文章来源于互联网:TPAMI-2024 | Uni-AdaFocus视频理解框架,让AI学会「划重点」,计算效率提升4-23倍!

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
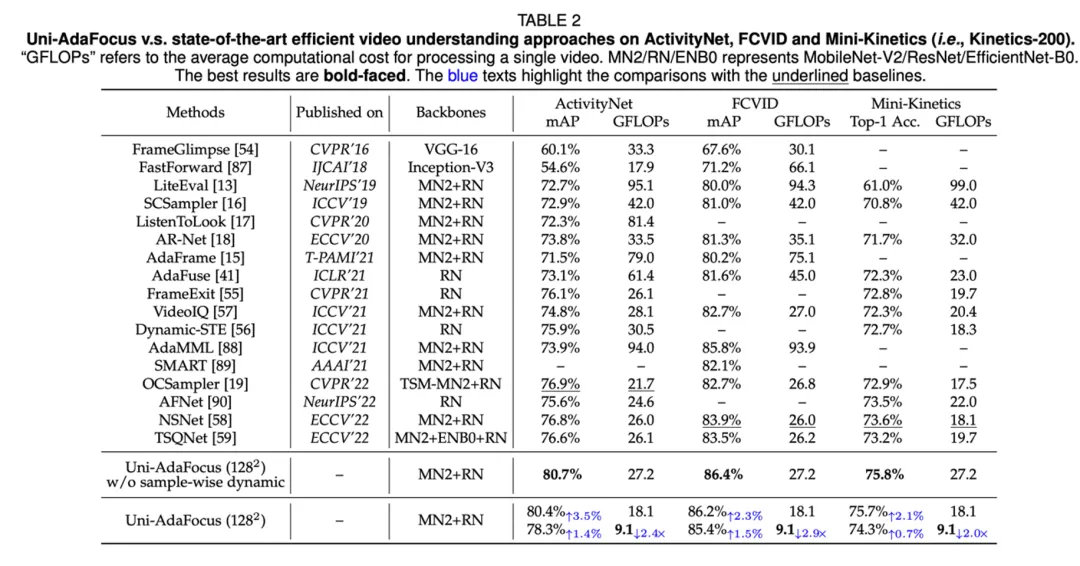
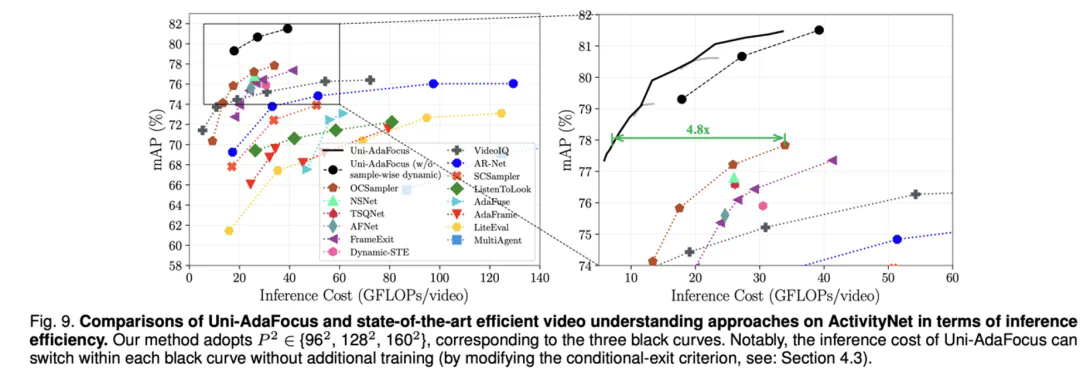
