文章来源于互联网:阿里云通义大模型新技术:MoE模型训练专家平衡的关键细节

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本周,在阿里云通义千问 Qwen 团队提交的一篇论文中,研究人员发现了目前最热门的 MoE(混合专家模型)训练中存在的一个普遍关键问题,并提出一种全新的方法——通过轻量的通信将局部均衡放松为全局均衡,使得 MoE 模型的性能和专家特异性都得到了显著的提升。

-
论文:《Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models》
-
论文链接:https://arxiv.org/abs/2501.11873
背景

负载均衡损失
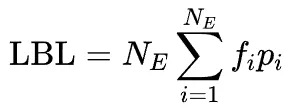
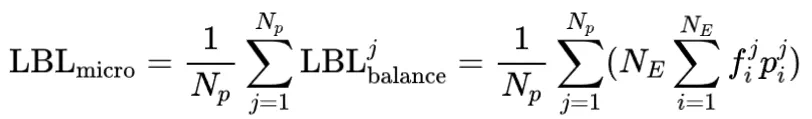
从局部均衡到全局均衡
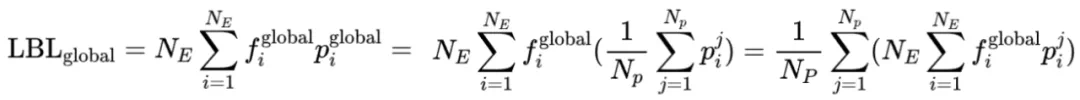
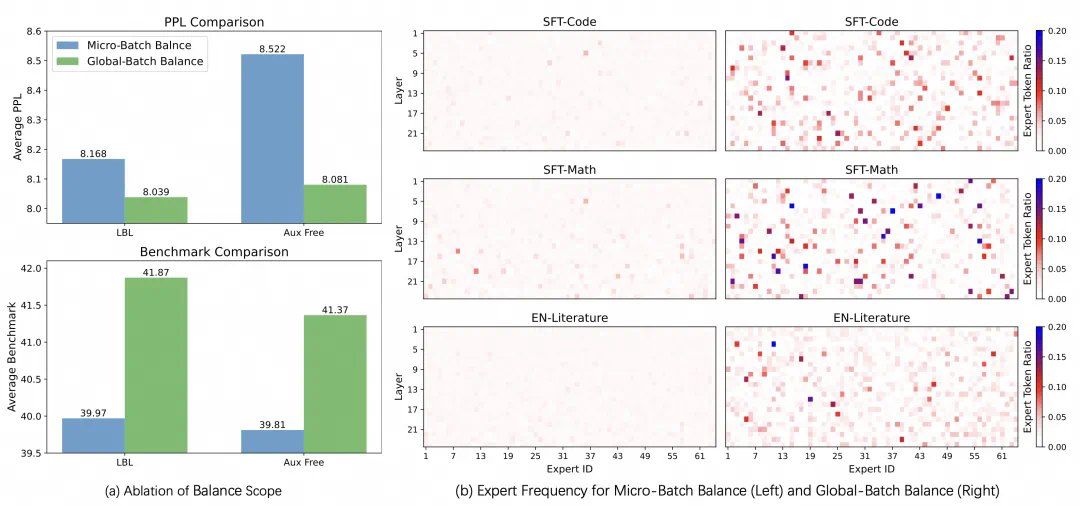
