前言
本章内容,我们将在已经构建的agent框架基础上,优化检索器,为检索器搭建ElasticSearch服务,实现问答系统的检索增强。
检索问题
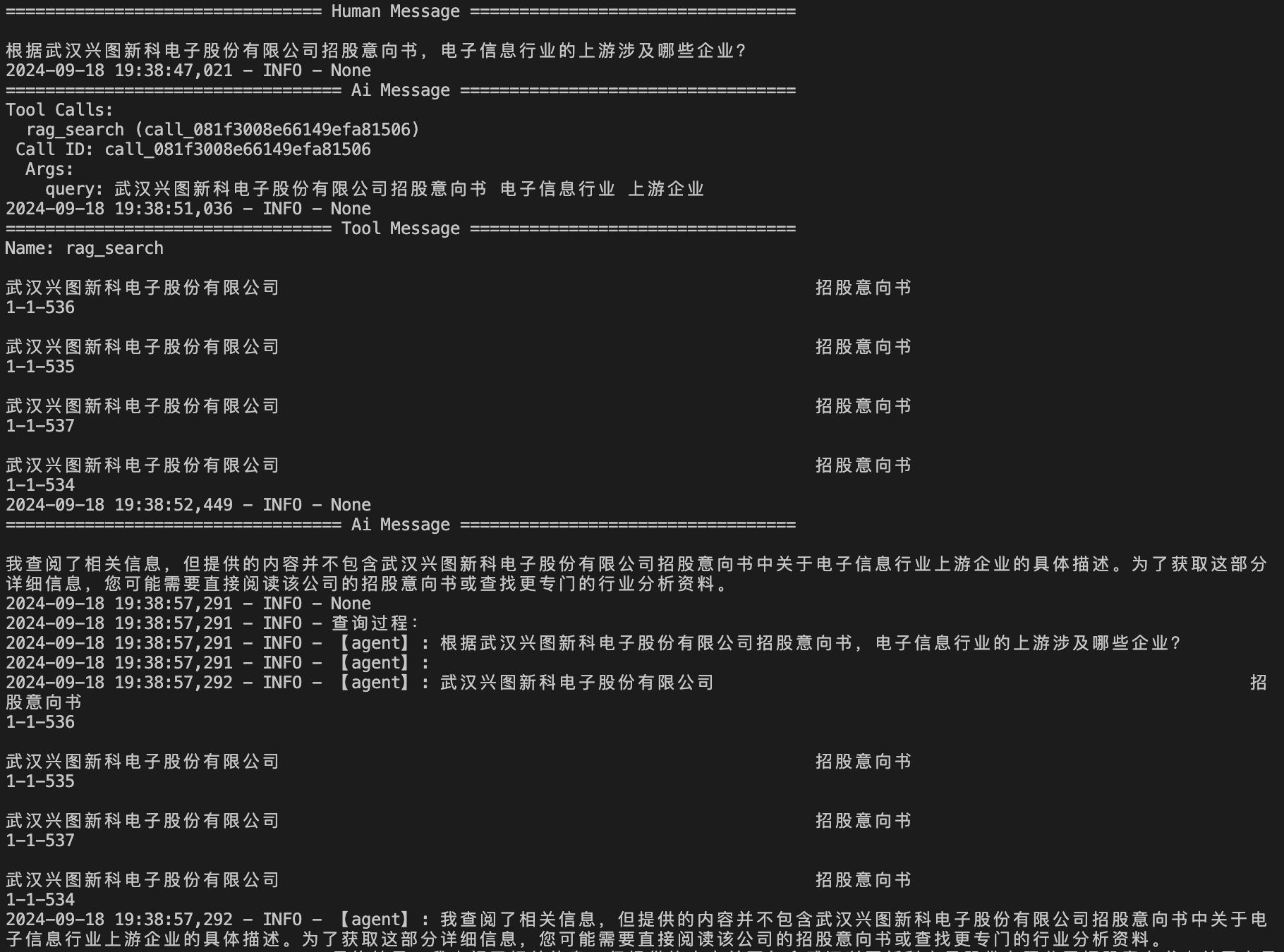
通过测试天池大赛数据集的前100个问题,我们发现有很多问题RAG检索不到,例如:
- {"id": 34, "question": "根据武汉兴图新科电子股份有限公司招股意向书,电子信息行业的上游涉及哪些企业?"}
通过查看日志,检索器没有检索到相关信息:
优化方案
分析上述case原因,检索器太过简单所致
class SimpleRetrieverWrapper():
"""自定义检索器实现"""
def __init__(self, store, llm, **kwargs):
self.store = store
self.llm = llm
logger.info(f'检索器所使用的Chat模型:{self.llm}')
def create_retriever(self):
logger.info(f'初始化自定义的Retriever')
chromadb_retriever = self.store.as_retriever()
return chromadb_retriever基于以上问题,我们计划使用集成检索器,方案如下:
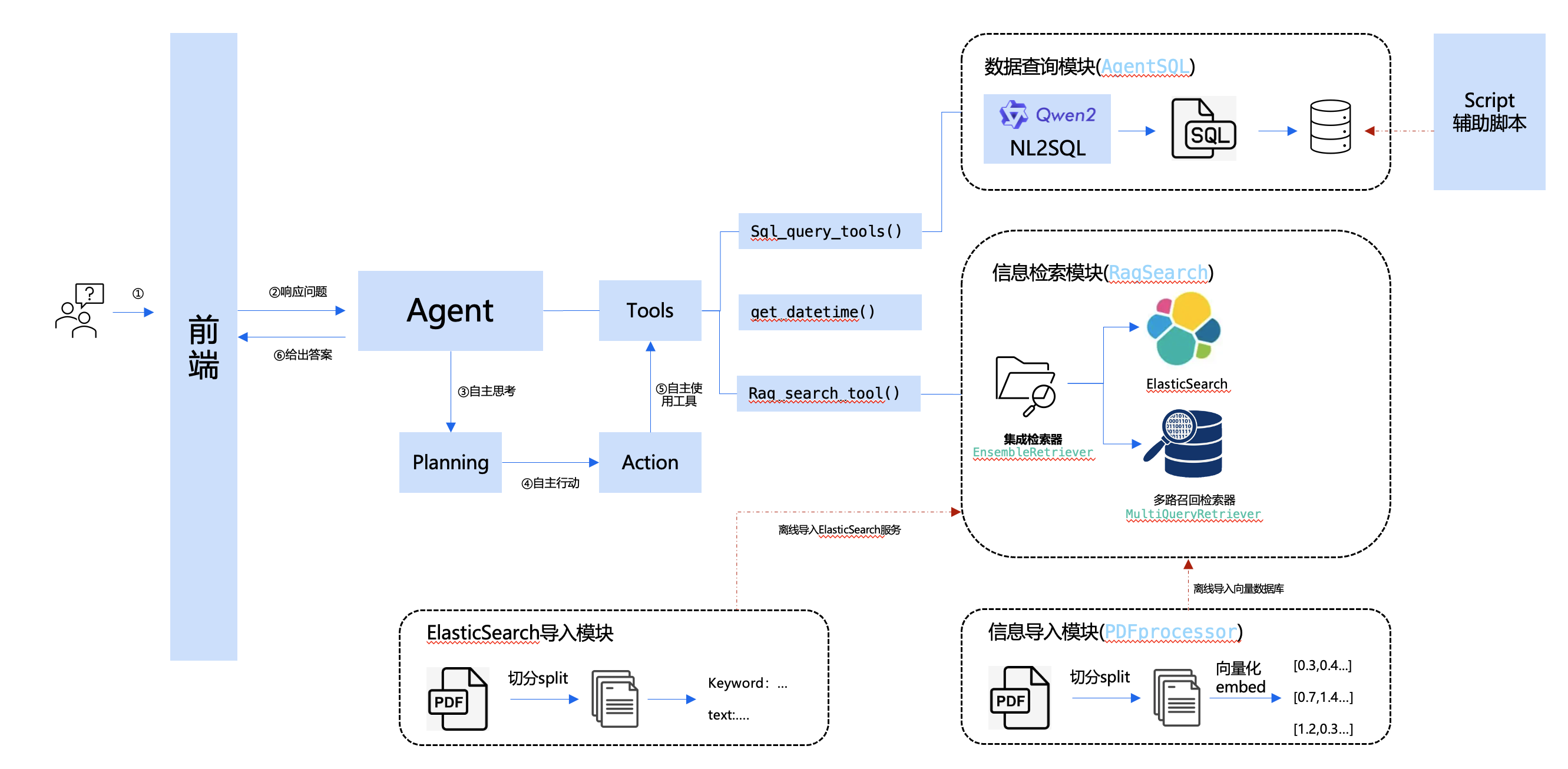
说明:
- 将检索器改为使用
EnsembleRetriever - 集成检索器其中之一使用
ElasticSearch检索器,这个检索器通过连接ElasticSearch服务,通过关键字查询相关信息。 - 集成检索器另外一个使用
MultiQueryRetriever检索器,这个检索器通过连接Chroma向量库查询信息。
