
前言
听了晓华老师分享的模型微调第一节课,其中有不少知识点需要后续查询资料了解,所以我对知识要点做了部分记录总结。同时模型微调涉及到一些基本的环境准备操作,例如Git客户端的安装使用、ubuntu子系统的安装等,我也顺便把过程梳理下来,方便其他同学了解。
试用过程索引
总体来说,模型微调的前序工作过程主要有下面几个步骤:
- Step1:准备机器环境
- Step2:准备Git客户端
- Step3:访问魔塔社区,查找Llama3模型
- Step4:通过Git clone命令,拉取Llama3的代码
- Step5:加载Llama3模型
环境准备
环境准备有两种方式:本地环境 或 阿里云远程环境
本地环境:需要本机有比较强的显卡做支持,例如:运行Llama3-8B需要20G的显存,本地的机器有24G+的显存。
远程环境:如果本地没有比较强的显卡做支撑,可以通过试用阿里云的免费PAI环境。(这种方式在忙时可能存在没有空余机器可用的情况)
方式一:本地环境
安装ubuntu系统
在Windows下安装子系统是比较常见的教程,网上有比较多的参考资料可供搜索。为了避坑,我这里基于网上的教程进行更为细化的操作指南梳理,以及可能踩坑问题的提醒。
安装方法:
-
检查Windows版本:
WSL最早出现在Windows 10版本1709(即Windows 10秋季创意者更新)中。因此,首先确保你的Windows系统版本是Windows 10秋季创意者更新或更高版本。 -
