前言
随着2024年5月14日GPT-4o的发布,多模态大模型逐渐成为行业热点,国内各大厂商阿里、百度、智谱也相继发布了自己的多模态大模型。本章内容,我们将从多模态的体验感受开始,逐步了解多模态大模型的架构组成、训练数据构成,最后搭建一个多模态大模型。
大视觉模型的体验感受
为了对大模型有一个初步的了解,我们使用阿里最新公布的通义千问VL-Max,感受一下多模态大模型的能力。
场景一:图像识别
首先,我们搜索一个关于导弹的图片(相信有很多人跟我一样,对我国国防力量感兴趣,但是不知道具体的武器型号)。
接着,我们在阿里云百炼平台,选择通义千问VL-Max模型,上传图片并提问。
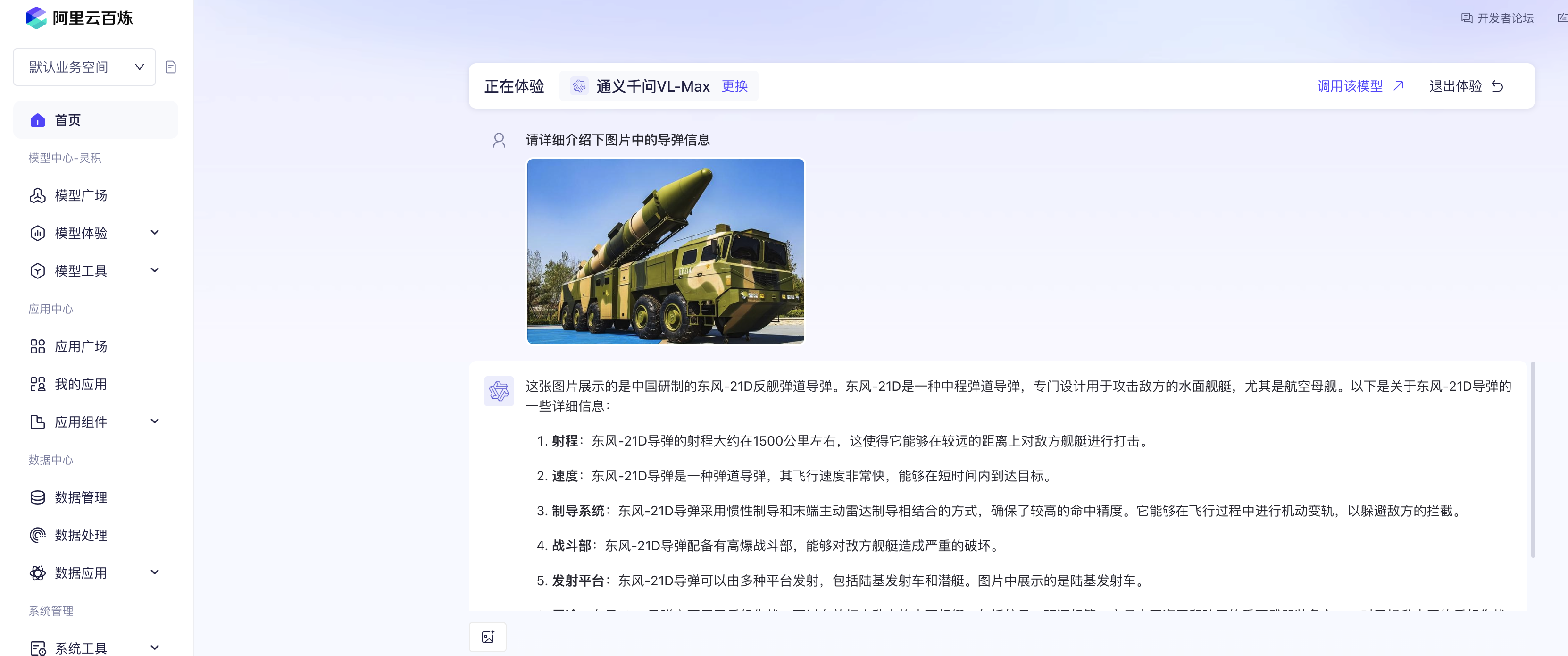
如上图所示,多模态大模型很快就识别出了该导弹的具体型号并且给出了相关的介绍。
场景二:OCR文字识别(基本文字)
OCR文字识别本身其实是一项非常成熟的技术了,但是在大模型的加持下,我们看看其能力如何。
首先,我们在搜索引擎里随意搜索一张火车票。
接着,我们在阿里云百炼平台上,上传图片并提问,提问内容我们不仅限于文字识别,而是增加一些推理内容,例如:
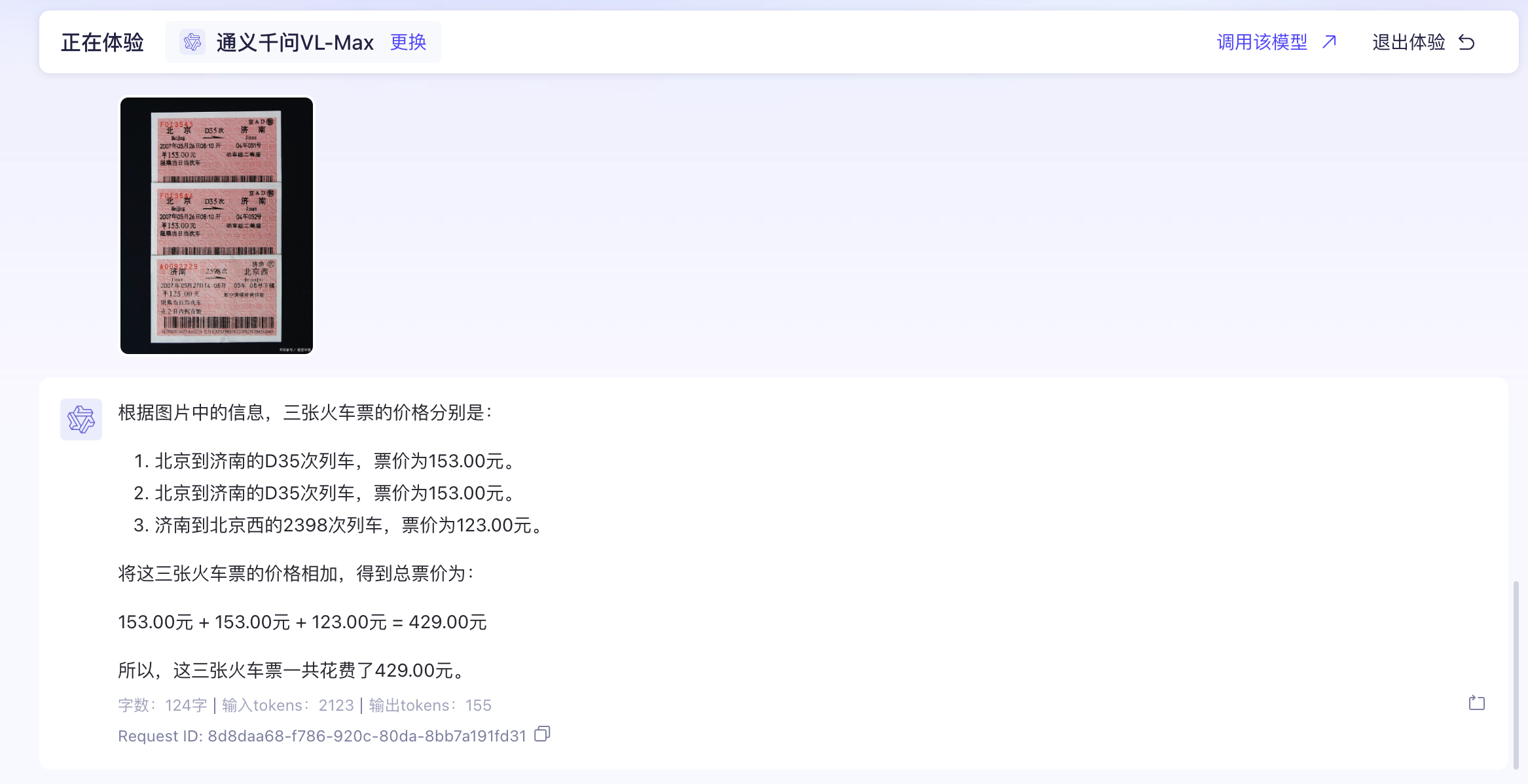
可以看到,多模态大模型轻易地就识别出了图片中火车票的金额,并且按照题目要求自动计算了总共花费的金额。
场景三:OCR文字识别+推理
场景二是一个简单的OCR识别,接下来我们试一个OCR识别+推理的例子。
首先,我们在搜索引擎里搜索一张医院的导诊照片,如图:

