
机器学习项目实战:外卖点评情感分析预测
项目目的
基于中文外卖评论数据集,通过机器学习算法,对评论内容进行情感预测。
数据集
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| label | 整型 | 情感标签(1为正面,0为负面)。 |
| review | 字符型 | 评论内容。 |
-
数据集样例:
label review 1 很快,好吃,味道足,量大 1 没有送水没有送水没有送水 1 非常快,态度好。 1 方便,快捷,味道可口,快递给力 1 菜味道很棒!送餐很及时! 1 今天师傅是不是手抖了,微辣格外辣! 1 送餐快,态度也特别好,辛苦啦谢谢 1 超级快就送到了,这么冷的天气骑士们辛苦了。谢谢你们。麻辣香锅依然很好吃。 1 经过上次晚了2小时,这次超级快,20分钟就送到了…… 1 最后五分钟订的,卖家特别好接单了,谢谢。
解决思路
在《【课程总结】Day1:人工智能的核心概念》一文中,初步梳理过人工智能的开展流程,在本次实战项目中,我们将结合实战深入理解项目流程。
第一步:分析输入/输出
通过分析,本次项目我们要解决的问题:给定一段中文评论,判断其是正面评论还是负面评论。
该问题是一个典型的分类问题,分析相关输入/输出如下:
- 输入:一段中文评论
- 输出:1为正面,0为负面
第二步:构建数据集
机器学习数据集特点
一般来说,机器学习的特征数据具有以下特点:
- 特征与特征之间相互独立
- 数据集是一个表格类数据
- 数据成行成列
- 一行一个样本,一列一个特征
通过分析上述的数据集,可以看到该数据集基本满足上述特点,但是仍然存在一个比较大的问题:数据集是汉字,机器无法处理(因为机器学习底层是对数字的处理),所以我们首先需要对数据数字化(也叫汉字向量化)。
汉字向量化
在机器学习中,汉字向量化是将汉字表示为计算机可识别的数值形式的过程。常用的方法有:
-
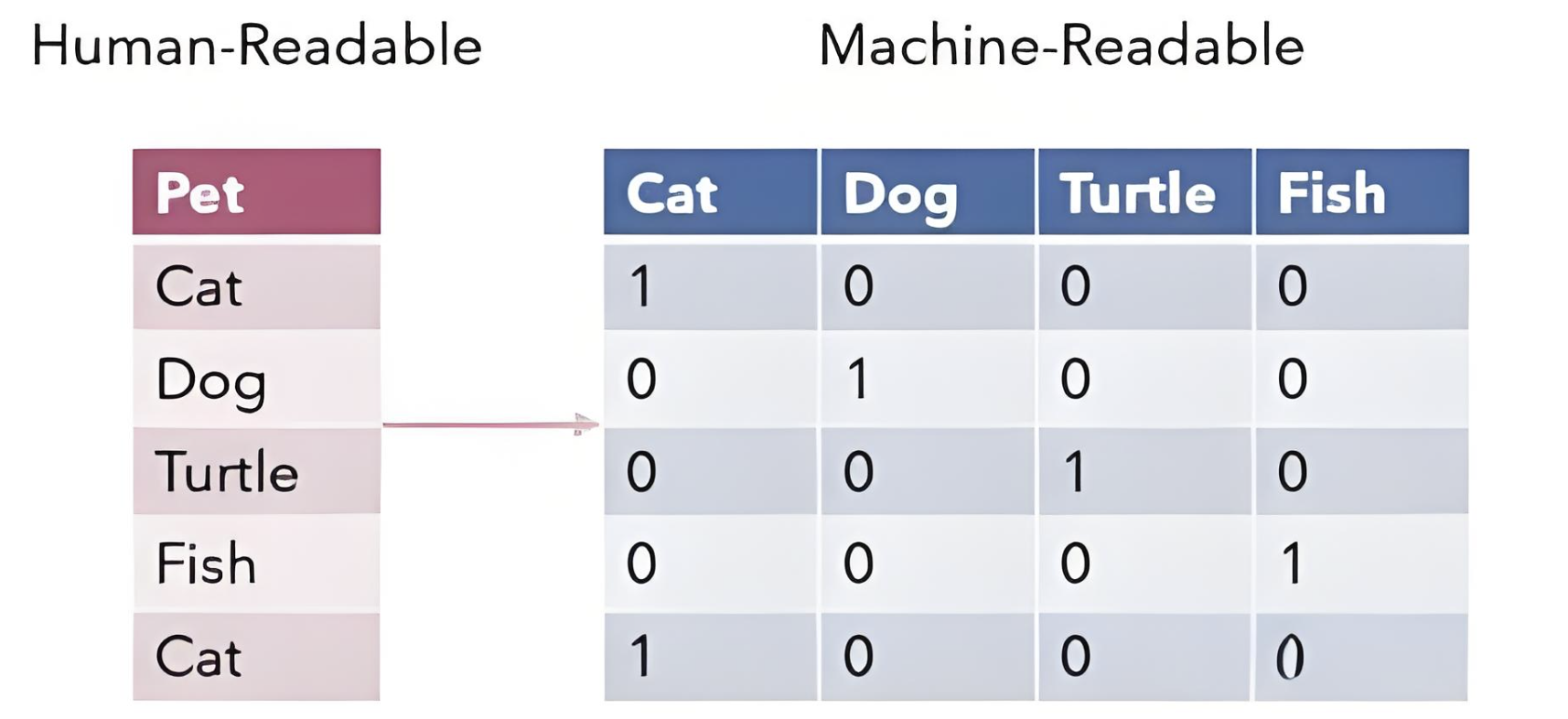
One-Hot 编码:
这是传统机器学习中常用的一种向量化方法。在这种方法中,每个汉字被表示为一个固定长度的向量,向量的大小等于字典的大小,每个条目对应于预定义单词字典中的一个单词,其中只有一个位置是1,其余为0。
-
词袋模型:
在词袋模型中,文本中的每个汉字被看作是独立的,没有关联性,然后根据字典统计单词出现的频数。这种方法虽然简单,但在文本向量化中具有一定的实用性。

以词袋模型为例:
如果将文本"方便,快捷,味道可口,快递给力"以字为单位进行切分,并使用词袋模型进行向量化,向量化过程如下:
