文章来源于互联网:揭示显式CoT训练机制:思维链如何增强推理泛化能力

-
Q1:与无 CoT 训练相比,采用 CoT 训练有哪些优势? -
Q2:如果存在优势,显式 CoT 训练的潜在机制是什么?
-
CoT 训练的优势
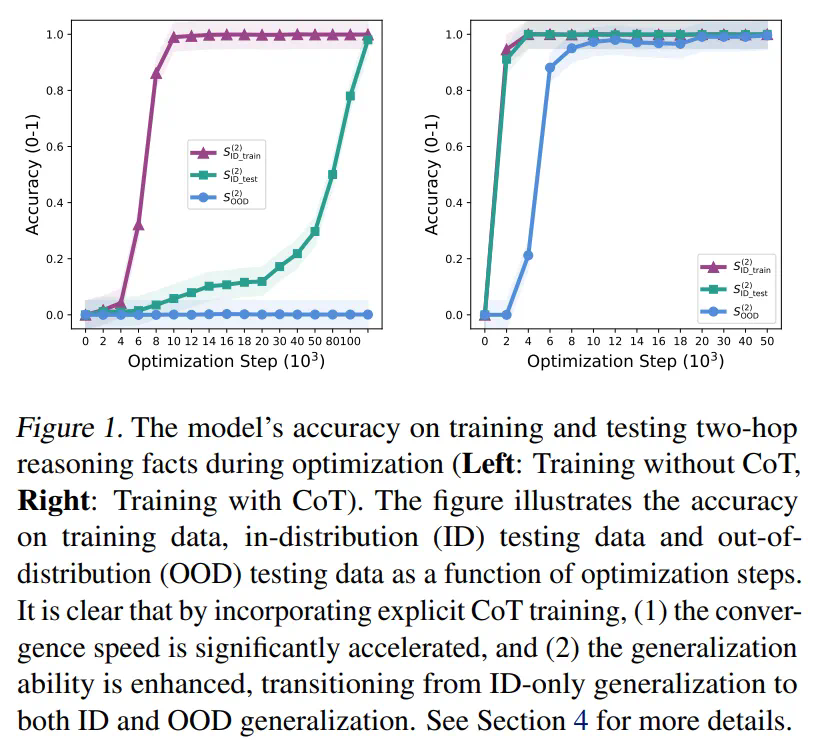
-
CoT 训练的内部机制

-
论文标题:Unveiling the Mechanisms of Explicit CoT Training: How Chain-of-Thought Enhances Reasoning Generalization -
论文链接:https://arxiv.org/abs/2502.04667
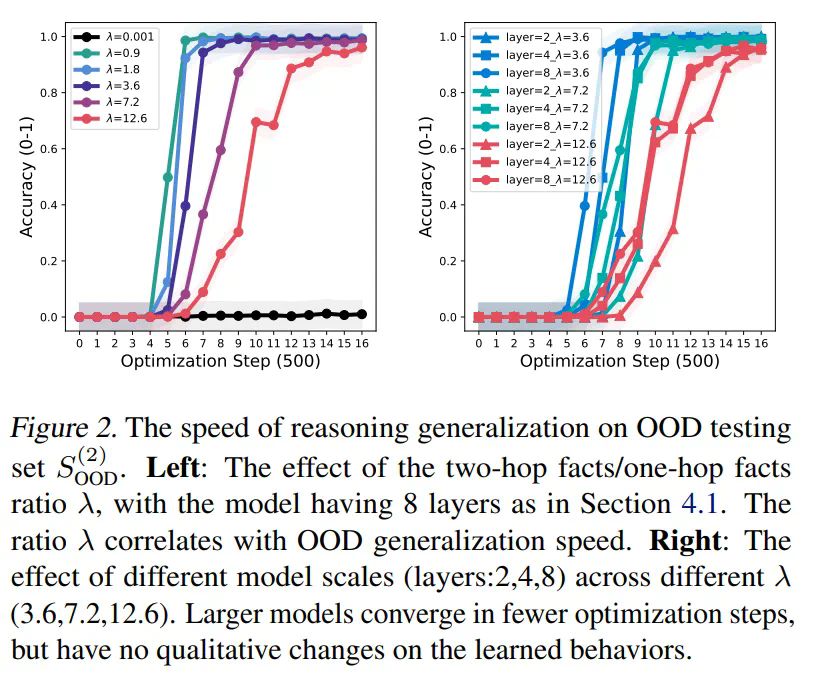
原子与多跳事实:研究使用三元组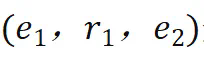 来表示原子(一跳)事实,并基于原子事实和连接规则来表示两跳事实以及多跳事实。
来表示原子(一跳)事实,并基于原子事实和连接规则来表示两跳事实以及多跳事实。

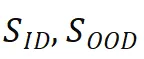 ),以及分布内(ID)的两跳事实(即
),以及分布内(ID)的两跳事实(即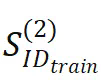 )。其中记 | 两跳事实 |:| 原子事实 |= λ。
)。其中记 | 两跳事实 |:| 原子事实 |= λ。
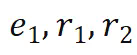 ,预测目标只有最终尾实体
,预测目标只有最终尾实体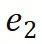 ;
;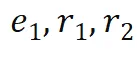 ,预测桥接实体
,预测桥接实体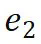 和最终尾实体
和最终尾实体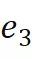 。
。
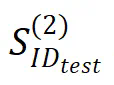 的能力,判断模型是否正确学习了潜在模式。
的能力,判断模型是否正确学习了潜在模式。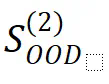 事实上测试模型来实现的。若模型在分布内数据上表现良好,可能仅表明其记忆或学习了训练数据中的模式。然而,在分布外数据上的优异表现则表明模型确实掌握了潜在模式,因为训练集仅包含原子事实
