文章来源于互联网:字节首次公开图像生成基模技术细节!数据处理到RLHF全流程披露

-
论文标题:Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
-
论文地址:https://arxiv.org/pdf/2503.07703
-
技术展示页:https://team.doubao.com/tech/seedream
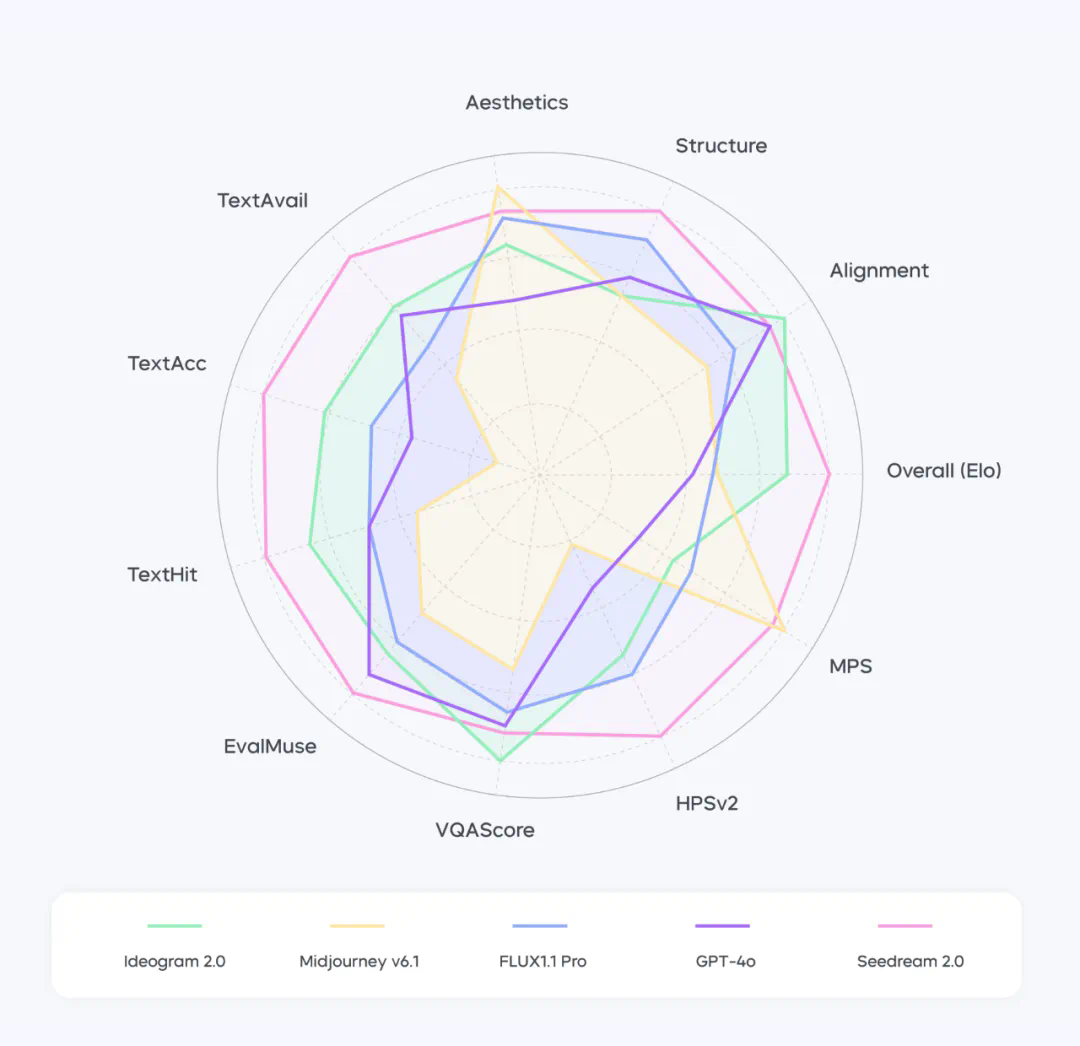
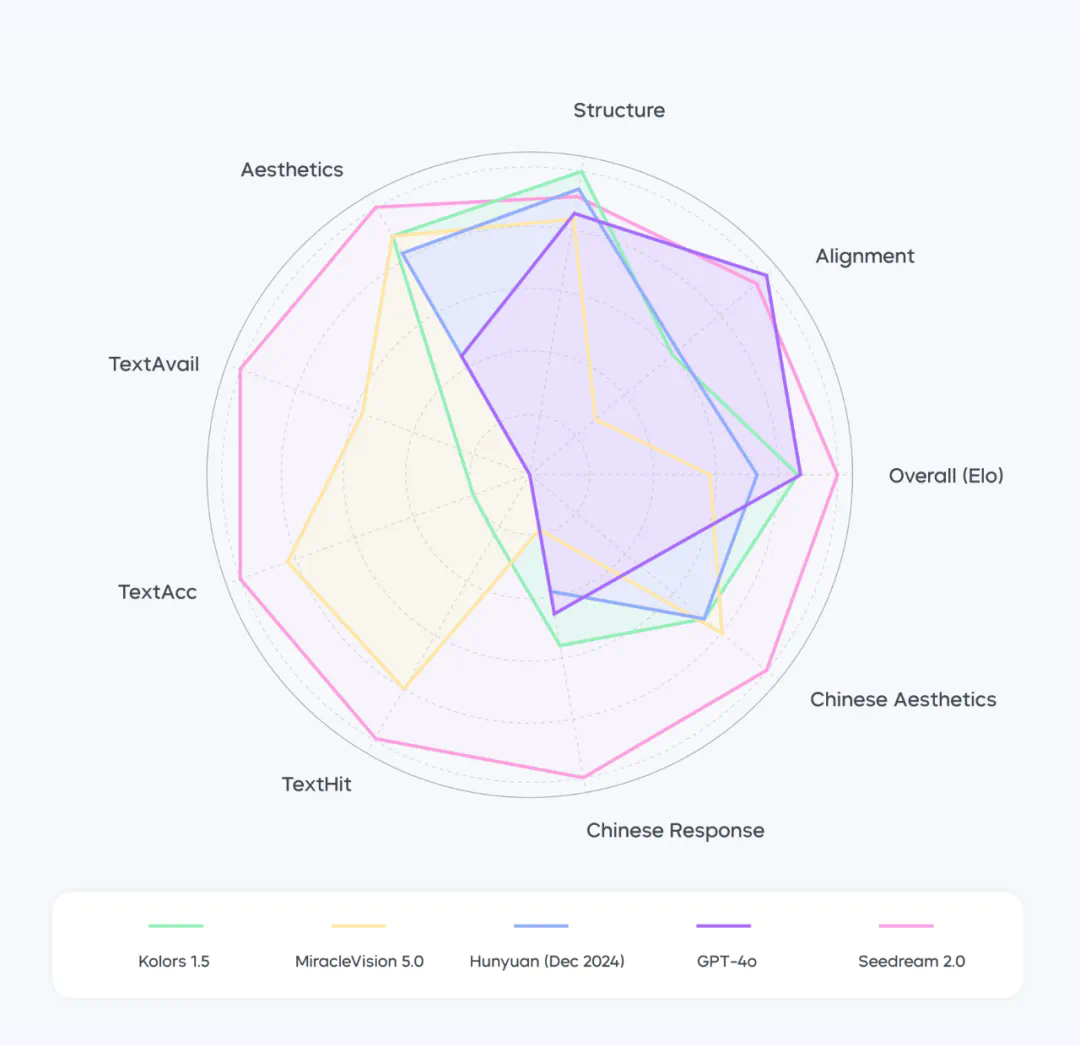
构建综合实力更强的模型
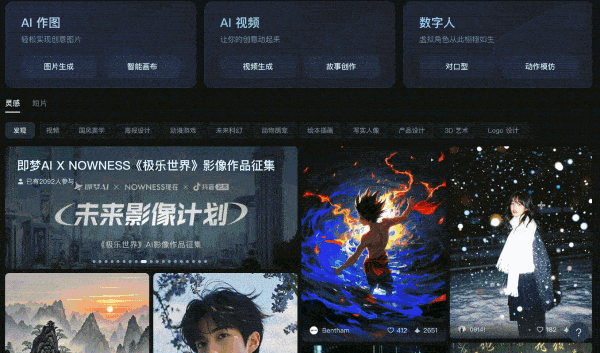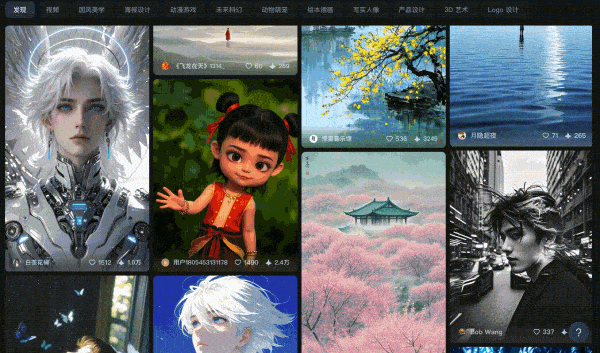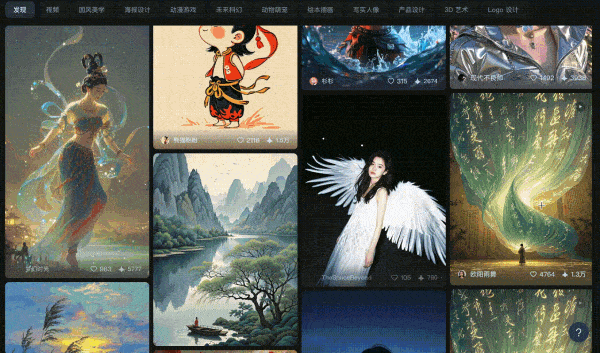