前言
在上一章,我们通过学习了解了语义分割以及U-Net网络结构【课程总结】Day15(上):图像分割之语义分割。在本章,我们将学习了解图像分割中的实例分割以及相关的数据预处理注意事项。
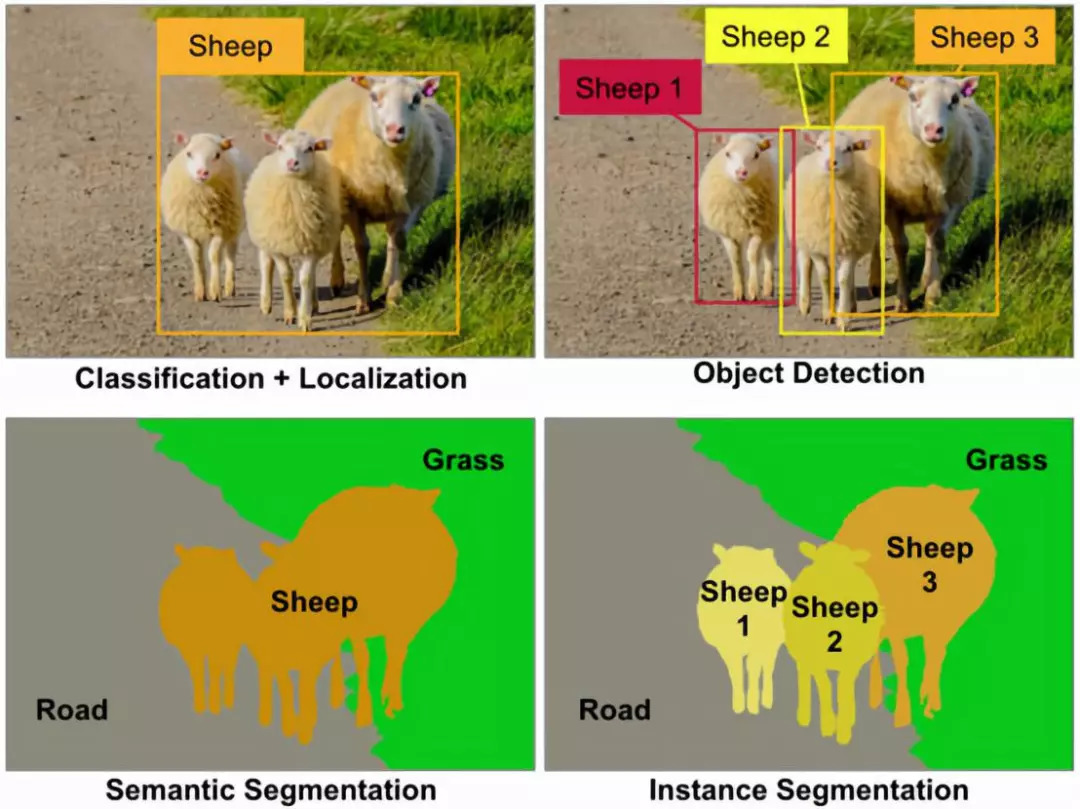
图像分割
语义分割
语义分割的目标是将图像中的每个像素分类为一个特定的类别,但它不区分同一类别的不同实例。
假设我们有一张包含多只羊的图片。
在语义分割中,所有的羊像素都会被标记为“羊”类别,而不会区分它们是第一只羊还是第二只羊。
实例分割
实例分割不仅对每个像素进行分类,还能够区分同一类别的不同实例。
在同样的羊的图片中,实例分割会将第一只羊的像素标记为“Sheep1”,第二只羊的像素标记为“Sheep2”,这样每只羊都有自己的标签。
实例分割:本质上是目标检测 + 语义分割(像素级分类)
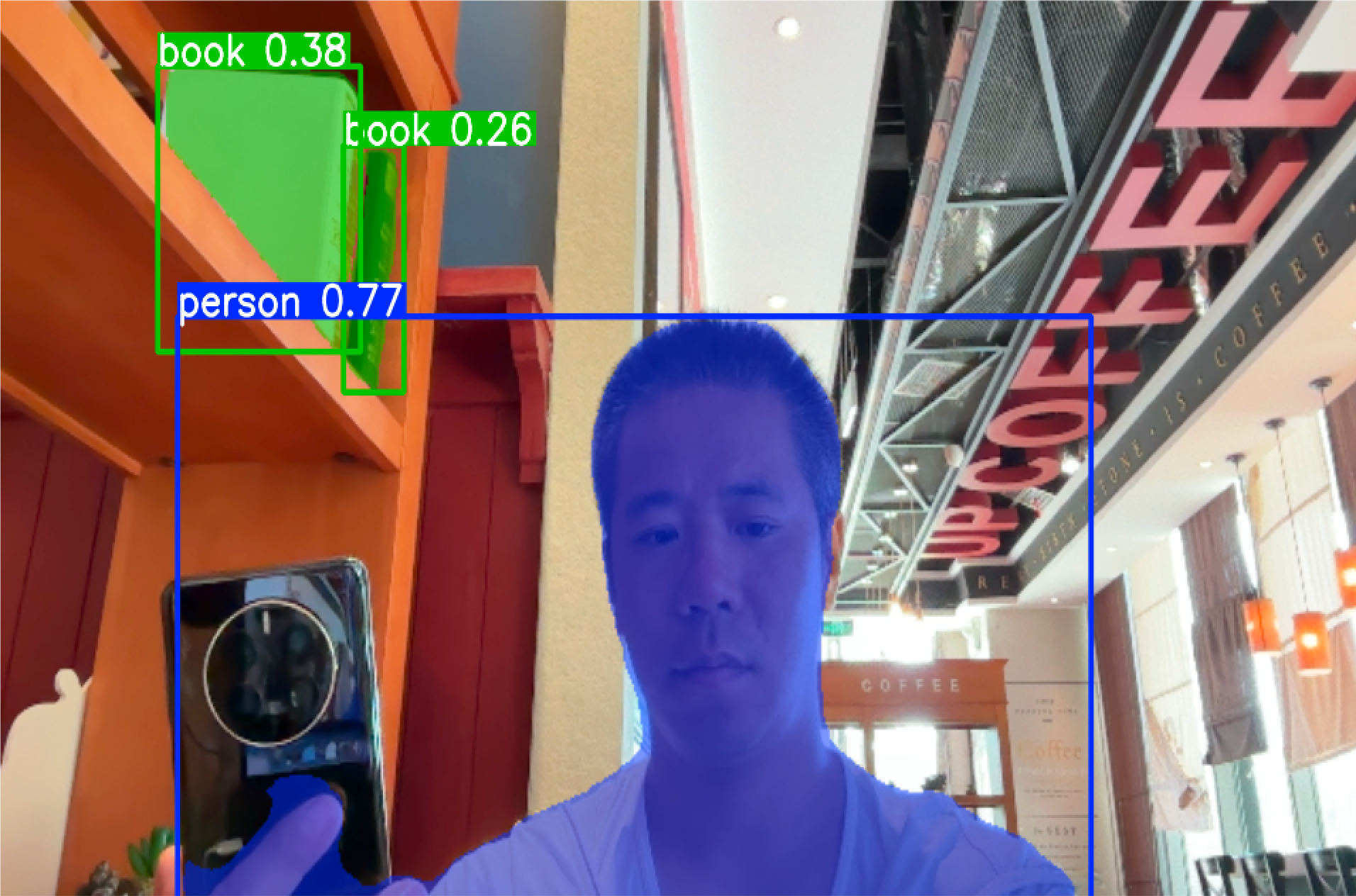
效果体验
第一步:访问YOLO官网,查看示例分割示例代码
https://docs.ultralytics.com/tasks/segment/#predict
第二步:根据示例代码增加读取摄像头并显示结果的功能,代码如下:
from ultralytics import YOLO
import cv2
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 加载模型
model = YOLO("yolov8n-seg.pt")
# 打开摄像头
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = model(frame)
result = results[0]
img = result.plot()
# 调整窗口大小
img_resized = cv2.resize(img, (640, 480))
# 显示图像
cv2.imshow("img", img_resized)
# 按 ESC 退出
if cv2.waitKey(int(1000 / 24)) == 27:
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
运行结果:
图像分割训练
COCO数据集下载
简介
COCO(Common Objects in Context)数据集是一个广泛使用的计算机视觉数据集,主要用于物体检测、分割和图像标注等任务。
特性
- 创建者:COCO数据集由Microsoft在2014年创建。
- 规模:COCO数据集包含超过33万张图像,约有250万标注的对象实例。
- 类别:数据集涵盖80个常见对象类别,如人、动物、交通工具等。
主要特性
- 对象检测:每个图像中标注了对象的边界框(bounding box)。
- 语义分割:提供每个对象的像素级分割掩码。
- 关键点检测:为某些对象(如人)提供关键点标注,用于姿态估计。
- 图像描述:每张图像配有多个自然语言描述,支持图像标注任务。
