前言
在上一章【项目实战】基于Agent的金融问答系统:RAG的检索增强之ElasticSearch中,我们在已经构建的Agent框架上,通过集成检索器将ES检索器和多路召回检索器集成进来,提升了检索的召回率。本章,我们将基于项目问题,进一步优化Agent的检索能力。
问题
随着该项目检索能力的增强,我们计划对天池大赛提供的1000个问题进行执行,依次评估我们的系统能力如何。
在这个测试过程中,我们发现了多个待优化的问题,其中有2个问题的解决值得分享,在此作为记录以供读者参考。
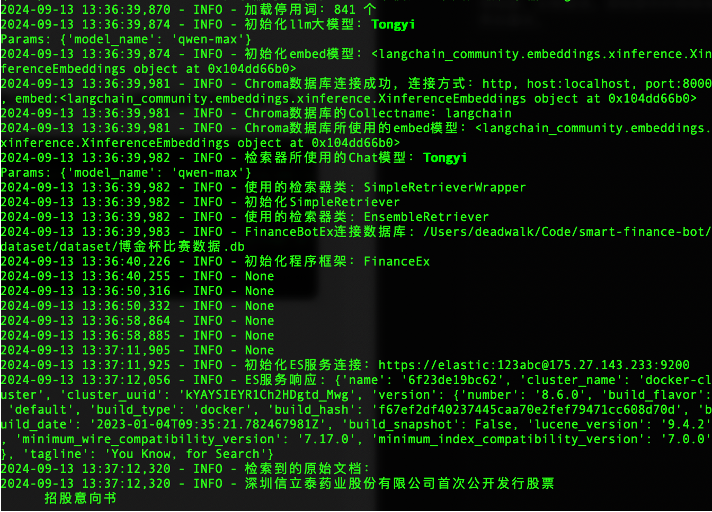
问题1:执行过程中,偶尔会出现RAG检索结果内容过长,超出大模型能够接收的范围(如下图中显示的status_code=400),导致执行中断
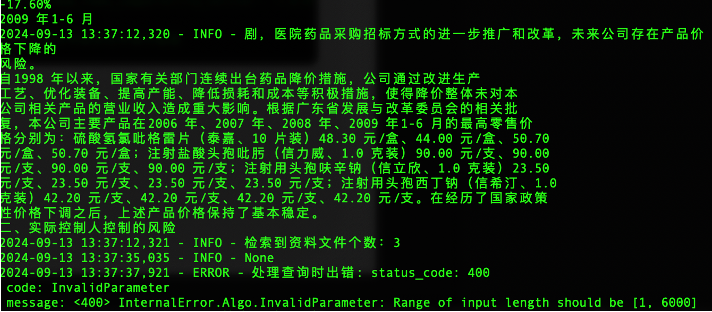
问题2:Agent遇到计算涨幅、收益率等问题时,会反复构造SQL语句,试图从数据库中直接查询出对应的数据,从而导致思考迭代此处超过限制,程序异常

优化方案
分析上述问题后,我们计划对整体程序进行优化,优化方案如下:
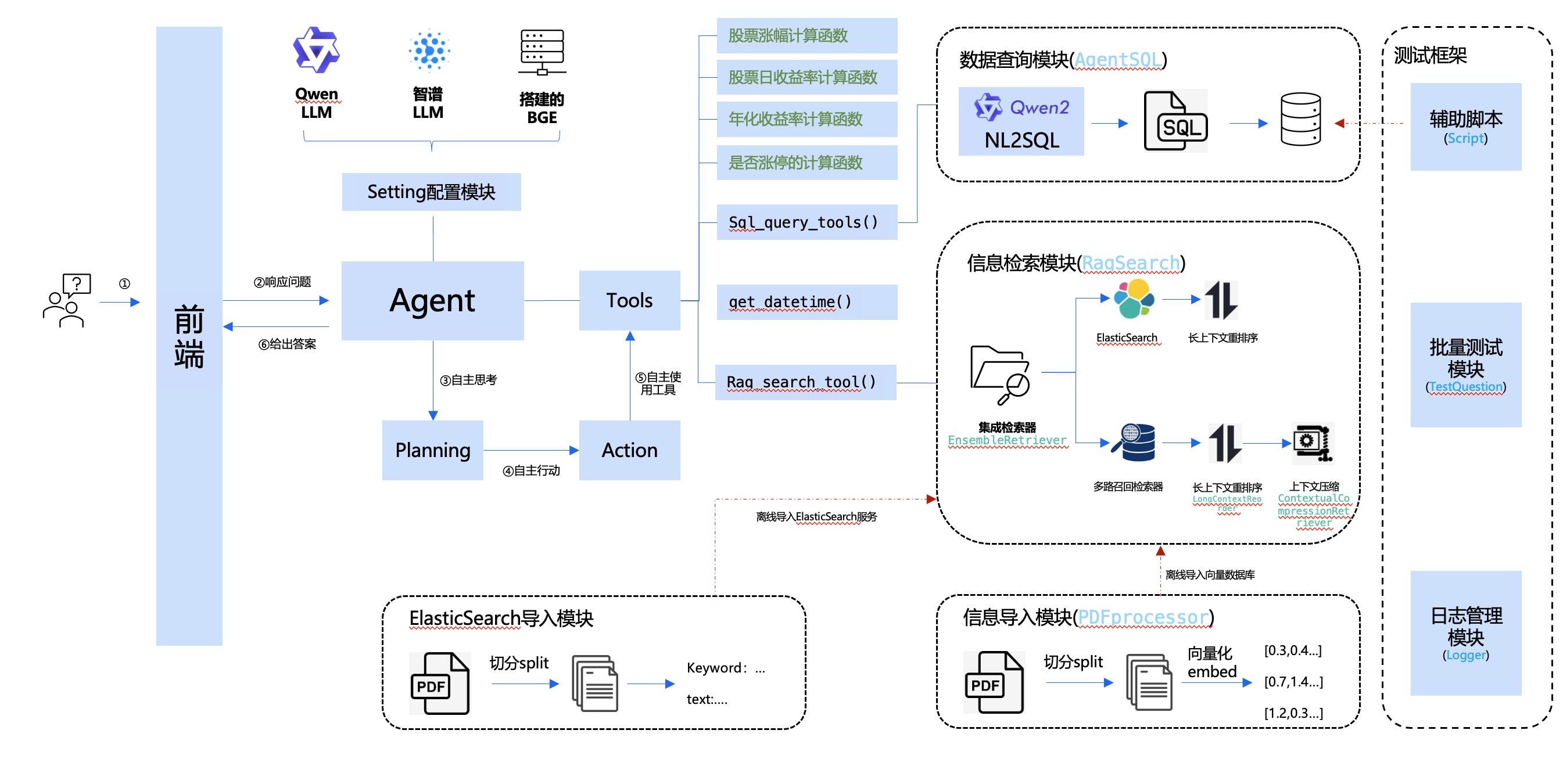
说明:
- 针对问题1,我们计划给集成检索器增加上下文重排和压缩,以解决长文本问题。
- 针对问题2,我们计划为Agent挂载更多的工具,进而让Agent使用工具计算涨幅、收益率等。
优化步骤
1、检索器增加上下文压缩
优化代码文件:app/rag/retrievers.py
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from utils.logger_config import LoggerManager
from langchain_core.retrievers import BaseRetriever
from langchain_core.documents import Document
from langchain.retrievers import EnsembleRetriever
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from rag.elasticsearch_db import ElasticsearchDB
# ES需要导入的库
from typing import List
import logging
import settings
from langchain_community.document_transformers import (
LongContextReorder,
)
from utils.util import get_rerank_model
logger = LoggerManager().logger
class SimpleRetrieverWrapper():
"""自定义检索器实现"""
def __init__(self, store, llm, **kwargs):
self.store = store
self.llm = llm
logger.info(f'检索器所使用的Chat模型:{self.llm}')
def create_retriever(self):
logger.info(f'初始化自定义的Retriever')
# 初始化一个空的检索器列表
retrievers = []
weights = []
# Step1:创建一个 多路召回检索器 MultiQueryRetriever
chromadb_retriever = self.store.as_retriever()
mq_retriever = MultiQueryRetrieverWrapper.from_llm(retriever=chromadb_retriever, llm=self.llm)
# Step2:创建一个 上下文压缩检索器ContextualCompressionRetriever
if settings.COMPRESSOR_ENABLE is True:
compressor = LLMChainExtractor.from_llm(llm=self.llm)
