文章来源于互联网:仅靠逻辑题,AI数学竞赛能力飙升!微软、九坤投资:7B小模型也能逼近o3-mini

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文由微软亚洲研究院的谢天、洪毓谦、邱凯、武智融、罗翀,九坤投资高梓添、Bryan Dai、Joey Zhou,以及独立研究员任庆楠、罗浩铭合著完成。

-
论文标题:Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
-
论文链接:https://arxiv.org/abs/2502.14768
-
Github 链接:https://github.com/Unakar/Logic-RL

示例问题:一个非常特殊的岛屿上只住着骑士和骗子。骑士总是说真话,骗子总是说谎。你遇到两位岛民:Zoey 和 Oliver。Zoey 说:「Oliver 不是骑士。」Oliver 说:「Oliver 是骑士且 Zoey 是骗子。」请问,谁是骑士,谁是骗子?
-
跳过 过程并直接回答。
-
将推理过程放在 标签内。
-
反复猜测答案而没有适当的推理。
-
在提供答案之外包含无关的废话。
-
在已经输出一个 后再次进入思考阶段,因为推理不足。
-
重复原始问题或使用诸如 “在此处进行思考过程” 之类的短语来避免真正的推理。
-
格式奖励:按格式正确与否给 + 1 或 – 1 的奖励。
-
答案奖励:答案无法被提取,奖励为 – 2;答案部分错误时,奖励为 – 1.5,答案正确时,奖励为 + 2。
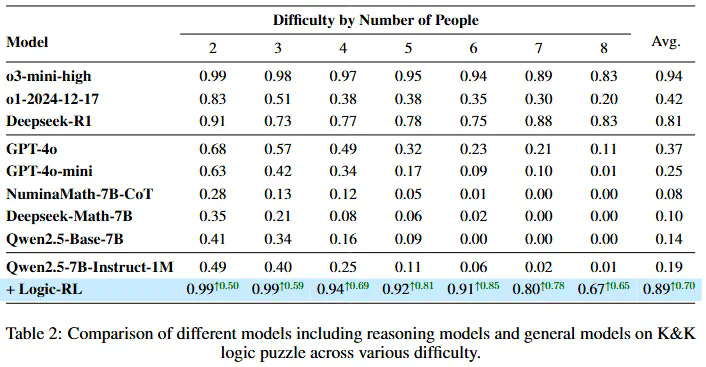
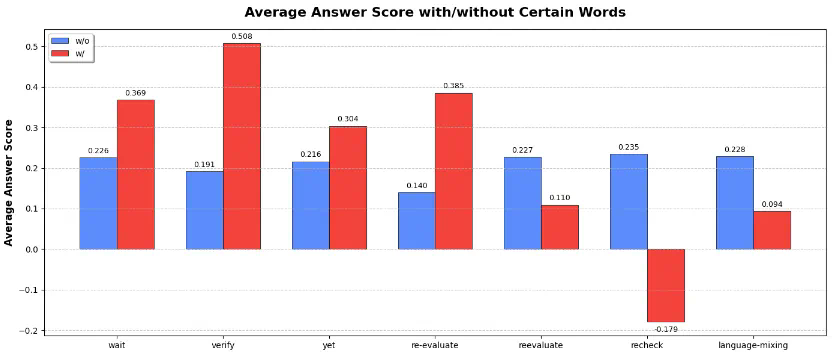

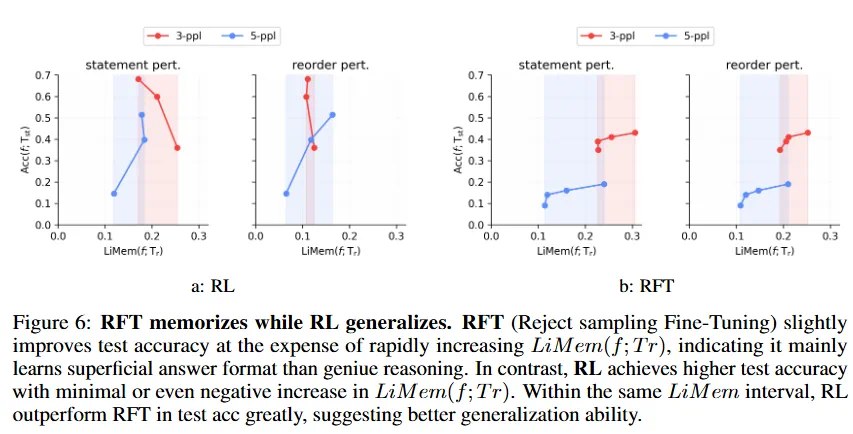

-
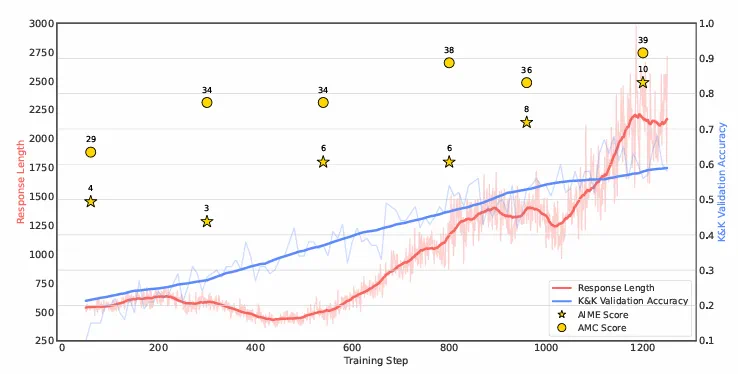
冷启动自有其好处,但非必需。无论是从 Base 模型还是 Instruct 模型开始,训练动态都保持惊人的相似性。不过 SFT 后的模型往往拥有略高的准确率。
-
对难度递进的课程学习仍然重要。在固定的数据混合比例下,精心设计的课程学习方法总是优于随机打乱。
