文章来源于互联网:可灵视频生成可控性为什么这么好?快手又公开了四篇研究
可灵,视频生成领域的佼佼者,近来动作不断。继发布可灵 1.6 后,又公开了多项研究揭示视频生成的洞察与前沿探索 ——《快手可灵凭什么频繁刷屏?揭秘背后三项重要研究》。可灵近一年来的多次迭代展现出惊人的技术进步,让我们看到了 AI 创作的无限可能,也让我们思考视频生成技术面临的挑战。
视频作为一种时空连续的媒介,对时间维度的连贯性有很高的要求。模型需要确保视频中的每一帧画面都能自然衔接,包括物体运动、光照变化等细节都需要符合现实世界的规律。另一个挑战是用户意图在视频中的精确表达。当创作者想要实现特定的视觉效果时,仅依靠文本描述往往难以准确传达他们的创作意图。这两个挑战直接导致了视频生成的“抽卡率”高,用户难以一次性获得符合预期的生成结果。
针对这些挑战,一个核心解决思路是:通过多模态的用户意图输入来提升视频生成的可控性,从而提升成功率。可灵团队沿着这一思路,在四个控制方向上做了代表性的探索:
-
三维空间控制:之前的视频生成往往局限于单一视角,难以满足复杂叙事需求。为此,团队研究了 SynCamMaster ,实现了高质量的多机位同步视频生成。让创作者能像专业导演一样,通过多角度镜头切换来讲述故事。