事实上测试模型来实现的。若模型在分布内数据上表现良好,可能仅表明其记忆或学习了训练数据中的模式。然而,在分布外数据上的优异表现则表明模型确实掌握了潜在模式,因为训练集仅包含原子事实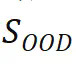 ,而不包含
,而不包含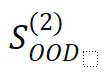 。
。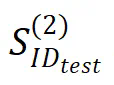 ,但高性能只有在经过大量训练后才能实现,远超过过拟合点。此外,即使经过数百万次优化步骤的训练,仍未观察到分布外泛化(
,但高性能只有在经过大量训练后才能实现,远超过过拟合点。此外,即使经过数百万次优化步骤的训练,仍未观察到分布外泛化(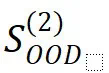 )的迹象,这表明这是一种缺乏系统性的延迟泛化现象。模型可能只是记忆或学习了训练数据中的模式。
)的迹象,这表明这是一种缺乏系统性的延迟泛化现象。模型可能只是记忆或学习了训练数据中的模式。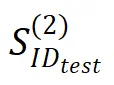 上的准确率就达到了接近完美的水平,表明与无思维链训练相比,泛化能力得到了显著提升。分布外泛化(
上的准确率就达到了接近完美的水平,表明与无思维链训练相比,泛化能力得到了显著提升。分布外泛化(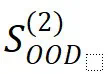 )也显示出明显改善,这突出表明思维链提示训练不仅在分布内泛化方面,而且在分布外泛化方面都发挥着关键作用,尽管效果程度有所不同。
)也显示出明显改善,这突出表明思维链提示训练不仅在分布内泛化方面,而且在分布外泛化方面都发挥着关键作用,尽管效果程度有所不同。
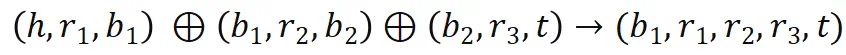 来表示三跳事实)。
来表示三跳事实)。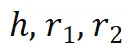 预测
预测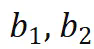 和
和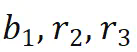 预测
预测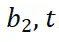 ,当两者都正确时,我们认为
,当两者都正确时,我们认为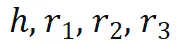 预测
