文章来源于互联网:刚刚,三名谷歌Vision Transformer作者官宣加入OpenAI
三人是紧密的合作伙伴。
也有人猜测,OpenAI 之所以在苏黎世设立办事处,是因为三个人都不愿意搬家。



-
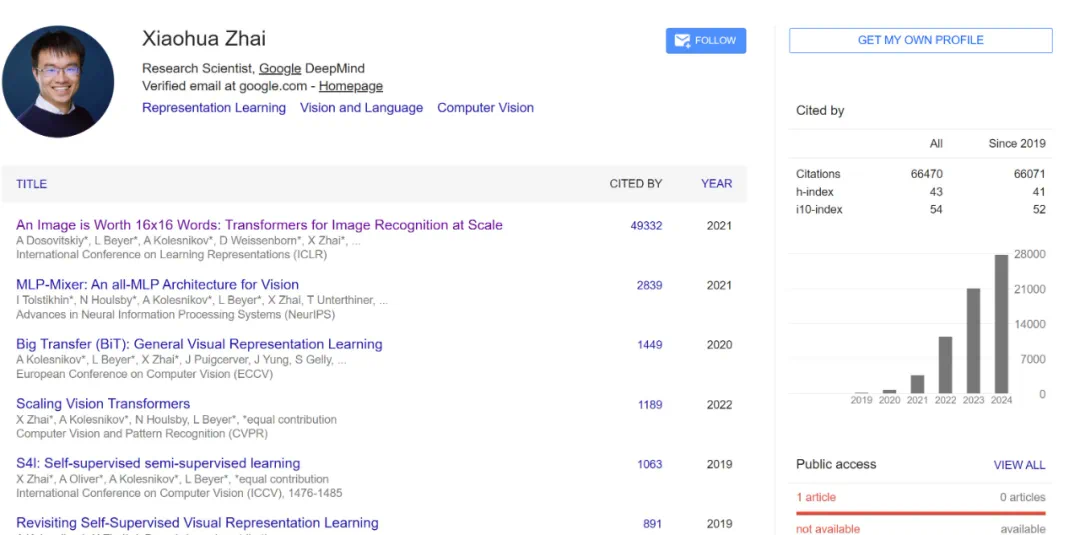
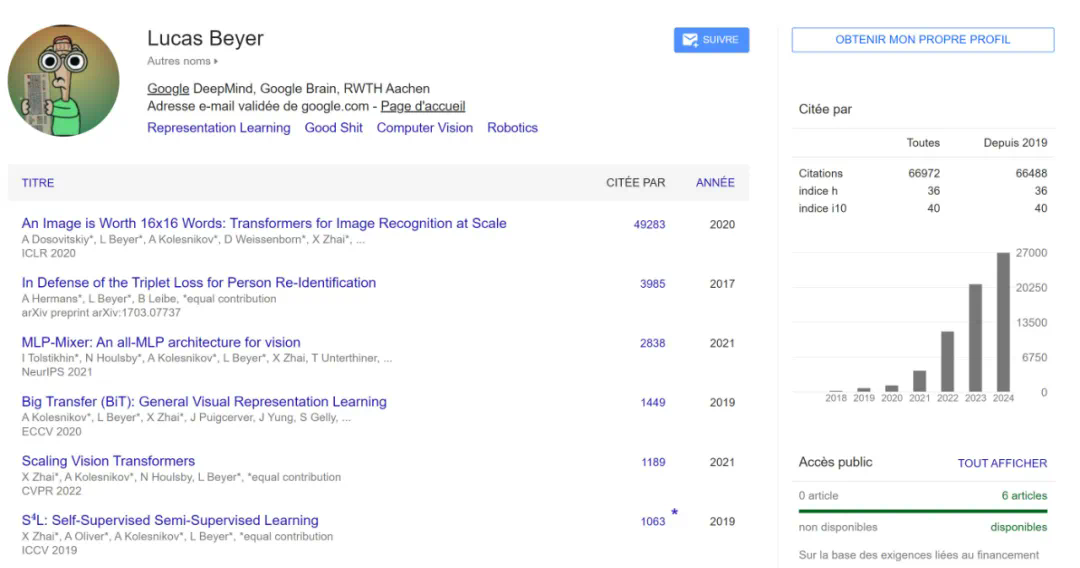
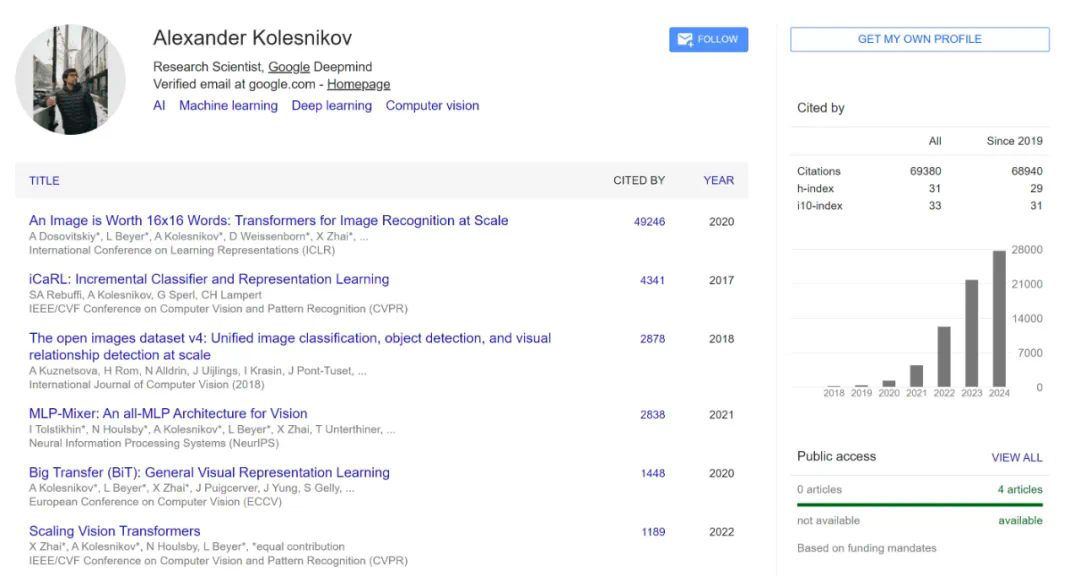
论文标题:An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale -
论文地址:https://arxiv.org/pdf/2010.11929 -