构建字汇表:首先,将文本中的所有不重复的字作为字汇表。在这个例子中,字汇表为["方", "便", ",", "快", "捷", "味", "道", "可", "口", "快", "递", "给", "力"]。
向量化过程:对于每个文本,统计字汇表中每个字在文本中出现的次数,形成一个向量表示。
在这个例子中,"方便,快捷,味道可口,快递给力"的向量表示如下:
"方"出现1次
"便"出现1次
","出现3次
"快"出现2次
"捷"出现1次
"味"出现1次
"道"出现1次
"可"出现1次
"口"出现1次
"递"出现1次
"给"出现1次
"力"出现1次
因此,根据字汇表的顺序,该文本的词袋模型向量化结果为:
1,1,3,2,1,1,1,1,1,1,1,1
代码实现思路
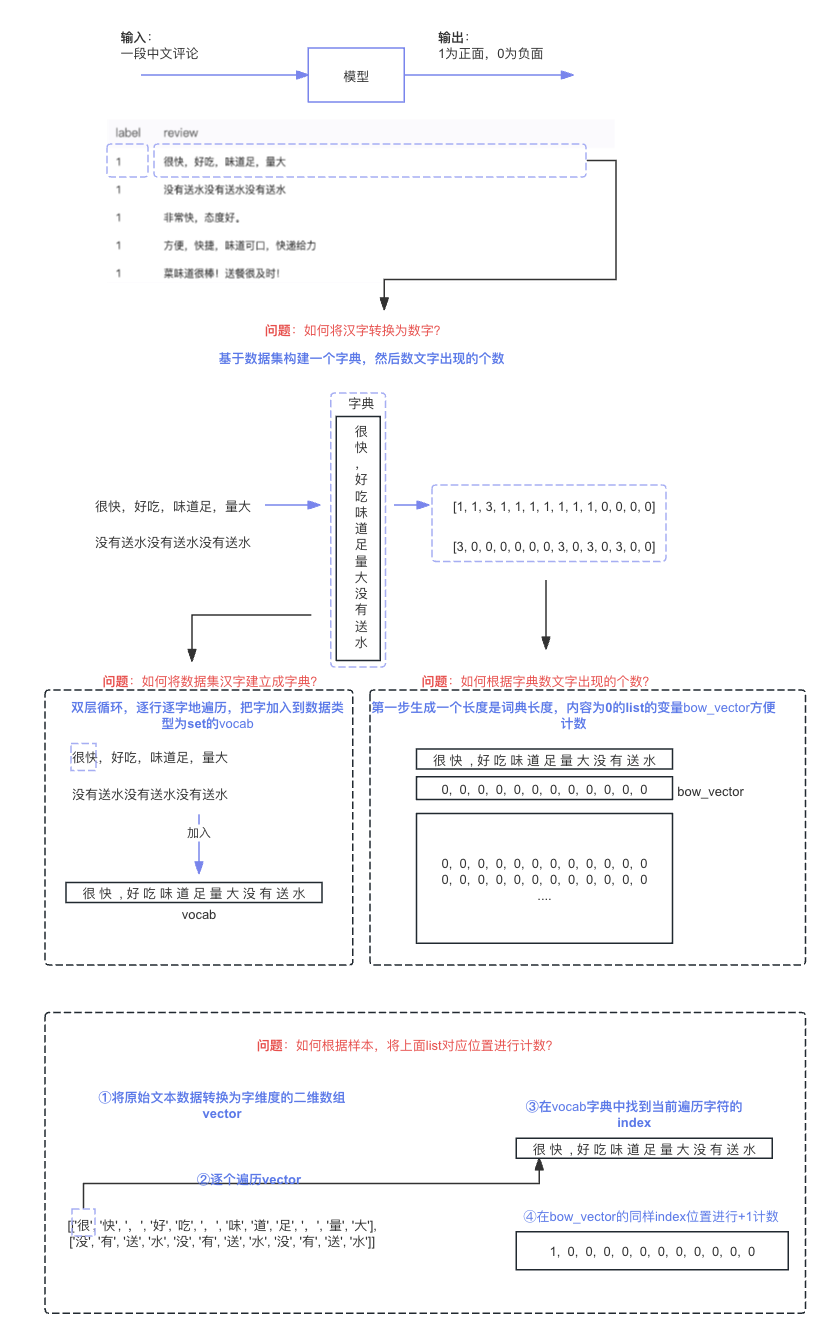
整体代码实现的解决思路如上图所示:
1、首先,我们需要读取csv文件并且将标签和特征数据切分出来。
2、其次,我们需要解决:如何将汉字转换为数字编码这个问题;
3、接着,通过与GPT沟通词袋模型,我们了解到需要构建一个词汇表,然后根据词汇表数个数,所以这个问题可以分解为两个子问题:如何将数据集汉字建立成字典?和如何根据字典数文字出现的个数?