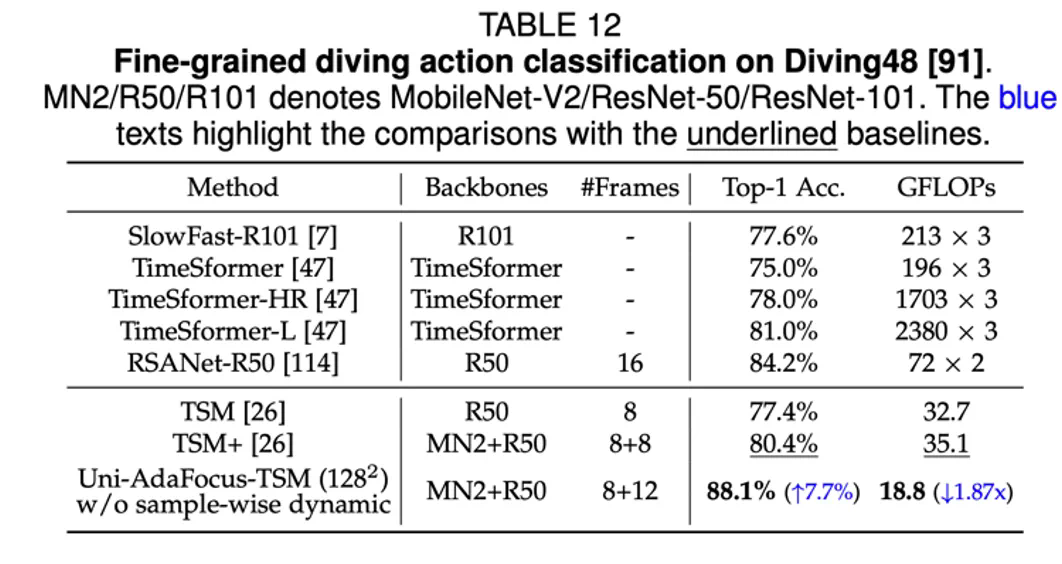
本文介绍刚刚被 IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 录用的一篇文章:Uni-AdaFocus: Spatial-temporal Dynamic Computation for Video Recognition,会议版本 