预测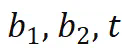 是正确的。这些发现与 [15] 结果一致:思维链与重现训练集中出现的推理模式有关。
是正确的。这些发现与 [15] 结果一致:思维链与重现训练集中出现的推理模式有关。
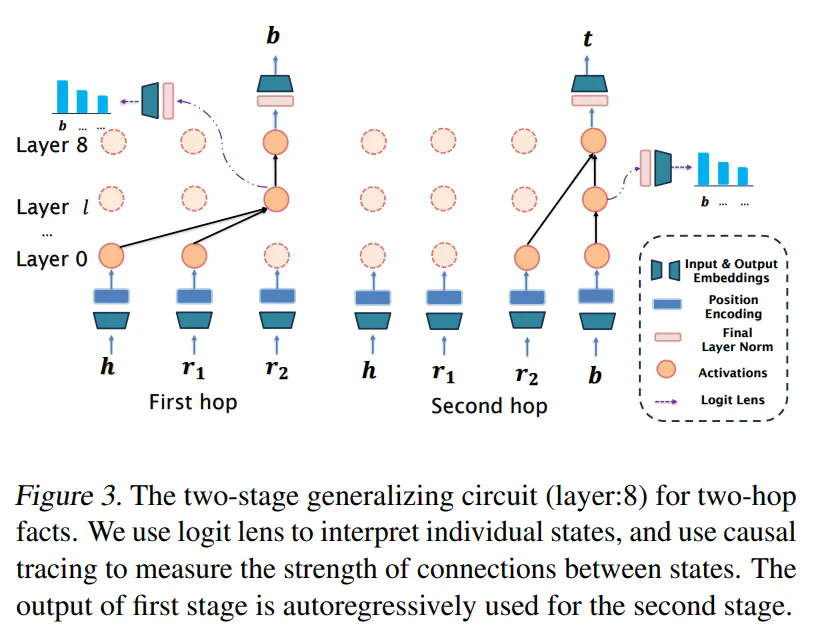
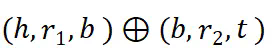 表示两跳推理。
表示两跳推理。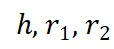 中检索第一跳事实,并将桥接实体
中检索第一跳事实,并将桥接实体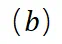 存储在状态
存储在状态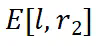 中;上部通过残差连接将的信息传递到输出状态(其中
中;上部通过残差连接将的信息传递到输出状态(其中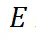 表示对应位置的激活)。由于数据分布可控,l 层可以精确定位(对于 ID 为第 3 层,对于 OOD 为第 5 层)。
表示对应位置的激活)。由于数据分布可控,l 层可以精确定位(对于 ID 为第 3 层,对于 OOD 为第 5 层)。 。该阶段省略了
。该阶段省略了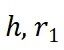 ,并从输入
,并从输入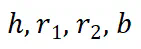 处理第二跳,将尾实体
处理第二跳,将尾实体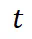 存储到输出状态
存储到输出状态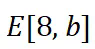 中。
中。
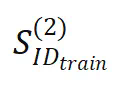 引入噪声(真实训练目标为
引入噪声(真实训练目标为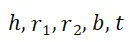 ):
):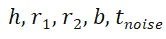 ;
;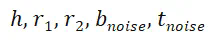 。
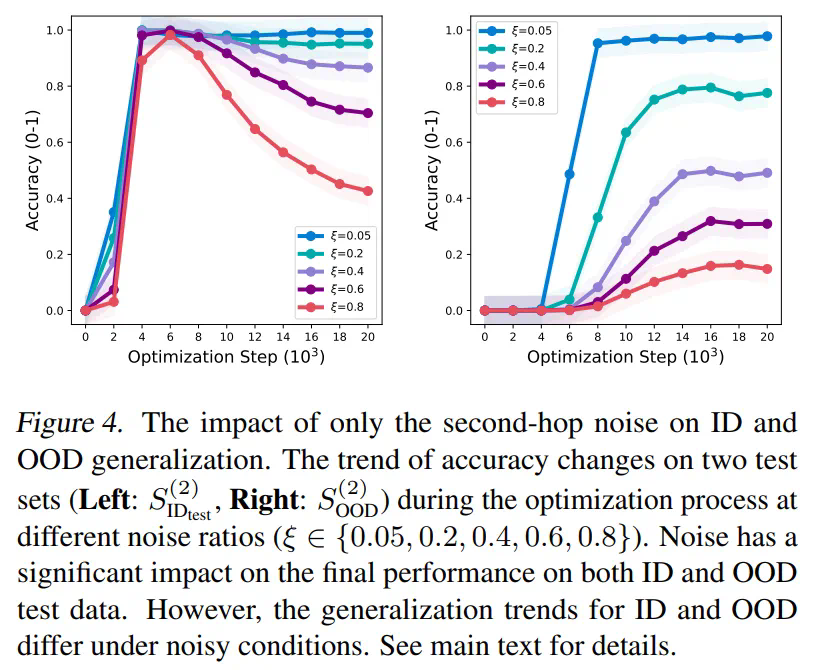
。
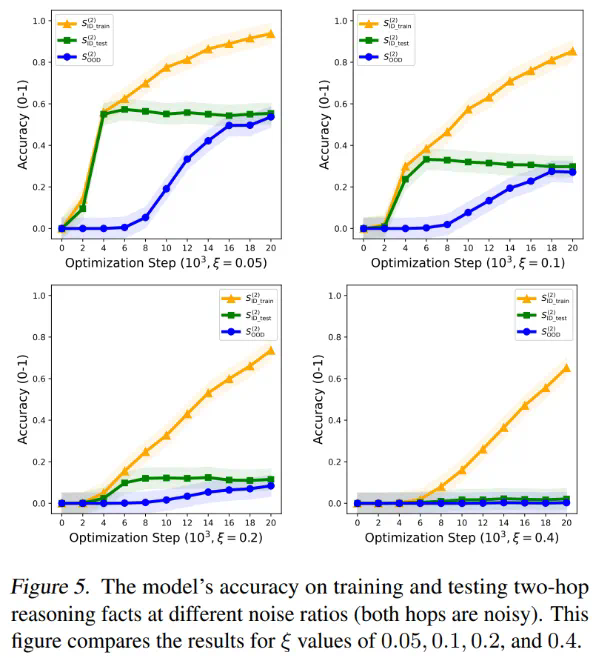

文章来源于互联网:揭示显式CoT训练机制:思维链如何增强推理泛化能力