下载地址
数据集可视化
COCO数据集下载后如下内容
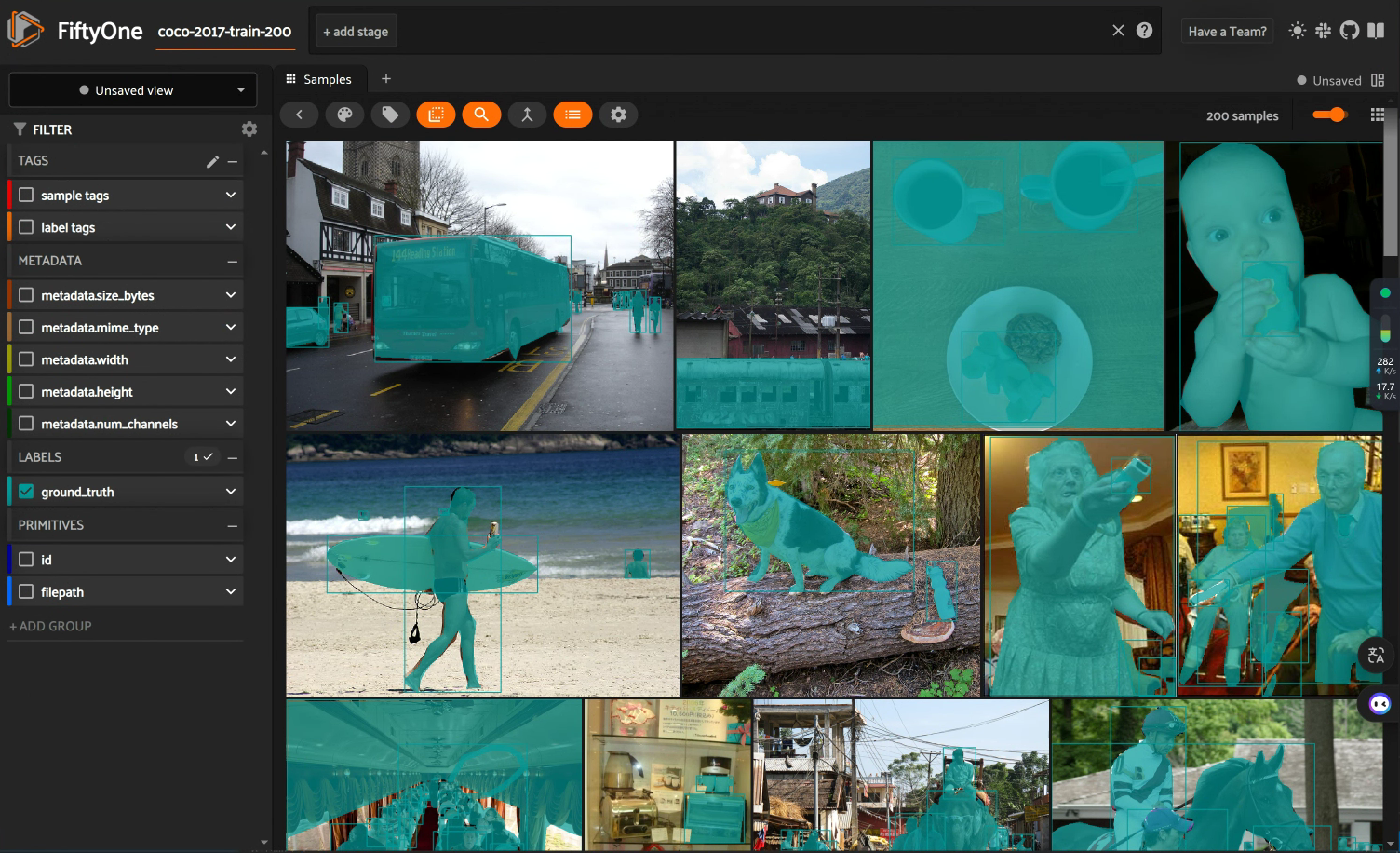
为了更好地了解数据集,我们使用FiftyOne提供的可视化工具,可视化数据集。
FiftyOne简介
FiftyOne是一个开源的数据集管理工具,它提供了可视化工具和API,用于管理、探索和共享数据集。
官网地址:https://voxel51.com/fiftyone/
FiftyOne效果
FiftyOne安装
创建Conda环境
创建Python 3.12版本的虚拟环境
conda create -n py312 python=3.12激活虚拟环境
conda activate py312安装FiftyOne
命令行下使用pip命令安装FiftyOne
pip install fiftyone为了避免报错,最好一并将 pycocotools 一起安装了,安装命令:
pip install pycocotools验证安装
安装完毕后可以通过导入fiftyone库来验证安装是否成功
import fiftyone as fo
如果没问题,当导入fiftyone时不应有任何输出,如果有其他故障,可以参考:
https://docs.voxel51.com/getting_started/install.html#install-troubleshooting
FiftyOne使用
将COCO数据集拷贝到一个新建的工作目录,例如:
fiftyone_demo
|-- coco2017
|-- annotations_trainval2017.zip
|-- train2017.zip
|-- val2017.zip在工作目录下,创建fiftyone_demo.py,内容如下:
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset(
"coco-2017",
split="train",
label_types=["segmentations"],
max_samples=200,
)
session = fo.launch_app(dataset)
session.wait()运行上述python文件,即可在浏览器中查看数据集。
代码说明:
| 参数 | 描述 |
|---|---|
split |
分别指定要加载的拆分的字符串或字符串列表;支持:"train"、"test"、"validation"。如果未指定,则会加载所有。 |
label_types |
要加载的标签类型或标签类型列表;支持:"detections"、"segmentations"。默认情况下,仅加载 "detections"。 |
max_samples |
要加载的每个拆分的最大样本数;针对指定的拆分,每个里面取 max_samples 个。 |
shuffle |
是否 随机洗牌 以部分下载样本的选择顺序;默认为 False。 |