AdaFocus V1/V2/V3 分别发表于 ICCV-2021 (oral)、CVPR-2022、ECCV-2022。

-
论文链接:https://arxiv.org/abs/2412.11228 -
项目链接:https://github.com/LeapLabTHU/Uni-AdaFocus
-
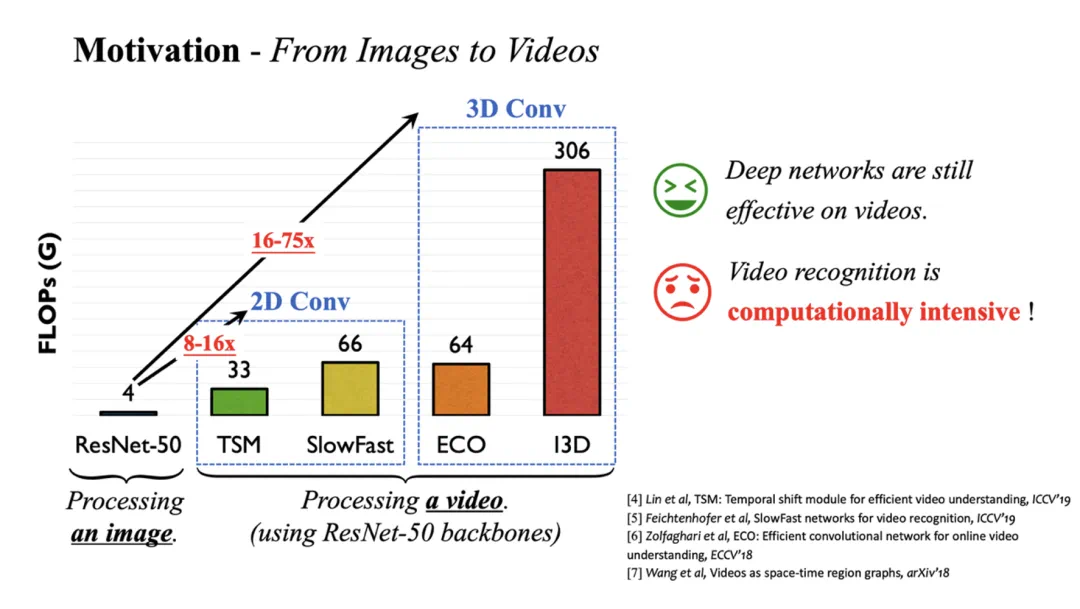
