前言
上节课主要学习了机器学习的基本项目流程,具体请见【课程总结】Day1:人工智能的核心概念。
本章学习的内容主要是机器学习最简单的一个算法:KNN算法。
为了对算法有个直观理解,今天的课程整体的过程概括为:
1、实例代入:先从一个经典的例子 鸢尾花分类 问题代入,理解机器学习的基本过程,即:分析问题 → 采集数据 → 遴选算法 → 代码实现 → 部署集成
2、代码实现:结合上述问题,通过 sklearn 实现KNN的使用过程,即:构建模型→训练模型→使用模型预测
实例代入:鸢尾花分类
问题场景

鸢尾花(Iris)是一种常见的花卉植物,其分类有多种不同的品种,其中最为著名的有三种
- 山鸢尾(Iris setosa):具有短而直立的叶子和鲜艳的花朵,生长在寒冷气候下。
- 杂色鸢尾(Iris versicolor):叶子宽大而扁平,花朵颜色丰富,常见于北美洲湿地。
- 长鞘鸢尾(Iris virginica):叶片弯曲,花朵大而丰满,生长在湿润的土壤中。
第一步:分析问题
定义问题
分析我们要解决的问题,即:给定一朵鸢尾花,让机器判断是三种类别中的哪一种类别。
分析输入/输出
输入:花
输出:类别
数字化实体(entity)
由于我们需要通过机器来进行处理,所以首要需要解决的问题是:如何数字化实体
-
一般数字化实体的方式是:通过这个实体的特征(或属性)来刻画这个实体,例如:
刻画一个人可以通过年龄、性别、国籍…来刻画,同理一朵花可以用相关属性(如:颜色、大小、重量…..来刻画)
-
具体选择什么特征,需要根据实际业务场景来进行定义(如:找业务专家通过业务场景进行特征定义)。
-
在本例中的问题,由于鸢尾花的三个类别通过颜色、大小是无法区分的,主要是通过花瓣来进行分类,具体是:花瓣长、花瓣宽、花萼长、花萼宽
明确输入/输出
通过以上分析,我们即可以明确输入输出:
- 输入:花瓣长、花瓣宽、花萼长、花萼宽
- 输出:花的类别
备注:
1、花的类别可以用数字编号,例如:从0,1,2进行类别编号
2、有上述可以得到一个样本内容格式为:花瓣长,花瓣宽,花萼长,花萼宽,类别编号
第二步:采集数据
采集训练的数据,这一过程一般需要根据上述的样本内容格式,人工采集和标注相关的数据。
在scikit-learn(sklearn)中,鸢尾花数据集(Iris dataset)是一个经典的示例,常用于机器学习算法的演示和测试。该数据集由Fisher在1936收集整理,数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
由此,我们直接使用sklearn中开源的数据集,加载并打印数据集的方法如下:
from sklearn.datasets import load_iris
iris = load_iris()
# 特征数据
X = iris.data
# 目标值
y = iris.target
print("特征数据:")
print(X)
print("\n目标值:")
print(y)运行结果:


备注:如果sklearn不能使用,需要先用pip install sklearn安装对应的组件包,具体方法可以见Python sklearn实现SVM鸢尾花分类
第三步:遴选算法,完成输入到输出的映射
常见分类算法
- KNN:K紧邻算法
- GNB:高斯贝叶斯
- DT:决策树算法
- SVM:支持向量机
- RF:随机森林算法
- 集成学习算法
以上算法都可以进行分类,在本章学习中主要使用了KNN算法。
数据切分
在使用算法之前,我们需要将数据集划分为两部分:train和test,train用来训练使用,test来进行测试验证训练后的模型。
在sklearn中有train_test_split的库可以帮助我们快速进行数据集的切分,具体代码如下:
from sklearn.datasets import load_iris
# 加载开源库中的iris数据集
X,y = load_iris(return_X_y=True)
# 数据集切分
from sklearn.model_selection import train_test_split
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
shuffle=True,
random_state=0)
# test_size=0.2代表拿20%用于测试集
# shuffle=True 代表洗牌,即将样本打乱顺序,
# 例如:样本y的样本是按照顺序0、1、2进行组成
# 使用shuffle之后返回的y_train是随机打乱的
# 备注:打乱的时候,X和y是同步进行的,例如第10个数据X打乱到样本最后一个,那么同步Y也会打乱到样本最后一个
# 默认情况下,每次执行都是随机的;如果设定random_state随机种子的话,那么随机是可回溯的。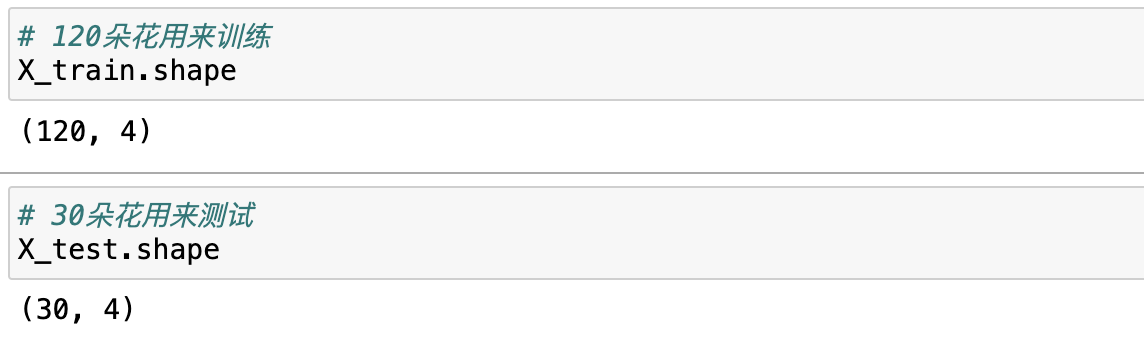
模型训练和预测
# 引入一个模型
from sklearn.neighbors import KNeighborsClassifier
# 1,构建模型
knn = KNeighborsClassifier()
# 2,训练模型
knn.fit(X=X_train, y=y_train)
# 3, 预测,将结果保存到y_pred
y_pred = knn.predict(X=X_test)查看knn.predict返回的y_pred结果
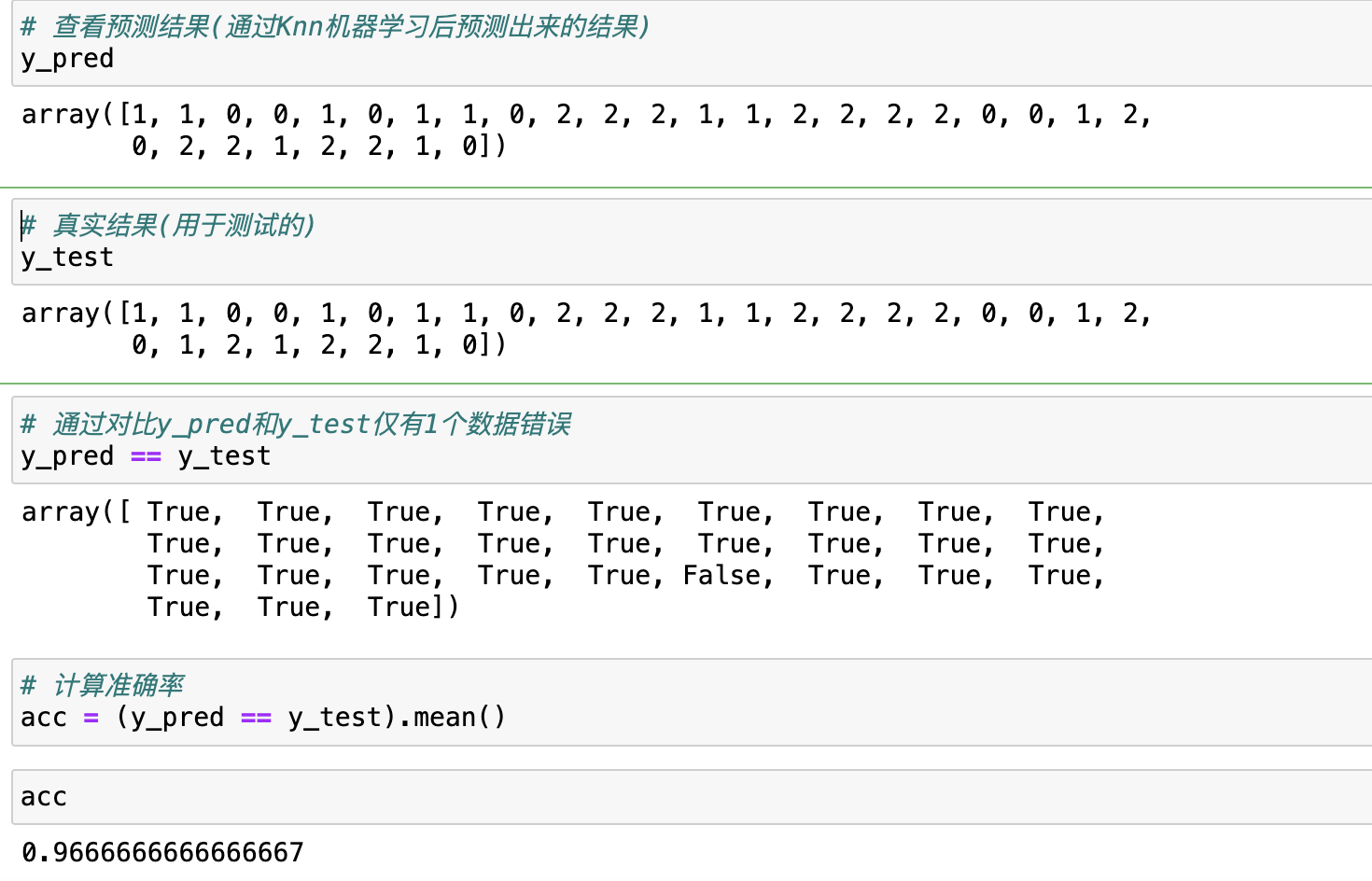
由此,我们完成了Knn算法从加载数据→切分数据→模型构建→模型训练→模型预测的基本使用过程。
除此之外,我们还可以使用决策树和向量机来实现上述分类,示例代码如下:
# 决策树分类示例
from sklearn.tree import DecisionTreeClassifier
# 1, 构建模型
dtc = DecisionTreeClassifier()
# 2, 训练模型
dtc.fit(X=X_train, y=y_train)
# 3, 预测
y_pred2 = dtc.predict(X=X_test)
