
前言
在前两篇学习中【课程总结】day19(中):Transformer架构及注意力机制了解,我们初步了解大模型的公共底层架构Transformer的构成,同时借助对 Transformer 的代码深入了解(【课程总结】day20:Transformer源码深入理解之训练过程),初步掌握了 Transformer 的训练过程。本篇我们将对大模型的训练阶段进行初步了解,同时部署一个T5模型进行试用体验。
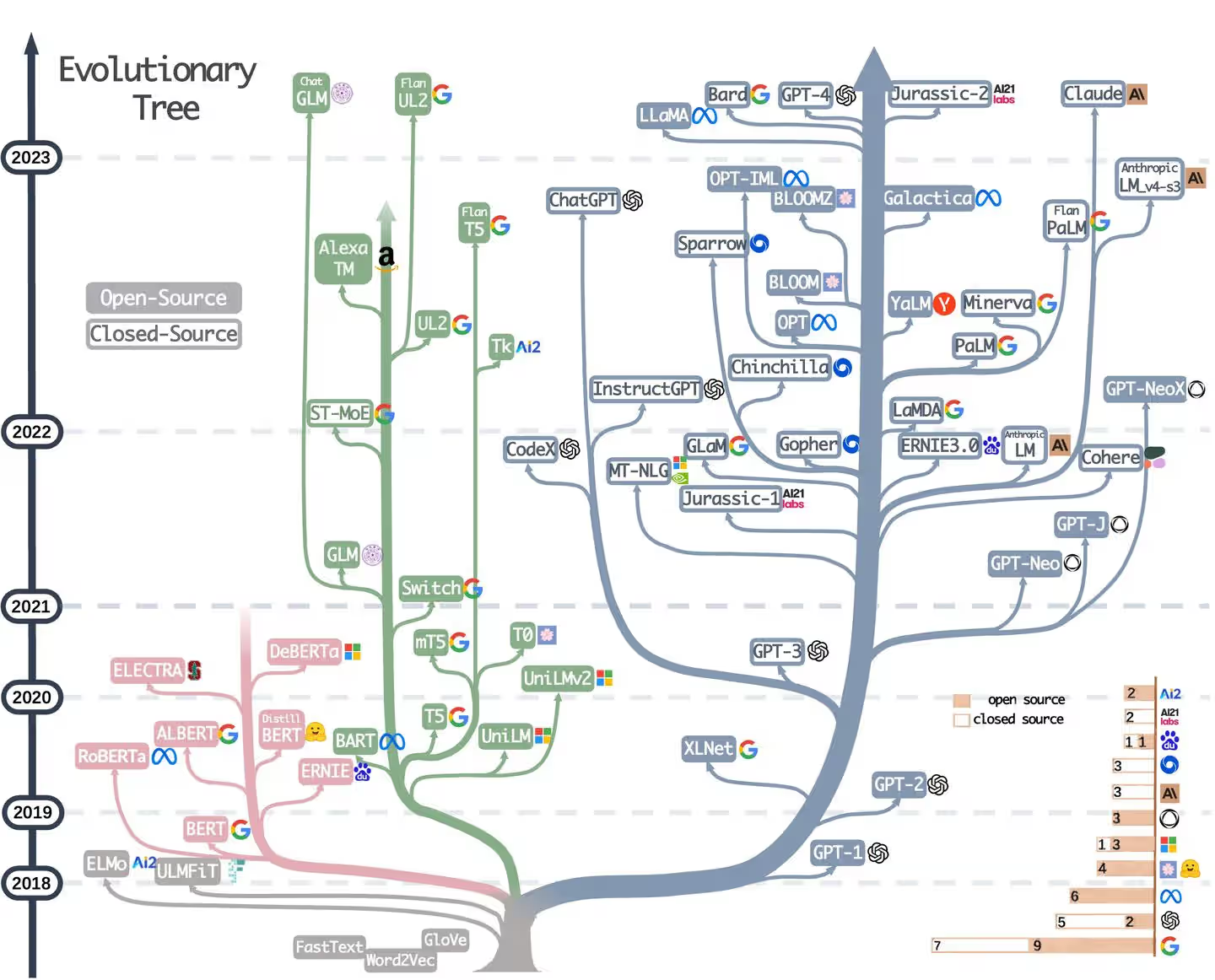
大模型的三大架构
大模型(如大型语言模型)的架构通常有多种类型,以下是三种主要的架构:
Encoder-Decoder 架构
架构:
由两个主要部分组成:编码器(Encoder)和解码器(Decoder),即Transformer 架构。它先理解输入的信息(Encoder部分),然后基于这个理解生成新的、相关的内容(Decoder部分)。
特点:
- 这种架构就像是翻译家。他先听你说一段话(比如英文),理解它,然后把它翻译成另一种语言(比如中文)。
- 擅长处理需要理解输入然后生成相关输出的任务,比如翻译或问答系统。
代表公司及产品:
- Google:Transformer、T5(Text-to-Text Transfer Transformer)
- Facebook:BART(Bidirectional and Auto-Regressive Transformers)
Encoder-Only 架构
架构:
仅包含编码器部分,即只是使用 Transformer 的 Encoder ,它专注于理解和分析输入的信息,而不是创造新的内容。
特点:
- 这种架构就像是一个专业的书评家。他阅读和理解一本书(输入的信息),然后告诉你这本书是关于什么的,比如它的主题是爱情、冒险还是悬疑。
- 擅长理解和分类信息,比如判断一段文本的情感倾向(积极还是消极)或者主题分类。
代表公司及产品:
- Google:BERT(Bidirectional Encoder Representations from Transformers)
- Facebook:RoBERTa、DistilBERT
Decoder-Only 架构
架构:
仅包含解码器部分,即只是使用 Transformer 的 Decoder ,它接收一些信息(开头),然后生成接下来的内容(故事)。
特点:
- 这种架构就像一个讲故事的人。你给他一个开头,比如“有一次,一只小猫走失了”,然后他会继续这个故事,讲述下去,一直到故事结束。
