文章来源于互联网:百万tokens仅需8毛,不蒸馏造出世界一流大模型,豆包全新1.5Pro不走捷径
马上就要进入蛇年了,国内的 AI 厂商们却完全没有闲下来的意思,正在春节前扎堆发布各自的新一代大模型。
本周一,豆包刚刚上线了全新的实时语音功能,可说是在中文语音对话方面做到了断崖式领先,为终端用户带来了智商与情商双高的实时语音助手和聊天伙伴。
第二天,月之暗面与 DeepSeek 都各自推出了可比肩满血版 o1 的推理模型,吸引了中外无数眼球。
而再一天后,也就是昨天,豆包大模型又迎来了一次重大的版本更新:豆包大模型 1.5Pro 版本。看完该版本模型的更新详情与技术博客后,我们的第一感觉是:开发者有福了!

-
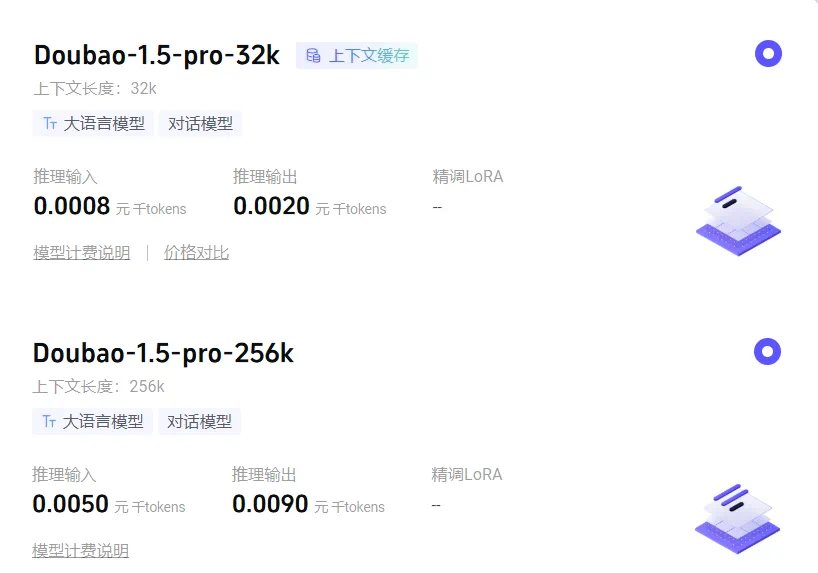
火山引擎产品页面(也可免费体验):https://www.volcengine.com/product/doubao -
技术博客地址:https://team.doubao.com/zh/special/doubao_1_5_pro
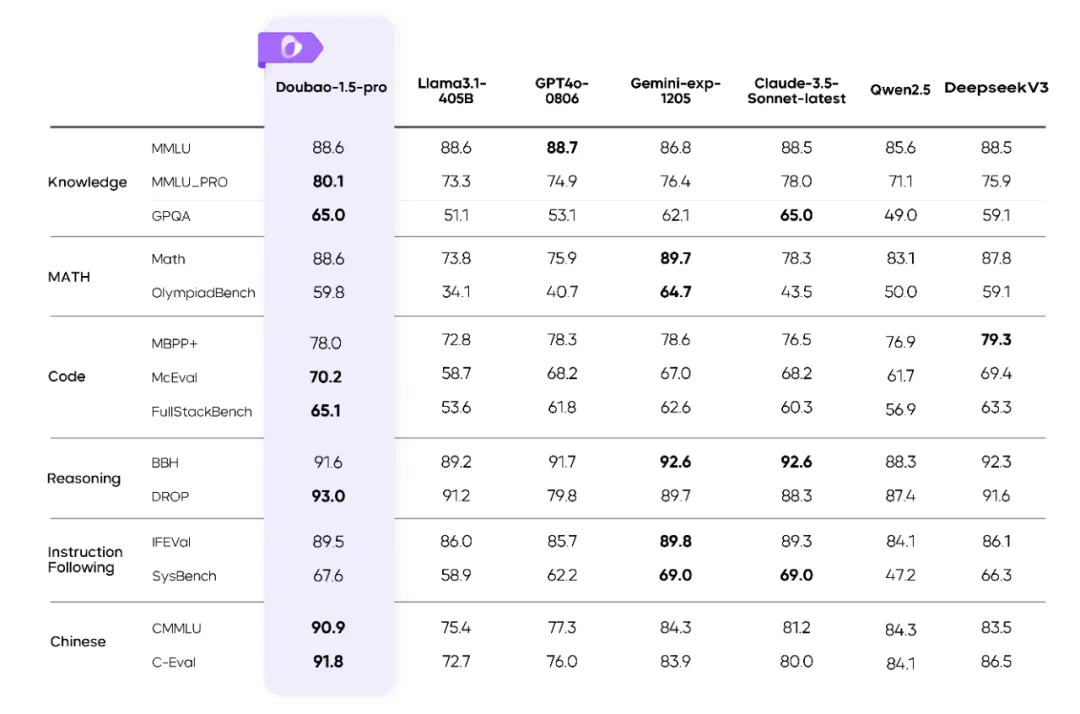
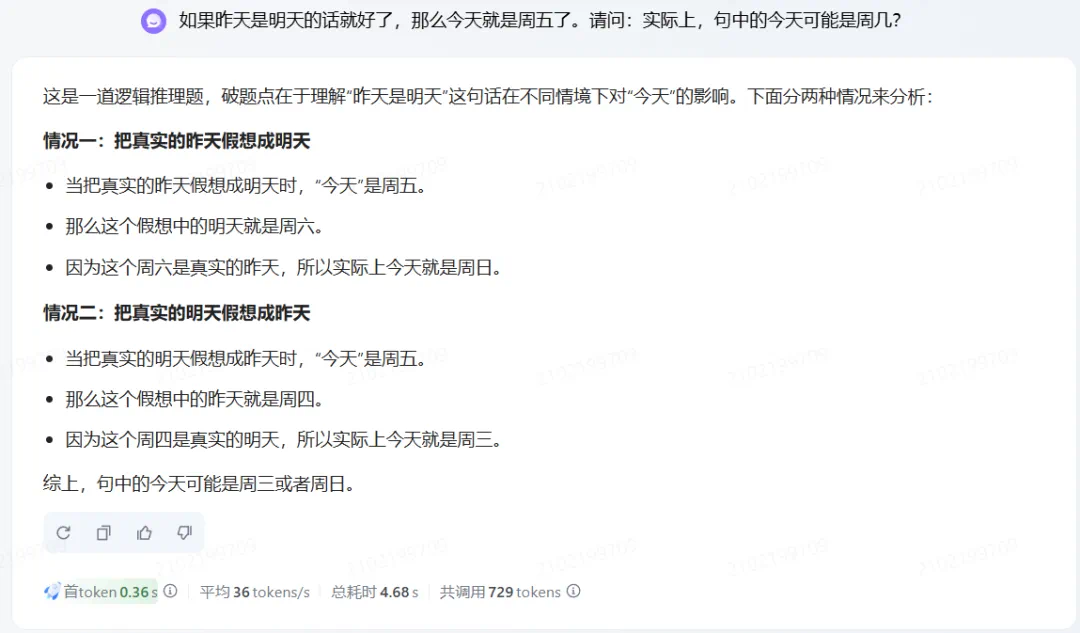