acc = (y_pred2 == y_test).mean()
# 查看准确率
acc# 向量机分类示例
from sklearn.svm import SVC
# 1, 构建模型
svc = SVC()
# 2, 训练模型
svc.fit(X=X_train, y=y_train)
# 3, 预测
y_pred3 = svc.predict(X_test)
acc = (y_pred3 == y_test).mean()
# 查看准确率
acc备注:sklearn官网有多种分类算法,具体可以查看官网https://scikit-learn.org/stable/
第四步:部署集成
由于模型最终是需要部署到生产环境去使用的,所以在部署集成这个环节,主要工作是两部分:
- 开发环境:序列化–>训练模型并把模型文件保存到硬盘上
- 生产环境:反序列化–>把模型从硬盘加载到内存中去使用
序列化方法
序列化时,可以使用python内置的一个joblib组件的dump方法来实现。
import joblib
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载开源库中的iris数据集
X,y = load_iris(return_X_y=True)
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
shuffle=True,
random_state=0)
# 1,构建模型
knn = KNeighborsClassifier()
# 2,训练模型
knn.fit(X=X_train, y=y_train)
# 3,将knn对象保存到硬盘上
joblib.dump(value=knn, filename="knn.aura")通过以上代码,我们将构建的模型对象knn转储了一份二进制文件到本地磁盘上,其文件为knn.aura
备注:如果本机没有安装joblib,需要使用pip install joblib安装对应组件
反序列化方法
在生成环境,通过joblib组件的load方法来加载之前保存好的模型文件。
import numpy as np
import joblib
knn = joblib.load(filename="knn.aura")
# 因为预测时是批量预测,所以如果我们想模拟一个数据集传入时,需要在两侧再加上一个[],将数据构建成一个二维数组才能预测使用。
# 如果不构建为二维数组,直接传入一维,模型会报"ValueError: Expected 2D array, got 1D array instead"的错误
X = np.array([[4.9, 3.1, 1.5, 0.1]])
# 对数据4.9, 3.1, 1.5, 0.1进行预测
y = knn.predict(X=X)
# 查看预测结果
y

可以看到,上述4.9, 3.1, 1.5, 0.1的预测结果为0。
KNN算法
KNN算法简述
-
KNN(K-Nearest Neighbor)(又称k最邻近算法)算法是机器学习算法中最基础、最简单的算法之一。KNN通过测量不同特征值之间的距离来进行分类。 -