- 擅长创造性的写作,比如写小说或自动生成文章。它更多关注于从已有的信息(开头)扩展出新的内容。
代表公司及产品:
- OpenAI:GPT-3、GPT-4
三大架构演进图
大模型T5的体验
为了对大模型有个初步感受,本次我们拉取代码在本地部署一个T5模型并体验它。
环境搭建
体验大模型的方法有两种方案:本地环境 和 远程环境。
本地环境
本地环境的配置和使用方法,可以查看往期文章:Windows下安装ubuntu方法。
远程环境
第一步:访问Modelscope平台,注册账号。
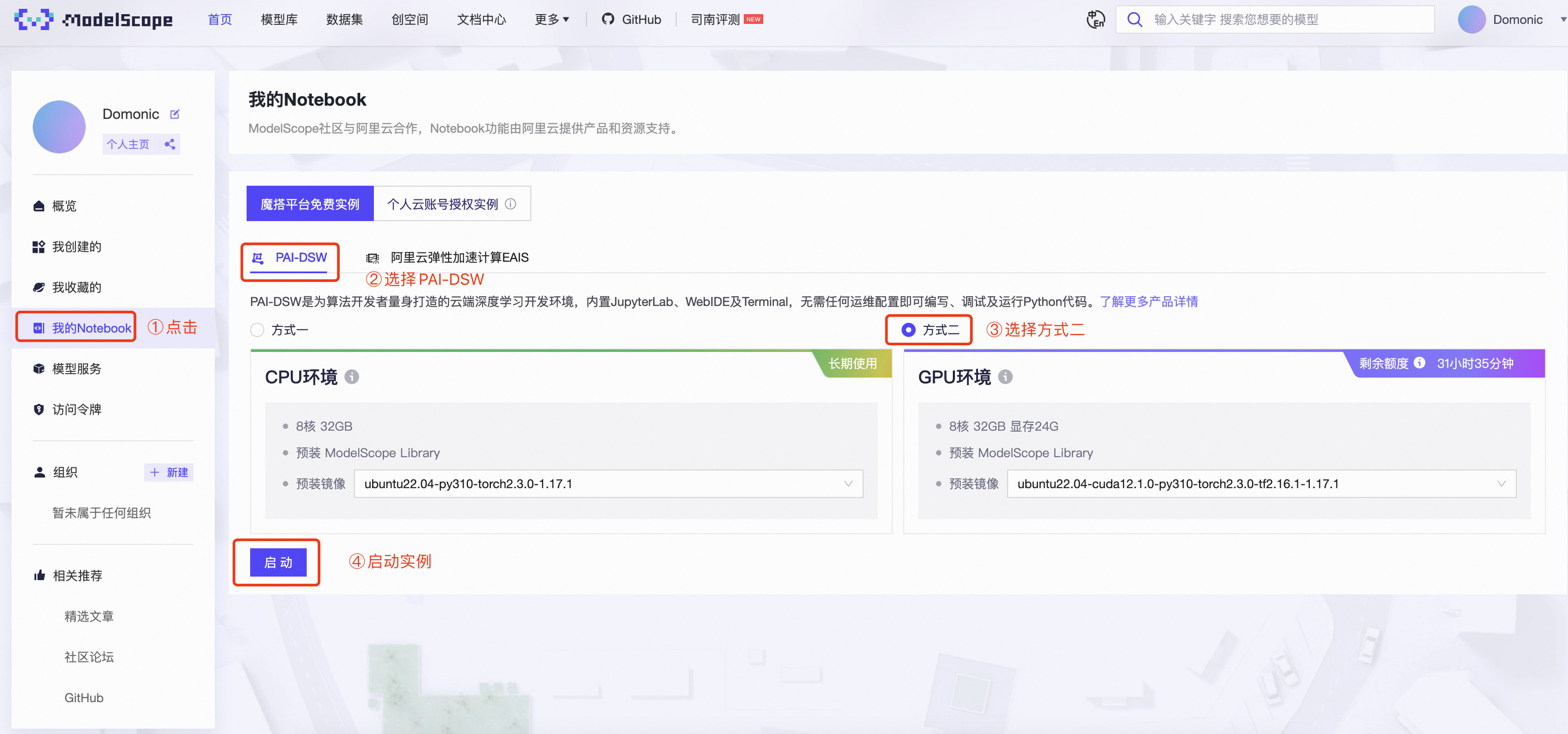
第二步:启动魔搭平台的PAI-DSW实例
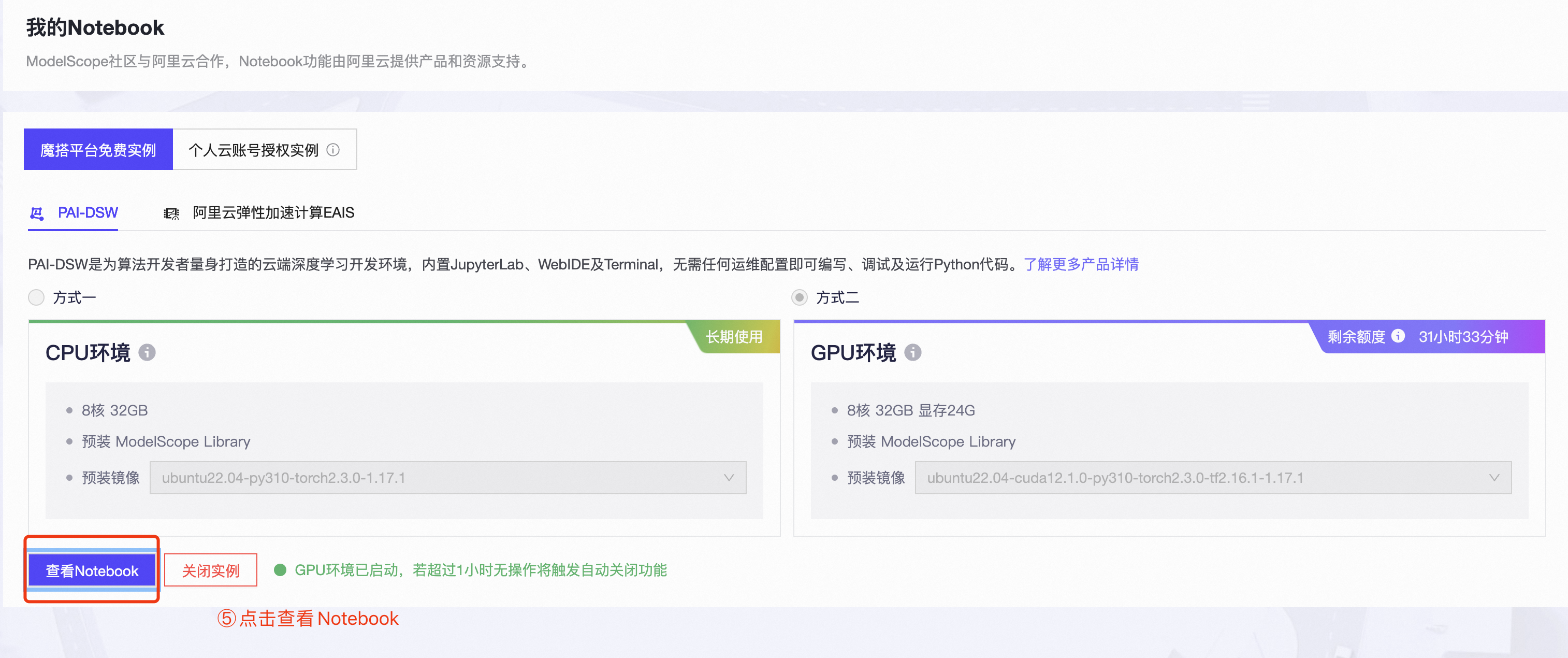
第三步:在新开的页面中登录阿里云账号
第四步:在PAI-DSW实例中启动终端命令行
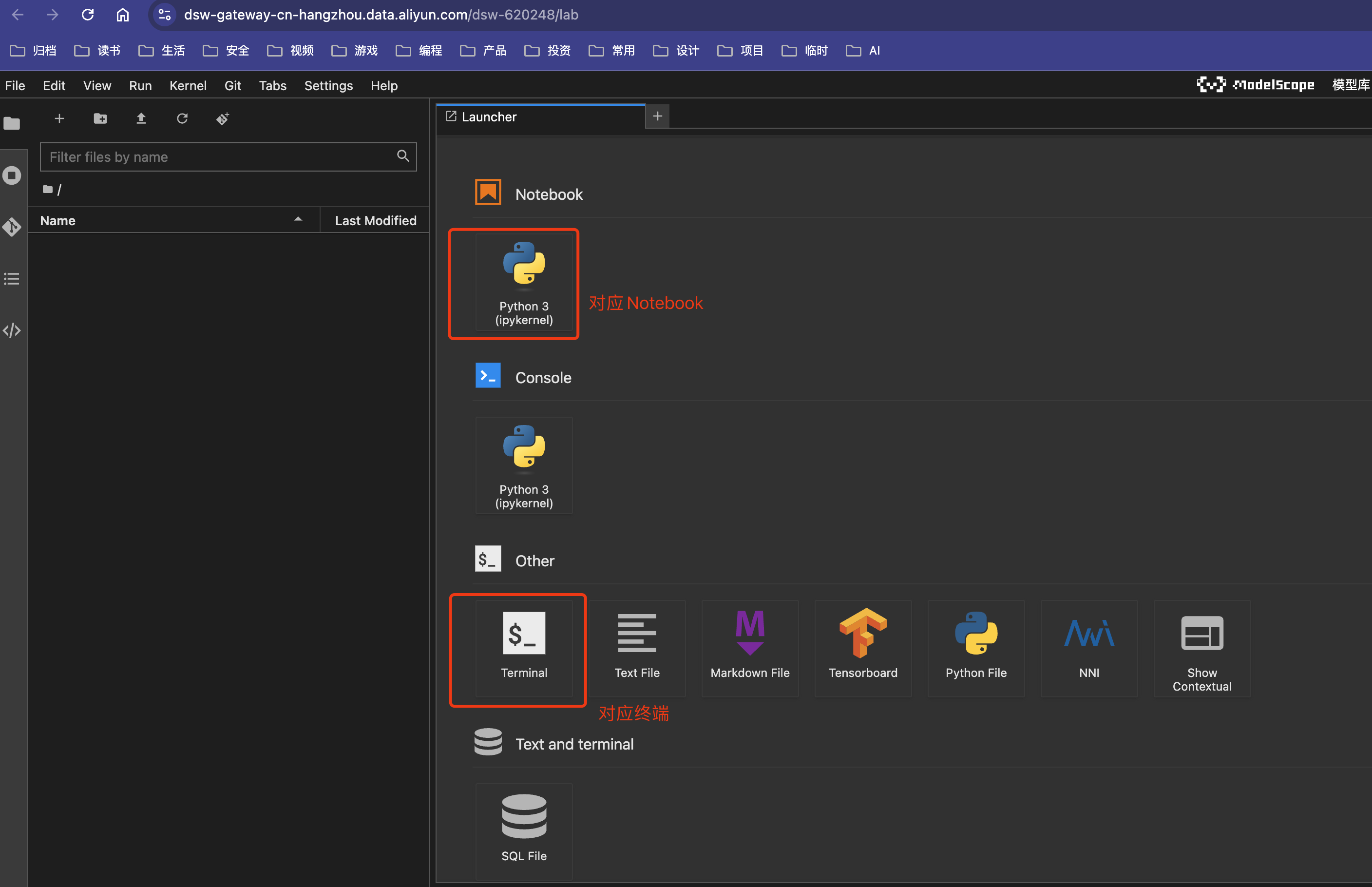
选择模型
在魔搭平台中搜索ChatLM模型,查看中文对话0.2B小模型,选择 模型文件,点击 下载模型。
代码拉取
在终端中输入以下命令,拉取模型代码
git clone https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git安装依赖
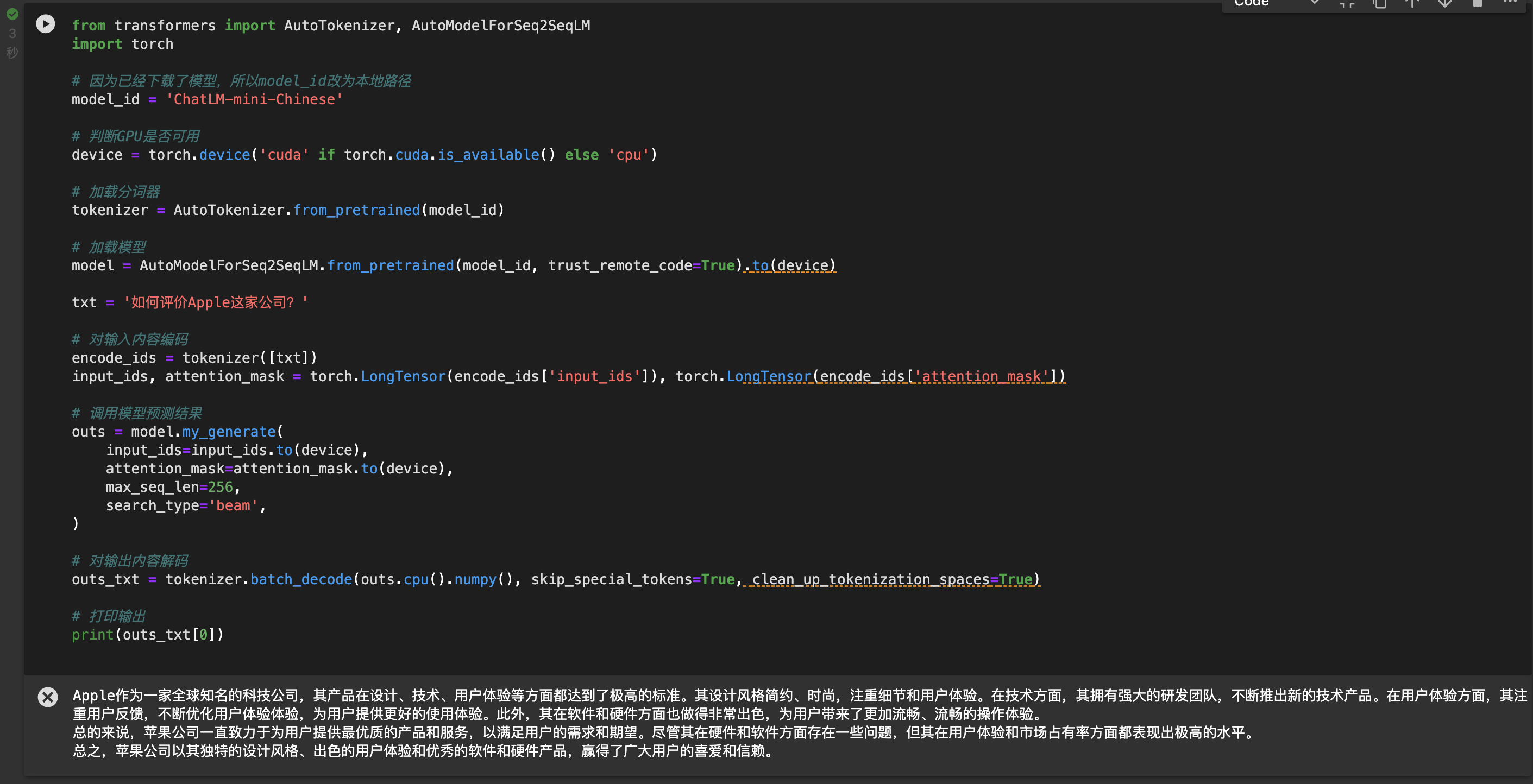
pip install transformers模型使用
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import torch
# 因为已经下载了模型,所以model_id改为本地路径
model_id = 'ChatLM-mini-Chinese'
# 判断GPU是否可用
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 加载模型
model = AutoModelForSeq2SeqLM.from_pretrained(model_id, trust_remote_code=True).to(device)
txt = '如何评价Apple这家公司?'
# 对输入内容编码
encode_ids = tokenizer([txt])
input_ids, attention_mask = torch.LongTensor(encode_ids['input_ids']), torch.LongTensor(encode_ids['attention_mask'])