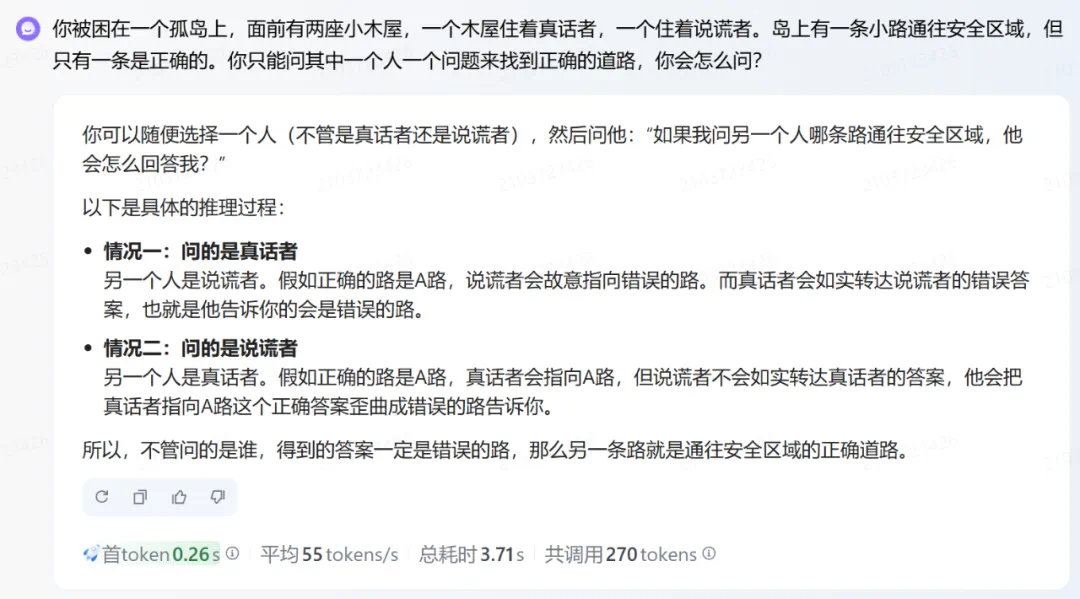
轻松拿捏推理 & 全模态任务

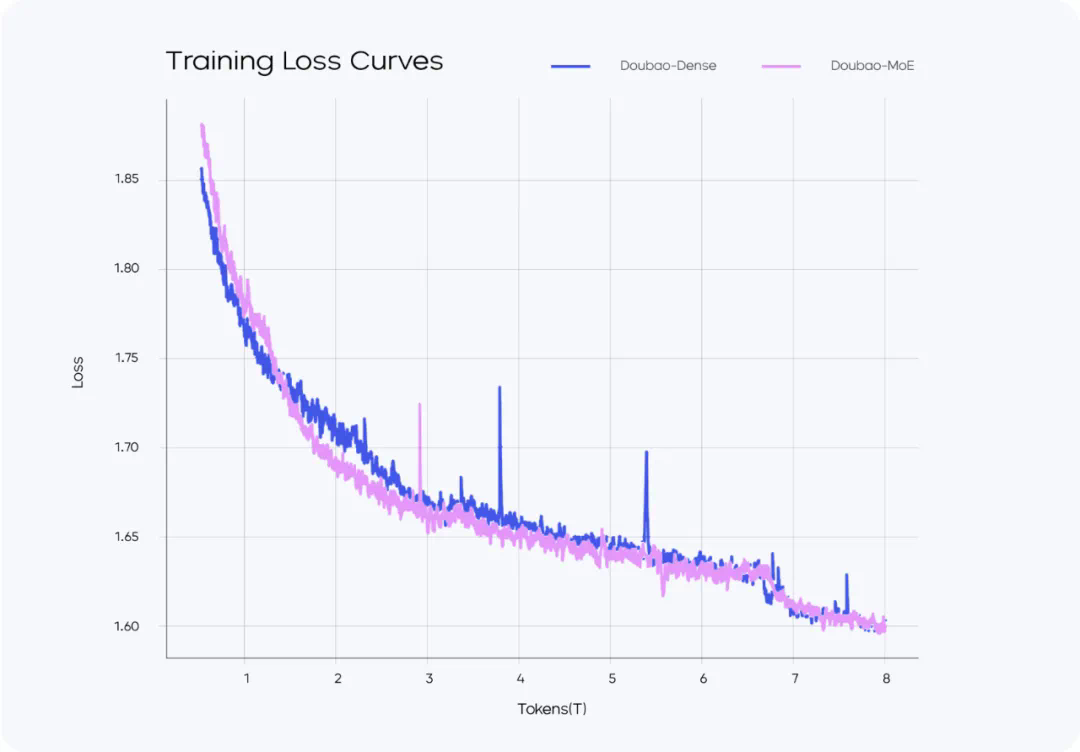
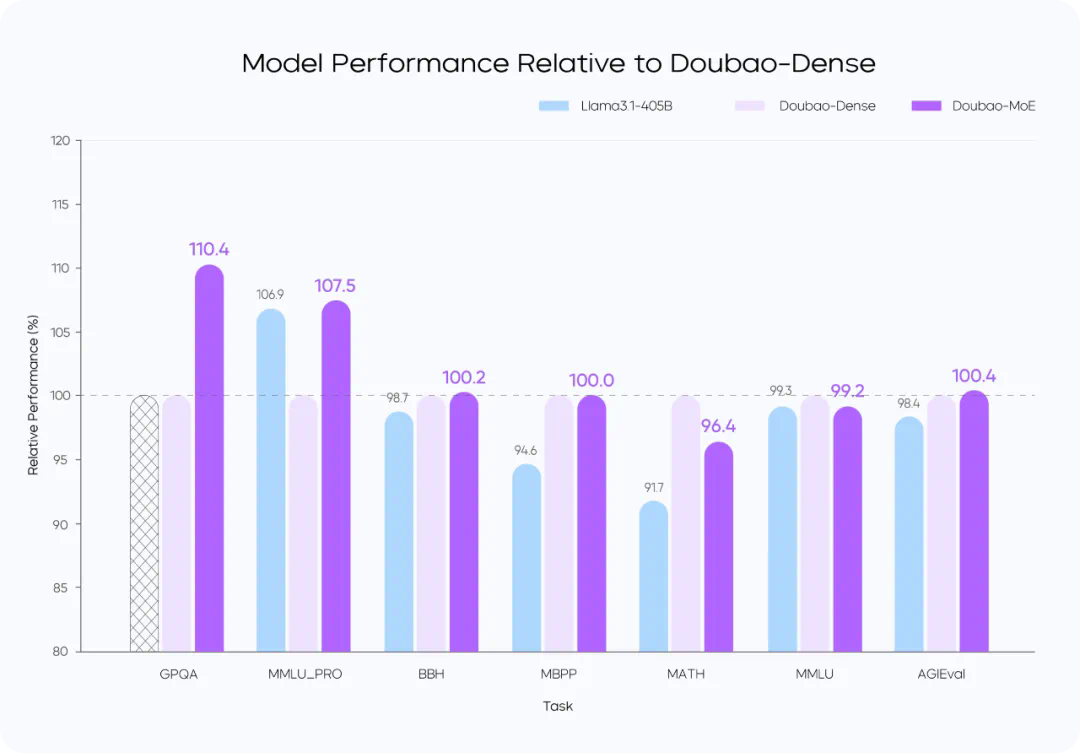
从 MoE 到高效后训练

-
在 SFT 阶段,利用算法驱动的训练数据优化系统来提升训练数据多样化,利用模型自演进技术来提升数据标注的多样性和难度,双管齐下,形成性能提升的良性循环。 -
在 Reward Model 阶段,建立起涵盖提示词分布优化、响应筛选、多轮迭代和主动学习的完整数据生产管道,并基于此实现了 