KNN算法是一种非常特别的机器学习算法,因为它没有一般意义上的学习过程。它的工作原理是利用训练数据对特征向量空间进行划分,并将划分结果作为最终算法模型。
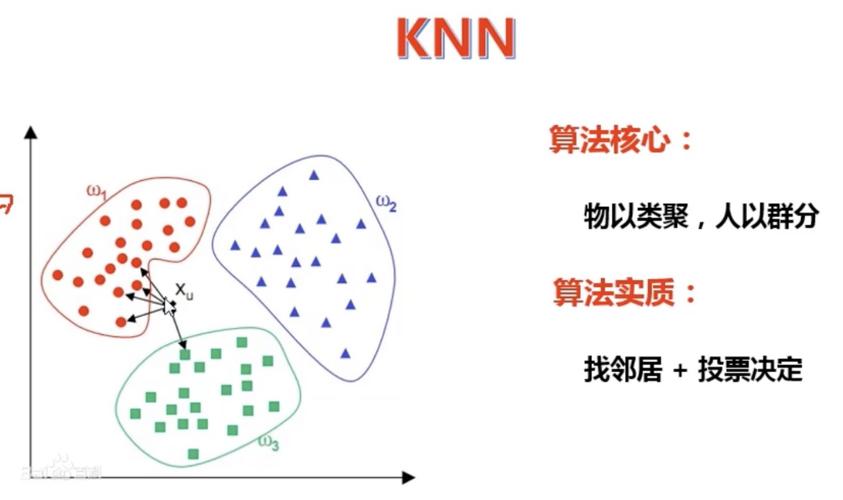
KNN算法核心思想
近朱者赤,近墨者黑
通俗的讲:假设要判断一个人是什么样的人,那么就看这个人跟什么样的人在一起,
是人工智能的第一思想,它认为好人堆里的人坏不到哪儿去,坏人堆里的人好不到哪儿去,是一种统计思想。近邻思想
KNN推理过程
- K-Nearest Neighbors 又称
k最邻近算法,所以核心在于K个最近的邻居
其推理过程是:(以上述给定一朵花,判定它是第几类为例)
- 找出这朵花的 K 个 最近的邻居
- 找到最近的 K 个邻居,K个邻居进行投票,选出类别出现次数最多的类别
如下图示例:
-
当预测一个新样本(图中绿色的点)的类别时,根据它距离最近的 K 个样本点(假设K=3)是什么类别来判断该新样本属于哪个类别(多数投票)。
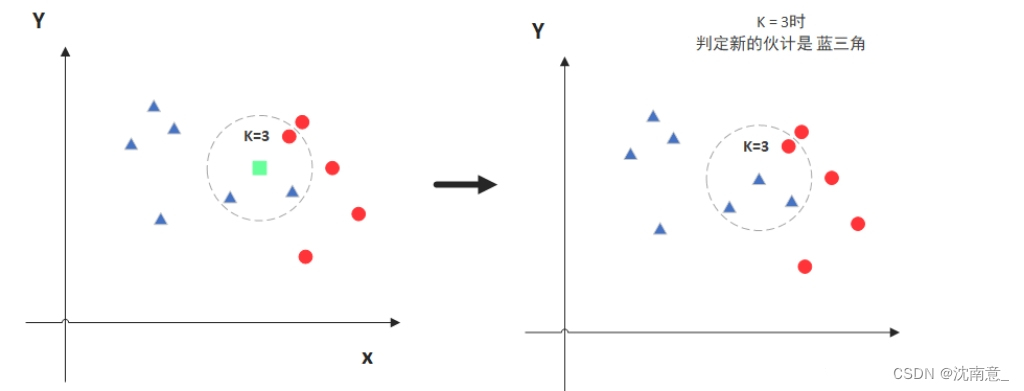
-
那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
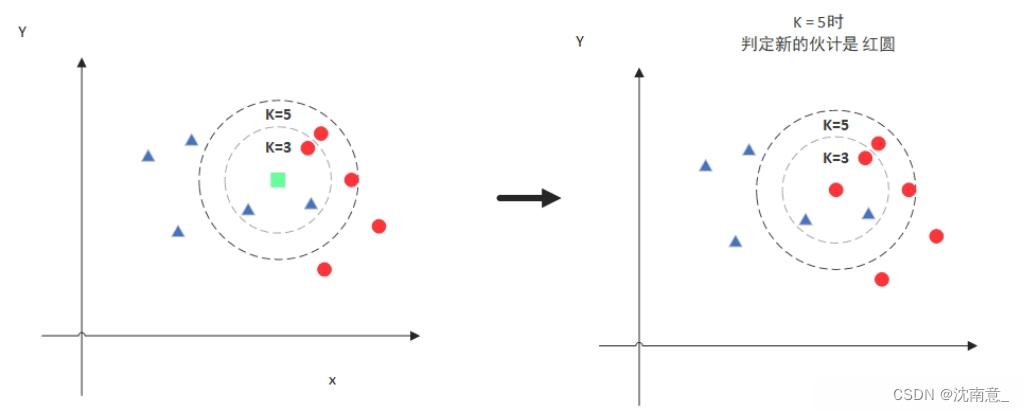
-
当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。
K值是超参数,可以由人来指定。
KNN算法中的相似度度量
在KNN算法中,有多种计算相似度的方法,一般来说有:几何视角(欧式空间)和线性代数视角(余弦相似度)两种。
几何视角(欧式空间)
距离计算,即勾三股四弦五,计算两点之间的直线距离,距离越短越相似。
欧式距离计算公式
在二维空间中,两点之间的欧式距离计算公式为:
\text{欧式距离} = \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2}在多维空间
\ P = (p_1, p_2, ..., p_n)和
\ Q = (q_1, q_2, ..., q_n)之间的欧式距离计算公式为:
\text{欧式距离} = \sqrt{\sum_{i=1}^{n} (q_i - p_i)^2}欧式距离计算代码实现
# 欧式距离计算示例
import numpy as np
a = np.array([2, 5])
b = np.array([1, 8])
# 计算a和b之间的距离
# 公式解析:
# a - b:相当于x1 - x2,y1 - y2
# (a - b) ** 2:相当于(x1-x2)的平方和 (y1-y2)的平方
# ((a - b) ** 2).sum():相当于(x1-x2)的平方 + (y1-y2)的平方
# np.sqrt是求平方根
c = np.sqrt((a - b)** 2 ).sum()
c计算结果:

线性代数视角(向量视角)