compression_retriever = ContextualCompressionRetrieverWrapper(
base_compressor=compressor, base_retriever=mq_retriever
)
# 开启开关就使用压缩检索器
retrievers.append(compression_retriever)
weights.append(0.5)
logger.info(f'已启用 ContextualCompressionRetriever')
else:
# 关闭开关就使用多路召回检索器
retrievers.append(mq_retriever)
weights.append(0.5)
logger.info(f'已启用 MultiQueryRetriever')
# Step3:创建一个 ES 检索器
if settings.ELASTIC_ENABLE_ES is True:
es_retriever = ElasticsearchRetriever()
retrievers.append(es_retriever)
weights.append(0.5)
logger.info(f'已启用 ElasticsearchRetriever')
# 使用集成检索器,将所有启用的检索器集合在一起
ensemble_retriever = EnsembleRetriever(retrievers=retrievers, weights=weights)
return ensemble_retriever说明:
- 首先,我们创建一个空的检索器列表,用于存储启用的检索器。
- 其次,创建一个
MultiQueryRetrieverWrapper,用于将ES检索器与多路召回检索器集成。 - 然后,通过
ContextualCompressionRetrieverWrapper,为多路检索器添加上下文压缩功能。 - 最后,将检索器列表与权重列表传入集成检索器,完成集成。
此处,MultiQueryRetrieverWrapper 和 ContextualCompressionRetrieverWrapper 分别是基于
MultiQueryRetriever和ContextualCompressionRetriever进一步封装实现的,在3、中会详细介绍。
2、检索器增加上下文重排
对之前实现的ElasticsearchRetriever增加上下文重排功能,具体代码如下:
优化代码文件:app/rag/retrievers.py
class ElasticsearchRetriever(BaseRetriever):
def _get_relevant_documents(self, query: str, ) -> List[Document]:
"""Return the first k documents from the list of documents"""
es_connector = ElasticsearchDB()
query_result = es_connector.search(query)
# 增加长上下文重排序
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(query_result)
# logger.info(f"ElasticSearch检索到的原始文档:")
# for poriginal in query_result:
# logger.info(f"{poriginal}")
logger.info(f"ElasticSearch检索重排后的文档:")
for preordered in reordered_docs:
logger.info(f"{preordered}")
logger.info(f"ElasticSearch检索到资料文件个数:{len(query_result)}")
if reordered_docs:
return [Document(page_content=doc) for doc in reordered_docs]
return []3、优化日志输出