检查Hyper-V支持:WSL 2需要Hyper-V支持。你可以通过以下步骤检查是否支持Hyper-V
- 在开始菜单中搜索“Windows功能”并打开“启用或关闭Windows功能”。
- 确保“Hyper-V”复选框已选中。
备注:此处一定要确认当前电脑的系统版本以及是否支持Hyper-V,我的某台电脑里如下所示是不支持Hyper-V。
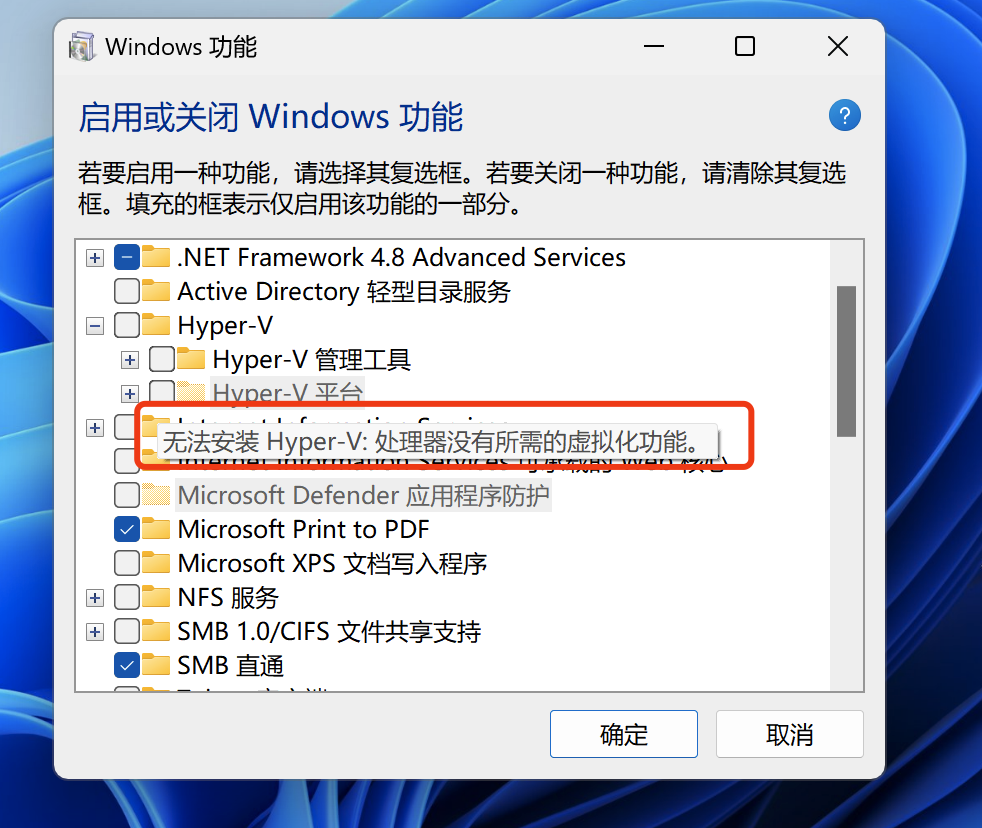
-
启用WSL功能:
打开Windows PowerShell或命令提示符(以管理员身份运行)。运行以下命令来启用WSL功能:dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart -
安装WSL 2:
- 打开Microsoft Store并搜索Ubuntu,选择Ubuntu发行版并安装。
- 在安装完成后,打开Windows PowerShell或命令提示符(以管理员身份运行)并运行以下命令来将WSL 2设置为默认版本:
wsl --set-default-version 2
-
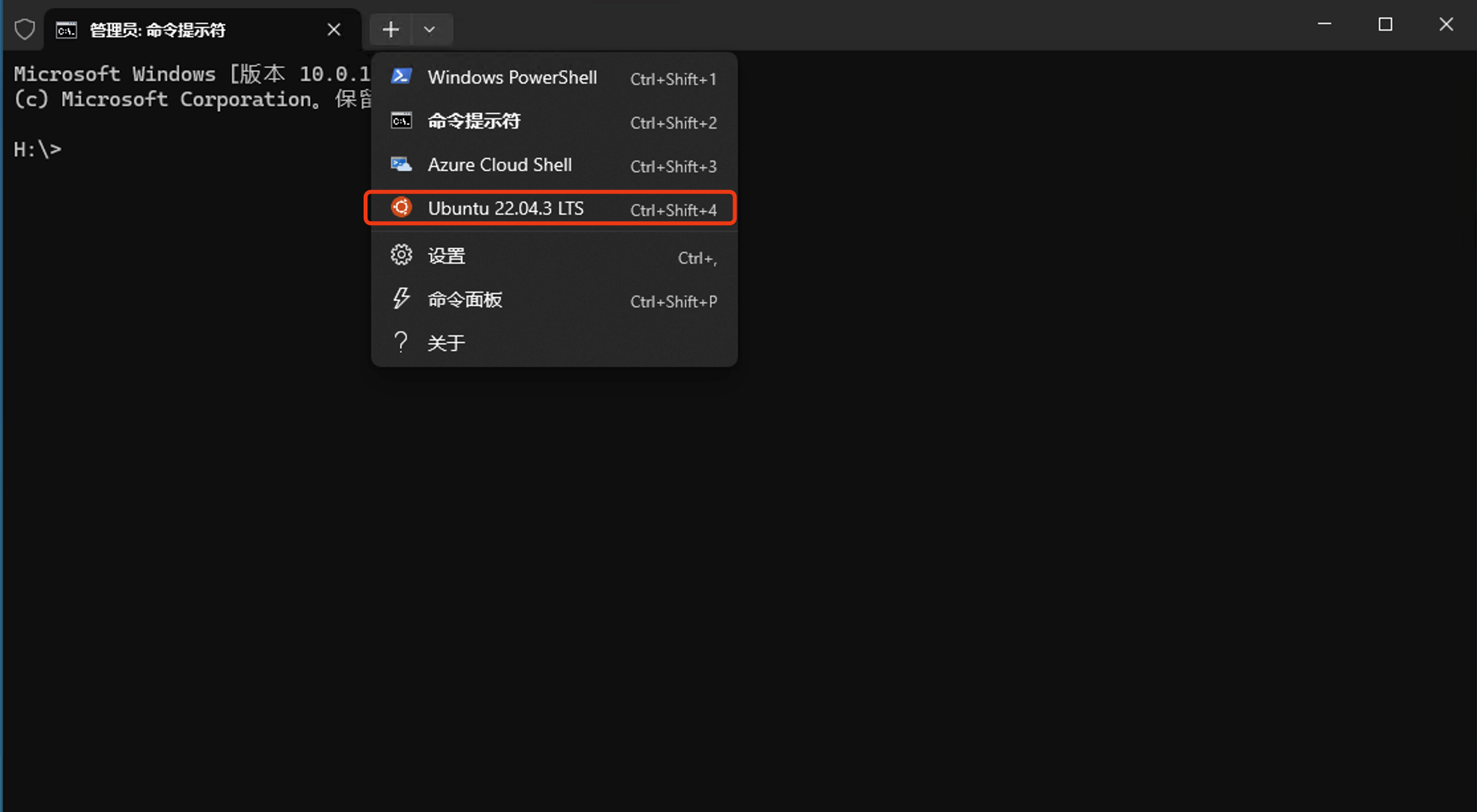
启动ubuntu系统:安装完毕后,启动Windows命令行,点击+号会多出一个ubuntu
安装必备组件
1、安装Git客户端
- 访问Git官网(https://git-scm.com) 下载并安装适合系统的Git版本。
- 配置Git:
- 打开命令提示符(Command Prompt)或Git Bash。