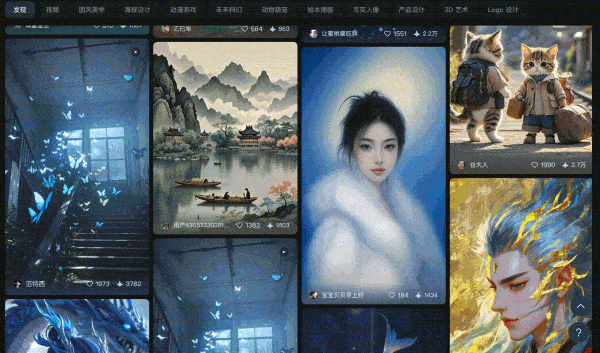

-
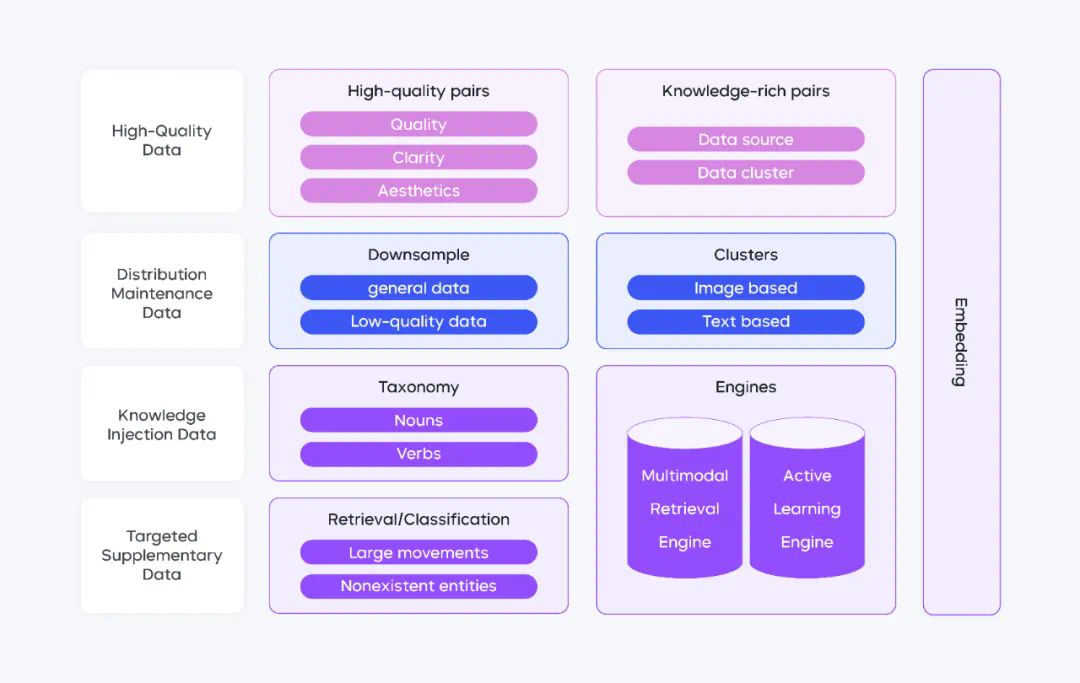
四维数据架构,实现质量与知识的动态平衡
-
优质数据层:精选高分辨率、知识密度强的数据(如科学图解、艺术创作),奠定质量基础;
-
分布维持层:采用双层级降采样策略,从数据源维度对头部平台等比降维,从语义维度通过 10 万级细粒度聚类维持多样性;