-
运动轨迹控制:3DTrajMaster 让创作者能在三维空间中直观地规划和精确地控制物体运动轨迹,让用户轻松实现复杂的动态效果。
-
内容风格控制:StyleMaster 确保了生成视频在保持时间连贯性的同时,能够统一呈现特定的艺术风格,为创作者提供了更丰富的艺术表现手法。
-
交互控制:GameFactory 使用少量 MineCraft 动作数据就能实现交互式游戏体验。结合视频生成的开放域生成,展示了视频生成技术在游戏创作中的广阔应用前景。
这一系列研究成果充分展现了可灵在视频生成领域的系统性探索。通过更好地理解和整合多模态用户意图,降低生成“抽卡率”,可灵正在逐步实现让 AI 视频创作更加精确、可控且易用的目的。

-
论文标题:SynCamMaster: Synchronizing Multi-Camera Video Generation from Diverse Viewpoints -
项目主页:https://jianhongbai.github.io/SynCamMaster -
代码:https://github.com/KwaiVGI/SynCamMaster -
论文:https://arxiv.org/abs/2412.07760




-
相机编码器:将归一化的相机外部参数投影到嵌入空间; -
多视角同步模块:在相机相对位姿的指导下进行多视角特征融合。
-
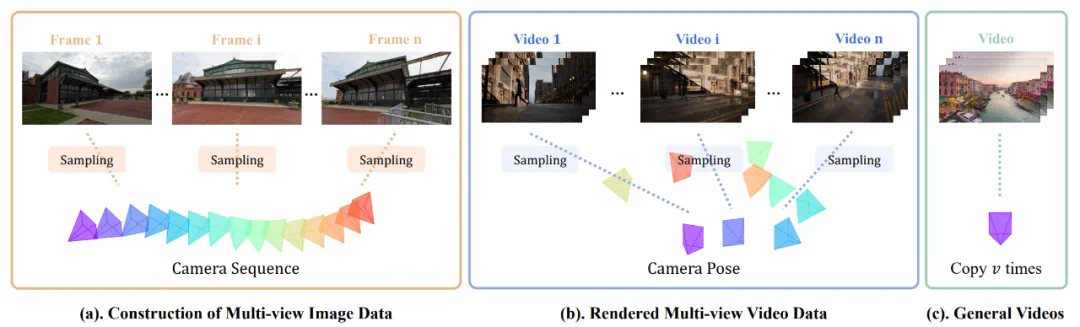
SynCamMaster 率先实现了多机位真实世界视频生成。设计了一种即插即用的 “多视角同步” 模块以实现任意视角下的同步视频生成。 -
提出了一种多种数据混合的训练范式,以克服多机位视频数据的稀缺性并使得模型具备较好的泛化能力。并公开了多视角同步视频数据集 SynCamVideo-Dataset 用于多视角视频生成的研究。



-
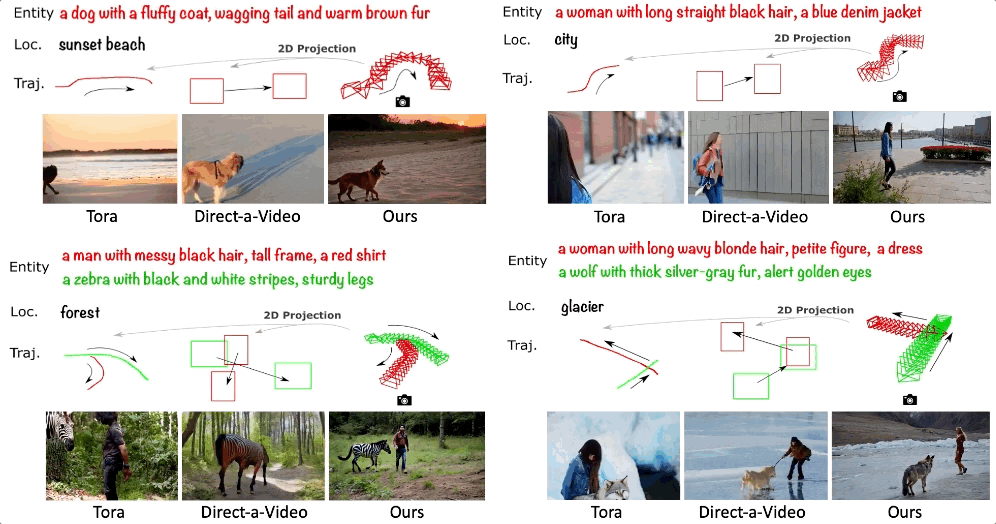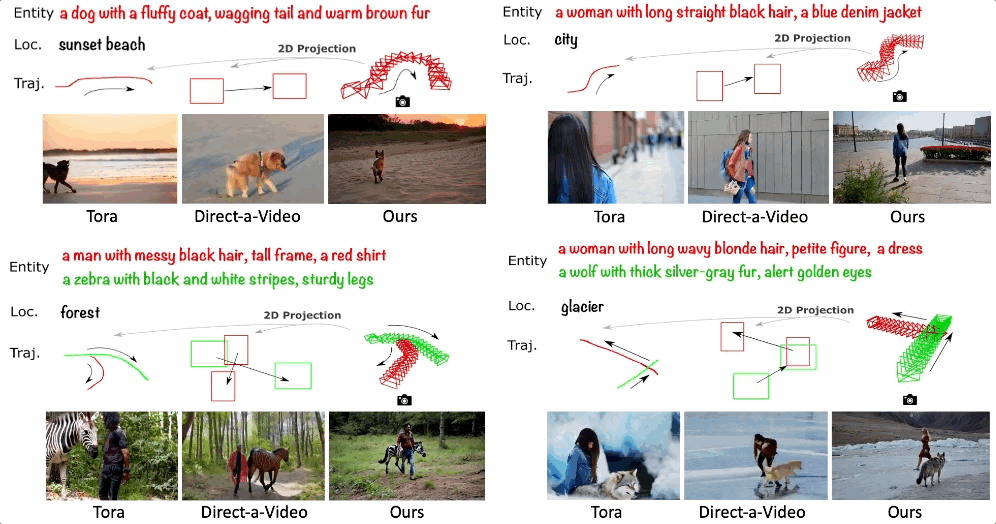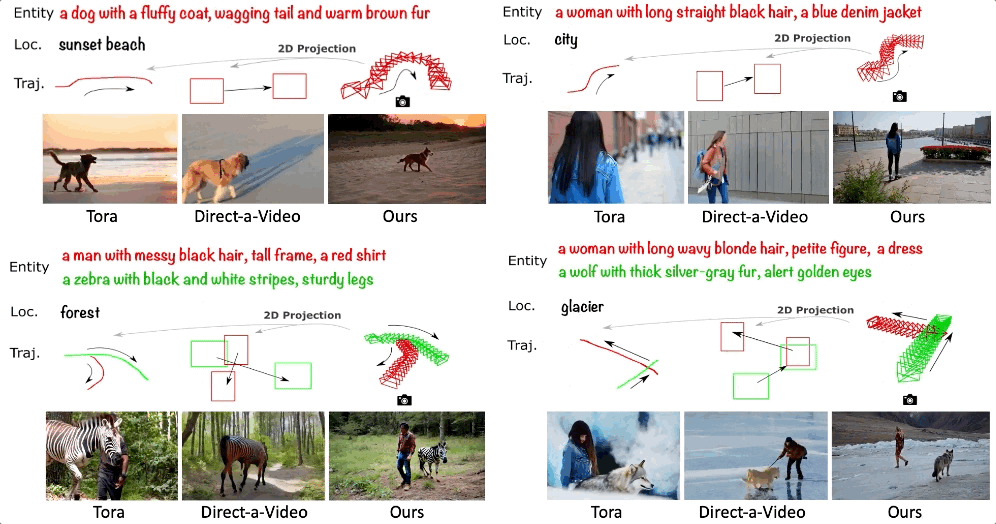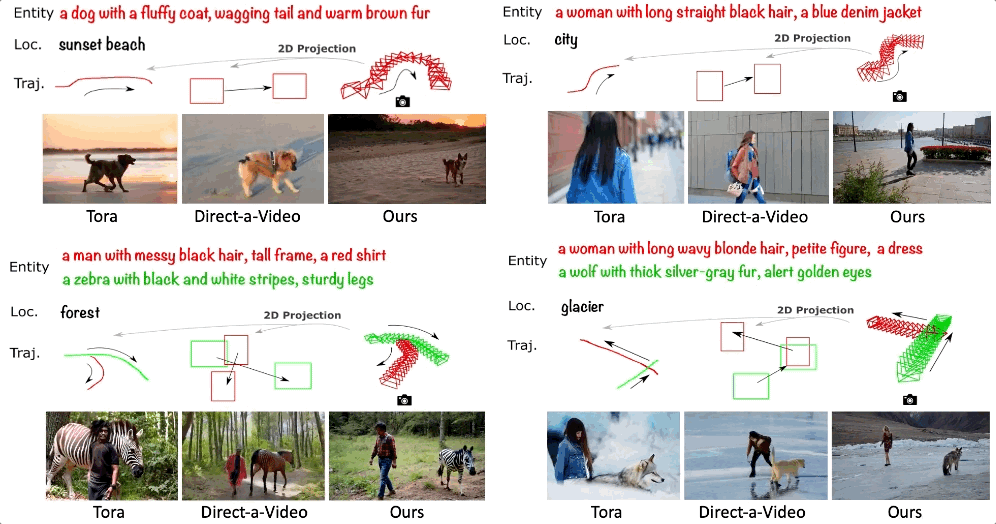