接着,我们上传图片并提问一个带有推理性的问题,例如:“我感冒了,请根据图片提示,告诉我具体看病是怎样的流程。”
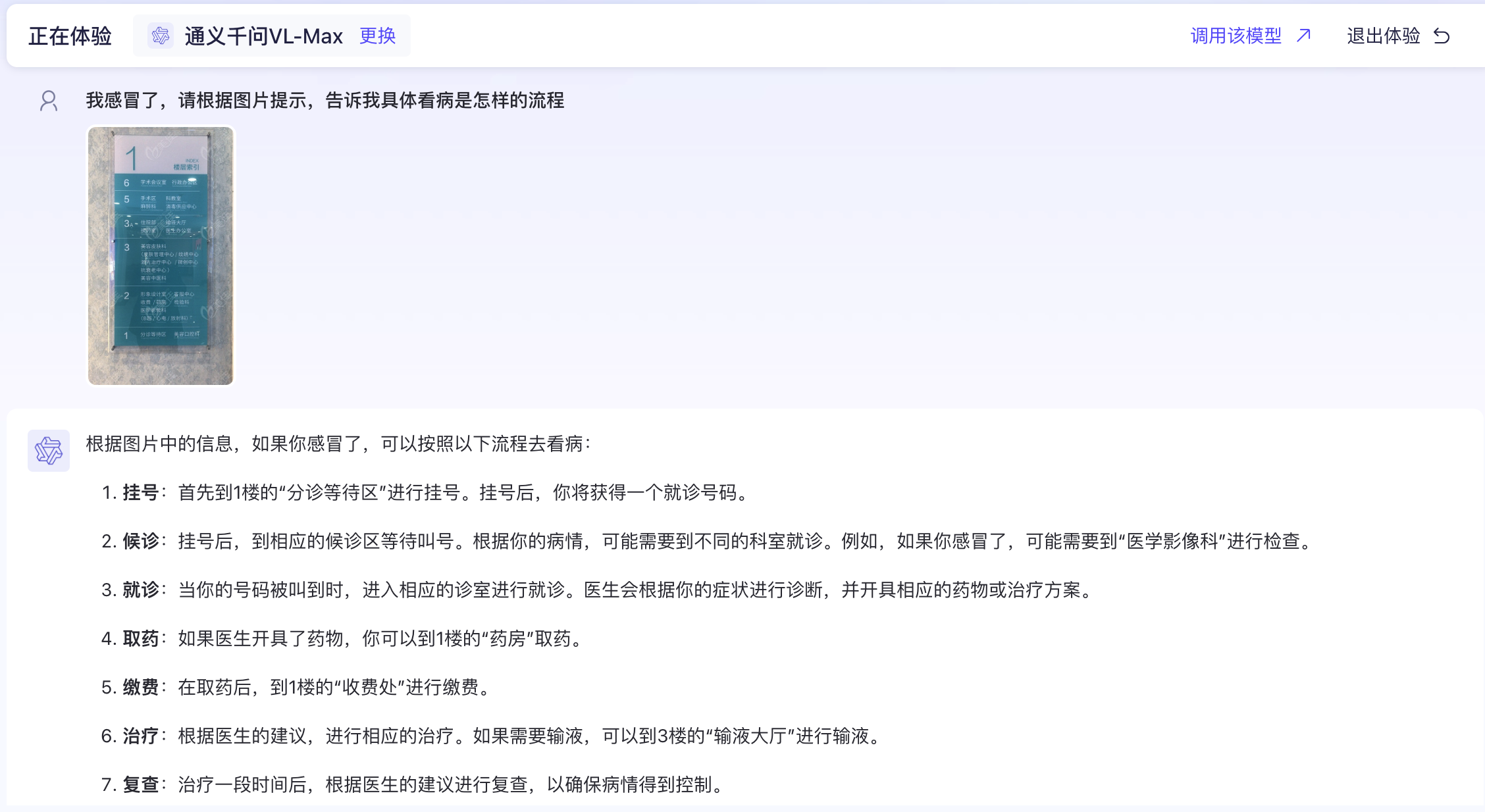
通过上图可以看到,多模态大模型不仅准确识别出图片中各个科室的位置,还借助大模型的推理能力,针对我的提问给出了相应的流程。
场景四:OCR文字识别(代码识别并改错)
接下来,我们试验一个多模态大模型识别代码错误并修改的示例。
首先,我们对一段有错误的代码进行截图,截图内容如下:
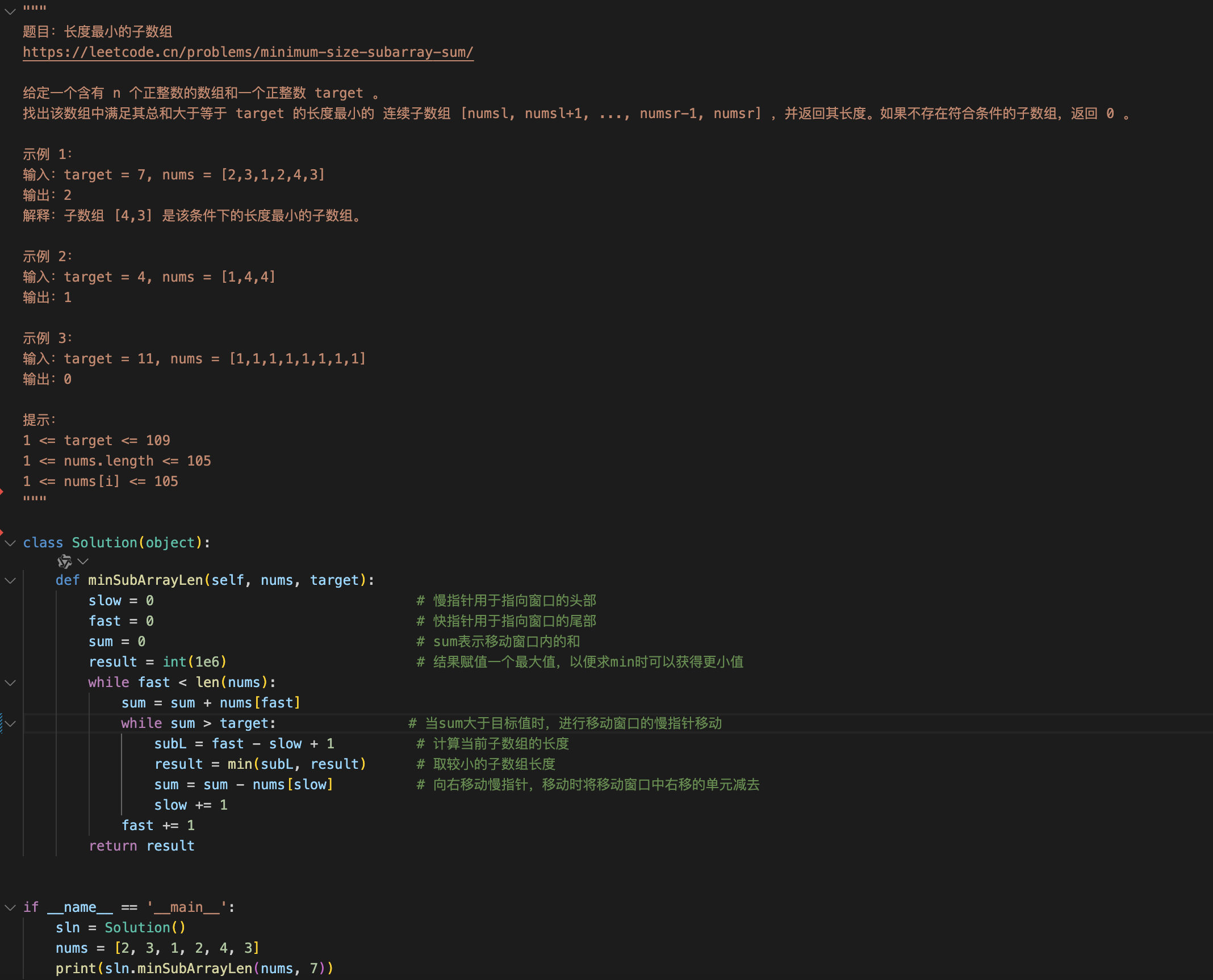
接着,我们上传图片给多模态大模型并且让大模型找到错误并修改。
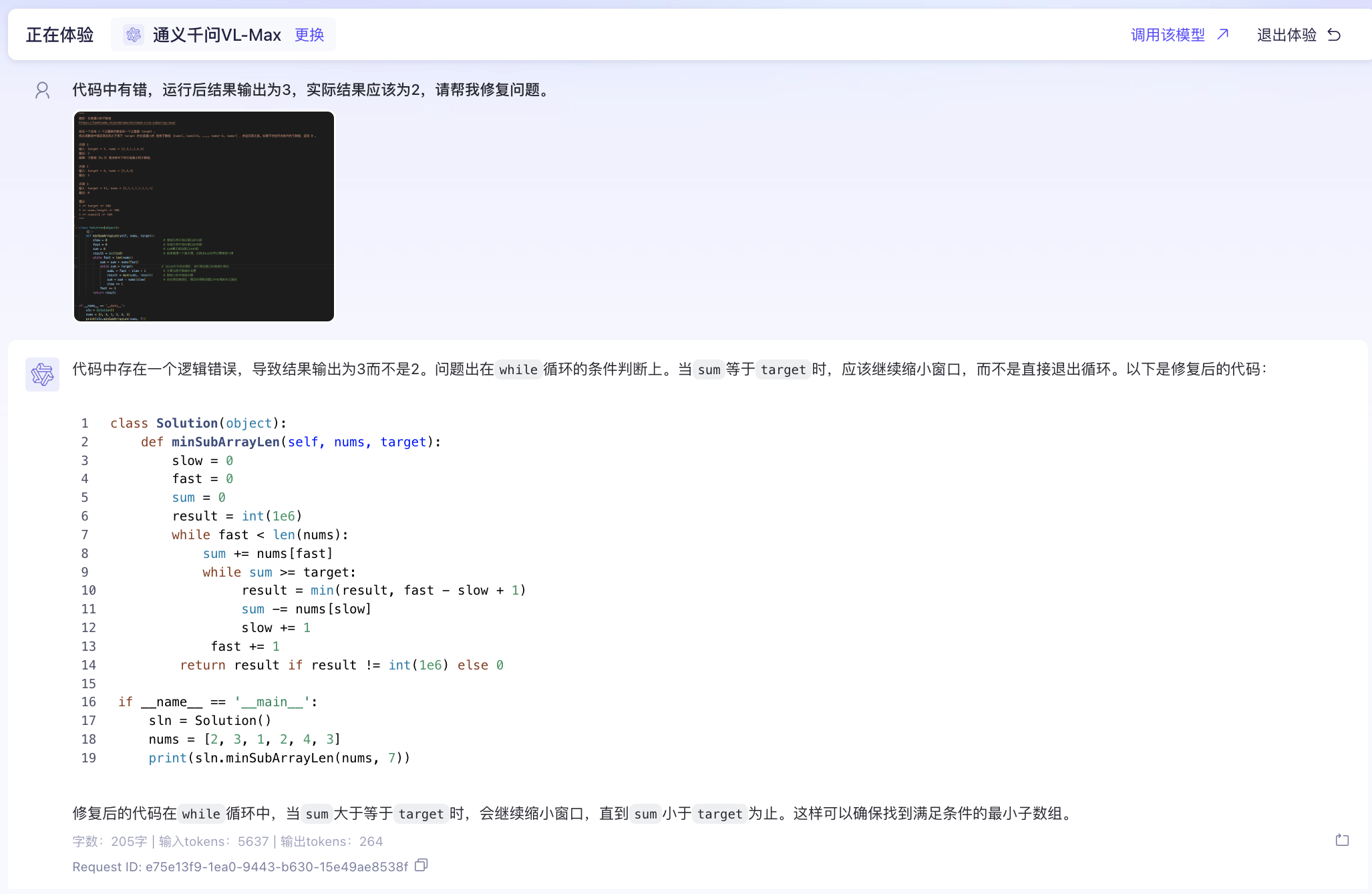
通过上图可以看到,多模态大模型准确地识别出代码中的错误并且给出了正确的代码片段。
场景五:目标检测
在【课程总结】Day13(上):使用YOLO进行目标检测学习中,我们对图片中的目标进行检测的话,一般需要准备大量的数据然后借助YOLO训练,才可以识别出目标。那么,如果是多模态大模型会怎样呢:
首先,我们搜索一张"七龙珠的全家福图片"

接着,我们上传图片给多模态大模型并且让其圈出人造人18号的位置。

然后,我们使用Python代码对识别结果进行绘图。
目前使用的通义千问多模态大模型还无法输出图片,所以我们此处通过Python代码手动绘制。
from PIL import Image, ImageDraw, ImageFont
# 打开图片
image_path = '七龙珠全家福.jpg' # 替换为你的图片路径
