文章来源于互联网:最强全模态模型Ola-7B横扫图像、视频、音频主流榜单,腾讯混元Research&清华&NTU联手打造

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
Ola 是腾讯混元 Research、清华大学智能视觉实验室(i-Vision Group)和南洋理工大学 S-Lab 的合作项目。本文的共同第一作者为清华大学自动化系博士生刘祖炎和南洋理工大学博士生董宇昊,本文的通讯作者为腾讯高级研究员饶永铭和清华大学自动化系鲁继文教授。
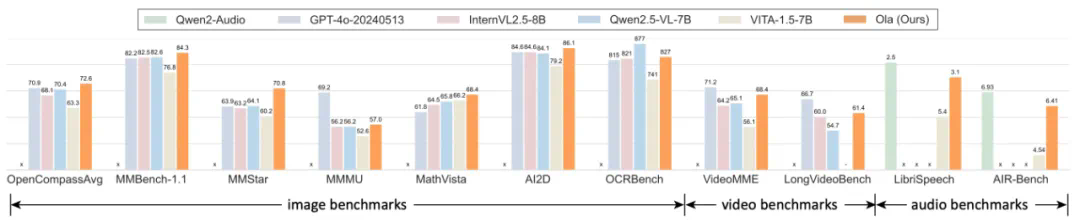
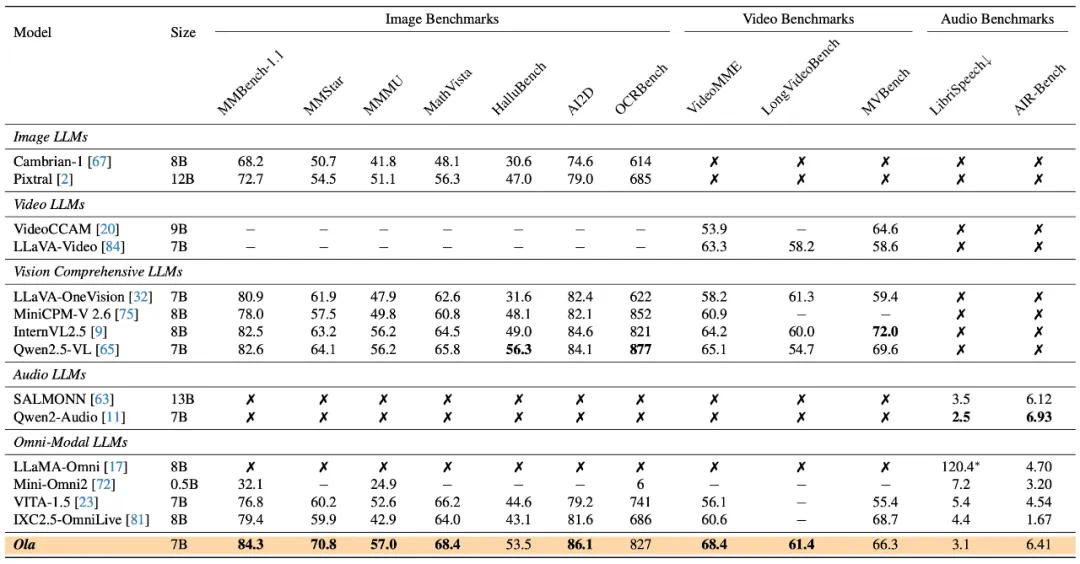
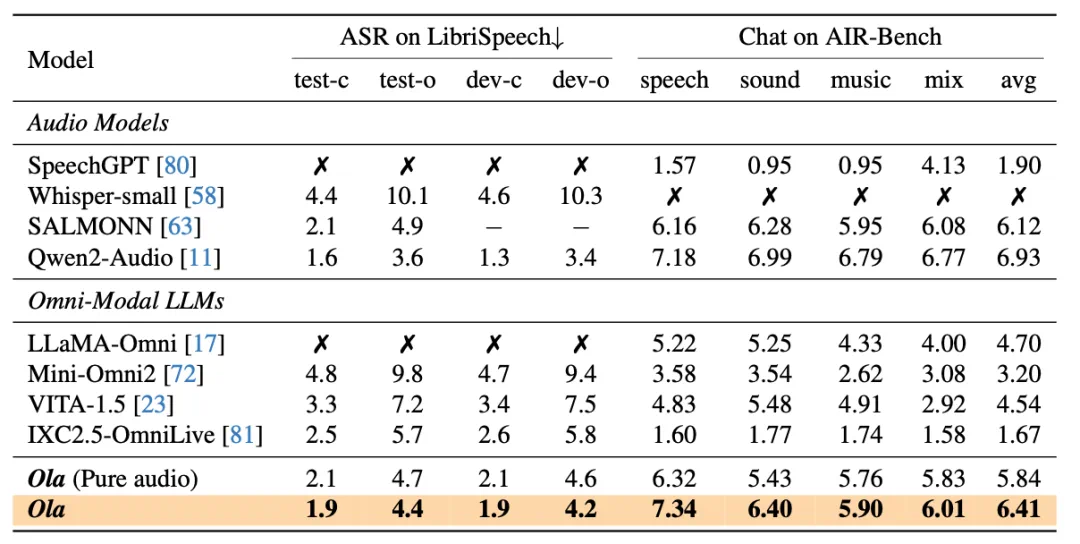
GPT-4o 的问世引发了研究者们对实现全模态模型的浓厚兴趣。尽管目前已经出现了一些开源替代方案,但在性能方面,它们与专门的单模态模型相比仍存在明显差距。在本文中,我们提出了 Ola 模型,这是一款全模态语言模型,与同类的专门模型相比,它在图像、视频和音频理解等多个方面都展现出了颇具竞争力的性能。
Ola 的核心设计在于其渐进式模态对齐策略,该策略逐步扩展语言模型所支持的模态。我们的训练流程从差异最为显著的模态开始:图像和文本,随后借助连接语言与音频知识的语音数据,以及连接所有模态的视频数据,逐步拓展模型的技能集。这种渐进式学习流程还使我们能够将跨模态对齐数据维持在相对较小的规模,从而让基于现有视觉 – 语言模型开发全模态模型变得更为轻松且成本更低。