- 配置全局用户名和邮箱地址:
git config --global user.name "Dongming" git config --global user.email "zgdmemail@126.com"
2、安装Python
在ubuntu系统下确认模型必备的Python已经安装。可以通过以下命令检查Python版本:
python --version3、安装pip
确保系统中已经安装了pip,它是Python的包管理工具。可以使用以下命令安装pip:
sudo apt update
sudo apt install python3-pip4、安装依赖库
安装必要的Python依赖库,如transformers、torch等。可以使用pip进行安装:
pip install transformers torchpytorch大概700多M,下载安装这个过程可能会比较久,耐心等待下。
5、安装Jupyter Notebook
安装Jupyter Notebook,方便后续运行代码查看用,命令为
pip install jupyter方式二:远程环境
申请免费试用资源
- 访问人工智能平台 PAI页面https://www.aliyun.com/product/bigdata/learn
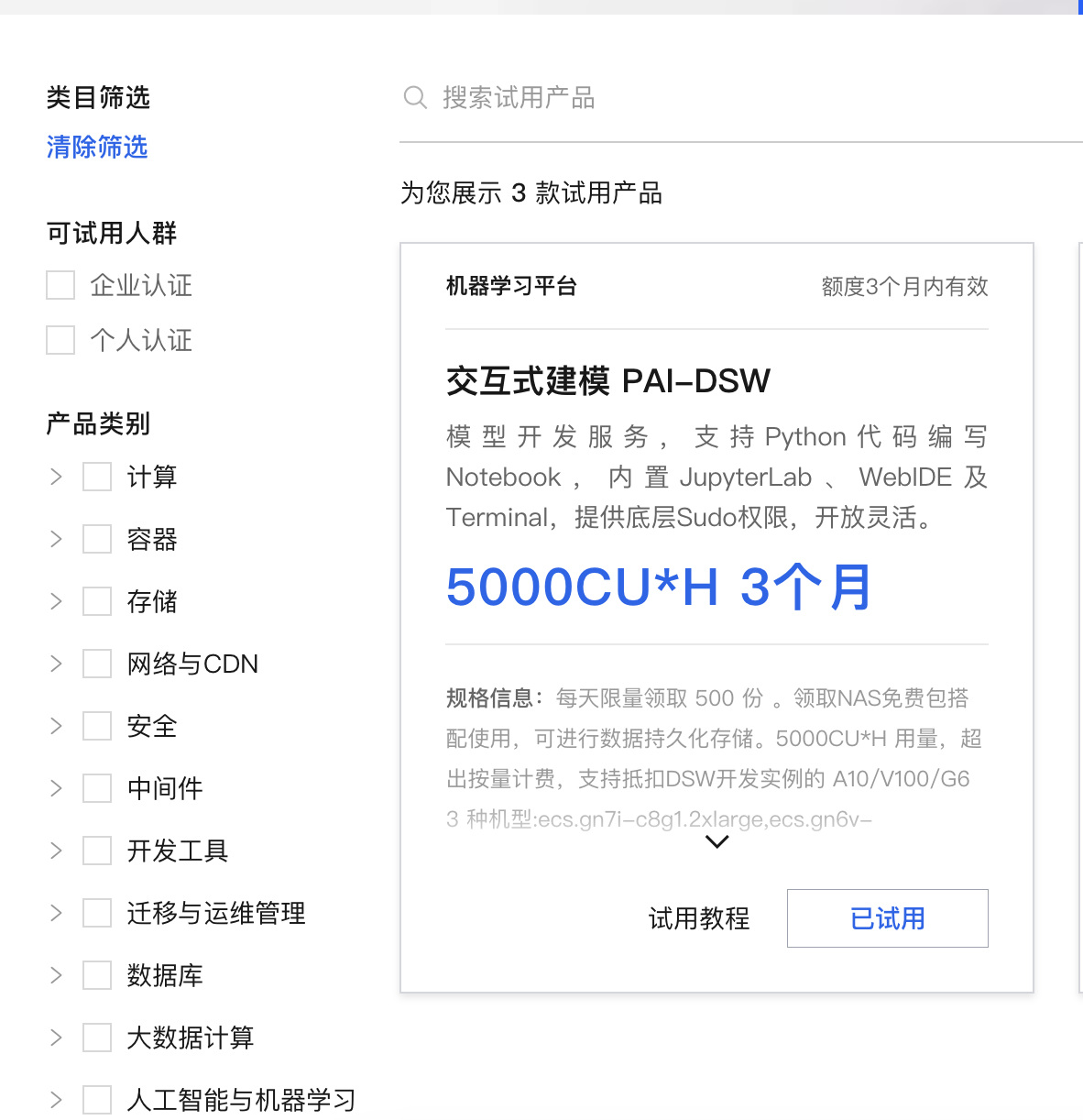
- 点击页面中的"免费试用"
- 选择交互式建模的"立即试用"
建立交互式实例
-