image = Image.open(image_path)
# 创建一个可绘制的对象
draw = ImageDraw.Draw(image)
# 定义多个矩形框的坐标和对应的人物名称
boxes = [
((20, 200, 100, 970), "人造人18号"),
]
# 绘制矩形框
for (x1, y1, x2, y2), name in boxes:
# 绘制矩形框
draw.rectangle([x1, y1, x2, y2], outline="red", width=3)
# 标注名称
draw.text((x1, y1), name, fill="red")
# 保存或显示图片
image.show() # 显示图片运行结果:

在没有任何训练的情况下,我们只是提供图片给多模态大模型并给出我们的要求,它就能较为准确地识别出图片中人物的位置。
小结
通过以上多个场景的试用体验,我们可以看到:大视觉模型拥有看懂图像的能力,大语言模型拥有强大推理能力,将这两者相结合的多模态大模型,可以开辟一个新的领域。
多模态大模型介绍
简介
多模态大模型是一种能够处理和理解多种数据类型(模态)的人工智能模型。这些模态通常包括文本、图像、音频和视频等。
发展历史
1、早期阶段(2010年代初)
- 多模态学习的研究起步于对不同模态数据的独立处理,如图像分类和文本处理。
- 研究者们开始探索如何将文本与图像结合,以提高任务的准确性。
2、深度学习兴起(2010年代中期)