扩大均衡的范围带来稳定的提升
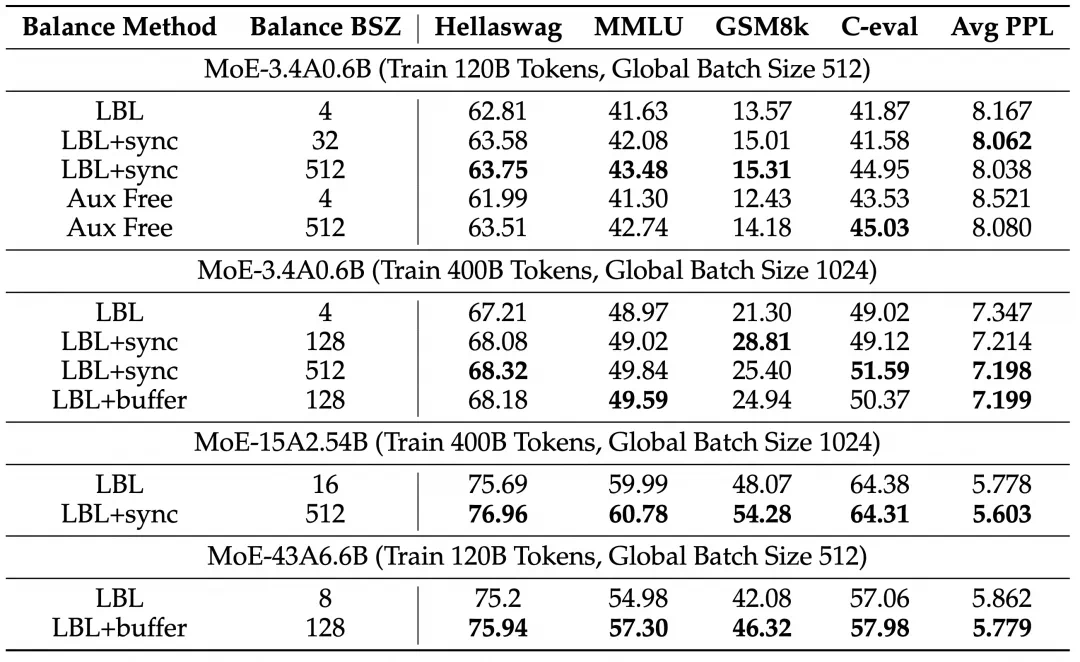
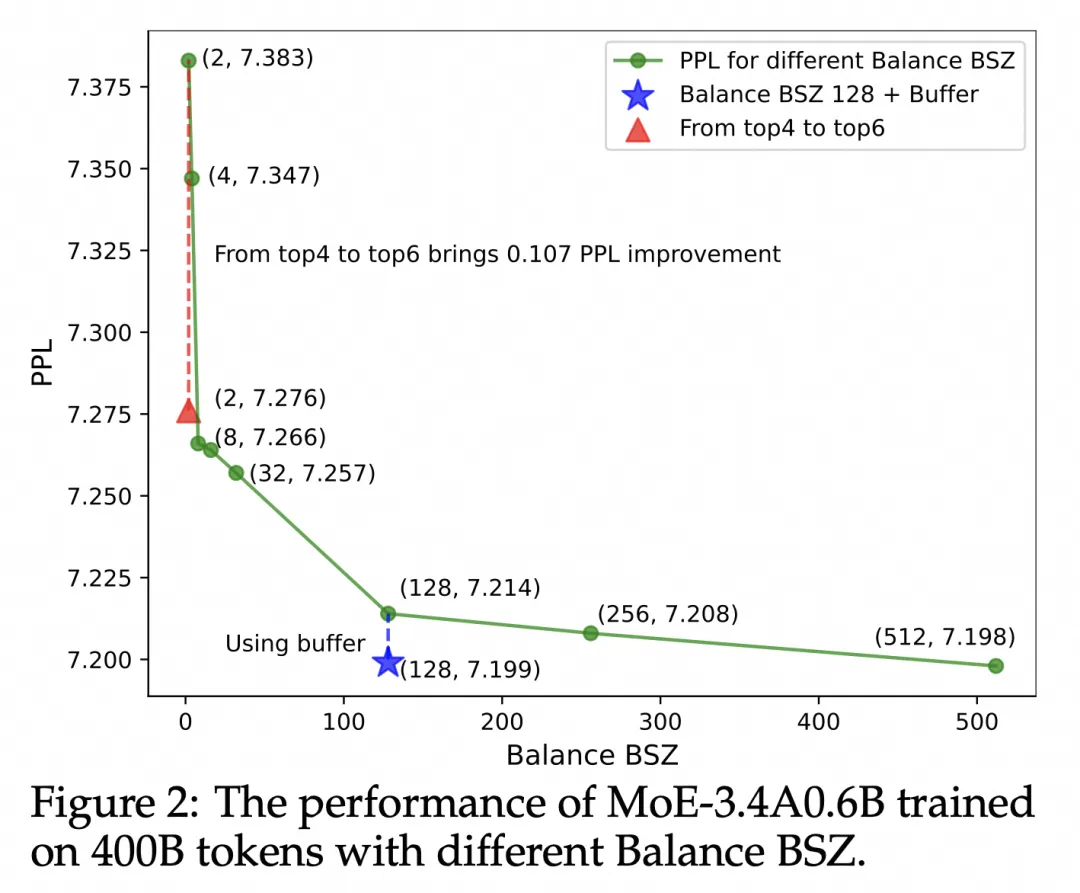
分析实验
假设验证
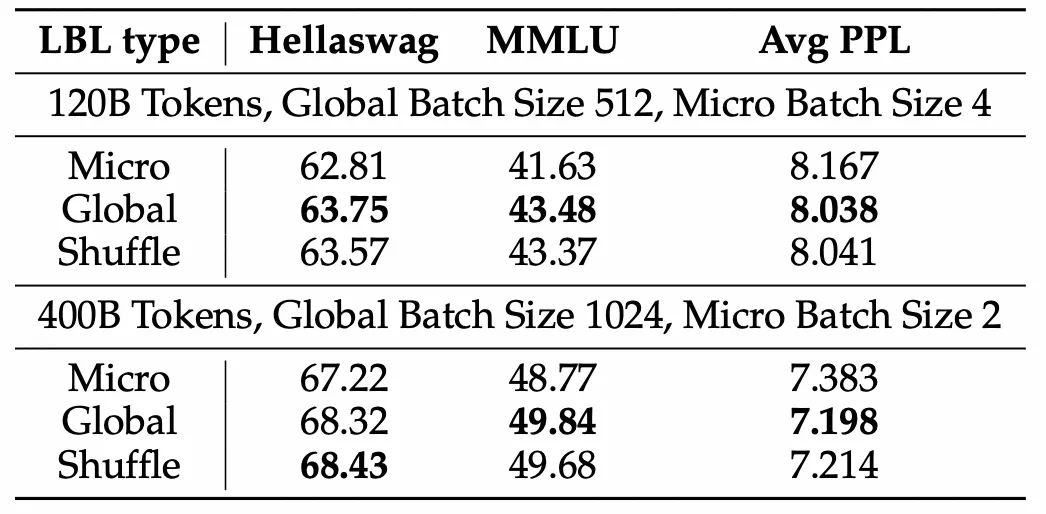
添加少量局部均衡损失
能提高模型效率
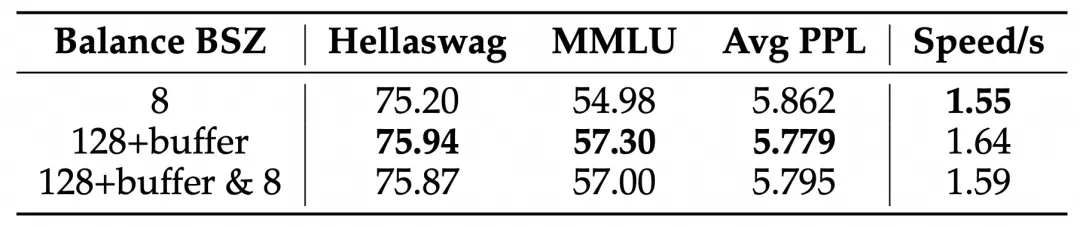
同期相关工作以及讨论
结论
文章来源于互联网:阿里云通义大模型新技术:MoE模型训练专家平衡的关键细节
