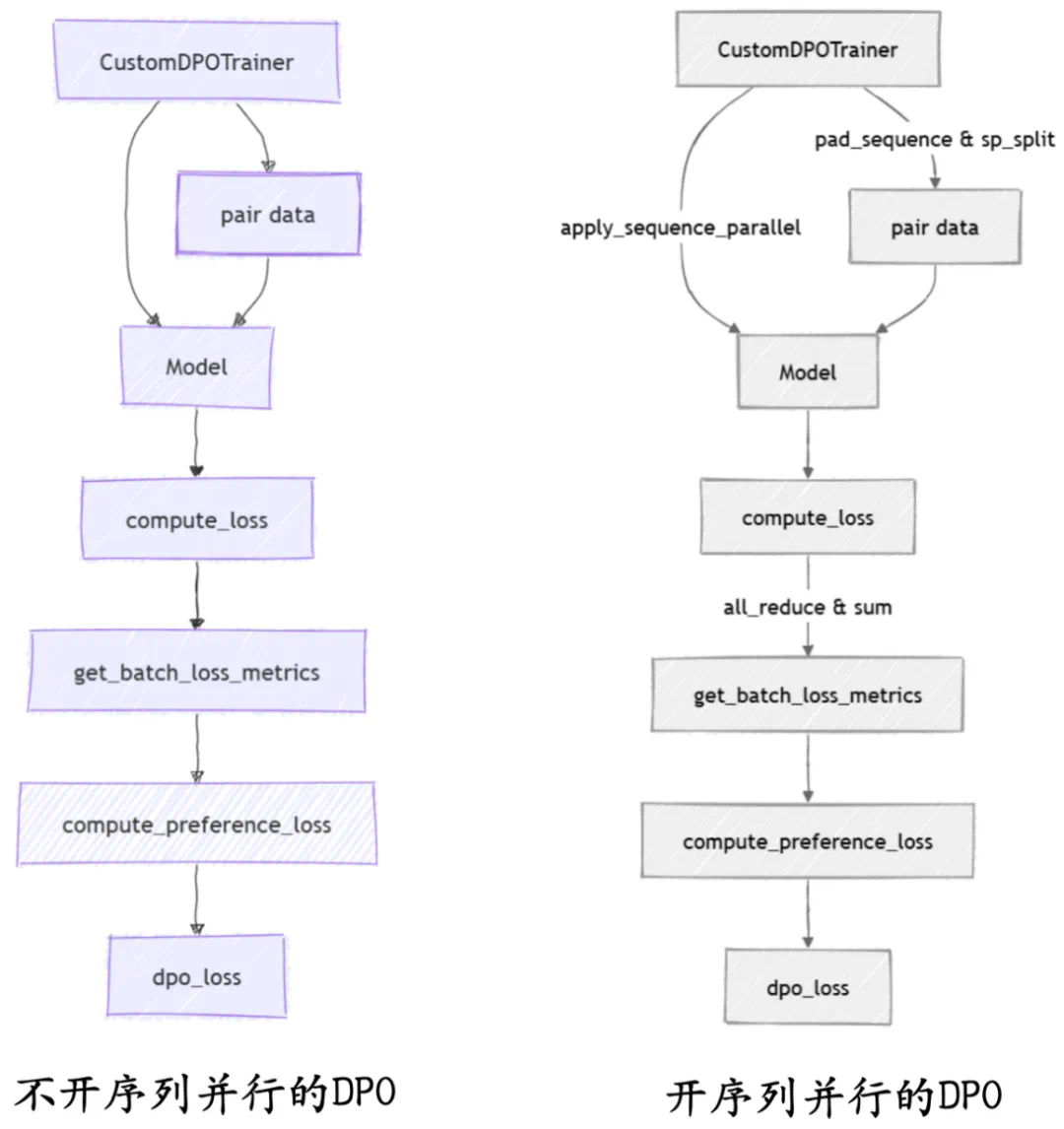
# src/llamafactory/train/sft/trainer.pydist.all_reduce(loss, op=dist.ReduceOp.SUM, group=sp_group)dist.all_reduce(label_num, op=dist.ReduceOp.SUM, group=sp_group)loss /= label_num# src/llamafactory/train/dpo/trainer.pydist.all_reduce(policy_chosen_logps, op=dist.ReduceOp.SUM, group=sp_group)dist.all_reduce(policy_rejected_logps, op=dist.ReduceOp.SUM, group=sp_group)dist.all_reduce(reference_chosen_logps, op=dist.ReduceOp.SUM, group=sp_group)dist.all_reduce(reference_rejected_logps, op=dist.ReduceOp.SUM, group=sp_group)
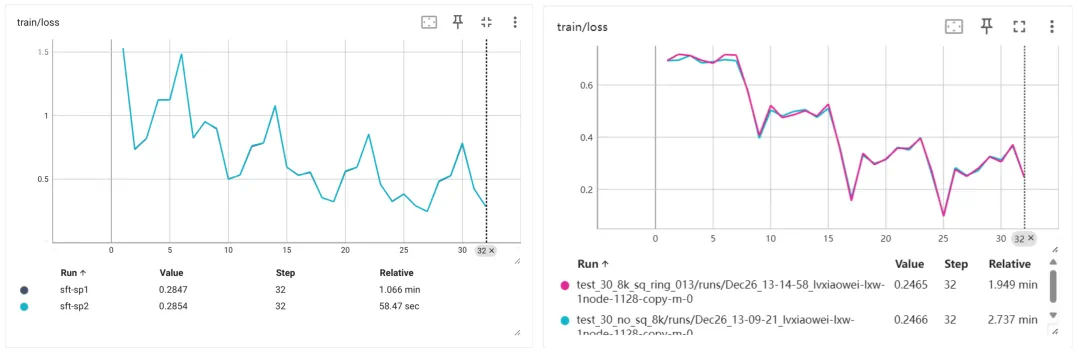
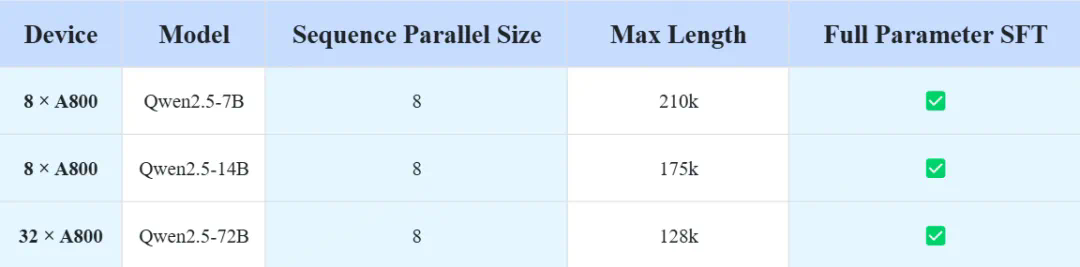
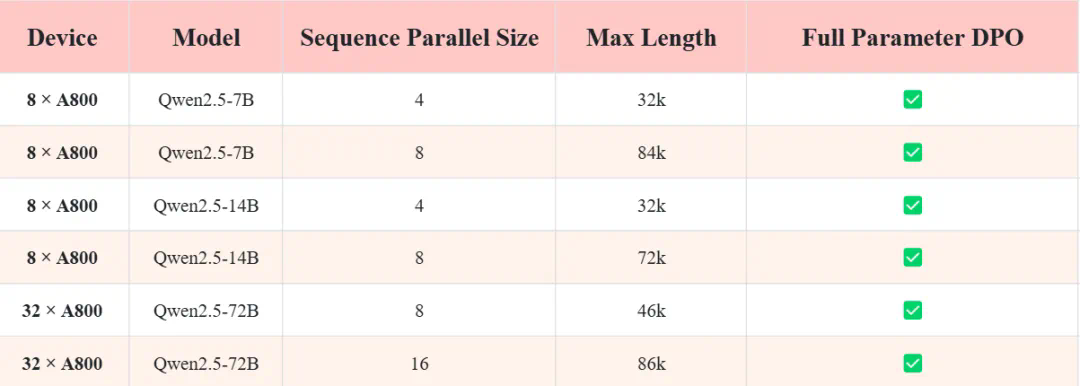
@software{360-llama-factory,author = {Haosheng Zou, Xiaowei Lv, Shousheng Jia and Xiangzheng Zhang},title = {360-LLaMA-Factory},url = {https://github.com/Qihoo360/360-LLaMA-Factory},year = {2024}}