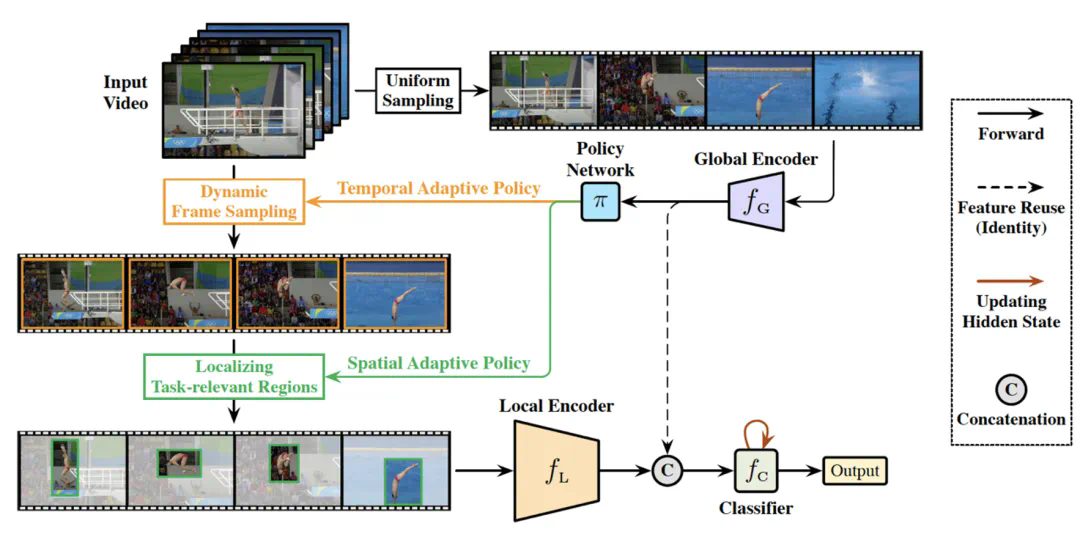
降低时间冗余性:动态定位和聚焦于任务相关的关键视频帧; -
降低空间冗余性:动态定位和聚焦于视频帧中的任务相关空间区域; -
降低样本冗余性:将计算资源集中于更加困难的样本,在不同样本间差异化分配;


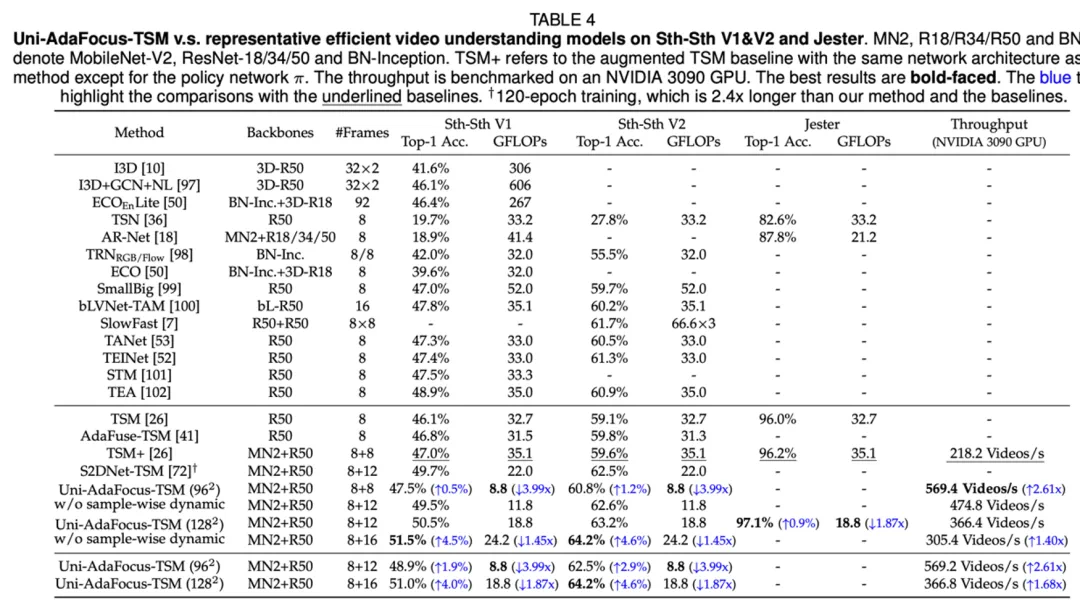