由于 MultiQueryRetriever 是langchain已经封装好的检索器,如果我们需要在其基础上增加一些功能,比如:增加日志,我们需要对其进行重写,具体方法:
重写MultiQueryRetriever
创建一个新的Class MultiQueryRetrieverWrapper,继承 MultiQueryRetriever ,重写 _get_relevant_documents 方法,具体代码如下:
class MultiQueryRetrieverWrapper(MultiQueryRetriever):
def _get_relevant_documents(
self,
query: str,
*,
run_manager: CallbackManagerForRetrieverRun,
) -> List[Document]:
"""
对MultiQueryRetriever进行重写,增加日志打印
"""
queries = self.generate_queries(query, run_manager)
if self.include_original:
queries.append(query)
documents = self.retrieve_documents(queries, run_manager)
# 增加长上下文重排序
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(documents)
logger.info(f'MultiQuery生成的检索语句:')
for q in queries:
logger.info(f"{q}")
logger.info(f'MultiQuery检索到的资料文件:')
for doc in documents:
logger.info(f"{doc}")
logger.info(f"MultiQuery检索到资料文件个数:{len(documents)}")
return self.unique_union(reordered_docs)重写ContextualCompressionRetriever
创建一个新的Class ContextualCompressionRetrieverWrapper,继承 ContextualCompressionRetriever ,重写 _get_relevant_documents 方法,具体代码如下:
class ContextualCompressionRetrieverWrapper(ContextualCompressionRetriever):
from typing import Any, List
def _get_relevant_documents(
self,
query: str,
*,
run_manager: CallbackManagerForRetrieverRun,
**kwargs: Any,
) -> List[Document]:
"""
对ContextualCompressionRetriever进行重写,增加日志打印
"""
docs = self.base_retriever.invoke(
query, config={"callbacks": run_manager.get_child()}, **kwargs
)
if docs:
compressed_docs = self.base_compressor.compress_documents(
docs, query, callbacks=run_manager.get_child()
)
logger.info(f'压缩后的文档长度:{len(compressed_docs)}')
logger.info(f'压缩后的文档:{compressed_docs}')
return list(compressed_docs)
else:
return []4、给Agent增加更多工具
实现工具函数:计算股票年化收益率
代码文件:app/finance_bot_ex.py
