
前言
由于使用 lm_evaluation_harness 工具评测时,遇到较多复杂的问题不好处理,例如:
- 连接
huggingface下载tokenizer被墙; - 评测
API时需要服务器支持LogProbs等问题 - 源代码较为晦涩难懂,
Readme文档不详细….
导致评测工具的使用成本以及体验不佳,因此我们寻求一款国产的、源码可读性高,文档详细的评测工具:OpenCompass。
简介
OpenCompass 是由上海人工智能实验室推出的开源大模型评测体系,主要特点包括:
- 全能力评估 – 提供50+评测数据集,覆盖语言/知识/推理/创作等七大能力维度
- 多模型支持 – 支持HuggingFace/API等50+主流模型接入,包括LLaMA/GLM/ChatGPT等
- 本土化优势 – 内置文言文理解、法律伦理等中文特色评测维度
- 说明文档全 – 提供了详细的说明文档,包括安装、使用、配置等
仓库地址:https://github.com/open-compass/opencompass
说明文档:https://opencompass.readthedocs.io/zh-cn/latest/get_started/quick_start.html
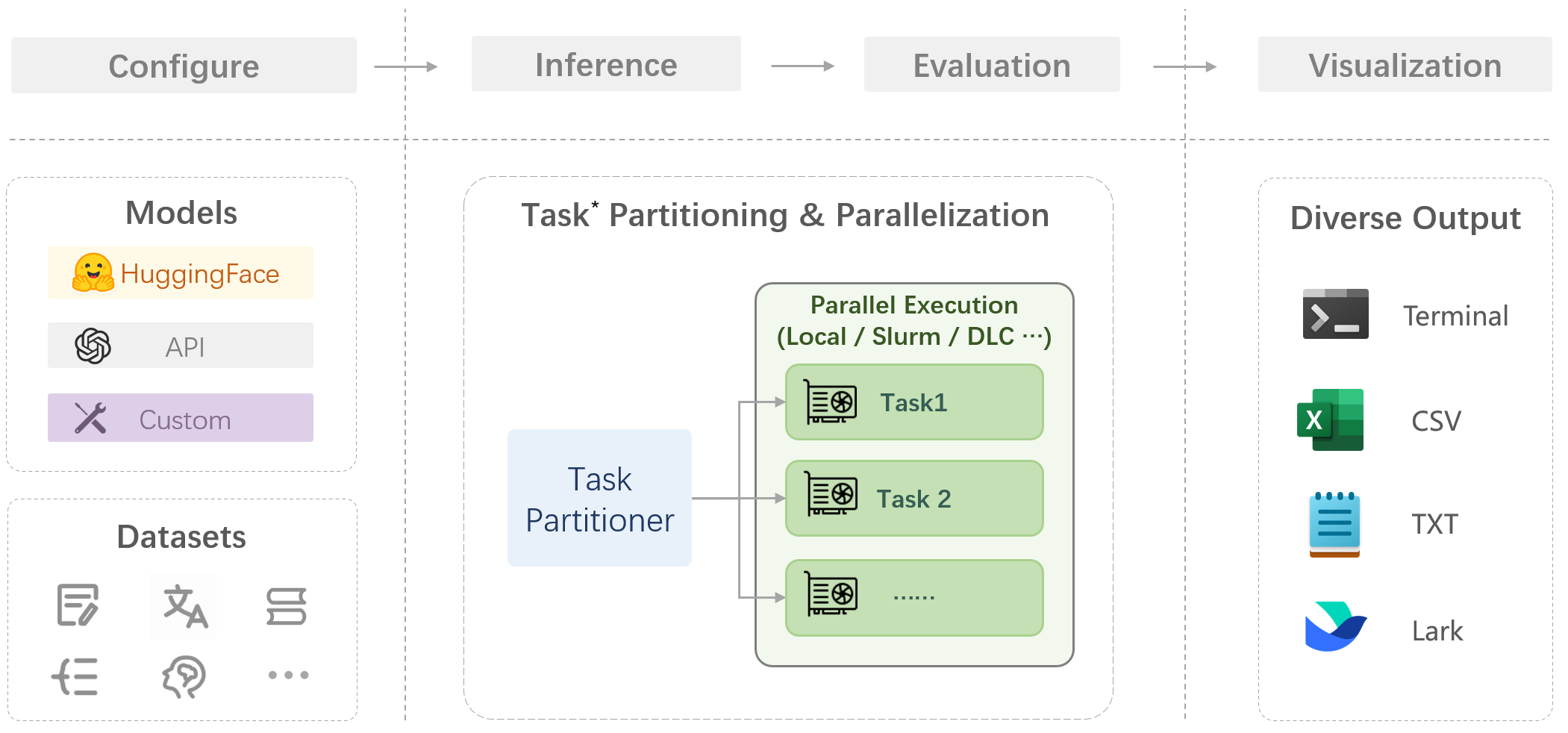
使用方法
1. 创建虚拟环境
conda create --name opencompass python=3.10 -y
conda activate opencompass2. 安装工具
该工具提供 pip install 和 源码 两种安装方式。由于我们后续需要自定义评测模型的 API 以及数据集,所以此处选择源码方式安装。
git clone https://github.com/open-compass/opencompass opencompass
cd opencompass
pip install -e .3. 安装依赖
# 安装sentencepiece
pip install torch sentencepiece protobuf# 安装torch
pip install torch torchvision torchaudio4. 获取API Key
访问Deepseek官网的开发者平台,获取 API Key 以及 API URL。
在本地新建Jupyter Notebook文件,测试API是否可用。
# 测试API可用
from openai import OpenAI
openai_api_key = "sk-fe599*******"
openai_api_base = "https://api.deepseek.com/"
model = "deepseek-chat"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "你是一个很有用的助手。"},
{"role": "user", "content": "中华人民共和国的首都是哪里?"},
]
)
print(chat_response.choices[0].message.content)运行后,API正常返回:
中华人民共和国的首都是北京。北京是中国的政治、文化、国际交往和科技创新中心,承载着中华民族的悠久历史和灿烂文化,同时也是中国共产党中央委员会、全国人民代表大会和国务院等国家最高权力机关的所在地。北京的发展成就充分展示了中国特色社会主义制度的优越性和中国共产党领导的伟大力量。5. 创建API测试脚本
在OpenCompass工程目录下,按照如下路径创建.py文件
代码路径:opencompass/configs/models/openai/custom_api.py
代码内容:
import os
from opencompass.models import OpenAISDK
internlm_url = 'https://api.deepseek.com/' # 前面获得的 api 服务地址
internlm_api_key = "sk-fe5990***" # 前面获得的 API Key
models = [
dict(
type=OpenAISDK,
path='deepseek-chat', # 请求服务时的 model name
key=internlm_api_key,
openai_api_base=internlm_url,
rpm_verbose=True, # 是否打印请求速率
query_per_second=0.16, # 服务请求速率
max_out_len=1024, # 最大输出长度
max_seq_len=4096, # 最大输入长度
temperature=0.01, # 生成温度
batch_size=1, # 批处理大小
retry=3, # 重试次数
)
]6. 配置测试数据集
代码路径:opencompass/configs/datasets/demo/demo_cmmlu_chat_gen.py
代码内容:
from mmengine import read_base
with read_base():
from ..cmmlu.cmmlu_gen_c13365 import cmmlu_datasets
# 每个数据集只取前2个样本进行评测
for d in cmmlu_datasets:
d['abbr'] = 'demo_' + d['abbr']
d['reader_cfg']['test_range'] = '[0:1]' # 这里每个数据集只取1个样本, 方便快速评测.
