文章来源于互联网:北航推出TinyLLaVA-Video,有限计算资源优于部分7B模型,代码、模型、训练数据全开源

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
近年来,随着多模态大模型的崛起,视频理解技术取得了显著进展。但是目前主流的全开源视频理解多模态模型普遍具有 7B 以上的参数量,这些模型往往采用复杂的架构设计,并依赖于大规模训练数据集。受限于高昂的计算资源成本,模型训练与定制化开发对于资源有限的科研人员而言仍存在显著的门槛。
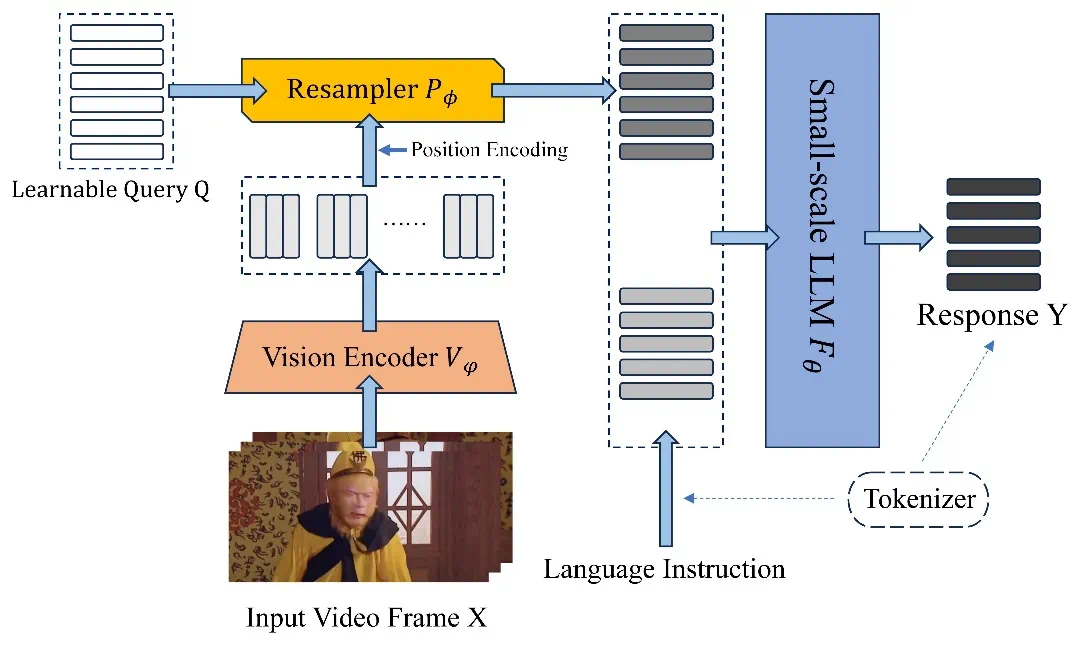
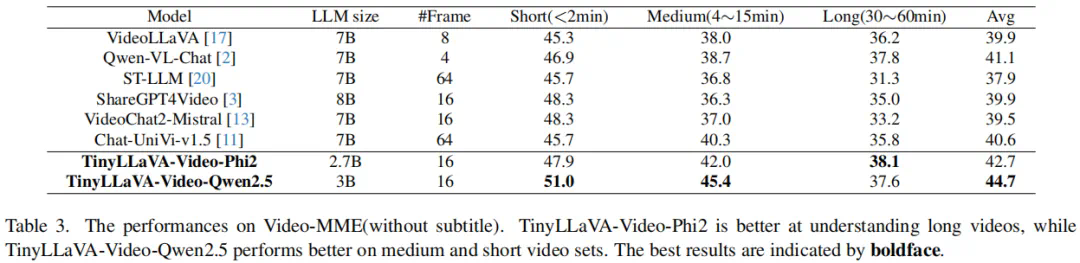
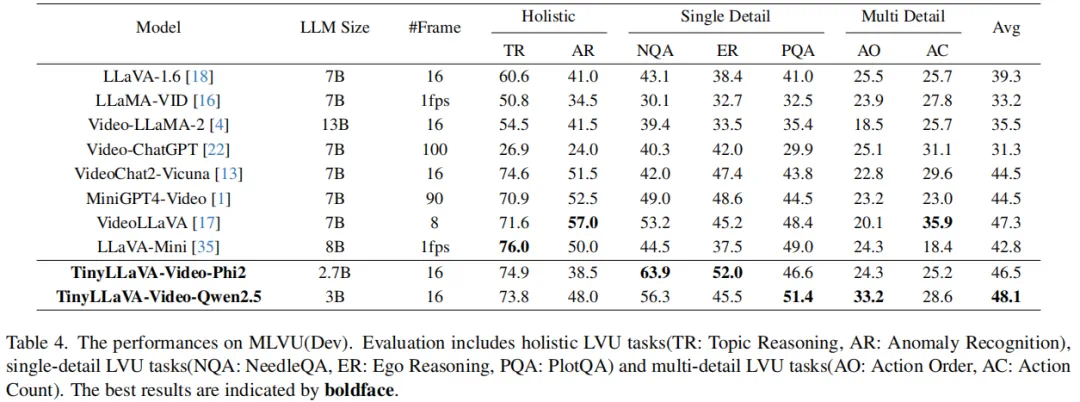
