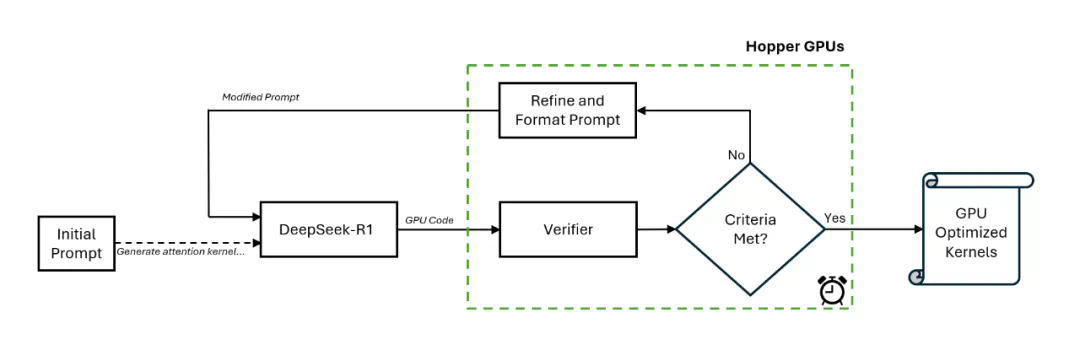
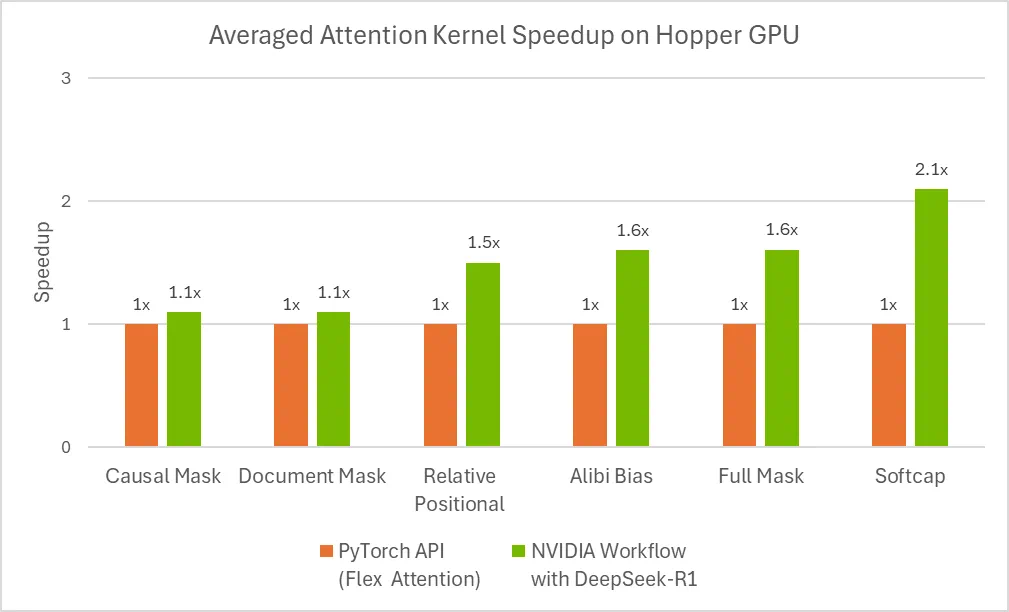
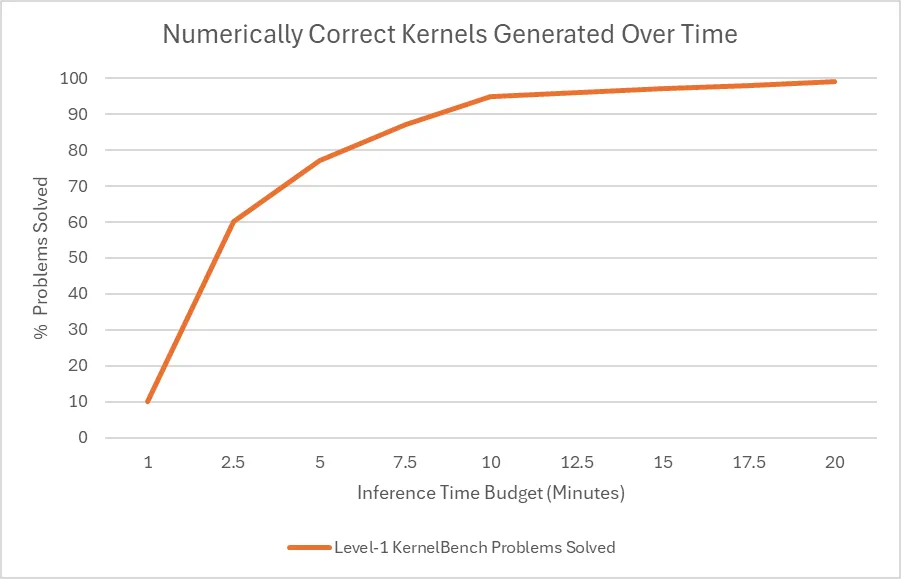
文章来源于互联网:DeepSeek R1不编程就能生成GPU内核,比熟练工程师好,惊到了英伟达
这项尝试只用到了 R1 模型和基本验证器,没有针对 R1 的工具,没有对专有的英伟达代码进行微调。其实根据 DeepSeek 介绍,R1 的编码能力不算顶尖。



Please write a GPU attention kernel to support relative position encodings. Implement the relative positional encoding on the fly within the kernel. The complete code should be returned, including the necessary modifications.Use the following function to compute the relative positional encoding:def relative_positional(score, b, h, q_idx, kv_idx):return score + (q_idx - kv_idx)When implementing the kernel, keep in mind that a constant scaling factor 1.44269504 should be applied to the relative positional encoding due to qk_scale = sm_scale * 1.44269504. The PyTorch reference does not need to scale the relative positional encoding, but in the GPU kernel, use:qk = qk * qk_scale + rel_pos * 1.44269504Please provide the complete updated kernel code that incorporates these changes, ensuring that the relative positional encoding is applied efficiently within the kernel operations.