# 调用模型预测结果
outs = model.my_generate(
input_ids=input_ids.to(device),
attention_mask=attention_mask.to(device),
max_seq_len=256,
search_type='beam',
)
# 对输出内容解码
outs_txt = tokenizer.batch_decode(outs.cpu().numpy(), skip_special_tokens=True, clean_up_tokenization_spaces=True)
# 打印输出
print(outs_txt[0])
运行结果:
补充知识
tokenizer 分词器
在Jupyter Notebook中查看tokenizer,可以看到分词器中包含常见的Token。
PreTrainedTokenizerFast(name_or_path='ChatLM-mini-Chinese', vocab_size=29298, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'eos_token': '[EOS]', 'unk_token': '[UNK]', 'pad_token': '[PAD]'}, clean_up_tokenization_spaces=True), added_tokens_decoder={
0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
1: AddedToken("[EOS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
2: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
3: AddedToken("[BOS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
4: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
5: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
6: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}model 模型
在Jupyter Notebook中查看model,可以看到T5模型的结构。
TextToTextModel(
(shared): Embedding(29298, 768)
(encoder): T5Stack(
(embed_tokens): Embedding(29298, 768)
(block): ModuleList(
(0): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=768, out_features=768, bias=False)
(k): Linear(in_features=768, out_features=768, bias=False)
(v): Linear(in_features=768, out_features=768, bias=False)
(o): Linear(in_features=768, out_features=768, bias=False)
(relative_attention_bias): Embedding(32, 12)
)
(layer_norm): FusedRMSNorm(torch.Size([768]), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=768, out_features=3072, bias=False)
(wo): Linear(in_features=3072, out_features=768, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): FusedRMSNorm(torch.Size([768]), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1-9): 9 x T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=768, out_features=768, bias=False)
(k): Linear(in_features=768, out_features=768, bias=False)
(v): Linear(in_features=768, out_features=768, bias=False)
(o): Linear(in_features=768, out_features=768, bias=False)
)