- 随着深度学习技术的快速发展,卷积神经网络(CNN)和循环神经网络(RNN)被广泛应用于图像和文本处理。
- 研究者提出了多模态嵌入(embedding)方法,将不同模态的数据映射到同一空间中。
3、Transformer架构的引入(2017年及以后)
- Transformer架构的出现革命性地改变了自然语言处理和计算机视觉领域。
- 结合Transformer的多模态模型(如CLIP、DALL-E等)开始出现,能够同时处理图像和文本。
4、当前阶段(2020年代)
- 多模态大模型如GPT-4、MUM、Flamingo等相继发布,这些模型在多个模态上表现出色,能够进行复杂的任务,如图像描述、文本生成、问答等。
- 研究者们关注模型的可解释性和公平性,以及如何在实际应用中更好地利用这些模型。
多模态大模型架构组成
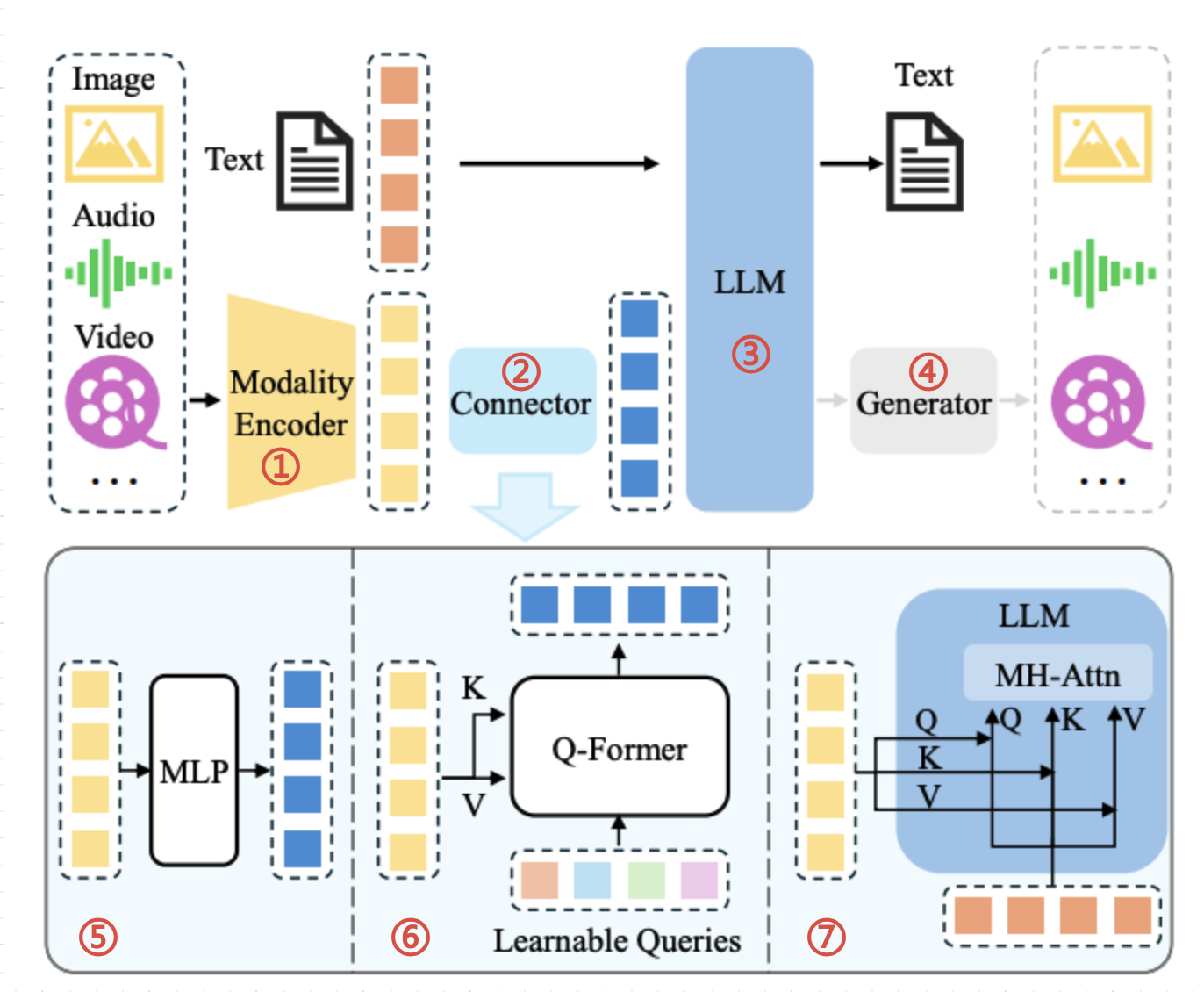
模态编码器(图①)
- 作用:是对每种模态(图片、音频、视频)的数据进行特征提取和编码,将原始输入转换为高维特征表示。
- 说明:
- 特征提取:不同模态的数据使用不同的网络架构进行特征提取。例如:
- 嵌入层:每种模态的特征经过处理后,都会被映射到一个统一的嵌入空间中,这样不同模态的特征可以在同一空间内进行比较和融合。
模态连接器(图②)
- 作用:将模态编码器转换的中间表达,通过Connector模块,将中间表达转换为与大语言模型相同的表达
- 说明:模态连接器是训练形成的,它有三种方式:
MLP 基于投影的连接器(图⑤)
简述:
多层感知机将编码器输出的特征投影到与LLM的词嵌入相同的维度空间,使得特征可以直接与文本令牌一起被匹配。