-
项目地址:https://ola-omni.github.io/ -
论文:https://arxiv.org/abs/2502.04328 -
代码:https://github.com/Ola-Omni/Ola -
模型:https://huggingface.co/THUdyh/Ola-7b
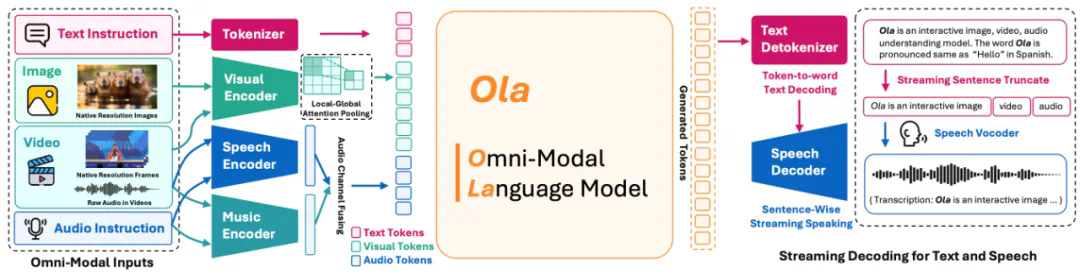
-
Ola 架构支持全模态输入以及流式文本和语音生成,其架构设计可扩展且简洁。我们为视觉和音频设计了联合对齐模块,通过局部 – 全局注意力池化层融合视觉输入,并实现视觉、音频和文本标记的自由组合。此外,我们集成了逐句流式解码模块以实现高质量语音合成。 -
除了在视觉和音频方面收集的微调数据外,我们深入挖掘视频与其对应音频之间的关系,以构建视觉与音频模态之间的桥梁。具体而言,我们从学术及开放式网络资源收集原始视频,设计独立的清理流程,然后利用视觉 – 语言模型根据字幕和视频内容生成问答对。
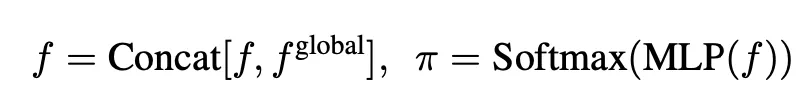
-
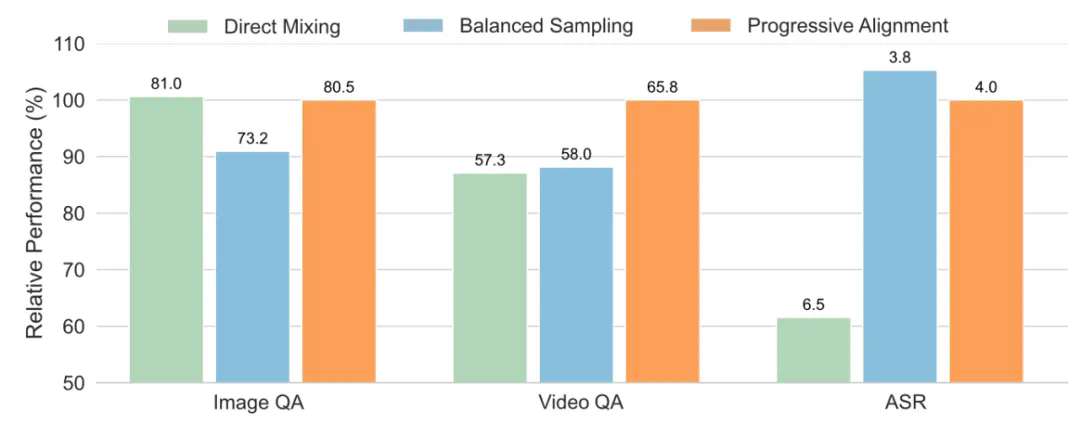
模态平衡:直接合并来自所有模态的数据会对基准性能产生负面影响。我们认为,文本和图像是全模态学习中的核心模态,而语音和视频分别是文本和图像的变体。学会识别文本和图像可确保模型具备基本的跨模态能力,所以我们优先处理这些较难的情况。随后,我们逐步将视频、音频和语音纳入全模态大语言模型的训练中。 -
音频与视觉之间的联系:在全模态学习中,联合学习音频和视觉数据能够通过提供跨不同模态的更全面视角,产生令人惊喜的结果。对于 Ola 模型,我们将视频视为音频与视觉之间的桥梁,因为视频在帧与伴随音频之间包含自然、丰富且高度相关的信息。我们通过优化训练流程和准备有针对性的训练数据来验证这一假设。


文章来源于互联网:最强全模态模型Ola-7B横扫图像、视频、音频主流榜单,腾讯混元Research&清华&NTU联手打造