(layer_norm): FusedRMSNorm(torch.Size([768]), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=768, out_features=3072, bias=False)
(wo): Linear(in_features=3072, out_features=768, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): FusedRMSNorm(torch.Size([768]), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(final_layer_norm): FusedRMSNorm(torch.Size([768]), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(decoder): T5Stack(
(embed_tokens): Embedding(29298, 768)
(block): ModuleList(
(0): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=768, out_features=768, bias=False)
(k): Linear(in_features=768, out_features=768, bias=False)
(v): Linear(in_features=768, out_features=768, bias=False)
(o): Linear(in_features=768, out_features=768, bias=False)
(relative_attention_bias): Embedding(32, 12)
)
(layer_norm): FusedRMSNorm(torch.Size([768]), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerCrossAttention(
(EncDecAttention): T5Attention(
(q): Linear(in_features=768, out_features=768, bias=False)
(k): Linear(in_features=768, out_features=768, bias=False)
(v): Linear(in_features=768, out_features=768, bias=False)
(o): Linear(in_features=768, out_features=768, bias=False)
)
(layer_norm): FusedRMSNorm(torch.Size([768]), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(2): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=768, out_features=3072, bias=False)
(wo): Linear(in_features=3072, out_features=768, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): FusedRMSNorm(torch.Size([768]), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1-9): 9 x T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=768, out_features=768, bias=False)
(k): Linear(in_features=768, out_features=768, bias=False)
(v): Linear(in_features=768, out_features=768, bias=False)
(o): Linear(in_features=768, out_features=768, bias=False)
)
(layer_norm): FusedRMSNorm(torch.Size([768]), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerCrossAttention(
(EncDecAttention): T5Attention(
(q): Linear(in_features=768, out_features=768, bias=False)
(k): Linear(in_features=768, out_features=768, bias=False)
(v): Linear(in_features=768, out_features=768, bias=False)