原理:
- 输入特征:将来自不同模态的特征向量拼接在一起,形成一个大的特征向量。
- 层级结构:通过多个全连接层(也称为线性层)对拼接后的特征进行处理。每个全连接层后通常会加上激活函数(如ReLU)以引入非线性。
- 输出:经过多层处理后,最终输出一个融合特征向量,可以用于后续的任务(如分类或生成)。
Q-Former 基于查询的连接器(图⑥)
简述:使用一组可学习的查询令牌来动态地从编码器输出的特征中提取信息。
原理:
- 查询、键、值:Q-Former 利用查询(Query)、键(Key)和值(Value)来进行特征融合。每种模态的特征被映射为查询、键和值。
- 自注意力机制:通过自注意力机制,Q-Former 可以动态地为不同模态的特征分配不同的权重,从而更好地捕捉模态之间的关系。
- 融合过程:对于每一个查询,计算其与所有键的相似度,并根据相似度加权求和对应的值,生成融合后的特征表示。
MH-Attn 基于融合的连接器(图⑦)
简述:在LLM内部实现特征级别融合,允许文本特征和视觉特征在模型内部进行更深入的交互和整合。
模态生成器(图④)
- 可选组件,它可以附加到LLM上,用于生成除文本之外的其他模态,如:图片、音频、视频等
多模态大模型训练
与大语言模型的训练过程类似《【课程总结】day24(上):大模型三阶段训练方法(LLaMa Factory)》,多模态大模型也有 预训练(Pre-train)、微调(fine-tune)、偏好对齐(RLHF) 三个过程。
第一阶段:预训练(Pre-train)