# 定义股票年化收益率计算函数
# 年化收益率定义为:((有记录的一年的最终收盘价-有记录的一年的年初当天开盘价)/有记录的一年的当天开盘价)* 100%。
def calculate_stock_annualized_return(final_closing_price: float, initial_opening_price: float) -> float:
"""
计算股票年化收益率
"""
annualized_return = ((final_closing_price - initial_opening_price) / initial_opening_price) * 100
return annualized_return
Agent增加工具
在init_agent函数中,增加工具函数,具体代码如下:
代码优化文件:app/finance_bot_ex.py
def init_agent(self):
# 初始化 RAG 工具
retriever_tool = self.init_rag_tools()
# 初始化 SQL 工具
sql_tools = self.init_sql_tool(settings.SQLDATABASE_URI)
# 创建系统Prompt提示语
system_prompt = self.create_sys_prompt()
# 创建Agent
agent_executor = create_react_agent(
self.chat,
tools=[
get_datetime,
calculate_stock_annualized_return, # 增加自定义的计算年化收益率工具
retriever_tool] + sql_tools,
state_modifier=system_prompt,
checkpointer=MemorySaver()
# state_modifier=modify_state_messages,
)
return agent_executor4、验证测试
完成上述检索器的优化之后,我们使用test_framework.py进行验证,验证结果如下:
问题1解决效果
-
用户输入问题,触发RAG检索的
MultiQueryRetriever检索器
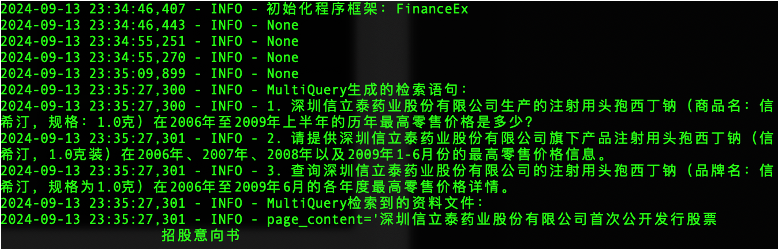
-
通过上下文压缩之后,原本
MultiQueryRetriever检索到的资料文件数量由12个减少到1个。
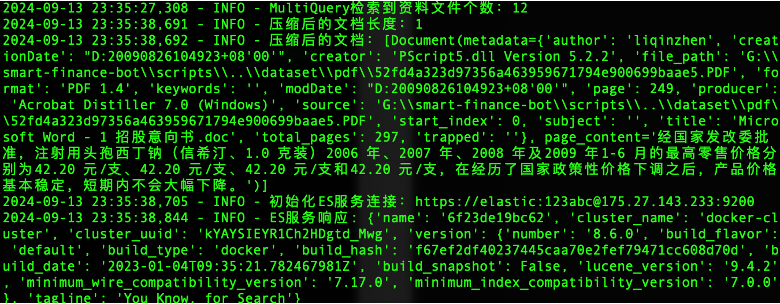
-
通过上下文压缩之后,原本
ElasticsearchRetriever检索到的资料文件数量由3个减少到2个。

-
最后,将两个检索器的结果进行整合后,大模型给出最终答案。

问题2解决效果
-
我们输入问题:计算代码000798股票在2020年的年化收益率,保留两位小数。
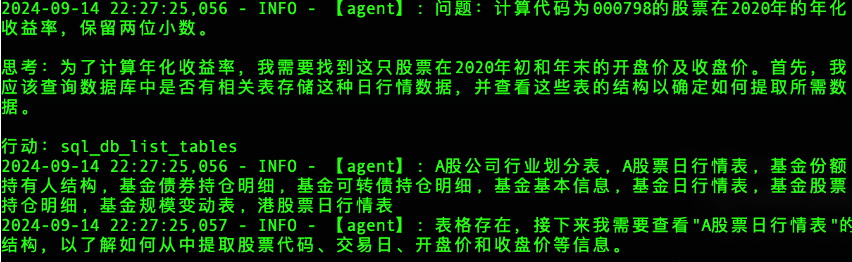
-
Agent分析问题后,形成SQL查询语句:获取2020年第一天开盘价以及2020年最后一天的收盘价

-
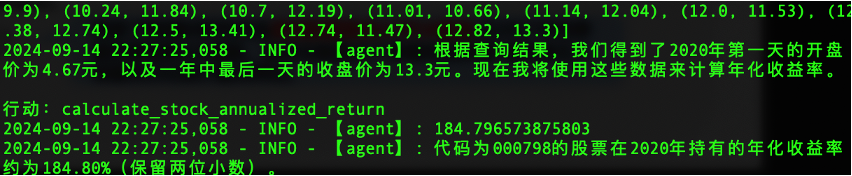
Agent获得开盘价和收盘价之后,调用我们提供的
calculate_stock_annualized_return函数计算年化收益率,并返回结果。
结束语
基于Agent的金融问答系统系列文章在此告一段落了。
在这个项目中,我们不只利用AI技术完成了项目课题,其中也不乏应用了软件工程的一些方法论,而最为重要的是:我们解决了一个又一个的问题。
最后,附带一张黑神话悟空的图片,希望看到此篇文章的你我一同共勉。

附录
欢迎查看该系列的其他文章:
- 【项目实战】基于Agent的金融问答系统:项目简介
- 【项目实战】基于Agent的金融问答系统:RAG检索模块初建成
- 【项目实战】基于Agent的金融问答系统:Agent框架的构建
- 【项目实战】基于Agent的金融问答系统:前后端流程打通
- 【项目实战】基于Agent的金融问答系统:代码重构
- 【项目实战】基于Agent的金融问答系统:RAG的检索增强之ElasticSearch
- 【项目实战】基于Agent的金融问答系统:RAG的检索增强之上下文重排和压缩
欢迎关注公众号以获得最新的文章和新闻