session 就是所启动的实例,网页或者桌面端的那个界面,后续可以在一个程序里面生成多个数据集,用 session.dataset 进行添加。
session.wait() 让程序在这里停着直到手动关闭界面,不然运行后会闪退。
数据集深入了解
为了深入了解数据集,我们在jupyter notebook中,使用如下代码:
# 读取coco2017annotations的json文件内容
import json
import os
import sys
def read_json_file(json_file):
with open(json_file, 'r') as f:
data = json.load(f)
return data
def main():
json_file = 'coco-2017/annotations/instances_train2017.json'
data = read_json_file(json_file)
print(data.keys())
print(data['info'])
print(data['licenses'])
print(data['categories'])
print(data['images'][0])
print(data['annotations'][0])
if __name__ == '__main__':
main()运行上述代码,可以了解到:
-
data.keys()内容如下:dict_keys([ 'info', 'licenses', 'images', 'annotations', 'categories']) -
data['info']内容如下:{ "dataset": { "description": "COCO 2017 Dataset", "url": "http://cocodataset.org", "version": "1.0", "year": 2017, "contributor": "COCO Consortium", "date_created": "2017/09/01" } } -
data['licenses']内容如下:
{
"licenses": [
{
"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/",
"id": 1,
"name": "Attribution-NonCommercial-ShareAlike License"
},
{
"url": "http://creativecommons.org/licenses/by-nc/2.0/",
"id": 2,
"name": "Attribution-NonCommercial License"
},
{
"url": "http://creativecommons.org/licenses/by-nc-nd/2.0/",
"id": 3,
"name": "Attribution-NonCommercial-NoDerivs License"
},
...