预训练目的:
- 对齐模态
- 提供世界知识
预训练模板:
Input: <image>
Response: {caption}预训练数据集:
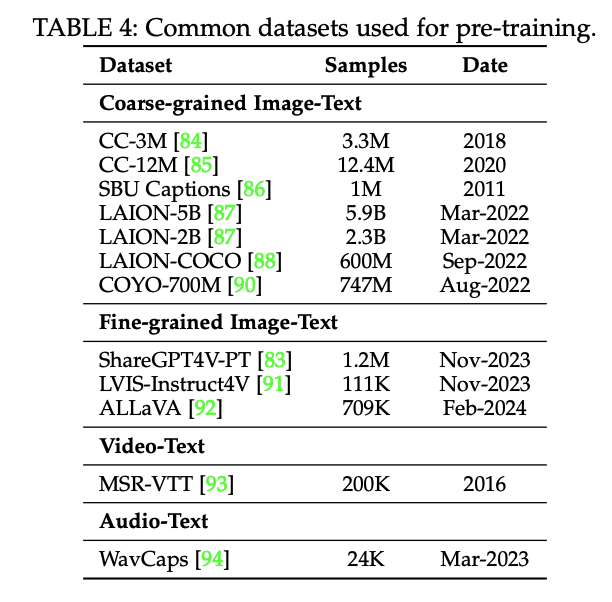
通过上图可以看到,预训练的数据集类型挺多的,有 粗粒度的图像-文字数据(coarse-grained image-text)、细粒度的图像-文字数据(fine-grained image-text)、视频-文字数据(video-text)、音频-文字数据(audio-text)等。
为了对以上数据集有个直观了解,我们挑几种数据集查看:
粗粒度图像-文字数据集一览
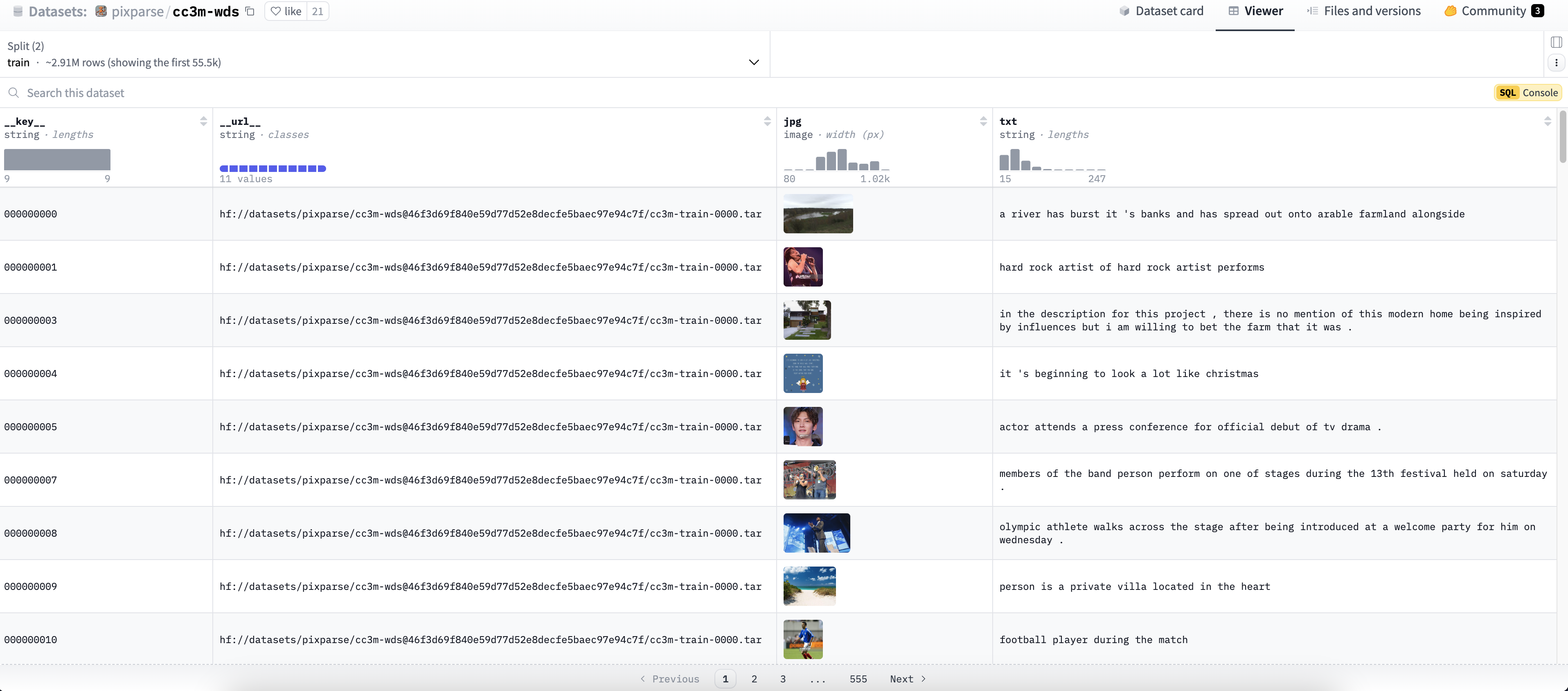
数据集名称:CC3M
数据集地址:https://huggingface.co/datasets/pixparse/cc3m-wds
数据集说明:该数据集主要是由图片和对图片的描述组成。
数据集截图:
细粒度图像-文字数据集一览
数据集名称:SHAREgpt4v-pt
数据集地址:https://huggingface.co/datasets/Lin-Chen/ShareGPT4V/viewer/ShareGPT4V
数据集说明:SHAREgpt4v-pt 数据集是一个专门用于多模态大模型训练和评估的数据集,其数据集有非常详细的描述,以下是SHAREgpt4v-pt与COCO描述的对比。

数据集截图:
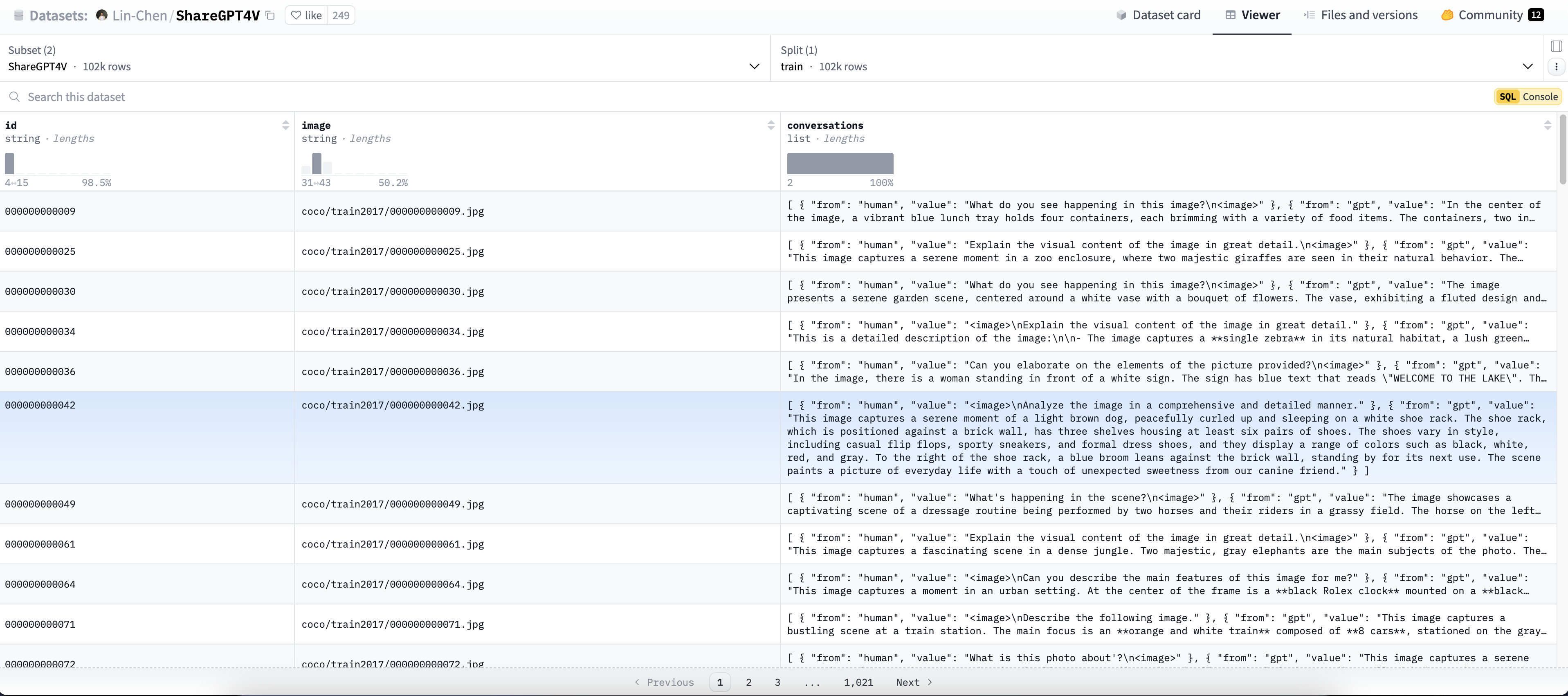