Verifier 和 Reward Model 的深度融合,均衡提升了模型在数学、编程、知识和对话等多领域的能力。 -
在 RL 阶段,攻克价值函数训练难点,实现 token-wise 稳定建模,高难度任务的性能提升了 10 个绝对点。利用对比学习方法,有效提升 LLM 的表现并显著缓解 Reward hacking 问题。最终在数据、算法、模型层面全面实现 Scaling,实现算力到智力的有效转换。


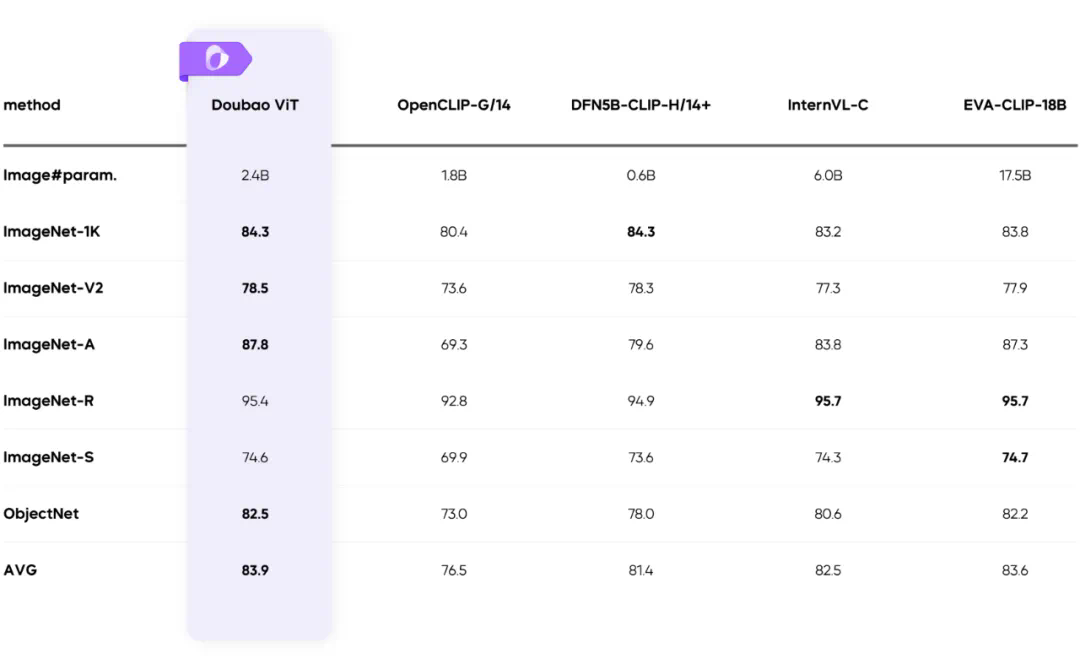
不忘探索技术前沿