]
}
data['categories']内容如下:
{
"categories": [
{
"supercategory": "person",
"id": 1,
"name": "person"
},
{
"supercategory": "vehicle",
"id": 2,
"name": "bicycle"
},
{
"supercategory": "vehicle",
"id": 3,
"name": "car"
},
{
"supercategory": "vehicle",
"id": 4,
"name": "motorcycle"
},
{
"supercategory": "vehicle",
"id": 5,
"name": "airplane"
},
{
"supercategory": "vehicle",
"id": 6,
"name": "bus"
}
...
]
}该文件是数据集类别的信息,其中
supercategory表示类别的父类别,id表示类别的ID,name表示类别的名称。
data['images'][0]内容如下:
{
"image": {
"license": 3,
"file_name": "000000391895.jpg",
"coco_url": "http://images.cocodataset.org/train2017/000000391895.jpg",
"height": 360,
"width": 640,
"date_captured": "2013-11-14 11:18:45",
"flickr_url": "http://farm9.staticflickr.com/8186/8119368305_4e622c8349_z.jpg",
"id": 391895
}
}
image表示图像的信息,其中:
license表示图像的版权信息,file_name表示图像的文件名,coco_url表示图像在COCO数据集中的URL,height表示图像的高度,width表示图像的宽度,date_captured表示图像的拍摄时间,flickr_url表示图像在Flickr上的URL,id表示图像的ID。
data['annotations'][0] 内容如下:
{
"annotation": {
"segmentation": [
[
239.97, 260.24, 222.04, 270.49, 199.84, 253.41,
213.5, 227.79, 259.62, 200.46, 274.13, 202.17,
277.55, 210.71, 249.37, 253.41, 237.41, 264.51,
242.54, 261.95, 228.87, 271.34