关于MultiQueryRetriever和ElasticSearch,之前有文章做过基本内容的总结,详情请查看课程总结】day29:大模型之深入了解Retrievers解析器。
优化步骤
1、搭建ES服务
第一步:安装Docker,该内容不再赘述,具体请见10分钟学会Docker的安装和使用
第二步:创建网络
docker network create es-net
第三步:拉取镜像
docker pull elasticsearch:8.6.0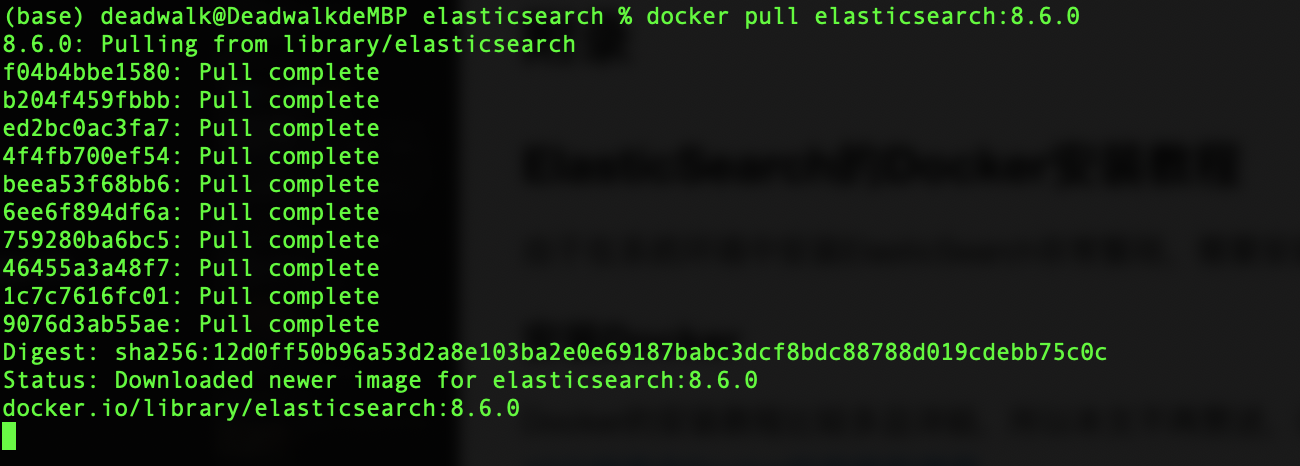
第四步:创建挂载点目录
smart-finance-bot \
|- app \
|- docker \
|- elasticsearch \ # 创建elasticsearch挂载目录
|- data \ # 创建数据目录
|- config \ # 创建配置目录
|- plugins \ # 创建插件目录第五步:命令行中输入命令启动Docker容器
docker run -d \
--restart=always \
--name es \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
--privileged \
-v /Users/deadwalk/Code/smart-finance-bot/docker/elasticsearch/data:/usr/share/elasticsearch/data \
-v /Users/deadwalk/Code/smart-finance-bot/docker/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
elasticsearch:8.6.0注意:
- 上述的
/Users/deadwalk/Code/smart-finance-bot请根据本地路径修改; - 运行完毕后请使用
docker ps确认容器已经启动。
第六步:进入es容器
docker exec -it es /bin/bash第七步:命令行输入重置密码命令(此处我们重置密码为123abc)
bin/elasticsearch-reset-password -i -u elastic
第八步:使用浏览器访问http://localhost:9200/,验证服务可以使用
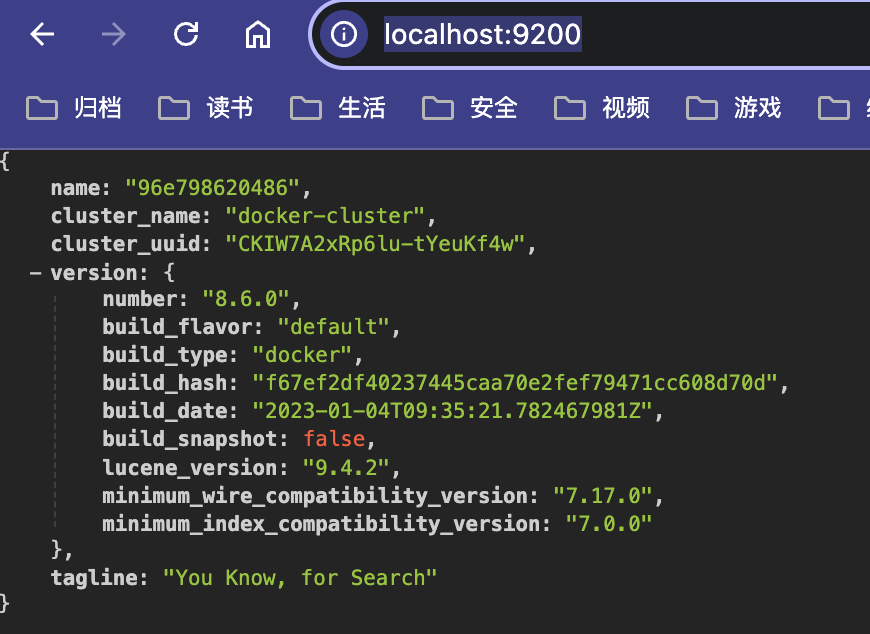
2、添加数据到ES服务
2.1、测试ES的连接
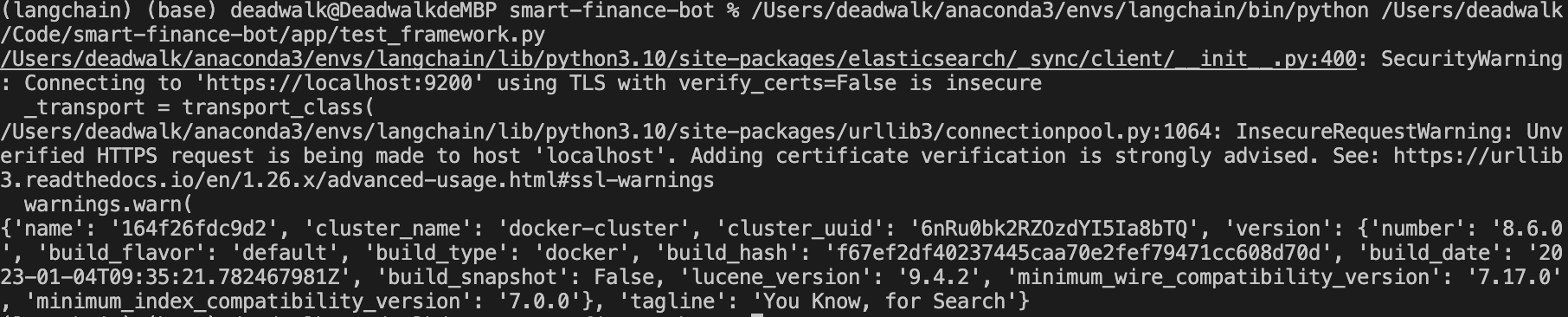
编写ES连接测试代码,验证ES服务连接。
def test_es_connect():
from elasticsearch import Elasticsearch
ELASTIC_PASSWORD = "123abc"
host = "localhost"
port = 9200
schema = "https"
url = f"{schema}://elastic:{ELASTIC_PASSWORD}@{host}:{port}"
client = Elasticsearch(
url,
verify_certs=False,
)
print(client.info())
运行结果:
2.2、实现ElasticSearch连接代码
代码文件:app/rag/elasticsearch_db.py
# 引入
from langchain_core.retrievers import BaseRetriever
from langchain_core.documents import Document
# ES需要导入的库
from typing import List
import re
import jieba
import nltk
from nltk.corpus import stopwords
import time
from elasticsearch import Elasticsearch
from elasticsearch.exceptions import ConnectionError, AuthenticationException
from elasticsearch import helpers
import settings
from utils.logger_config import LoggerManager
from utils.util_nltk import UtilNltk
import os
import warnings
warnings.simplefilter("ignore") # 屏蔽 ES 的一些Warnings
utilnltk = UtilNltk()
logger = LoggerManager().logger
class TraditionDB:
def add_documents(self, docs):
"""
将文档添加到数据库
"""
raise NotImplementedError("Subclasses should implement this method!")
def get_store(self):
"""
获得向量数据库的对象实例
"""
raise NotImplementedError("Subclasses should implement this method!")