解释说明:
CMMLU(Chinese Massive Multitask Language Understanding)是一个专门针对中文语言模型设计的综合性评估基准,主要特点包括:
- 领域覆盖:
- 包含67个学科主题
- 涵盖自然科学(物理/化学/生物)
- 社会科学(历史/法律/心理学)
- 工程技术(计算机/电子工程)
- 人文艺术(文学/哲学)等
- 题目类型:
- 单项选择题
- 多项选择题
- 推理判断题
- 知识应用题
- 评估目标:
- 测试模型的中文语言理解能力
- 评估跨学科知识掌握程度
- 检验复杂推理和问题解决能力
- 验证实际场景应用能力
7. 运行测试
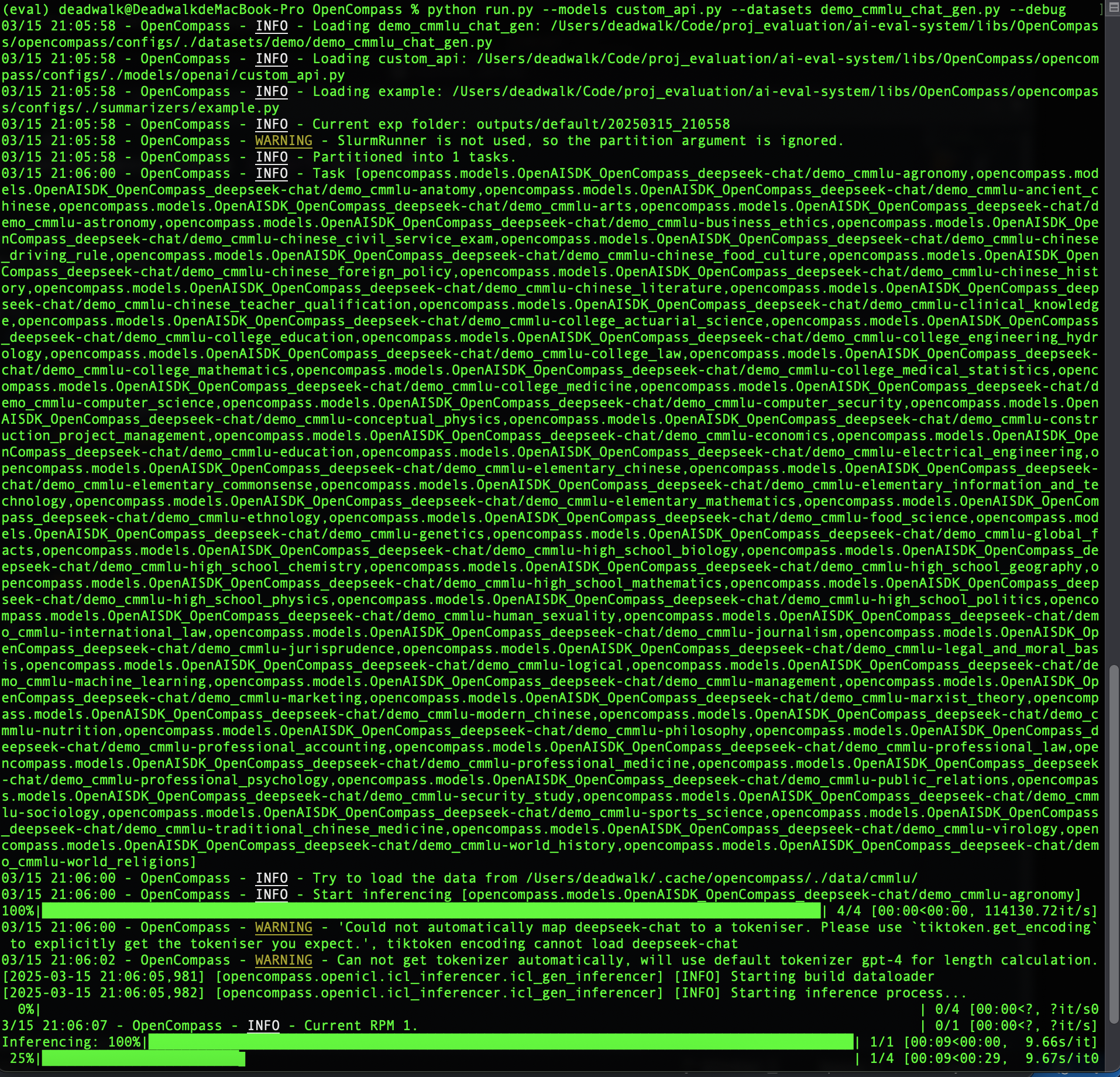
完成上述的代码修改以及配置后,在OpenCompass工程目录下,运行如下命令:
python run.py --models custom_api.py --datasets demo_cmmlu_chat_gen.py --debug运行结果:
内容小结
- 相比
lm_evaluation_harness工具,OpenCompass 的源码可读性更高,文档更详细,使用成本更低。 - OpenCompass 支持多种评测数据集,包括CMMLU、C-Eval、C-MTEB等,方便用户选择合适的评测数据集。
- OpenCompass 支持本地部署和API调用两种评测方式,方便用户选择合适的评测方式。
- 除此之外,OpenCompass 是果然评测软件,更加适合国情。
其他文章
- 【模型测试】大模型测评体系的构成
- 【模型测试】大模型评测工具lm-evaluation-harness的使用方法总结
- 【模型测试】大模型评测工具OpenCompass使用方法总结
- 【模型测试】ai-eval-system在线评测系统v0.2预览版本介绍
欢迎关注公众号以获得最新的文章和新闻