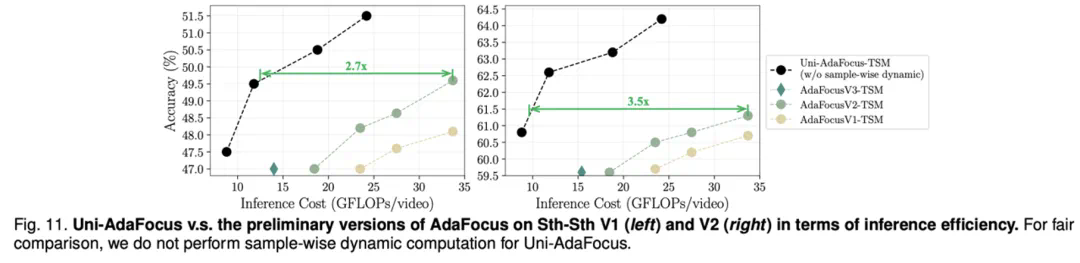
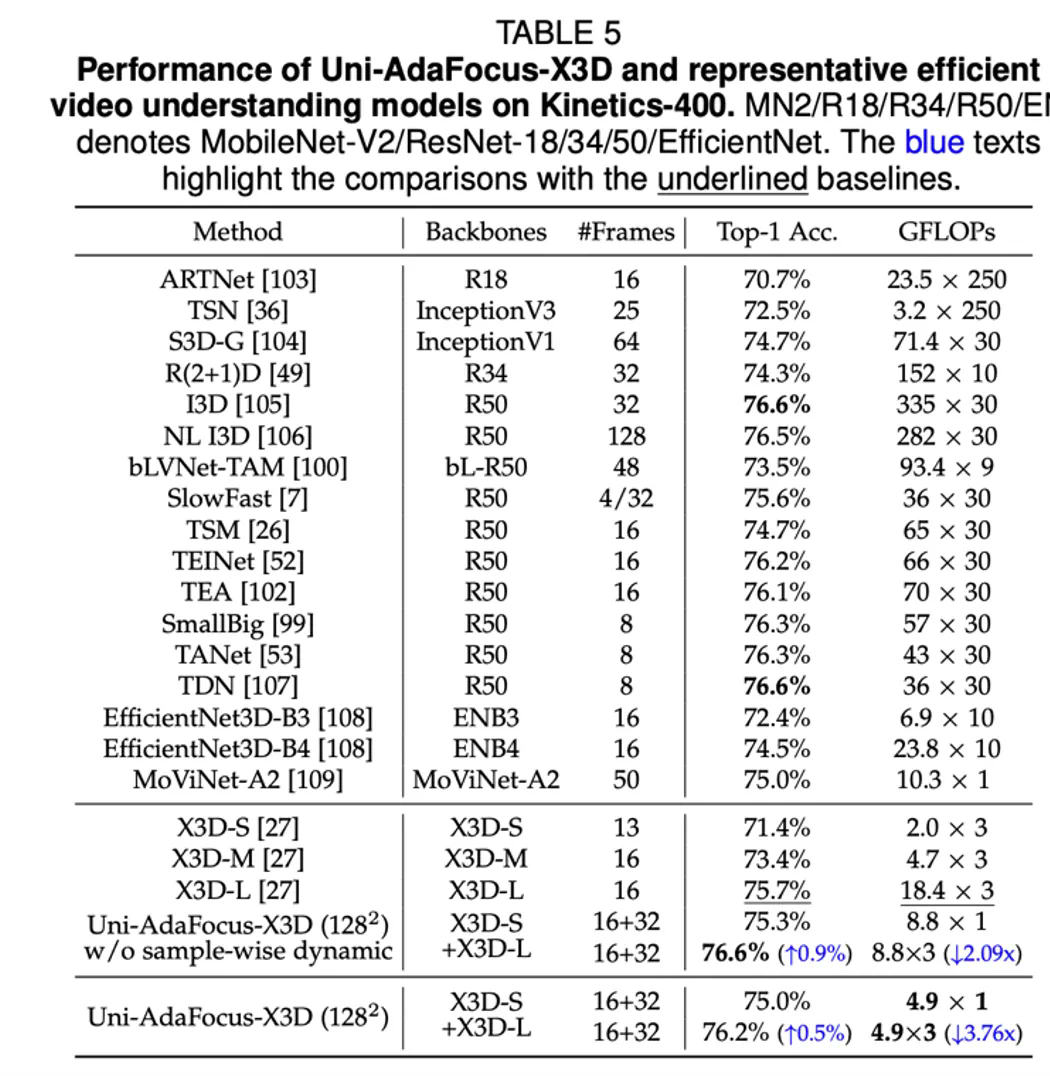
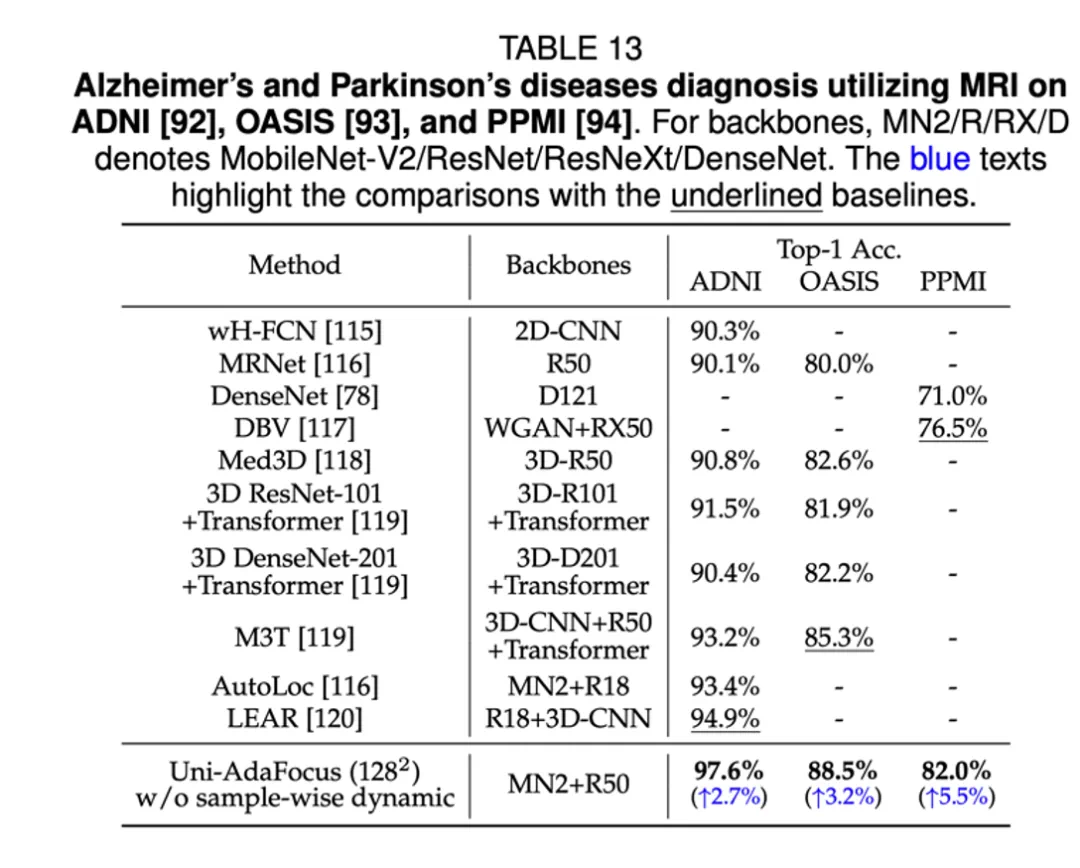


文章来源于互联网:TPAMI-2024 | Uni-AdaFocus视频理解框架,让AI学会「划重点」,计算效率提升4-23倍!