(o): Linear(in_features=768, out_features=768, bias=False)
)
(layer_norm): FusedRMSNorm(torch.Size([768]), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(2): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=768, out_features=3072, bias=False)
(wo): Linear(in_features=3072, out_features=768, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): FusedRMSNorm(torch.Size([768]), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(final_layer_norm): FusedRMSNorm(torch.Size([768]), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(lm_head): Linear(in_features=768, out_features=29298, bias=False)
)- 查看该模型的结构,其结构是一个典型的
Transformer模型结构。 (encoder): T5Stack是编码器,其内部是由10个T5Block组成,(decoder): T5Stack是解码器,其内部也是由10个T5Block组成。T5LayerSelfAttention是自注意力处理模块,T5LayerCrossAttention是融合注意力处理模块,T5LayerFF是前馈模块。(lm_head): Linear是对应Transformer的输出层。
内容小结
- 大模型有三大架构:Encoderdecoder、Encoder-Only、Decoder-Only。
- Encoderdecoder架构就像是翻译家,代表模型是T5模型。
- Encoder-Only架构就像是书评家,代表模型是BERT模型。
- Decoder-Only架构就像是数学家,代表模型是GPT-4模型。
- 大模型训练阶段由三个阶段组成:
预训练(PT)、监督微调(SFT)和基于人类反馈的强化学习(RLHF)。
参考资料
欢迎关注公众号以获得最新的文章和新闻