-
知识注入层:构建 3 万 + 名词和 2000 + 动词分类体系,结合百亿级跨模态检索,为数据注入文化特征;
-
定向增强层:建立 “缺陷发现 – 数据补充 – 效果验证” 闭环,优化动作序列、反现实生成等场景。
-
智能标注引擎:三级认知进化
-
工程化重构:百亿数据的流水线革命
-
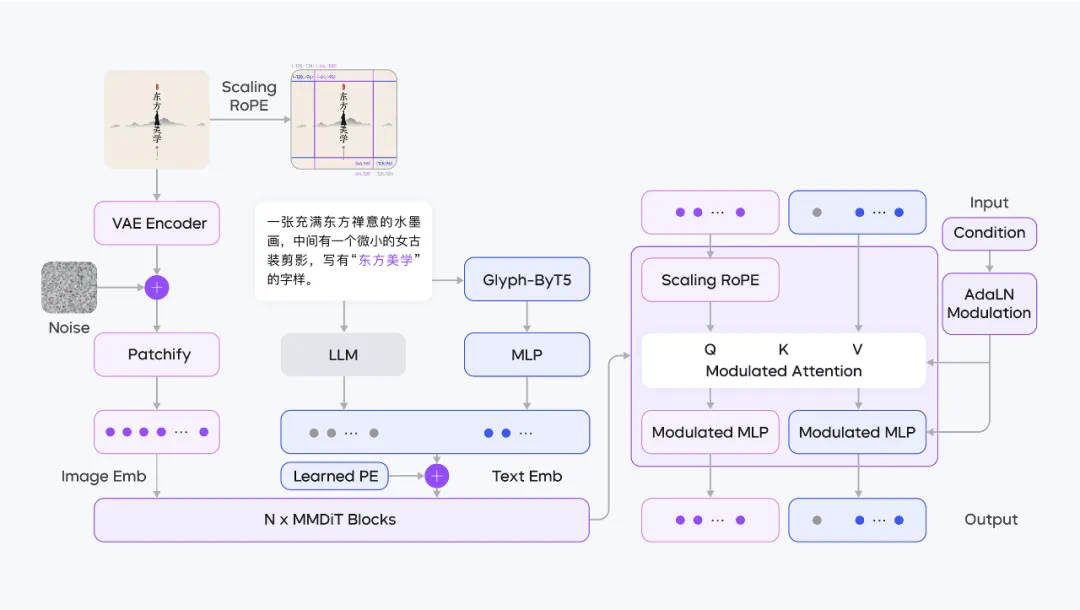