视频-文字数据集一览
数据集名称:MSRVTT
数据集地址:https://huggingface.co/datasets/AlexZigma/msr-vtt
数据集说明:MSRVTT 是一个视频-文本数据集,它主要内容有视频地址、视频起始时间、结束时间以及视频帧文字描述构成。
数据集截图:
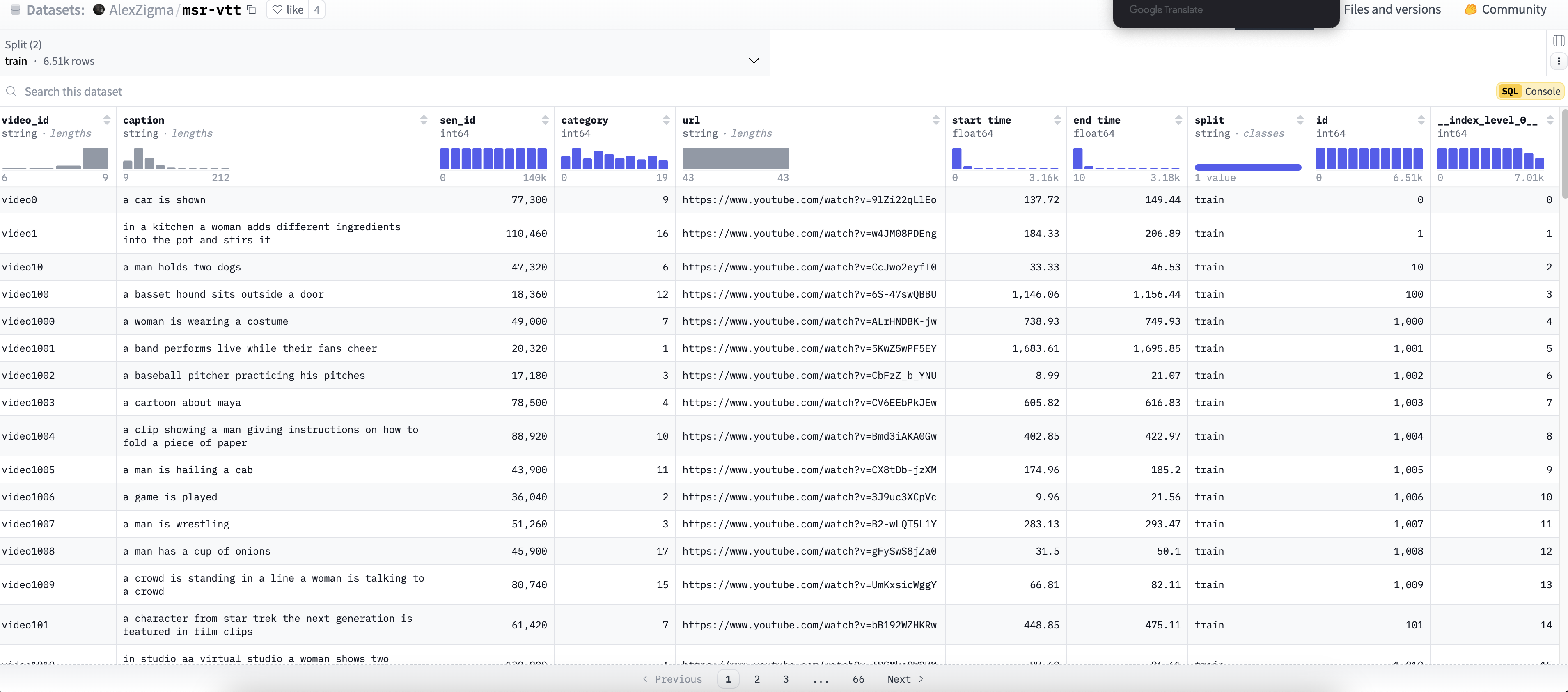
其中video0的视频具体内容为:

音频-文字数据集一览
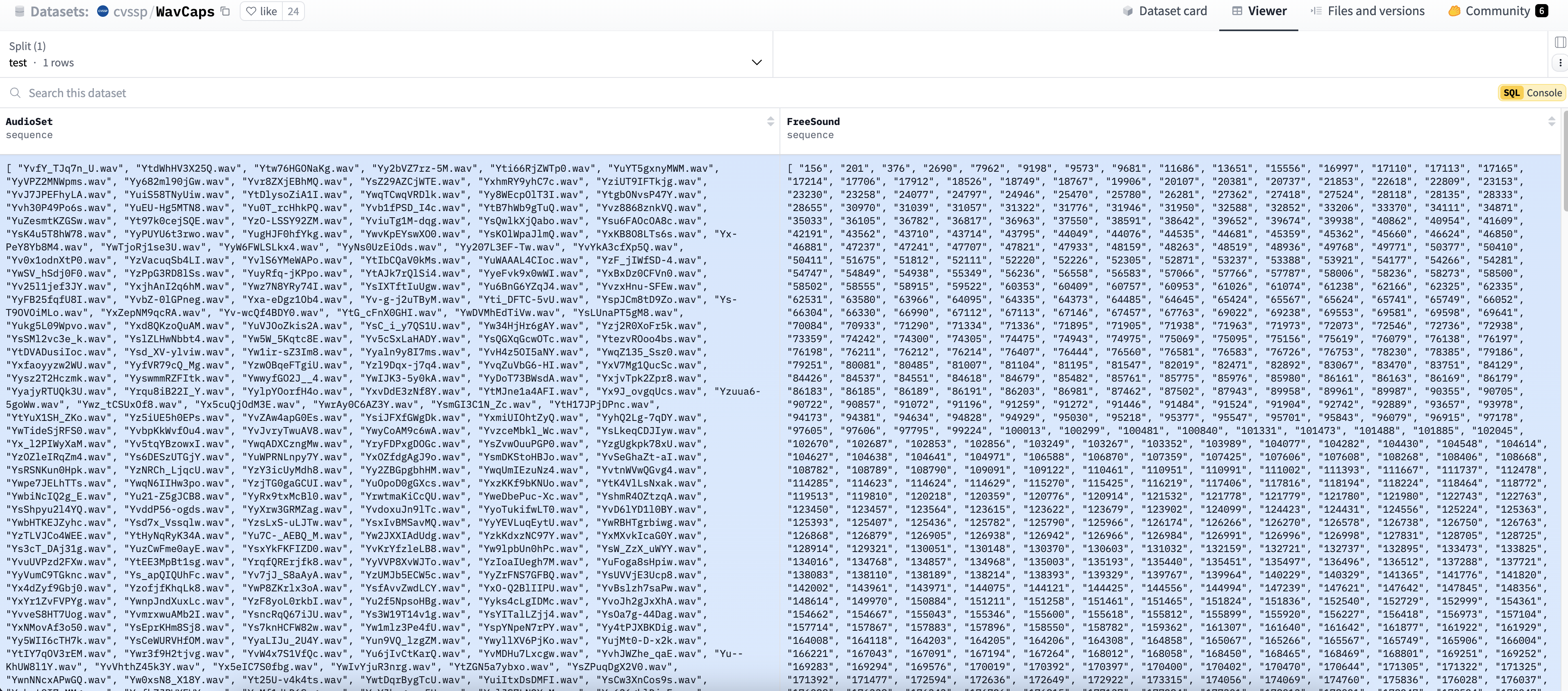
数据集名称:wavCaps
数据集地址:https://huggingface.co/datasets/cvssp/WavCaps?row=0
数据集说明:wavCaps 是一个音频-文本数据集,它主要包含FreeSound 数据库具体音频片段、对应的描述文字信息编号。
FreeSound 是一个开放的音频共享平台,用户可以上传和下载各种类型的音频文件,涵盖自然声音、环境音效、音乐片段等。
数据集截图:
第二阶段:微调(fine-tune)
微调目的:
- 让模型更好地理解用户的指令并完成所需的任务
- 泛化能力,少(零)样本推理
微调模板:
Instruction: <instruction>
Input: {<image>, <text>}
Response: <output>微调数据集:

对上述微调数据集,我们挑选两个典型的进行了解。
LLaVa-Instruct
数据集名称:LLaVa-Instruct