论文标题:3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation -
项目主页:http://fuxiao0719.github.io/projects/3dtrajmaster -
代码:https://github.com/KwaiVGI/3DTrajMaster -
论文:https://arxiv.org/pdf/2412.07759




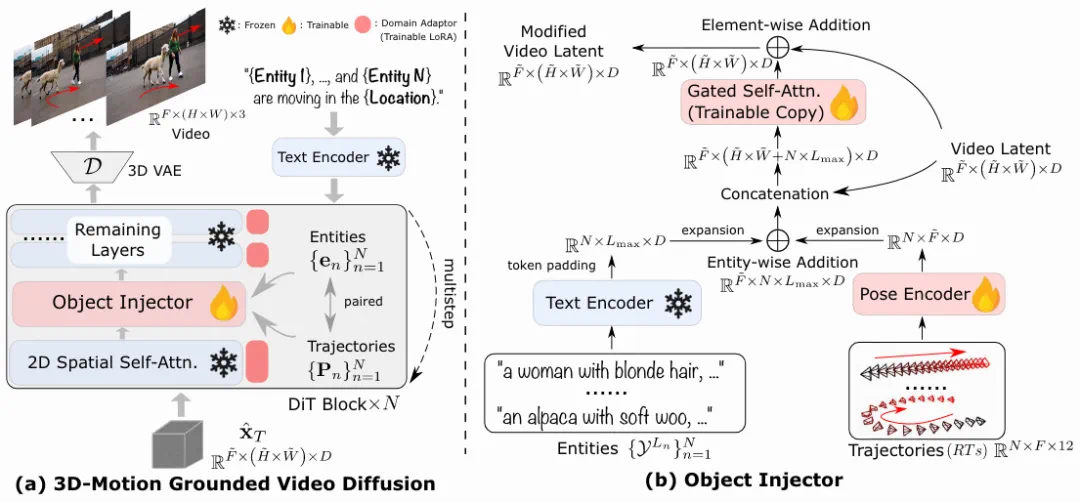

-
较低的物体多样性和质量:高质量并成对的主体和轨迹大多受限于人和自动驾驶车辆,不同数据集在 3D 空间的分布差异非常大,而且主体可能过于冗余。在一些数据集中,人的分布占了大量的比重,会导致域外的主体泛化问题。 -
低质量 / 失败的位姿估计:对于非刚性物体的运动 6D 物体,只有人通过 SMPL 模型被广泛地研究。目前仍然缺乏通用的 6DoF 位姿估计器。


-
论文标题:StyleMaster: Stylize Your Video with Artistic Generation and Translation -