原生双语对齐方案,打破语言视觉次元壁
-
让模型既看懂文本,又关注字体字形
-
三重升级 DiT 架构,让图像生成缩放自如
-
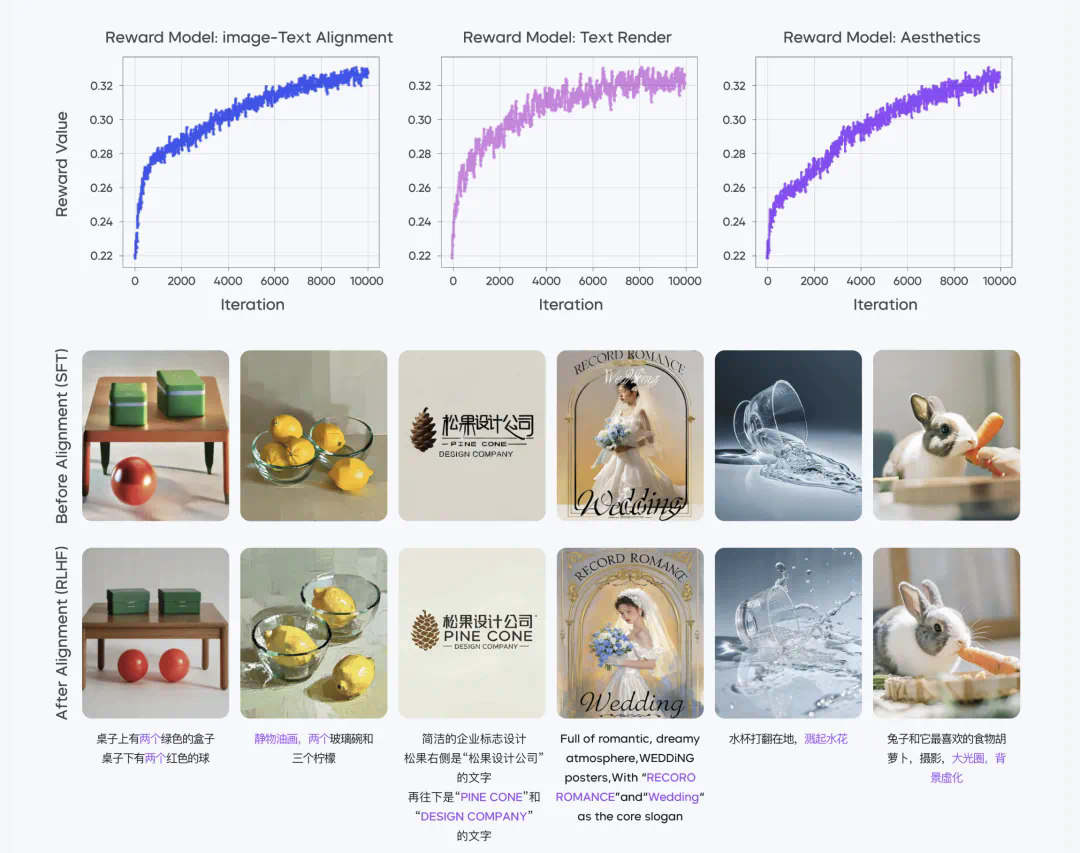
多维度偏好数据体系,提升模型偏好上限
-
三个不同奖励模型,给予专项提升
-
反复学习,驱动模型进化
文章来源于互联网:字节首次公开图像生成基模技术细节!数据处理到RLHF全流程披露