数据集地址:https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
数据集说明:LLaVa-Instruct 数据集是一个用于训练和评估多模态模型的数据集,尤其关注于视觉和语言之间的交互。它旨在通过提供指令和相应的视觉内容,帮助模型理解和生成与视觉信息相关的文本。
数据集截图:
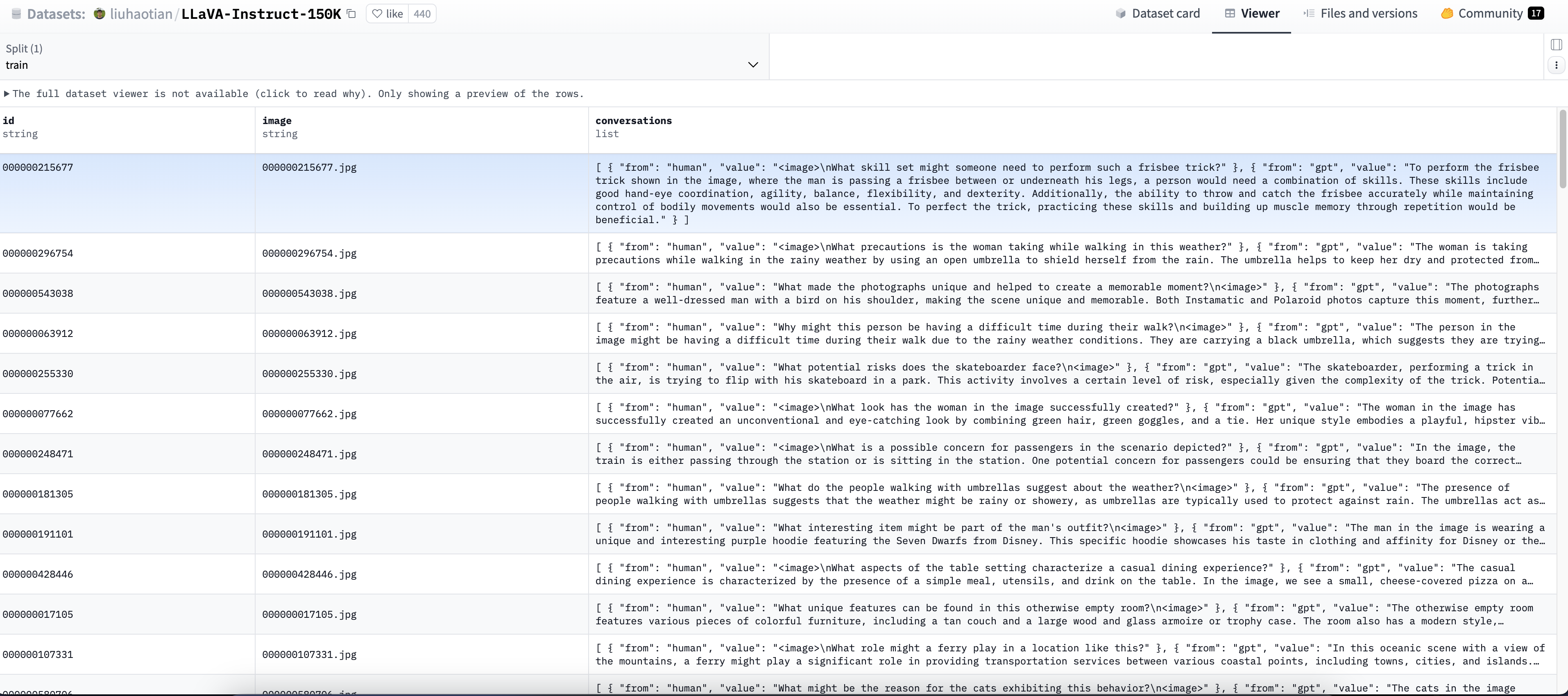
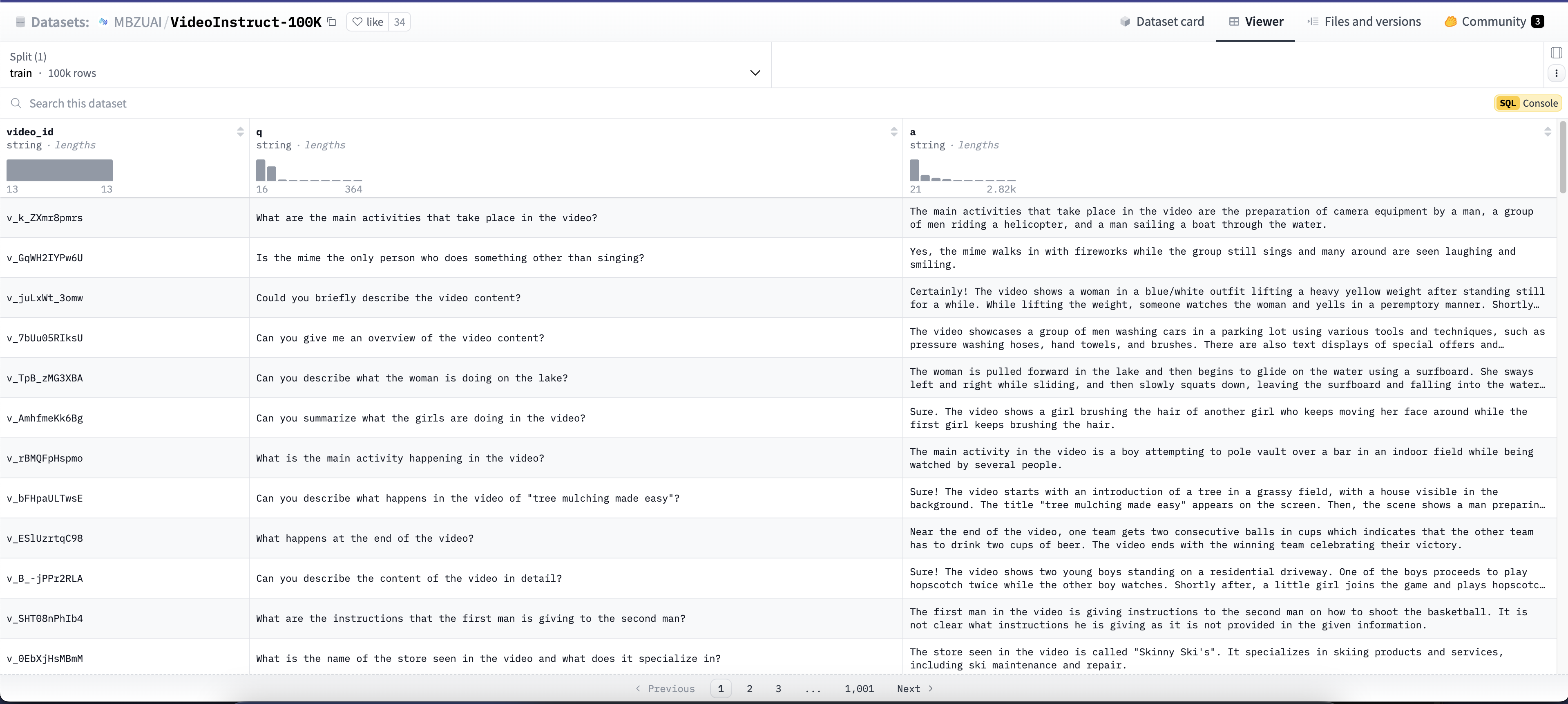
Video-ChatGPT
数据集名称:Video-ChatGPT
数据集地址:https://huggingface.co/datasets/MBZUAI/VideoInstruct-100K
数据集说明:Video-ChatGPT 数据集是一个专门用于视频理解和对话生成的多模态数据集,其数据集主要是由视频id、视频的问题和视频问题回答三个部分组成。
数据集截图:
Clotho
数据集名称:Clotho
数据集地址:https://paperswithcode.com/dataset/clotho
数据集说明:一个用于音频理解和生成的多模态数据集,特别关注于音频描述的生成和音频内容的理解。
数据集截图:
(由于网络不稳定,暂未找到对应数据集的具体内容)
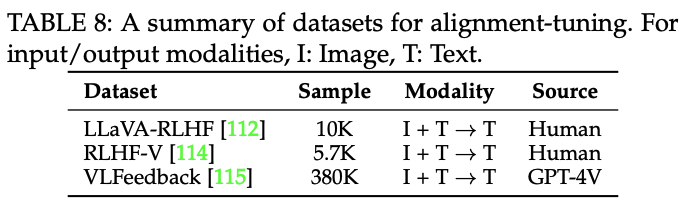
第三阶段:偏好对齐
偏好对齐目的:
- 对齐微调数据
偏好对齐数据集:




1人评论了“【课程总结】day31:多模态大模型初步了解”
赞!