4、对于如何将数据集汉字建立成字典?这个问题,我们通过与GPT沟通了解到,可以使用一个双层循环,逐行逐字遍历数据集,然后把字加入到一个set变量中。(因为set数据类型有滤重功能)
5、对于如何根据字典数文字出现的个数?这个问题,我们通过与GPT沟通了解到,需要下面几个小步骤:
- ①生成一个长度为字典长度,内容都为0的bow_vector。
- ②将原始的文本数据,以字的维度转成二维数组vector。
- ③根据上面②生成的vector,继续使用双层循环遍历,在字典vocab中找当前遍历的字地索引值
- ④根据索引值,在bow_vector同样的位置进行计数+1
大致的代码实现方法如下:
-
第一步:读取csv文件
import csv import numpy as np def read_file(file_path, skip_header=True): """ 读取CSV文件的内容。 参数: file_path (str): CSV文件的路径。 skip_header (bool): 是否跳过表头数据,默认为True。 返回: list: 包含CSV文件内容的列表。 """ print(f'读取原始数据集文件: {file_path}') with open(file_path, 'r', encoding='utf-8') as f: if skip_header: # 跳过表头数据 f.readline() reader = csv.reader(f) return [row for row in reader] # 读取csv文件的内容 read_file("./中文外卖评论数据集.csv") -
第二步:切分标签和数据
def split_data(data): """ 将数据分割为标签和数据。 参数: data (list): 数据行的列表,第一个元素是标签。 返回: numpy.ndarray: 标签数组。 numpy.ndarray: 连接元素后的数据数组。 """ label = [row[0] for row in data] data = [','.join(row[1:]) for row in data] # 转换为numpy数组 n_label = np.array(label) n_data = np.array(data) return n_label, n_data listdata = read_file('./中文外卖评论数据集.csv') label, data = split_data(listdata) print(label) print(data) -
第三步:生成词汇表
# 原始文本数据 data = [ "很快,好吃,味道足,量大", "没有送水没有送水没有送水" ] # 构建词汇表 vocab = set() for text in data: for char in text: vocab.add(char) # 输出结果 print("词汇表:", vocab)
运行结果:

-
第四步:生成向量化数据
# 原始文本数据 data = [ "很快,好吃,味道足,量大", "没有送水没有送水没有送水" ] # 向量化处理 vector = [] for text in data: words = list(text) # 将每个文本按字拆分为单个字,并转换为列表 vector.append(words) print("向量化后的结果:", vector)运行结果:

-
第五步:生成一个长度为字典长度,内容都为0的bow_vector;遍历vector,在vocab字典中找到当前遍历字符的index,然后在bow_vector的同样index位置进行+1计数
# 原始文本数据 data = [ "很快,好吃,味道足,量大", "没有送水没有送水没有送水" ] # 向量化处理 vector = [] for text in data: words = list(text) # 将每个文本按字拆分为单个字,并转换为列表 vector.append(words) # 向量化处理(生成词袋模型) vectorized_data = [] for words in vector: # 生成一个长度为len(vocab),内容都为0的向量 bow_vector = [0] * len(vocab) # 找到词语在词汇表中的索引,然后在对应的位置上加1 for word in words: if word in vocab: index = list(vocab).index(word) bow_vector[index] += 1 vectorized_data.append(bow_vector) # 输出向量化后的结果 print("向量化后的结果(词袋模型):", vectorized_data)运行结果:

至此,一个基本的数据预处理过程雏形已经完成。
接下来,
1、我们需要对上面的过程封装为一个function,然后将示例代码中的data替换为从文件读取切分出来的n_data,详细过程不再赘述。
2、最终生成的向量化数据,可以保存在内存中,在下面的运行模型中直接使用;也可以将向量化数据保存到本地文件,然后在模型方法中读取后使用。
我使用的方法是保存到本地后,在下面的decision_tree来读取使用。处理后的数据保存在vectorized_data.csv文件,其内容如下:

- label为标签
- x0~xn为特征数据
第三步:试验算法
为了跑通逻辑,我们先选择决策树来验证上述数据集是否可用。
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
def decision_tree(train_data_file_path='vectorized_data.csv', test_size=0.2):
"""
决策树模型的训练和评估。
参数:
train_data_file_path (str): 向量化数据的文件路径。
test_size (float): 测试集的比例,默认为0.2。
"""
print('开始加载训练数据...')
# 读取文件
with open(train_data_file_path, 'r', encoding='utf-8') as f:
reader = csv.reader(f)
data = [row for row in reader]
# 数据切分
label = [row[0] for row in data[1:]]
vector = [row[1:] for row in data[1:]]
# 训练集和测试集切分
X_train, X_test, y_train, y_test = train_test_split(vector, label, test_size=0.2)
print('开始训练决策树模型...')