项目地址:https://github.com/google-research/vision_transformer


-
论文标题:Scaling Vision Transformers -
论文地址:https://arxiv.org/pdf/2106.04560
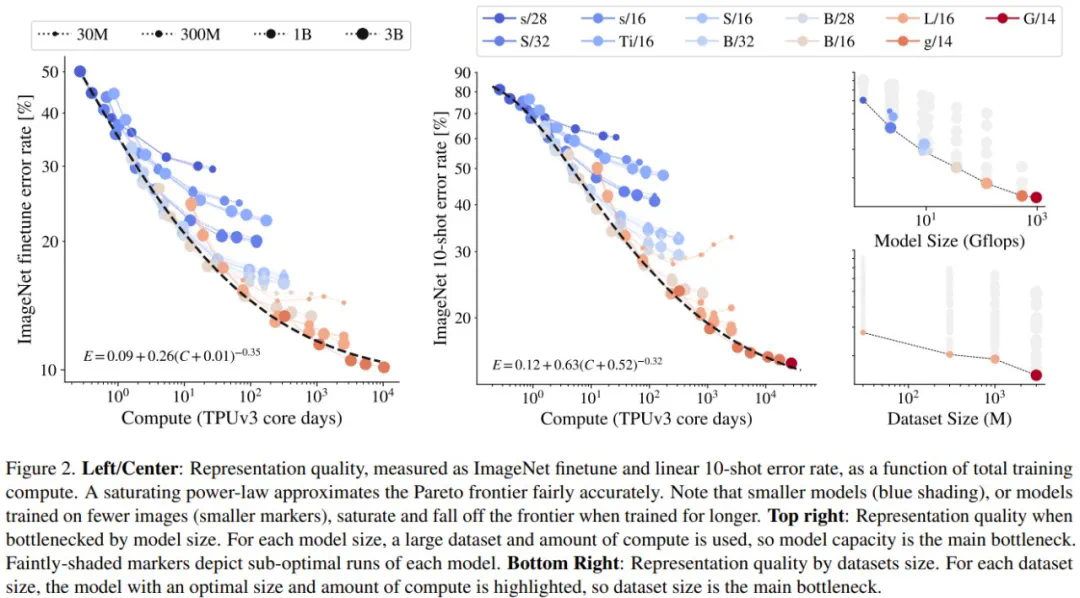
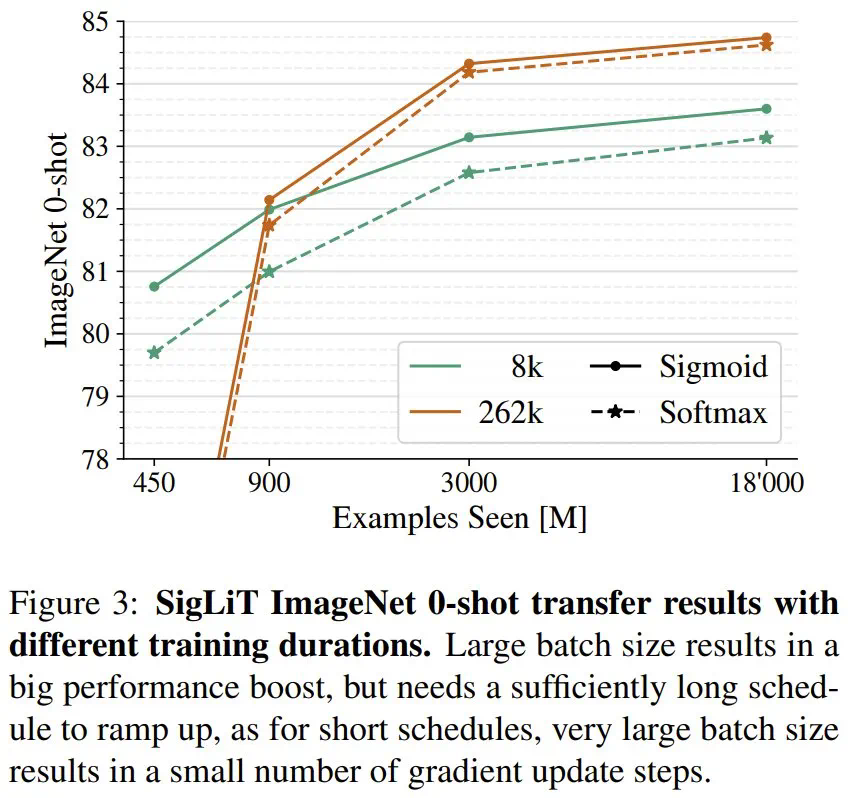
-
UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes,该论文提出了一种建模多样化计算机视觉任务的统一方法。该方法通过组合使用一个基础模型和一个语言模型实现了互相增益,从而在全景分割、深度预测和图像着色上取得了不错的效果。 -
Tuning computer vision models with task rewards,这项研究展示了强化学习在多种计算机视觉任务上的有效性,为多模态模型的对齐研究做出了贡献。 -
JetFormer: An Autoregressive Generative Model of Raw Images and Text,这是上个月底才刚刚发布的新研究成果,其中提出了一种创新的端到端多模态生成模型,通过结合归一化流和自回归 Transformer,以及新的噪声课程学习方法,实现了无需预训练组件的高质量图像和文本联合生成,并取得了可与现有方法竞争的性能。