class ElasticsearchDB(TraditionDB):
def __init__(self,
schema=settings.ELASTIC_SCHEMA,
host=settings.ELASTIC_HOST,
port=settings.ELASTIC_PORT,
index_name=settings.ELASTIC_INDEX_NAME,
k=3
# docs=docs
):
# 定义索引名称
self.index_name = index_name
self.k = k
try:
url = f"{schema}://elastic:{settings.ELASTIC_PASSWORD}@{host}:{port}"
logger.info(f'初始化ES服务连接:{url}')
self.es = Elasticsearch(
url,
verify_certs=False,
# ca_certs="./docker/elasticsearch/certs/ca/ca.crt",
# basic_auth=("elastic", settings.ELASTIC_PASSWORD)
)
response = self.es.info() # 尝试获取信息
logger.info(f'ES服务响应: {response}')
except (ConnectionError, AuthenticationException) as e:
logger.error(f'连接 Elasticsearch 失败: {e}')
raise
except Exception as e:
logger.error(f'发生其他错误: {e}')
logger.error(f'异常类型: {type(e).__name__}') # 记录异常类型
raise
def to_keywords(self, input_string):
"""将句子转成检索关键词序列"""
# 按搜索引擎模式分词
word_tokens = jieba.cut_for_search(input_string)
# 加载停用词表
stop_words = set(stopwords.words('chinese'))
# 去除停用词
filtered_sentence = [w for w in word_tokens if not w in stop_words]
return ' '.join(filtered_sentence)
def sent_tokenize(self, input_string):
"""按标点断句,没有用到"""
# 按标点切分
sentences = re.split(r'(?<=[。!?;?!])', input_string)
# 去掉空字符串
return [sentence for sentence in sentences if sentence.strip()]
def create_index(self):
"""如果索引不存在,则创建索引"""
if not self.es.indices.exists(index=self.index_name):
# 创建索引
self.es.indices.create(index=self.index_name, ignore=400)
def bluk_data(self, paragraphs):
"""批量进行数据灌库"""
# 灌库指令
actions = [
{
"_index": self.index_name,
"_source": {
"keywords": self.to_keywords(para.page_content),