# 数据预测
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
# 评估
print('开始决策树预测...')
accuracy = np.mean(y_pred == y_test)
print(f'预测准确率:{accuracy}')运行结果:

第四步:工程优化
通过上述验证数据集已经可以使用,整体流程已经没有问题。接下来我们对代码进行重构:
1、将整体代码使用面向对象封装为类实现
2、在汉字向量化处理中使用jieba的分词方式
3、在模型预测部分加入KNN、贝叶斯、线性回归、随机森林、SVC向量机的方式
由于重构的代码内容较多,本篇文章不再赘述,详情请见Github仓库
第五步:遴选算法
通过运行上述工程优化后的代码,执行结果如下:
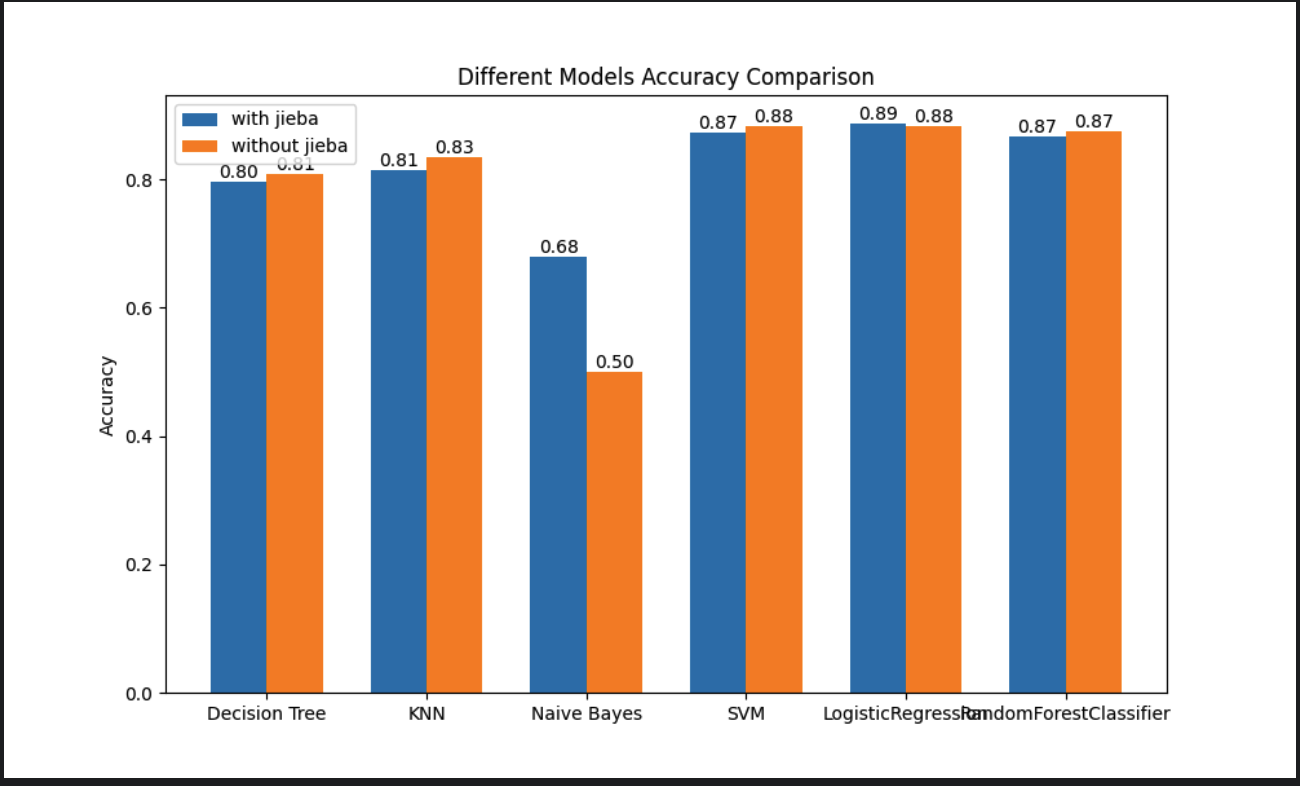
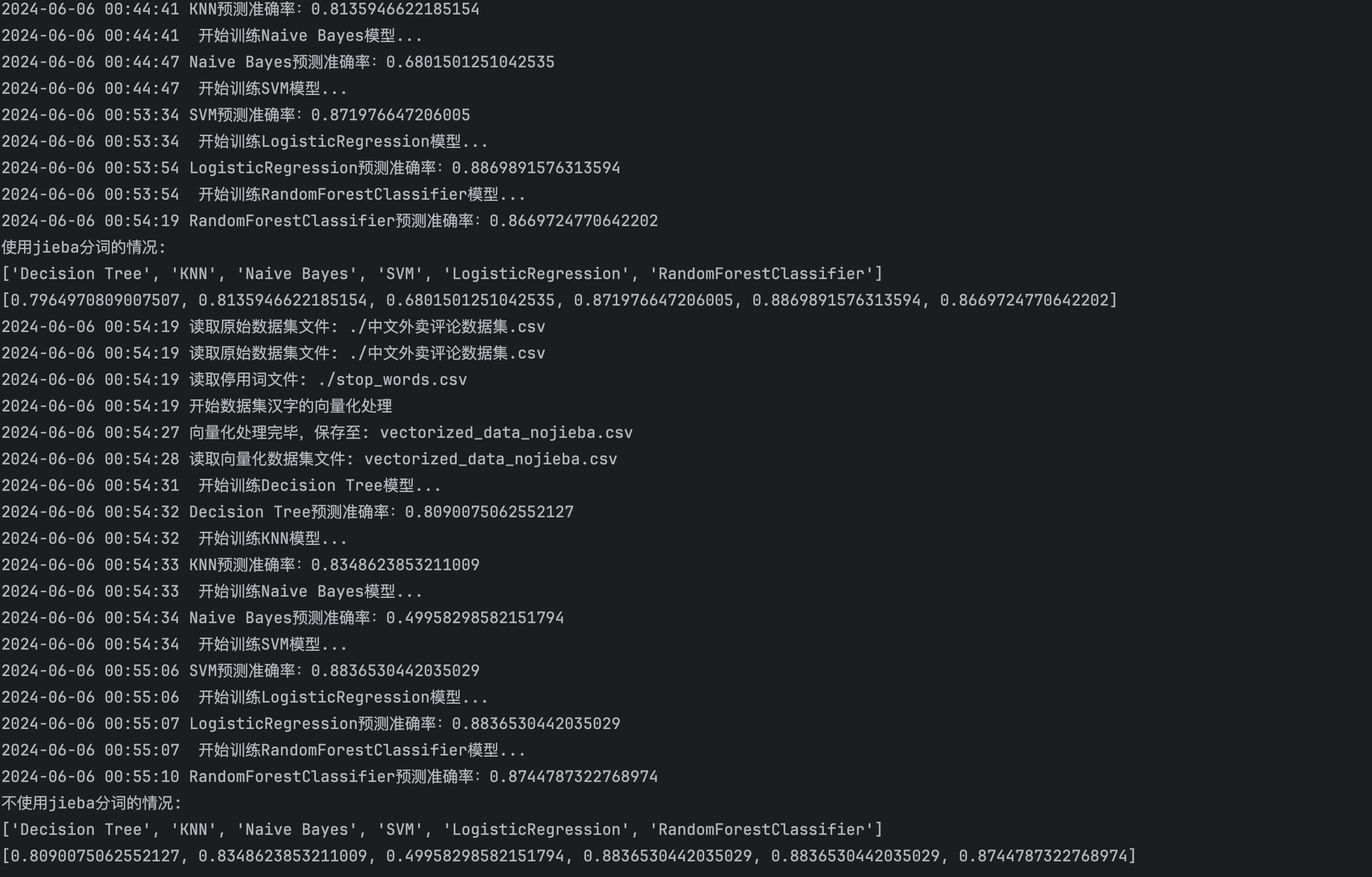
- 通过对比准确率,线性回归、SVC、随机森林的准确率较高。
- 通过分析日志中的执行时间,SVC在使用jieba分词时的训练时间大概有9分钟,训练速度比较慢。
- 因此,综合下来线性回归和随机森林是较为合适的机器学习模型。
内容小结
-
机器学习时,数据一般有如下特点
- 特征与特征之间相互独立
- 数据集是一个表格类数据
- 数据成行成列
- 一行一个样本,一列一个特征
-
如果数据是汉字,机器是无法处理的,其底层都是处理数字,我们需要将汉字向量化为数字
-
汉字的向量化方法一般来说有OneHot编码和词袋模型
参考资料
欢迎关注公众号以获得最新的文章和新闻