线性代数视角(向量视角):计算余弦相似度,余弦相似度越高越相似。
余弦相似度计算公式
两个向量A和B
\text{余弦相似度} = \frac{A \cdot B}{\|A\| \cdot \|B\|}其中,
A \cdot B 表示向量 A 和 B 的点积(内积),|A| 和 |B| 分别表示向量 A 和 B 的范数(模长)。
该计算方法特别适用于处理高维稀疏数据。余弦相似度计算方法衡量了两个向量之间的夹角,而不仅仅是它们之间的距离。
余弦相似度计算代码实现
import numpy as np
# 余弦相似度计算(计算两个向量求内积)
a = np.array([2, 5])
b = np.array([1, 8])
# 计算内积有两种方法:
# 第一种:计算a和b的内积
ret = (a * b).sum()
print(f"第一种计算方法:内积= {ret}" )
# 第二种:使用@是内积计算方法
ret = a @ b
print(f"第二种计算方法:内积= {ret}")
# 第三种:使用np.dot计算内积
ret = np.dot(a, b)
print(f"第三种计算方法:内积= {ret}")
# 计算余弦相似度
# 公式解析:
# a @ b:计算a和b的内积
# np.linalg.norm(a):计算a的模,相当于np.sqrt((a ** 2).sum())
cosine_similarity = a @ b / np.linalg.norm(a) / np.linalg.norm(b)
cosine_similarity运行结果:

备注:除上述两种相似度度量之外,还有曼哈顿距离、汉明距离
KNN推理过程代码实现(不使用sklearn内置函数)
import numpy as np
from collections import Counter
class MyKNeighborsClassifier(object):
"""
自定义KNN分类器
"""
def __init__(self, n_neighbors=5):
"""
初始化方法:
- 输入:设置超参(Hyper-Parameter,即人为指定的,不是系统学习的参数)
- 输出:无输出
"""
# 超参设置
self.n_neighbors = n_neighbors
def fit(self, X, y):
"""
训练过程
- 输入:
- X:训练集的特征
- y:训练集的标签
"""
# 类型转换
X = np.array(X)
y = np.array(y)
self.X = X
self.y = y
# 形状校验
# 如果X不是二维数组,或者y不是一维,或者x的样本数量与y的样本数量不同
if X.ndim != 2 or y.ndim != 1 or X.shape[0] != y.shape[0]:
raise ValueError('入参有误')
def predict(self, X):
"""
预测过程:
- 输入:
- X:待预测的样本的特征(批量)
- 输出:
- y:预测的类别
"""