"text": para.page_content
}
}
for para in paragraphs
]
# 文本灌库
helpers.bulk(self.es, actions)
# # 灌库是异步的
# time.sleep(2)
def flush(self):
# 刷新数据,数据入库完成以后刷新数据
self.es.indices.flush()
def search(self, query_string):
"""关键词检索"""
# ES 的查询语言
search_query = {
"match": {
"keywords": self.to_keywords(query_string)
}
}
res = self.es.search(index=self.index_name, query=search_query, size=self.k)
return [hit["_source"]["text"] for hit in res["hits"]["hits"]]
def delete(self):
"""如果索引存在,则删除索引"""
if self.es.indices.exists(index=self.index_name):
# 创建索引
self.es.indices.delete(index=self.index_name, ignore=400)
def add_documents(self, docs):
self.bluk_data(docs)
self.flush()说明:
- elasticsearch后续的插入操作中,使用到了nltk分词,其代码已经封装在UtilNltk类中,具体代码请查看Github仓库代码,本文不再赘述。
LoggerManager是代码重构时,封装的一个日志管理类,具体代码请查看Github仓库代码,本文不再赘述。
2.3、修改PDF文件导入代码
在settings.py中添加elasticsearch配置信息:
"""
ES数据库相关的配置
"""
# ES服务开关:True表示开启ES服务,False表示关闭ES服务
ELASTIC_ENABLE_ES = True
ELASTIC_PASSWORD = os.getenv("ELASTIC_PASSWORD", "123abc")
ELASTIC_HOST = os.getenv("ELASTIC_HOST", "localhost")
ELASTIC_PORT = os.getenv("ELASTIC_PORT", 9200)
ELASTIC_SCHEMA = "https"
ELASTIC_INDEX_NAME = "smart_test_index"
确认PDFProcessor.py中已经添加了对于Elasticsearch的插入操作支持,具体代码在【项目实战】基于Agent的金融问答系统:代码重构已做介绍,所以本文不再赘述。
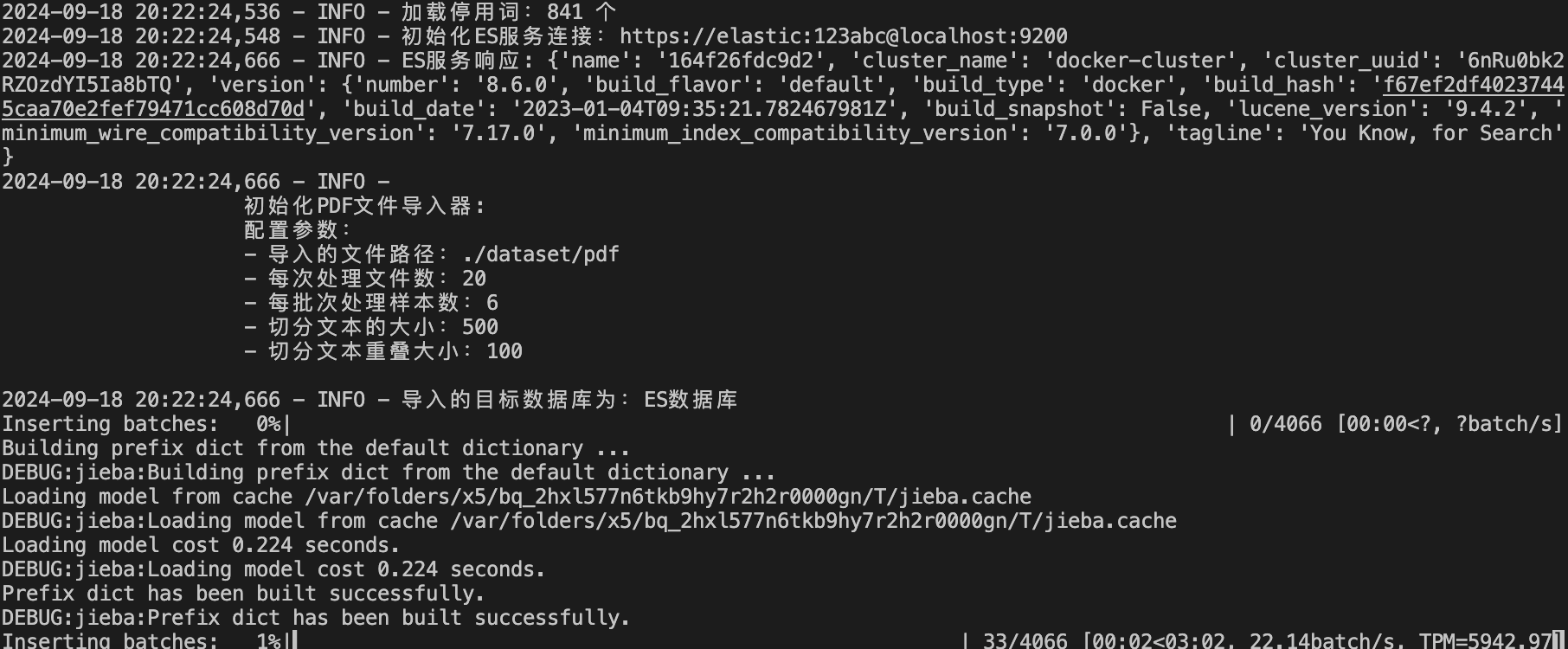
2.4、测试PDF文件导入代码
在test_framework.py中添加如下代码
def test_import_elasticsearch():
# from rag.elasticsearch_db import TraditionDB
from rag.elasticsearch_db import ElasticsearchDB
from rag.pdf_processor import PDFProcessor
llm, chat, embed = settings.LLM, settings.CHAT, settings.EMBED
# 导入文件的文件目录
directory = "./dataset/pdf"