论文链接:https://arxiv.org/abs/2412.07744 -
项目主页:https://zixuan-ye.github.io/stylemaster/ -
代码仓库:https://github.com/KwaiVGI/StyleMaster








-
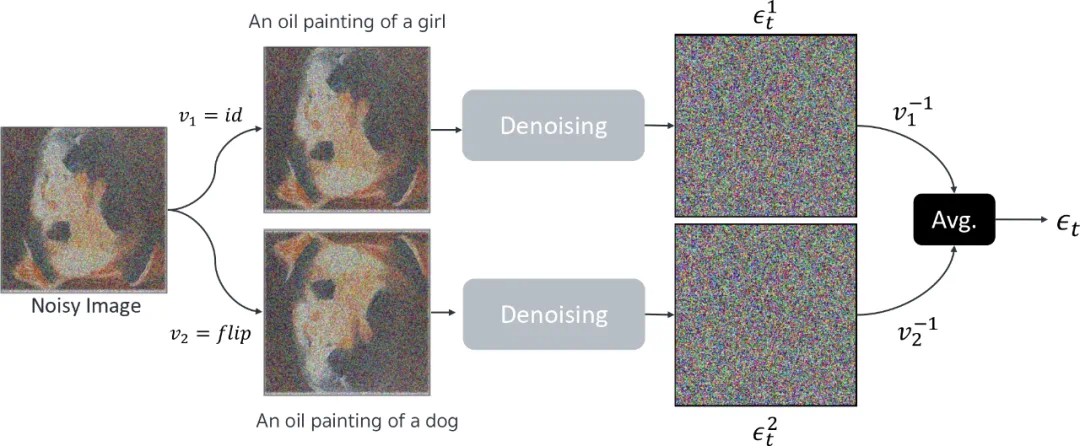
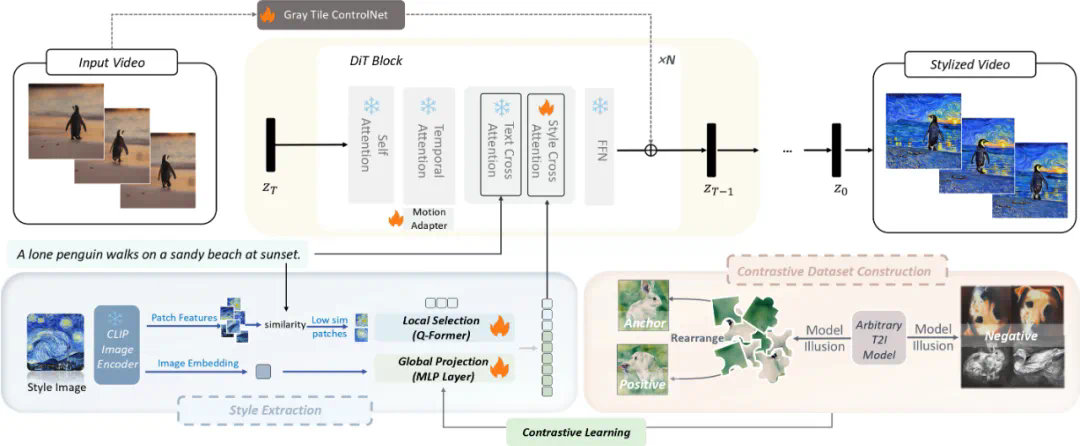
全局风格提取:基于对比学习与幻觉数据集的提取器。使用 CLIP 提取初始图像特征,通过 MLP 投影层转换为全局风格表示。采用三元组损失函数训练,将同对图像作为正样本,其他图像作为负样本。 -
局部纹理保持:提取 CLIP patch 特征,通过计算与文本提示的相似度,选择相似度较低的 patch 作为纹理特征。通过 Q-Former 结构处理,更新查询 token 并整合特征,既保留局部纹理信息,又避免内容泄露。
-
动态质量优化:使用 MotionAdapter 的时序注意力模块,通过调节 α 参数控制动态效果。α=0 保持原始效果,α=1 生成静态视频,α=-1 增强动态范围。 -