]
],
"area": 2765.1486500000005,
"iscrowd": 0,
"image_id": 558840,
"bbox": [199.84, 200.46, 77.71, 70.88],
"category_id": 58,
"id": 156
}
}
annotation表示标注的信息,其中:
segmentation表示图像的分割信息,area表示图像的分割区域的面积,iscrowd表示图像是否是 crowd,image_id表示图像的ID,bbox表示图像的边界框信息,category_id表示图像的类别ID,id表示标注的ID。
核对数据
我们在代码中增加以下遍历代码,来核对如下图的信息:
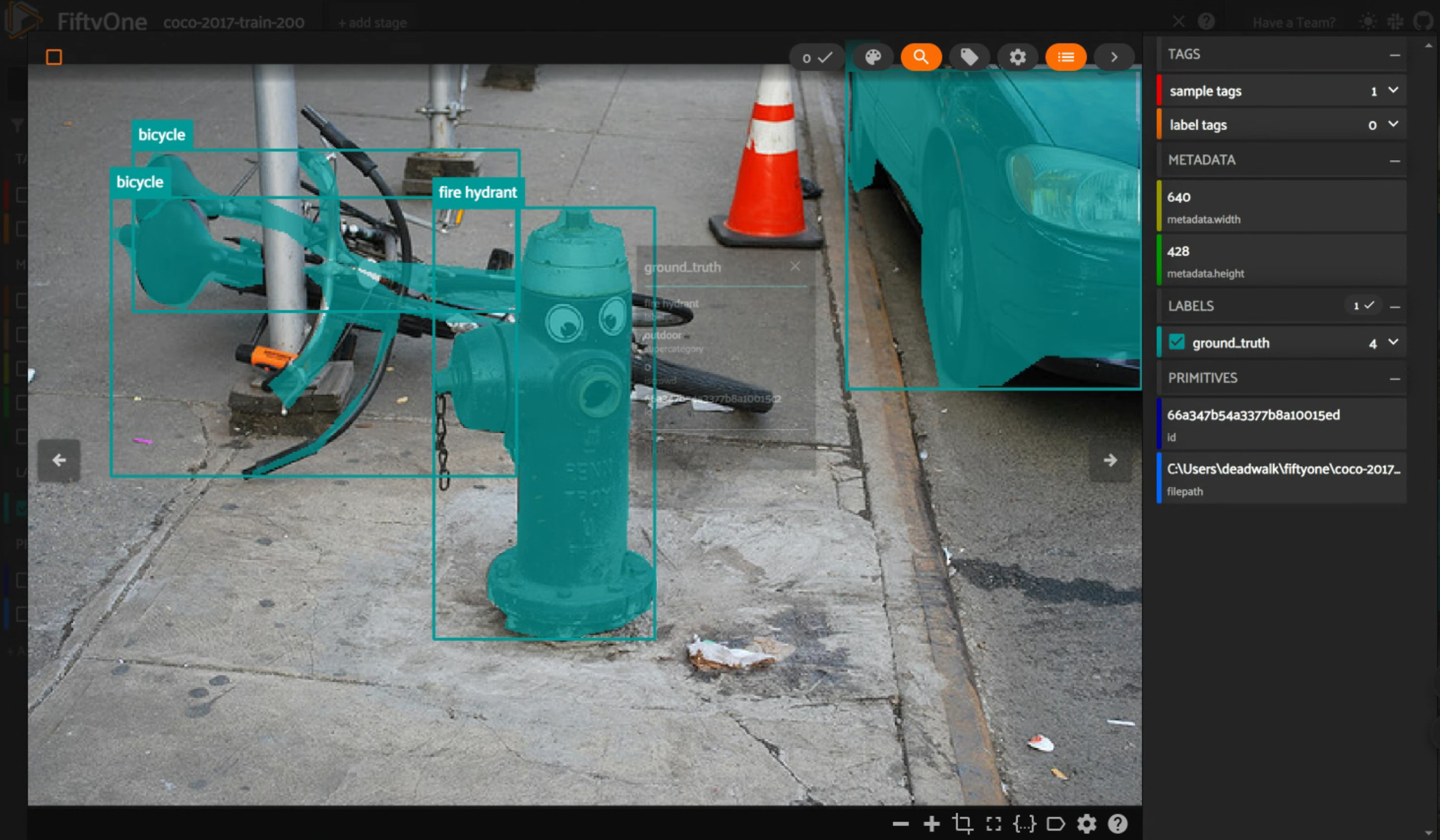
# 输出file_name为000000029913.jpg的json数据和annotations数据
print('-------------------')
image_id = ''
for image in data['images']:
if image['file_name'] == '000000029913.jpg':
print(image)
image_id = image['id']
break
# 输出image_id为150552的annotations数据
for annotation in data['annotations']:
if annotation['image_id'] == image_id:
print(annotation)
break运行结果:
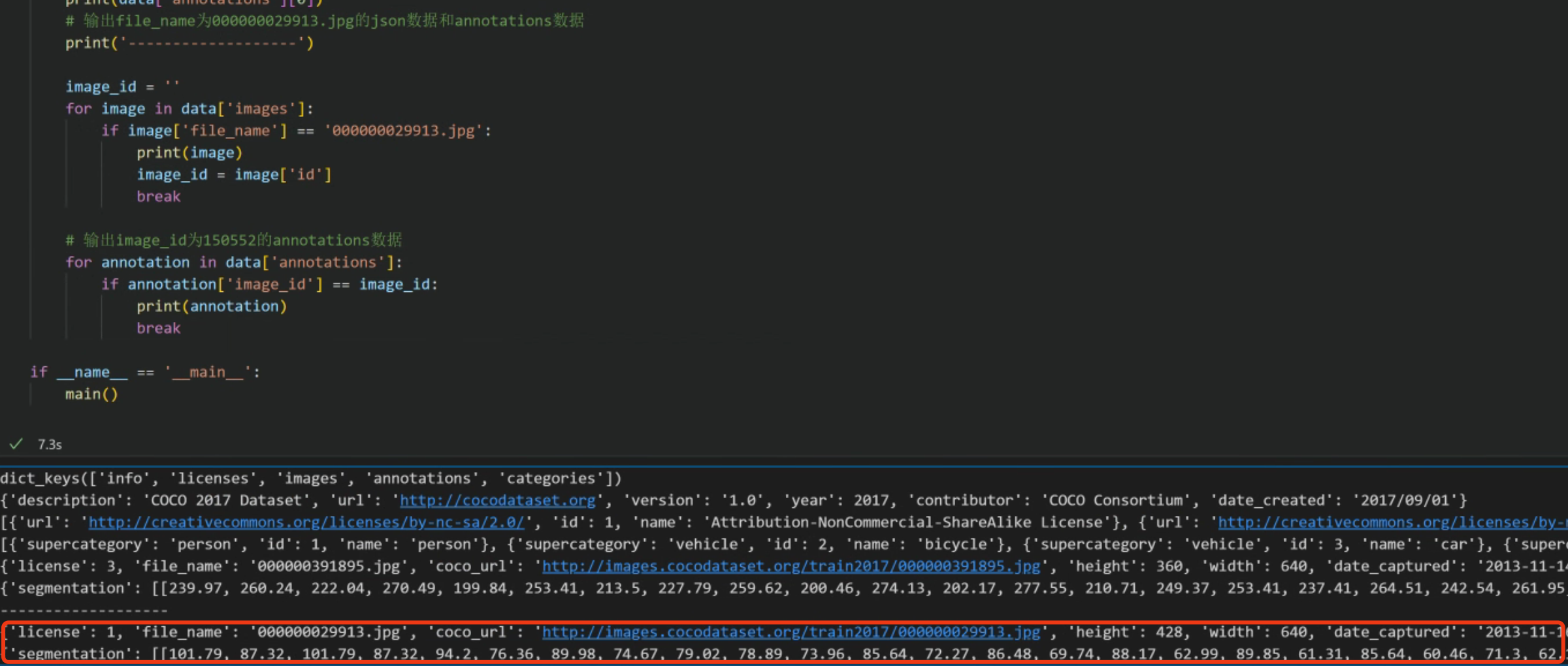
截图中的json数据与截图匹配,其中segmentation即为实例分割的信息。
数据集转换
问题场景
在实际项目应用场景中,我们会经常遇到对数据标注并转换为YOLO格式训练。在这一过程中,常见的最为复杂的场景问题为: 物体重叠问题

解决方案
如果存在区域被分割的问题,需要对区域进行合并。
具体方法:
- 标注:使用
标注工具标注每一个物体(如果存在遮挡,则需要分块标注) - 转换:把标注结果转化为类似
COCO格式 - 合并:利用YOLO提供的多段合成算法,合并多个分段
X-Anylabeling
目前标注工具有多个可以选择,其中常用的labelme教程较多,本文不再赘述,详细内容可以参考CSDN:图像数据标注工具labelme使用教程。
本文尝试使用另外一款开源的标注工具:X-Anylabeling
工具安装
X-AnyLabeling提供两种运行方式:exe方式运行和源码方式运行,官方推荐使用源码方式运行。
工具下载地址:X-AnyLabeling