# 创建 Elasticsearch 数据库实例
es_db = ElasticsearchDB()
# 创建 PDFProcessor 实例
pdf_processor = PDFProcessor(directory=directory,
db_type="es",
es_client=es_db,
embed=embed)
# 处理 PDF 文件
pdf_processor.process_pdfs()运行结果:
3、修改检索器增加Elasticsearch检索
代码文件:app/rag/retrievers.py
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from utils.logger_config import LoggerManager
from langchain_core.retrievers import BaseRetriever
from langchain_core.documents import Document
from langchain.retrievers import EnsembleRetriever
from langchain.retrievers.multi_query import MultiQueryRetriever
from rag.elasticsearch_db import ElasticsearchDB
# ES需要导入的库
from typing import List
import logging
import settings
logger = LoggerManager().logger
class SimpleRetrieverWrapper():
"""自定义检索器实现"""
def __init__(self, store, llm, **kwargs):
self.store = store
self.llm = llm
logger.info(f'检索器所使用的Chat模型:{self.llm}')
def create_retriever(self):
logger.info(f'初始化自定义的Retriever')
# 初始化一个空的检索器列表
retrievers = []
weights = []
# Step1:创建一个 多路召回检索器 MultiQueryRetriever
chromadb_retriever = self.store.as_retriever()
mq_retriever = MultiQueryRetriever.from_llm(retriever=chromadb_retriever, llm=self.llm)
retrievers.append(mq_retriever)
weights.append(0.5)
logger.info(f'已启用 MultiQueryRetriever')
# Step2:创建一个 ES 检索器
if settings.ELASTIC_ENABLE_ES is True:
es_retriever = ElasticsearchRetriever()
retrievers.append(es_retriever)
weights.append(0.5)
logger.info(f'已启用 ElasticsearchRetriever')
# 使用集成检索器,将所有启用的检索器集合在一起
ensemble_retriever = EnsembleRetriever(retrievers=retrievers, weights=weights)
return ensemble_retriever