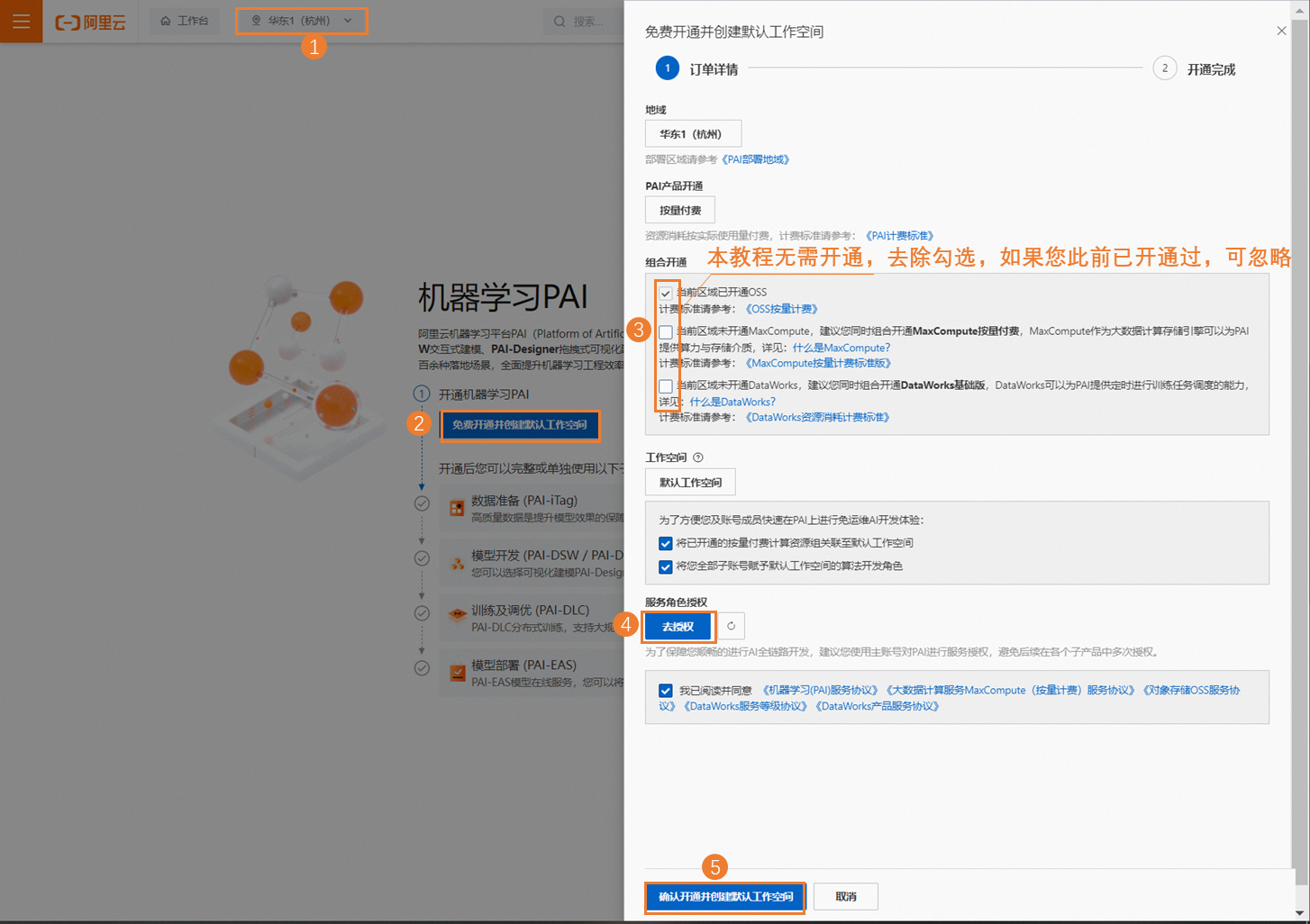
在人工智能平台 PAI页面点击"立即开通"
-
进入工作台之后选择"交互式建模(DSW)"
-
在右侧页面中选择新建实例并输入相关内容,例如:
实例名称:Llama3_for_study
-
选择支持资源包抵扣的CPU和GPU后,选择下一步创建实例。
-
稍等片刻后,在实例页面显示"运行中"状态,就可以点击打开进入远程环境

-
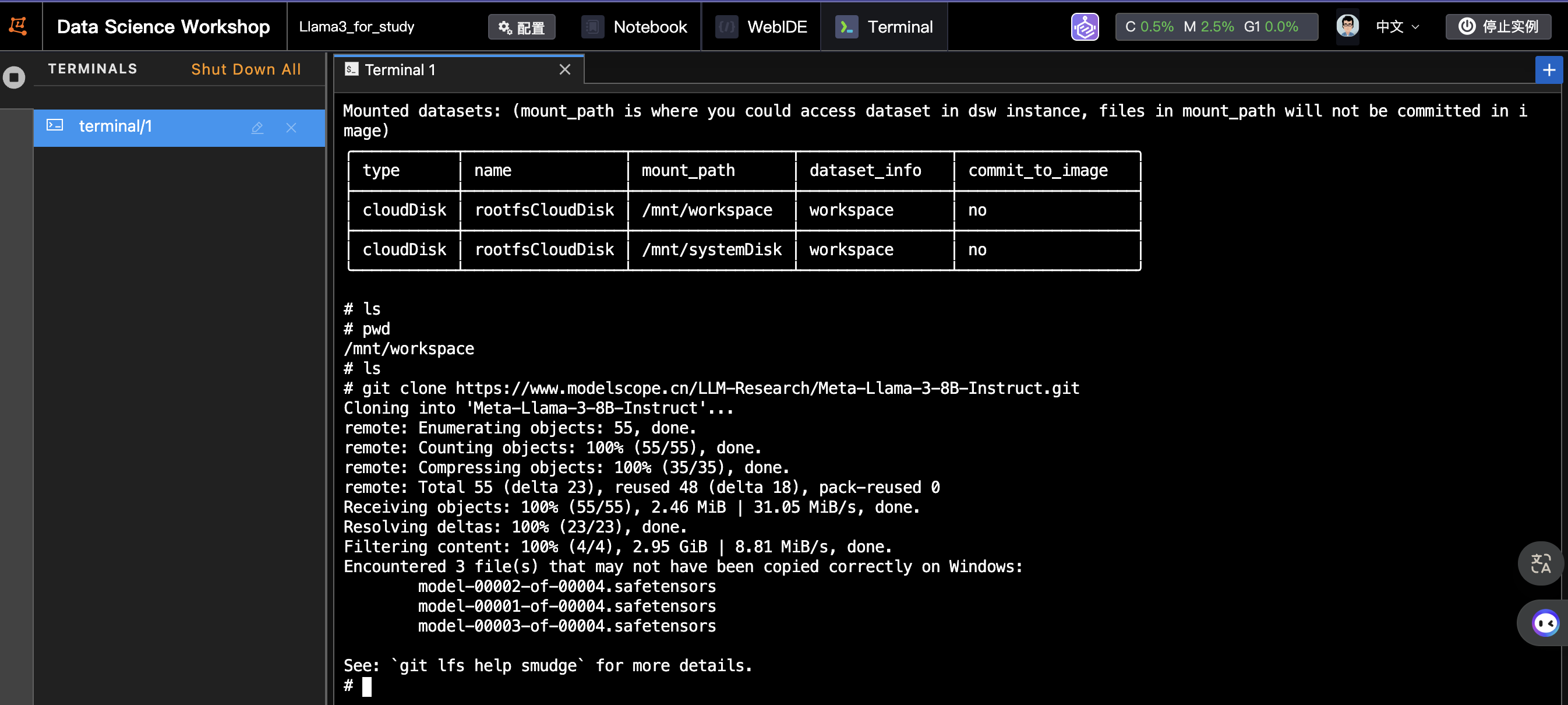
点击打开,进入远程环境如下:
下载代码
查找Llama3模型
- 访问https://modelscope.cn/models
- 在下拉框搜索Llama3,查找对应的模型
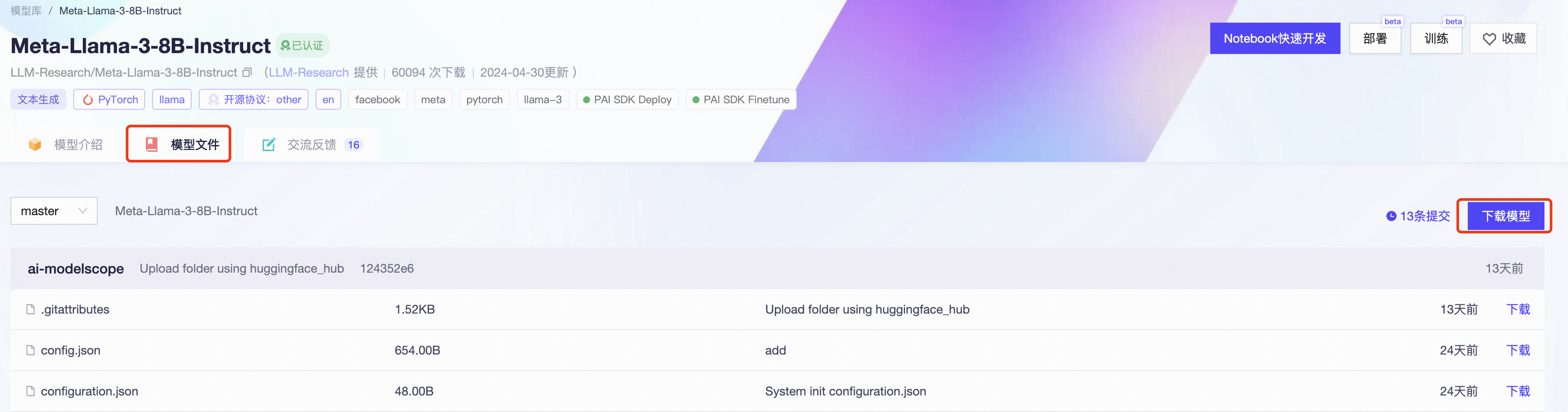
(或者直接访问LLM 的https://modelscope.cn/models/LLM-Research/Meta-Llama-3-8B-Instruct/summary) - 在页面的模型文件中,找到"下载模型",获取Git的地址
拉取代码
本地环境
如果使用的是本地环境,在安装了Git客户端后,选择对应的目录拉取代码。
- 在本地电脑的合适目录下(例如:E:\Code目录),右键菜单→选择Git bash
- 在Git Bash中执行以下命令来克隆代码库:
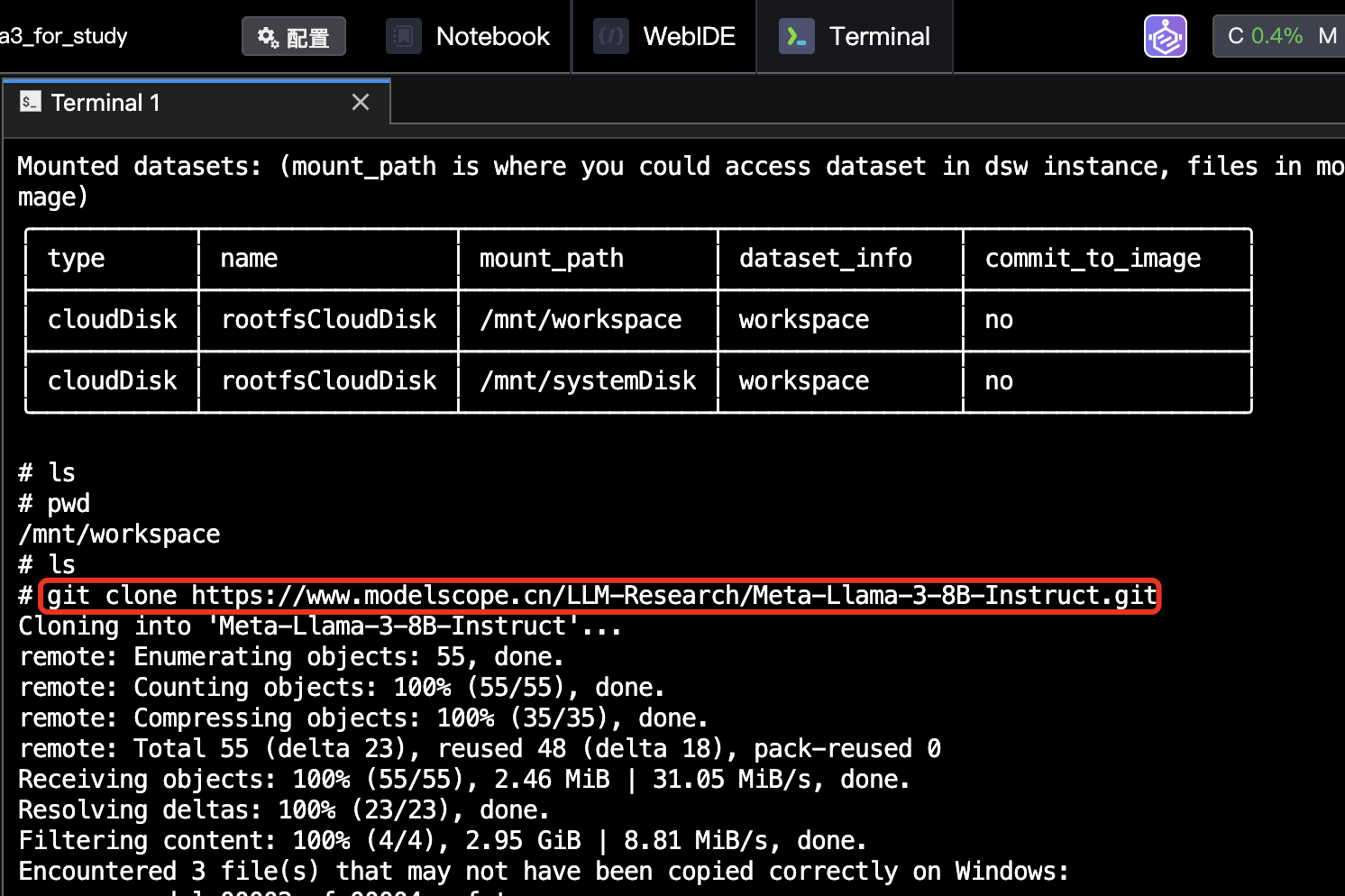