下载源码
git clone https://github.com/CVHub520/X-AnyLabeling安装相关依赖
pip install -r requirements.txt启动程序
python anylabeling/app.py工具使用
- 选择要标注的图片
- 使用多边形工具进行标注
- 标注完毕后,选择另存为按钮,保存为COCO格式
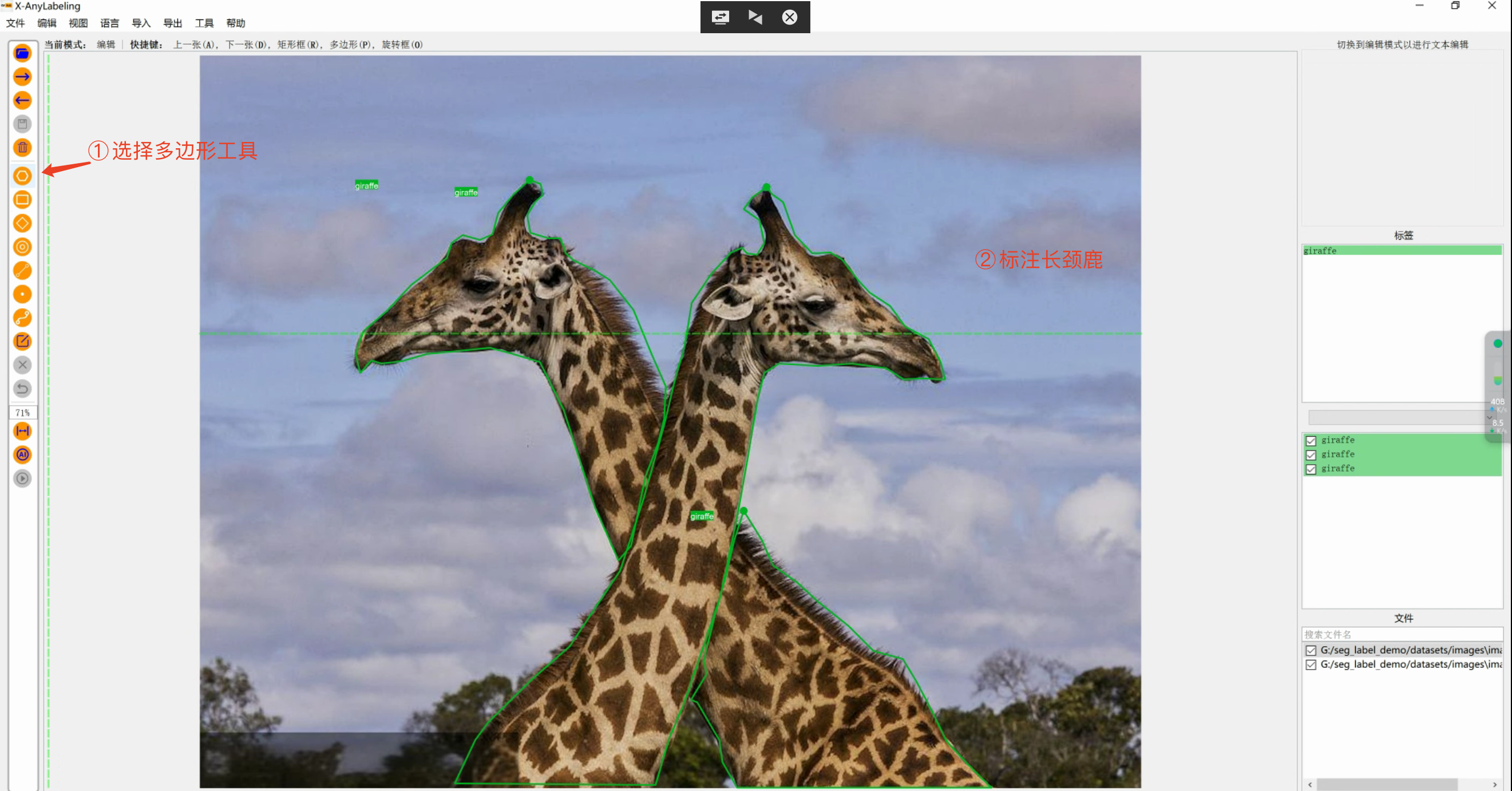
导出数据

导出成功后,会在当前目录下生成一个annotations文件夹,里面包含COCO格式的标注数据instances_defaults.json。
转换数据
由于在上一步中,处于被遮挡的长颈鹿被分割为两部分,我们需要借助YOLO的多段合成脚本,将多段合成为单段。具体方法如下:
下载YOLO的转换脚本
git clone https://github.com/ultralytics/JSON2YOLO.git修改脚本的路径参数
打开JSON2YOLO目录下的generate_yolo.py文件,根据需要修改源文件目录,例如:我的数据保存在datasets/annotations目录下。
if __name__ == "__main__":
source = "COCO"
if source == "COCO":
convert_coco_json(
"../datasets/annotations", # directory with *.json
use_segments=True,
cls91to80=False,
)
执行转换脚本
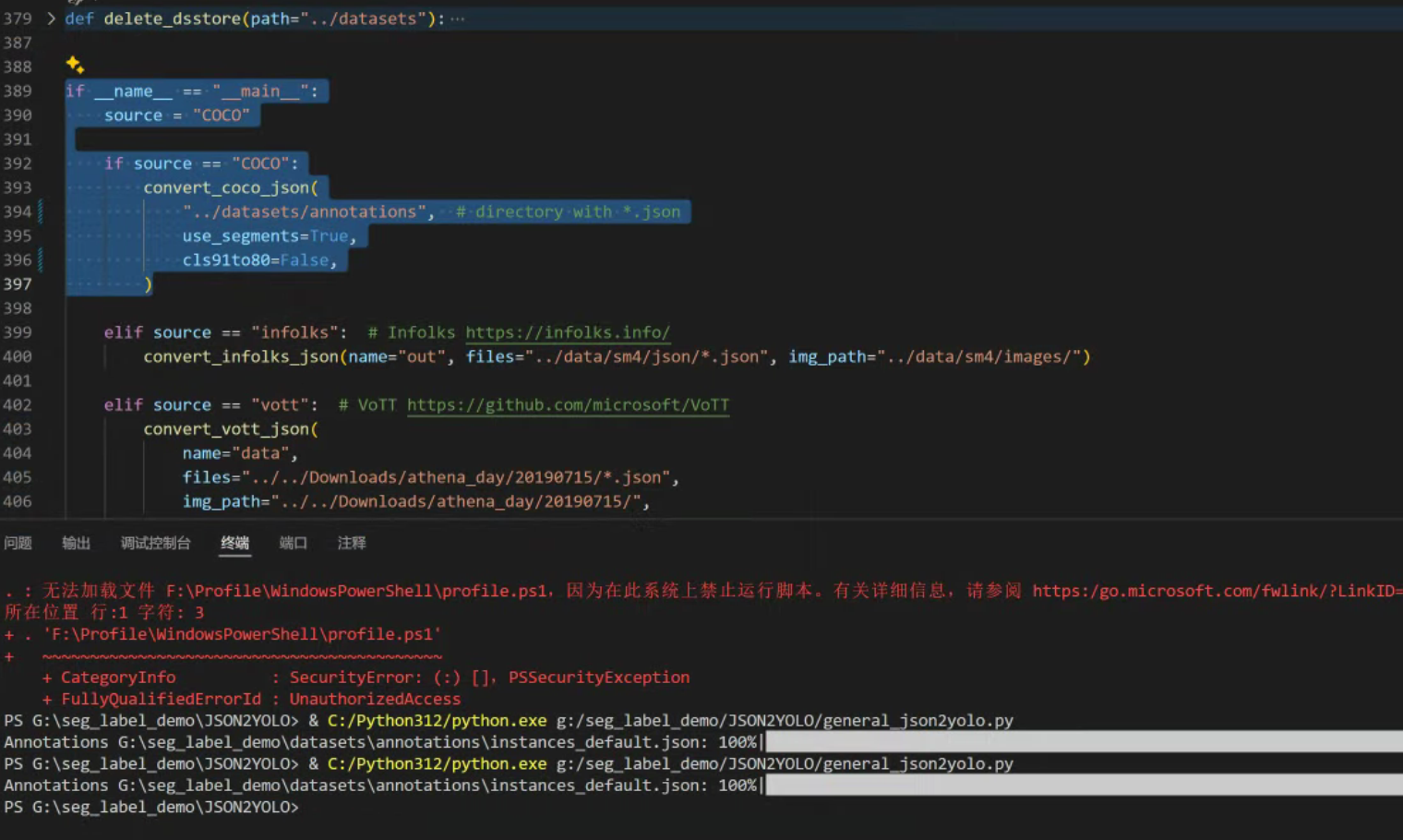
执行完毕后,会在JSON2YOLO目录下生成一个new_dir目录,该目录下的labels对应就是转换后的标注数据。
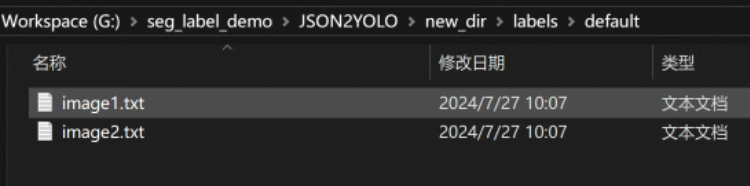
将lables目录下*.txt复制到YOLO的labels目录下,后续即可进行模型的训练,训练过程不再赘述,详情可以参考YOLO的模型训练
核心代码解读
上述转换脚本主要实现了以下功能:
-
通过min_index函数找到最短距离的索引
def min_index(arr1, arr2): """ Find a pair of indexes with the shortest distance. Args: arr1: (N, 2). arr2: (M, 2). Return: a pair of indexes(tuple). """ dis = ((arr1[:, None, :] - arr2[None, :, :]) ** 2).sum(-1) return np.unravel_index(np.argmin(dis, axis=None), dis.shape)arr1[:, None, :]:这个操作将 arr1 的形状从(N, 2)改变为(N, 1, 2),在第二个维度上增加一个维度。