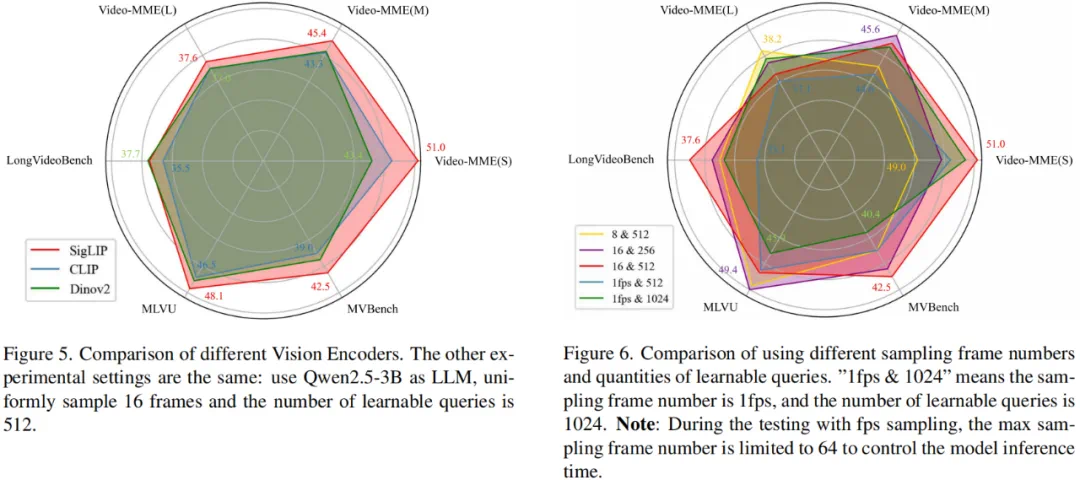
近日,北京航空航天大学的研究团队基于 TinyLLaVA_Factory 的原项目,推出小尺寸简易视频理解框架 TinyLLaVA-Video,其模型,代码以及训练数据全部开源。在计算资源需求显著降低的前提下,训练出的整体参数量不超过 4B 的模型在多个视频理解 benchmark 上优于现有的 7B + 模型。同时,由于 TinyLLaVA-Video 衍生自 Tinyllava_Factory 代码库,因此项目仍然具有组件化与可扩展性等优点,使用者可以根据自身需求进行定制与拓展研究。

-
论文地址:https://arxiv.org/abs/2501.15513 -
Github 项目:https://github.com/ZhangXJ199/TinyLLaVA-Video