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
又是一个漫长的拉取代码的过程,代码拉取完毕大概30G。
远程环境
由于远程环境已经提前安装好了Git、Jupyter、Python、torch等环境依赖,所以直接拉取代码即可。
- 在远程管理台切换至Terminal
- 在命令行下输入同样的拉取代码指令
加载模型
检测运行环境
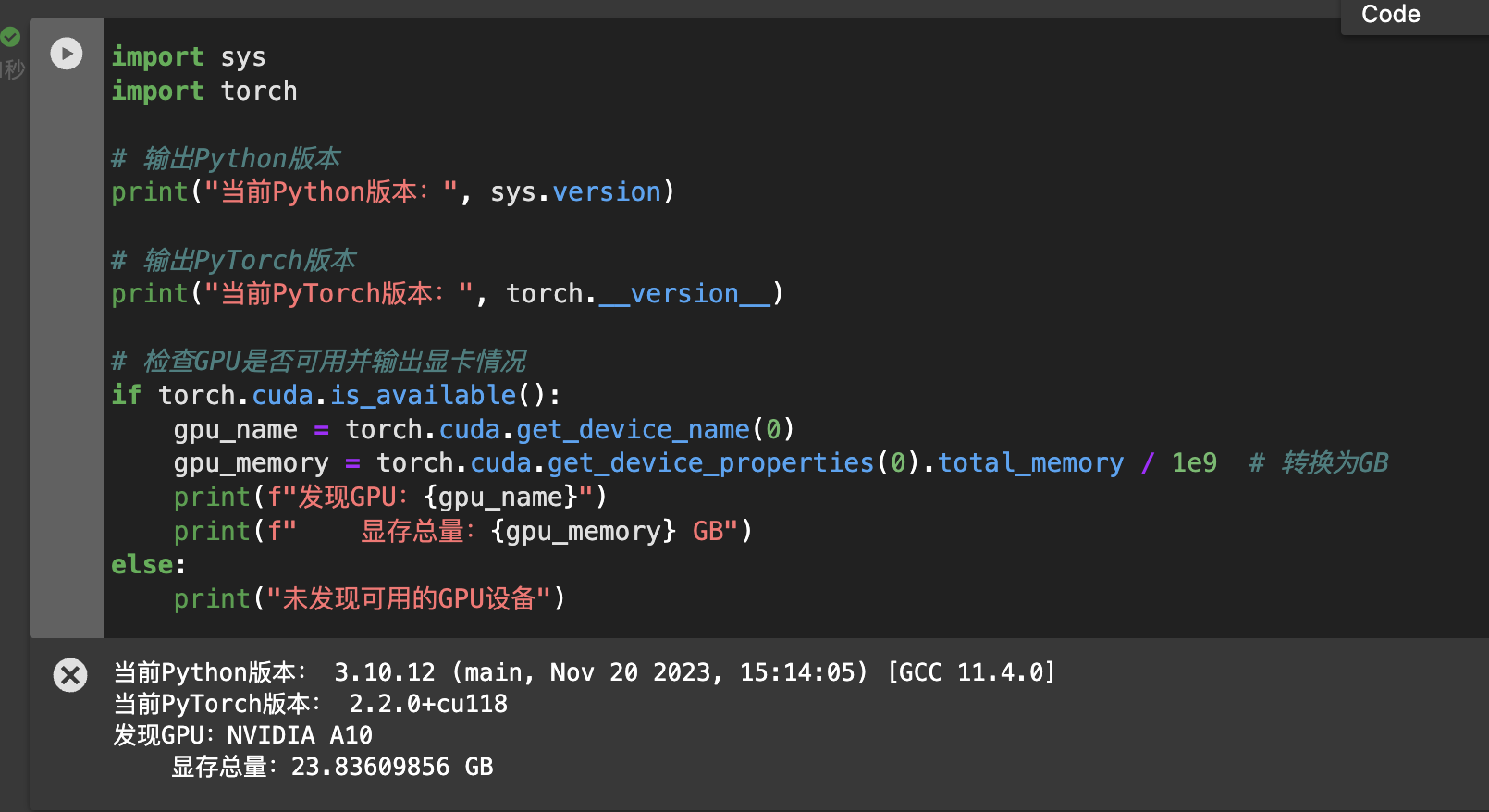
在Jupyter Notebook中,运行以下指令,检测当前机器环境
import sys
import torch
# 输出Python版本
print("当前Python版本:", sys.version)
# 输出PyTorch版本
print("当前PyTorch版本:", torch.__version__)
# 检查GPU是否可用并输出显卡情况
if torch.cuda.is_available():
gpu_name = torch.cuda.get_device_name(0)
gpu_memory = torch.cuda.get_device_properties(0).total_memory / 1e9 # 转换为GB
print(f"发现GPU:{gpu_name}")
print(f" 显存总量:{gpu_memory} GB")
else:
print("未发现可用的GPU设备")运行后提示如下信息:
安装ipywidgets