# 对X进行类型转换
X = np.array(X)
# 形状校验
# 如果X不是2个维度,或者最后一个维度
if X.ndim != 2 or X.shape[-1] != self.X.shape[-1]:
raise ValueError("入参有误")
# 推理过程
results = []
# 从样本集self.X中逐个取出进行处理
for x in X:
# 第一步:找 K 个好友(使用欧式距离)
# 函数解析:
# 1.所有的样本self.X都减去x
# 2.然后求平方和再开根号,计算得到欧式距离
distances = np.sqrt(((self.X - x) ** 2).sum( axis= -1))
# 第二步:对 K 个好友的进行倒序排序
# 函数解析:使用np.argsort得到最近好友的序号
# 特别注意:这里排序不是求好友的距离,而是求最近的好友是谁
idxes = np.argsort(distances)[:self.n_neighbors]
# 第三步:取出好友的类别
labels = self.y[idxes]
# 第四步:计算出现次数最多的类别
# 函数即系:使用collections的Counter可以方便得到出现次数最多的类别
label = Counter(labels).most_common(1)[0][0]
# 第五步:将类别结果添加到results方便返回
results.append(label)
return np.array(results)
# 1, 构建模型
my_knn = MyKNeighborsClassifier()
# 2, 训练
my_knn.fit(X=X_train, y=y_train)
# 3, 预测
y_pred = my_knn.predict(X=X_test)
# 4, 计算准确率
acc = (y_pred == y_test).mean()
# 5, 输出准确率
acc运行结果:

内容小结:
-
机器学习的应用基本流程:
分析问题→采集数据→遴选算法→部署集成 -
分析问题:
- 要考虑输入输出是什么,输入输出要数字化实体
- 数字化实体一般是通过实体的特征(或属性)来刻画,具体选择特征要根据业务场景来定义
-
采集数据:
- 采集后的数据,可以通过train_test_split进行数据切分为训练数据和测试数据
- 测试数据主要用来验证,不能用作训练
-
遴选算法:
- 分类场景下有多种算法,常用的有Knn
- 使用算法的三个基本步骤:构建模型、训练模型(fit)、预测(predict)
-
部署集成:
- 部署集成本质上就是序列化和反序列化过程
- 序列化和反序列化时可以使用joblib的dump和load方法
-
KNN算法也叫K最近邻算法
-
KNN算法核心思想:近朱者赤,近墨者黑
-
KNN算法推理过程:找出 K 个 最近的邻居 → K个邻居进行投票,选出类别出现次数最多的类别
-
KNN的相似度度量有多种方法,几何视角是欧式距离,向量视角是余弦相似度
参考资料:
欢迎关注公众号以获得最新的文章和新闻