class ElasticsearchRetriever(BaseRetriever):
def _get_relevant_documents(self, query: str, ) -> List[Document]:
"""Return the first k documents from the list of documents"""
es_connector = ElasticsearchDB()
query_result = es_connector.search(query)
logger.info(f"ElasticSearch检索到资料文件个数:{len(query_result)}")
if query_result:
return [Document(page_content=doc) for doc in query_result]
return []
async def _aget_relevant_documents(self, query: str) -> List[Document]:
"""(Optional) async native implementation."""
es_connector = ElasticsearchDB()
query_result = es_connector.search(query)
if query_result:
return [Document(page_content=doc) for doc in query_result]
return []4、测试验证
在test_framework.py中运行test_financebot_ex()函数,测试检索功能。
def test_financebot_ex():
from finance_bot_ex import FinanceBotEx
# 使用Chroma 的向量库
financebot = FinanceBotEx()
example_query = "根据武汉兴图新科电子股份有限公司招股意向书,电子信息行业的上游涉及哪些企业?"
financebot.handle_query(example_query)运行结果:
连接ES后检索到3个资料文件
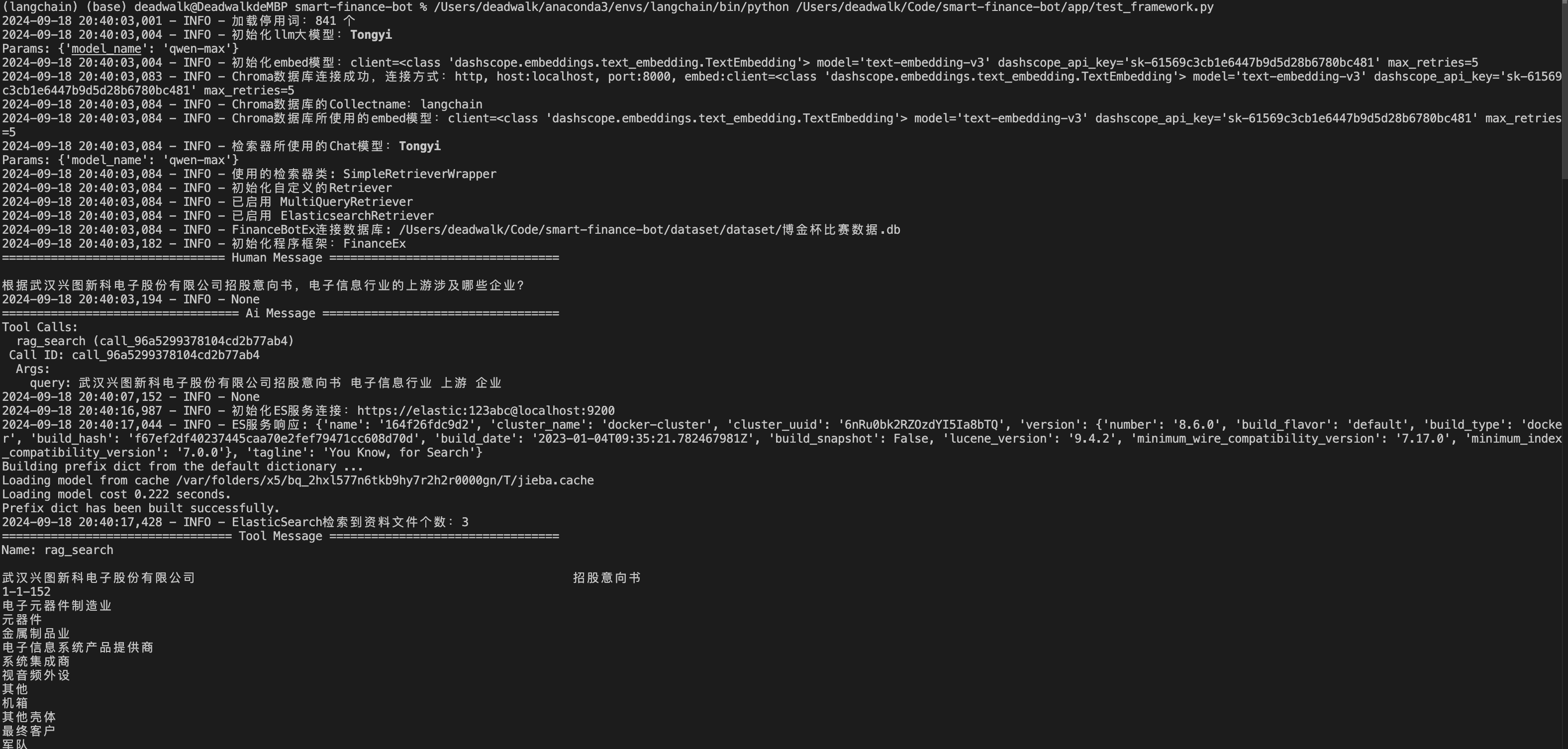
使用多路召回,生成3个检索问题

最终通过集成检索器检索到答案

优化效果
通过对天池大赛前100个问题的对比测试,我们最终得到如下对比验证结果:
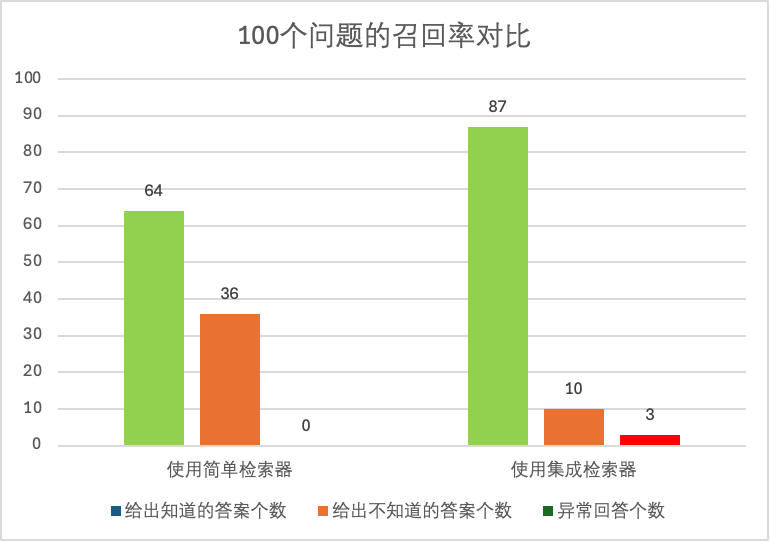
内容小结
- 集成检索器:
- 可以有效提高检索的效率,同时可以增加检索的准确度。
- 可以添加多个检索器并配置不同的权重,以实现灵活的组合。
- Elasticsearch
- 作为传统搜索引擎,可以通过keyword_search检索到相关内容。
- 使用时需要使用Docker搭建ES服务。
- 数据文件需要添加到ES服务中,方便检索。
- MultiQueryRetriever
- 多路召回,将问题拆分成多个问题,然后进行检索,最终合并结果。
附录
欢迎查看该系列的其他文章:
- 【项目实战】基于Agent的金融问答系统:项目简介
- 【项目实战】基于Agent的金融问答系统:RAG检索模块初建成
- 【项目实战】基于Agent的金融问答系统:Agent框架的构建
- 【项目实战】基于Agent的金融问答系统:前后端流程打通
- 【项目实战】基于Agent的金融问答系统:代码重构
- 【项目实战】基于Agent的金融问答系统:RAG的检索增强之ElasticSearch
- 【项目实战】基于Agent的金融问答系统:RAG的检索增强之上下文重排和压缩
欢迎关注公众号以获得最新的文章和新闻