直接使用Llama3提供的加载代码,会报错提示安装ipywidgets,所以我们切换到Terminal下通过pip安装对应的组件。
pip install ipywidgets运行Llama3提供的加载模型代码
import transformers
import torch
from modelscope import snapshot_download
from transformers import AutoTokenizer, pipeline
model_id = snapshot_download("LLM-Research/Meta-Llama-3-8B-Instruct")
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
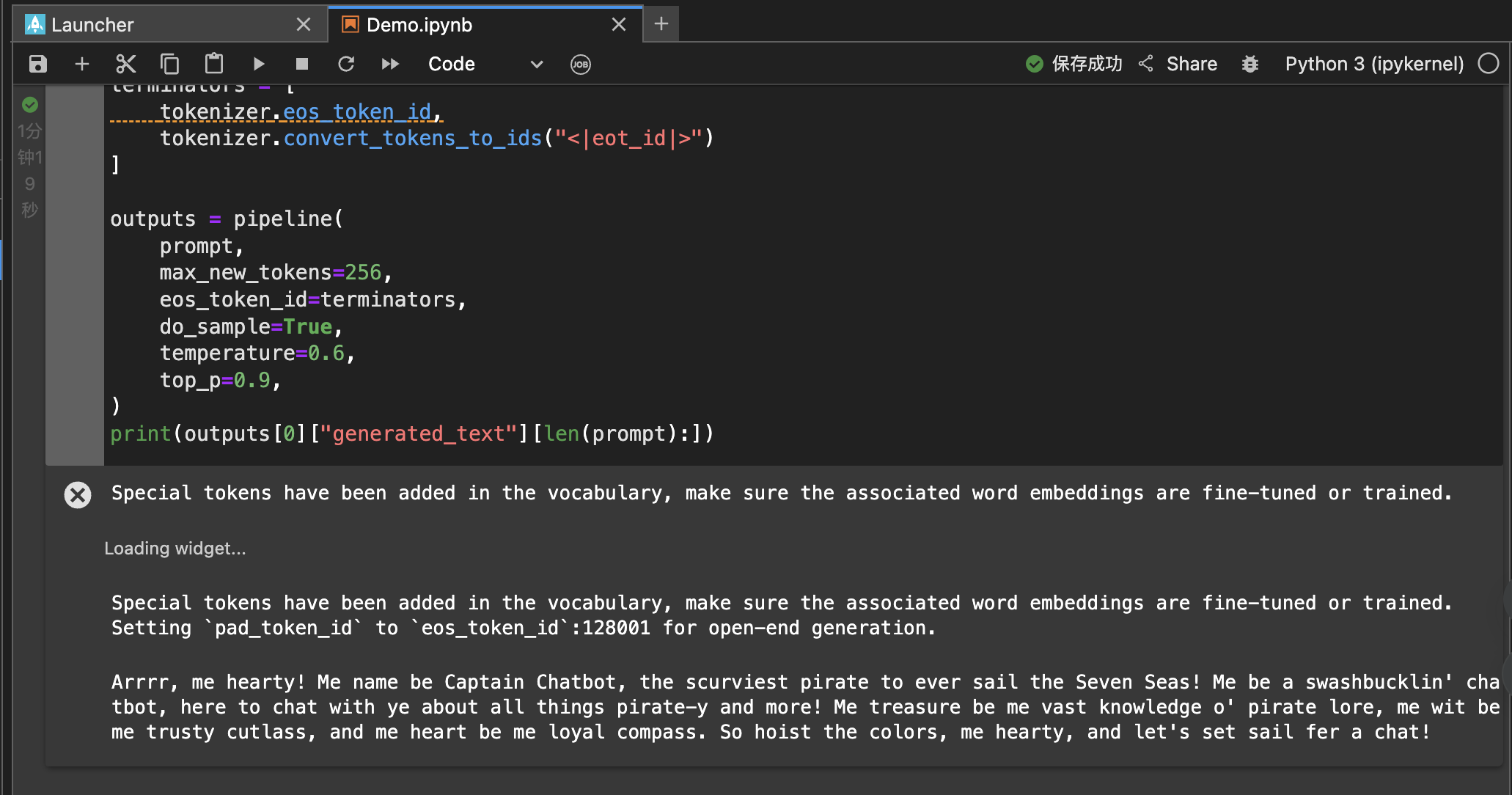
运行成功后,大模型会通过对话返回相关信息。
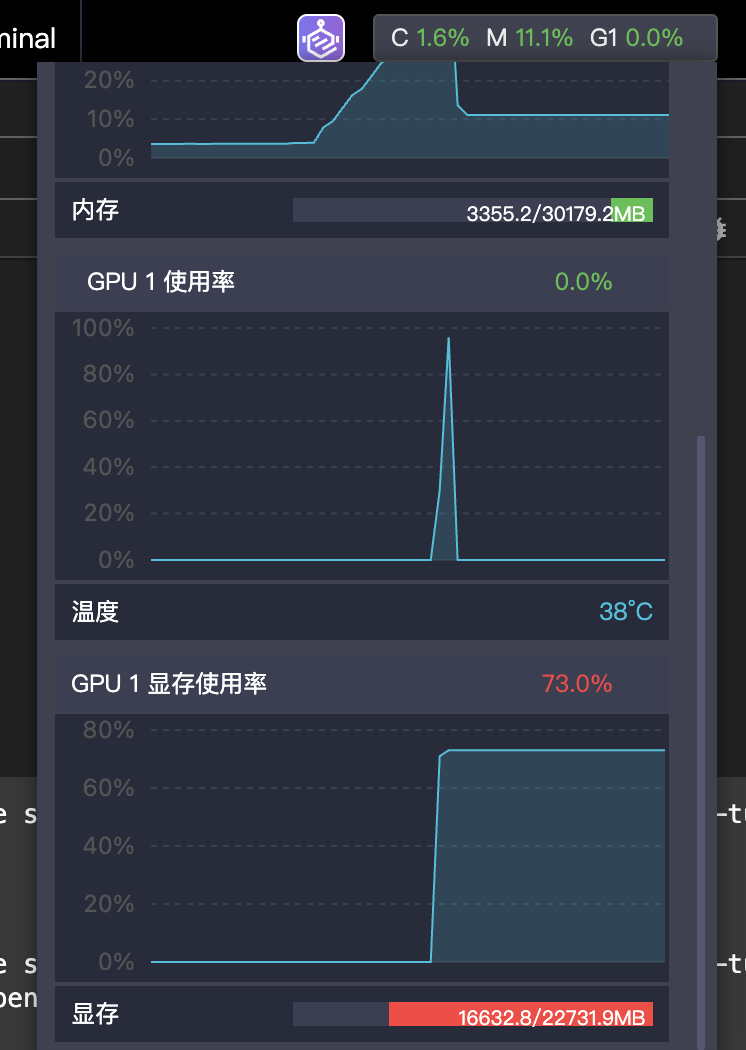
在加载大模型的过程中,阿里云的控制台会实时显示显存的使用情况。
除了使用控制台,可以通过Linux命令查看显存的使用情况watch -n 1 nvidia-smi
知识点总结
Llama3模型简介
Llama3是Meta推出的最新一代大型语言模型(LLM),它基于Llama2架构进行了进一步的优化和增强。Llama3在性能和可扩展性方面进行了显著提升,能够轻松处理多步骤任务。通过改进的后训练过程,Llama3显著降低了错误拒绝率,提高了回应的一致性,并增加了模型答案的多样性。此外,Llama3在推理、代码生成和指令执行等能力上都有显著提升。