精确内容控制:采用 gray tile ControlNet 设计,移除颜色信息避免对风格迁移的干扰。复制一半 vanilla DiT 块作为控制层,与风格 DiT 模块特征相加,确保内容和风格平衡。

-
论文标题:GameFactory: Creating New Games with Generative Interactive Videos -
项目主页:https://vvictoryuki.github.io/gamefactory -
代码:https://github.com/KwaiVGI/GameFactory -
论文:https://arxiv.org/abs/2501.08325 -
GF-Minecraft 训练数据集: https://huggingface.co/datasets/KwaiVGI/GameFactory-Dataset
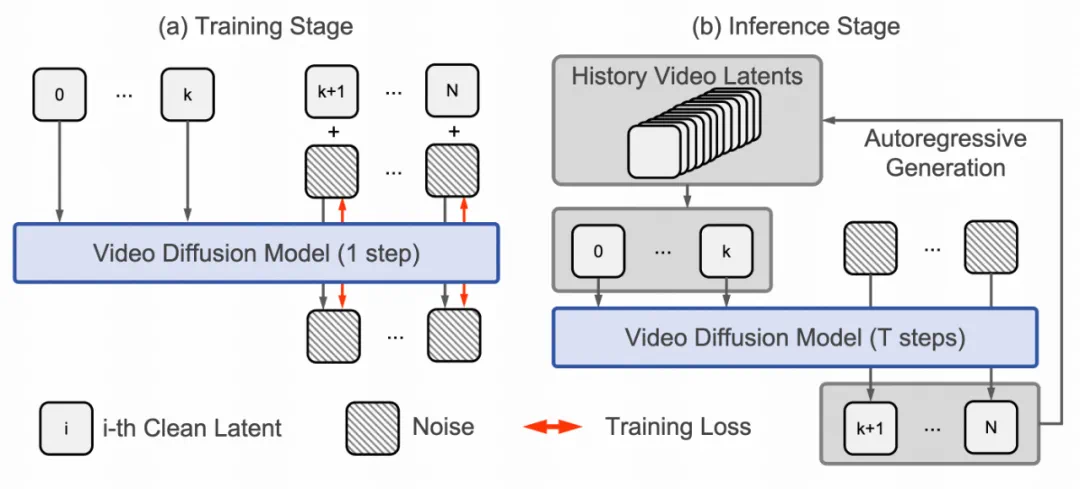