arr2[None, :, :]:这个操作将 arr2 的形状从(M, 2)改变为(1, M, 2),在第一个维度上增加一个维度。- 通过这两个操作,我们可以进行广播(broadcasting),计算每个点之间的距离。
arr1[:, None, :] - arr2[None, :, :]计算了每个arr1中的点与每个arr2中的点之间的差。- 取平方
** 2,然后用.sum(-1)计算每对点之间的平方距离。最终,dis的形状为(N, M),其中dis[i, j]表示arr1[i]和arr2[j]之间的平方距离。
-
通过merge_multi_segment函数将多个分段(segments)合并成一个连续的线段
def merge_multi_segment(segments): """ Merge multi segments to one list. Find the coordinates with min distance between each segment, then connect these coordinates with one thin line to merge all segments into one. Args: segments(List(List)): original segmentations in coco's json file. like [segmentation1, segmentation2,...], each segmentation is a list of coordinates. """ # 初始化和预处理 s = [] segments = [np.array(i).reshape(-1, 2) for i in segments] idx_list = [[] for _ in range(len(segments))] # 计算最小距离的索引 for i in range(1, len(segments)): idx1, idx2 = min_index(segments[i - 1], segments[i]) idx_list[i - 1].append(idx1) idx_list[i].append(idx2) # use two round to connect all the segments for k in range(2): # 遍历每个分段的索引列表。 