Llama3模型提供了两种规模的版本:8B参数和70B参数,每种规模都有基础(预训练)版本和指令调优版本。所有版本的模型都可以在各种消费级硬件上运行,并且具有8K令牌的上下文长度。
模型训练的三个阶段:
模型训练通常包括三个阶段:Self-Supervised Pre-Training(自监督预训练)、Self-Supervised Fine-Tuning(自监督微调)和Reinforcement Learning with Human Feedback(强化学习与人类反馈)。
-
Self-Supervised Pre-Training (SFT):
在这个阶段,模型通过大规模的未标记数据(如Masked Language Model(MLM)或Next Sentence Prediction(NSP))进行自监督预训练,学习捕捉数据中的模式和特征。这有助于模型建立起对数据的基本理解和知识。 -
Self-Supervised Fine-Tuning (SSFT):
在自监督微调阶段,模型使用少量标记数据对预训练模型进行微调,以适应特定任务或领域的要求。微调过程有助于提升模型在特定任务上的性能和泛化能力。 -
Reinforcement Learning with Human Feedback (RLHF):
在这一阶段,模型通过与人类交互和接收人类反馈来进一步优化和改进。强化学习算法被用于指导模型在与环境互动时学习最优策略,同时结合人类反馈提供额外的指导和调整。
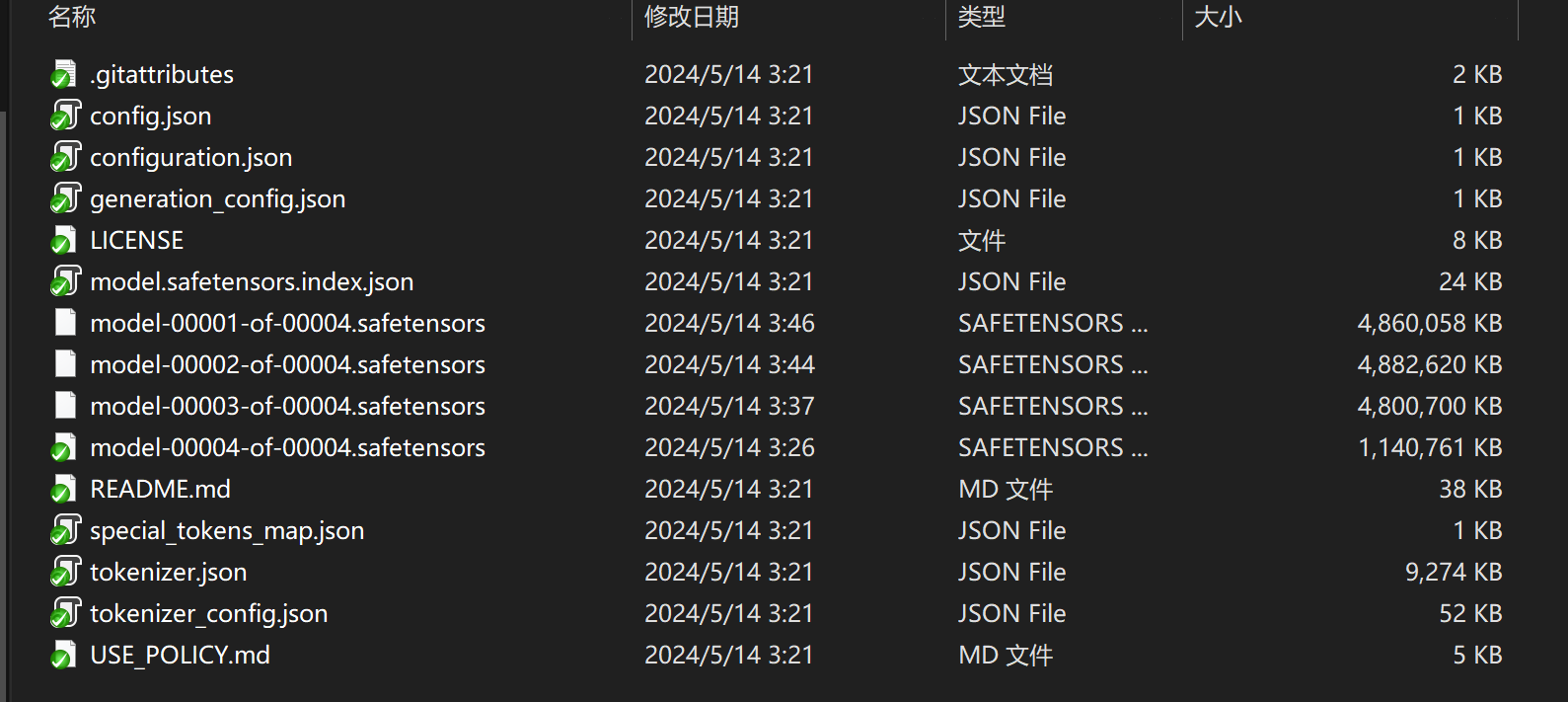
Llama3模型文件解析:
- config.json: 这个文件通常包含有关模型或工具的配置信息,例如超参数设置、模型结构等。
- configuration.json: 与 config.json 类似,用于存储模型或工具的配置信息,可能包含不同的设置和参数。
- generation_config.json: 这个文件可能包含生成文本时的配置信息,如生成文本的长度、温度等参数。
- model.safetensors.index.json: 这个文件可能是模型的索引文件,用于快速访问模型中的张量数据。
- model-00001-of-00004.safetensors: 这是模型的安全张量文件,可能包含模型的权重和参数数据。
- special_tokens_map.json: 这个文件通常包含特殊标记(special tokens)的映射,用于处理特殊标记在模型中的表示方式。
- tokenizer.json: 存储了分词器(tokenizer)的配置信息和规则,用于将文本转换为模型可处理的输入格式。
- tokenizer_config.json: 与 tokenizer.json 类似,包含有关分词器配置的信息,例如词汇表、分词规则等。
欢迎关注公众号以获得最新的文章和新闻