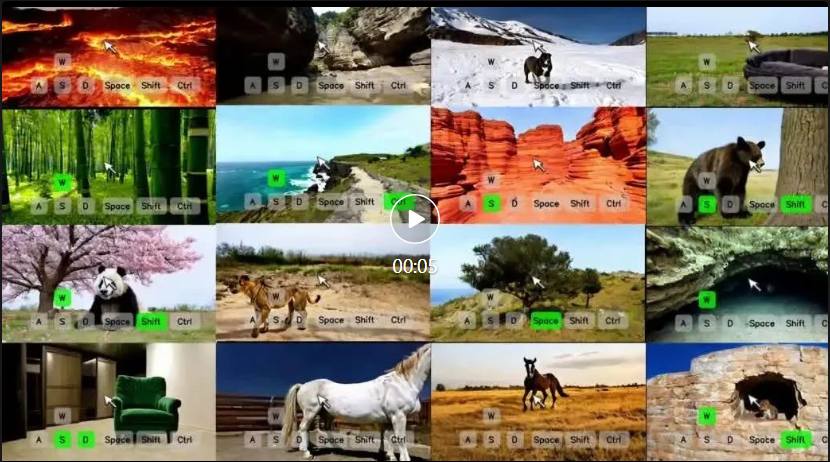 (2)无限长可控游戏视频的生成能力。如下所示,展示了 GameFactory 通过自回归的方式生成几十秒可控游戏长视频的效果。
(2)无限长可控游戏视频的生成能力。如下所示,展示了 GameFactory 通过自回归的方式生成几十秒可控游戏长视频的效果。 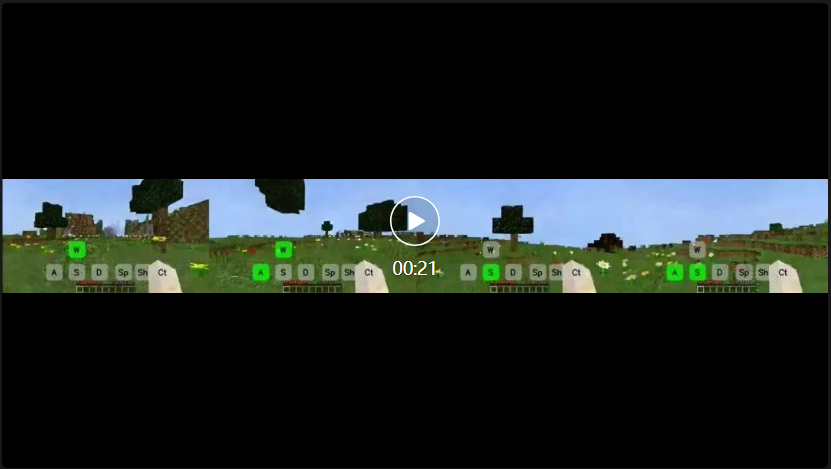
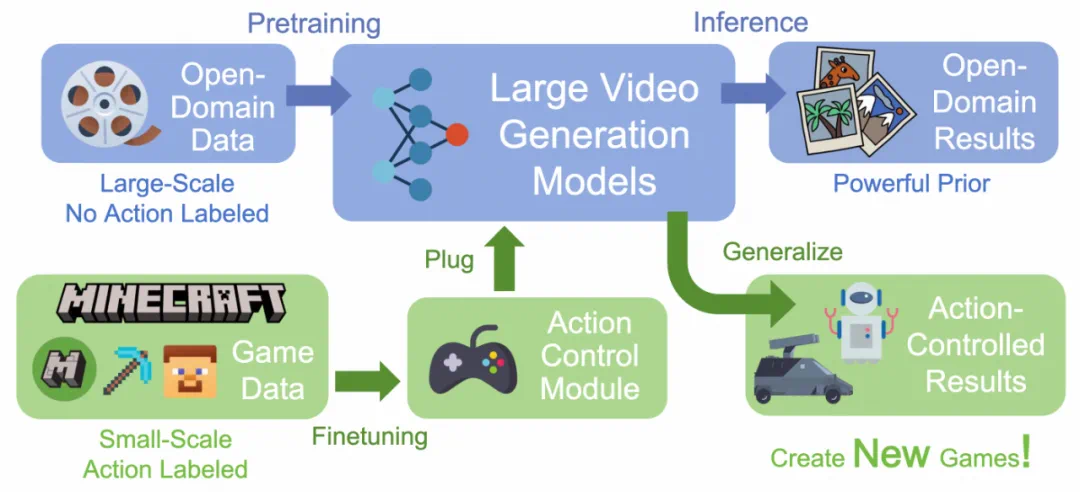
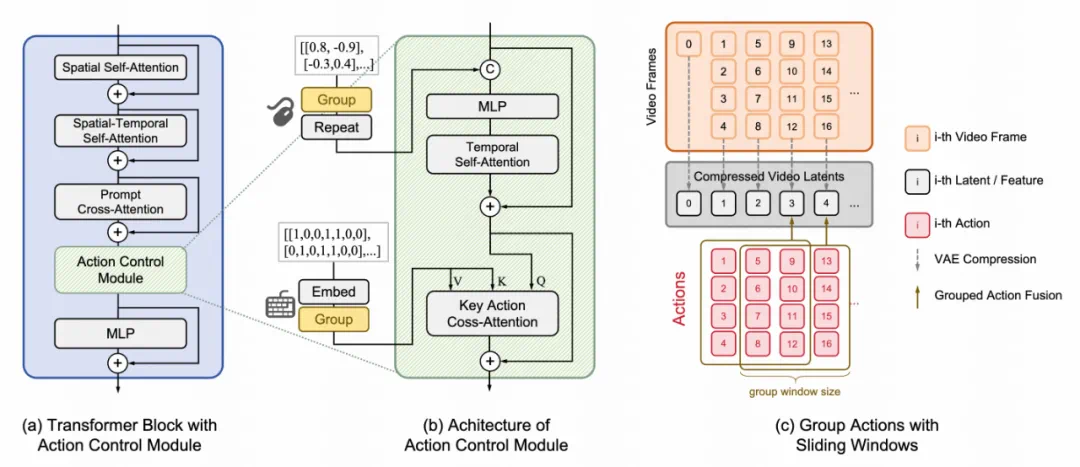
-
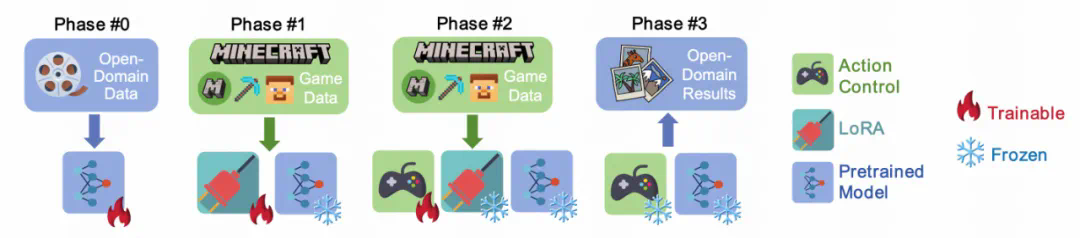
Phase #0 通过在开放领域数据上预训练视频生成模型,为模型提供可泛化的生成能力; -
Phase #1 使用游戏数据进行 LoRA 微调,学习特定的游戏风格; -
Phase #2 在固定模型其他部分的情况下,训练动作控制模块,实现与风格无关的动作响应能力; -
Phase #3 通过推理结合动作控制模块和预训练模型,生成受动作信号控制的开放领域视频内容。

文章来源于互联网:可灵视频生成可控性为什么这么好?快手又公开了四篇研究