if k == 0: for i, idx in enumerate(idx_list): # middle segments have two indexes # reverse the index of middle segments if len(idx) == 2 and idx[0] > idx[1]: idx = idx[::-1] segments[i] = segments[i][::-1, :] # 使用 np.roll 将分段滚动到第一个索引的位置。 segments[i] = np.roll(segments[i], -idx[0], axis=0) segments[i] = np.concatenate([segments[i], segments[i][:1]]) # 将第一个点添加到分段的末尾,以便形成一个闭合的线段。 if i in [0, len(idx_list) - 1]: s.append(segments[i]) else: # 如果是第一个或最后一个分段,直接将其添加到结果中。 idx = [0, idx[1] - idx[0]] s.append(segments[i][idx[0] : idx[1] + 1]) else: # 反向遍历 idx_list,对于中间的分段,添加从最小索引到最后的部分。(没有太看懂这部分代码) for i in range(len(idx_list) - 1, -1, -1): if i not in [0, len(idx_list) - 1]: idx = idx_list[i] nidx = abs(idx[1] - idx[0]) s.append(segments[i][nidx:]) # 最后返回合并后的分段列表 s return s内容小结
-
实例分割本质上是目标检测 + 语义分割(像素级分类),它不仅会分割出羊,而且会将不同的羊有自己的标签。
-
COCO数据集是一个广泛使用的计算机视觉数据集,主要用于物体检测、分割和图像标注等任务。
-
FiftyOne是一个开源的数据集管理工具,通过它可以对数据集可视化管理。
-
在实际标注的场景中,常见
物体重叠问题;如果存在区域被分割的问题,需要对区域进行合并。 -
区域合并方法:
-
标注:使用 标注工具 标注每一个物体(如果存在遮挡,则需要分块标注)
-
转换:把标注结果转化为类似 COCO 格式
-
合并:利用YOLO提供的多段合成算法,合并多个分段
参考资料
- 目标检测数据集汇总
- CSDN:大数据集可视化——FiftyOne 的使用经验分享
- CSDN:labelme的安装与使用
- CSDN:图像数据标注工具labelme使用教程
- CSDN:自动标注!!!x-anylabeling使用教程
欢迎关注公众号以获得最新的文章和新闻



