
前言
本篇文章,我们将通过示例来逐步学习理解导数、求函数最小值、深度学习的本质、以及使用numpy和pytorch实操深度学习训练过程。
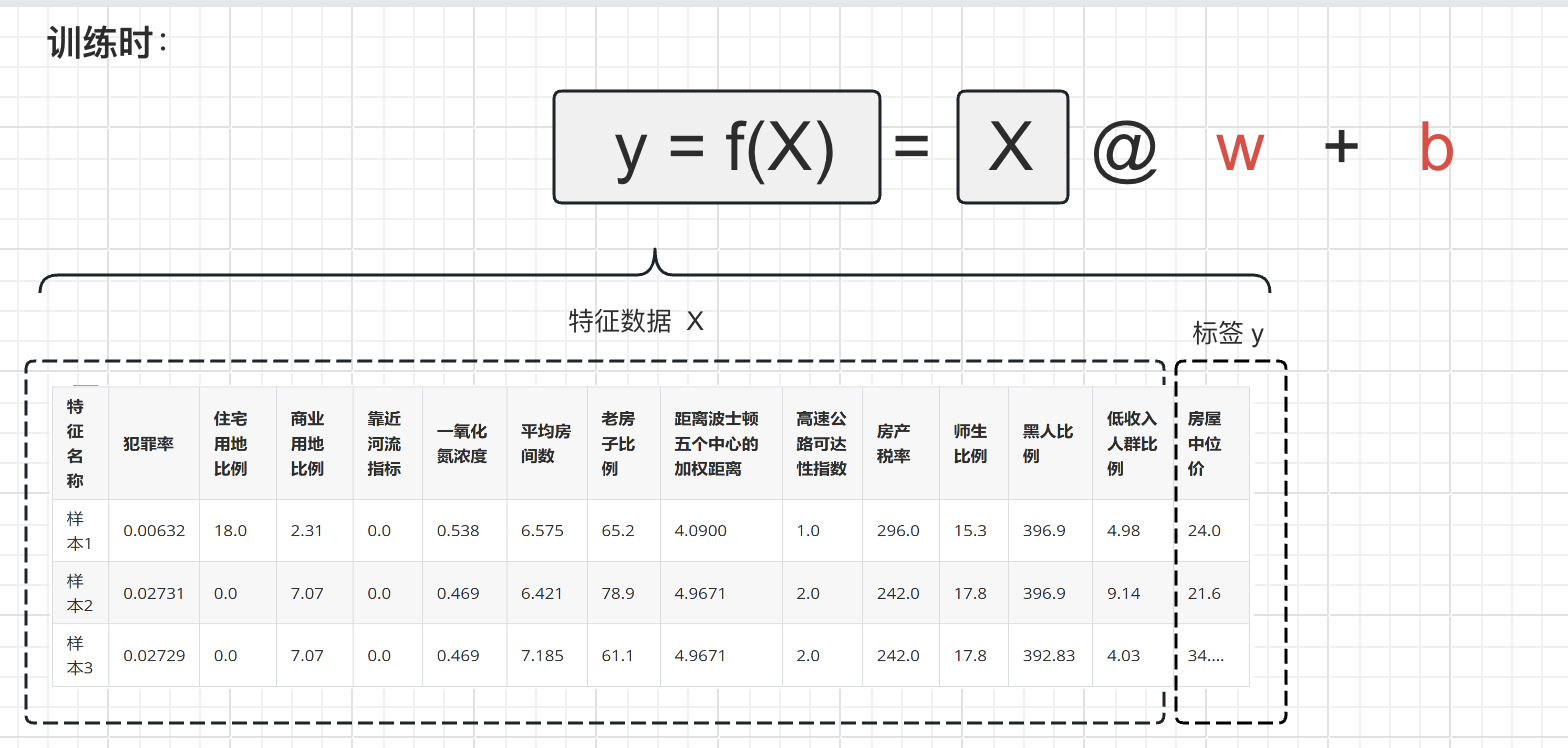
线性回归
线性回归内容回顾
在《【课程总结】Day5(下):PCA降维、SVD分解、聚类算法和集成学习》中,我们已经了解到线性回归以及线性回归可以表示为:
y=f(x)=x_1w_1 + x_2w_2 + ... + x_{13}w_{13} + b
其中:
- ( x1, x2, …, x_{13} ):输入特征向量 ( x ) 的各个特征值,代表输入数据的各个特征。
- ( w_1, w2, …, w{13} ):权重向量 ( w ) 的各个权重值,用来衡量每个特征对输出的影响程度。
- ( b ):偏置项,也称为截距项,用来调整模型的输出值,即在没有特征输入时的输出值。
- ( y ):模型的输出值,即线性回归模型对输入特征的预测值。
该公式也可以表示为内积相乘的方式,如下:
y=f(x)=x@w+b
其中:
x@w:特征向量 ( x ) 与 权重向量( w ) 的内积
如果有多个样本的话,那么上面的公示可以进一步表示为:
y=f(X)=X@w+b
其中:
X代表特征矩阵,矩阵的行为一条一条的样本,矩阵的列为多个特征向量。
线性回归方程的解析
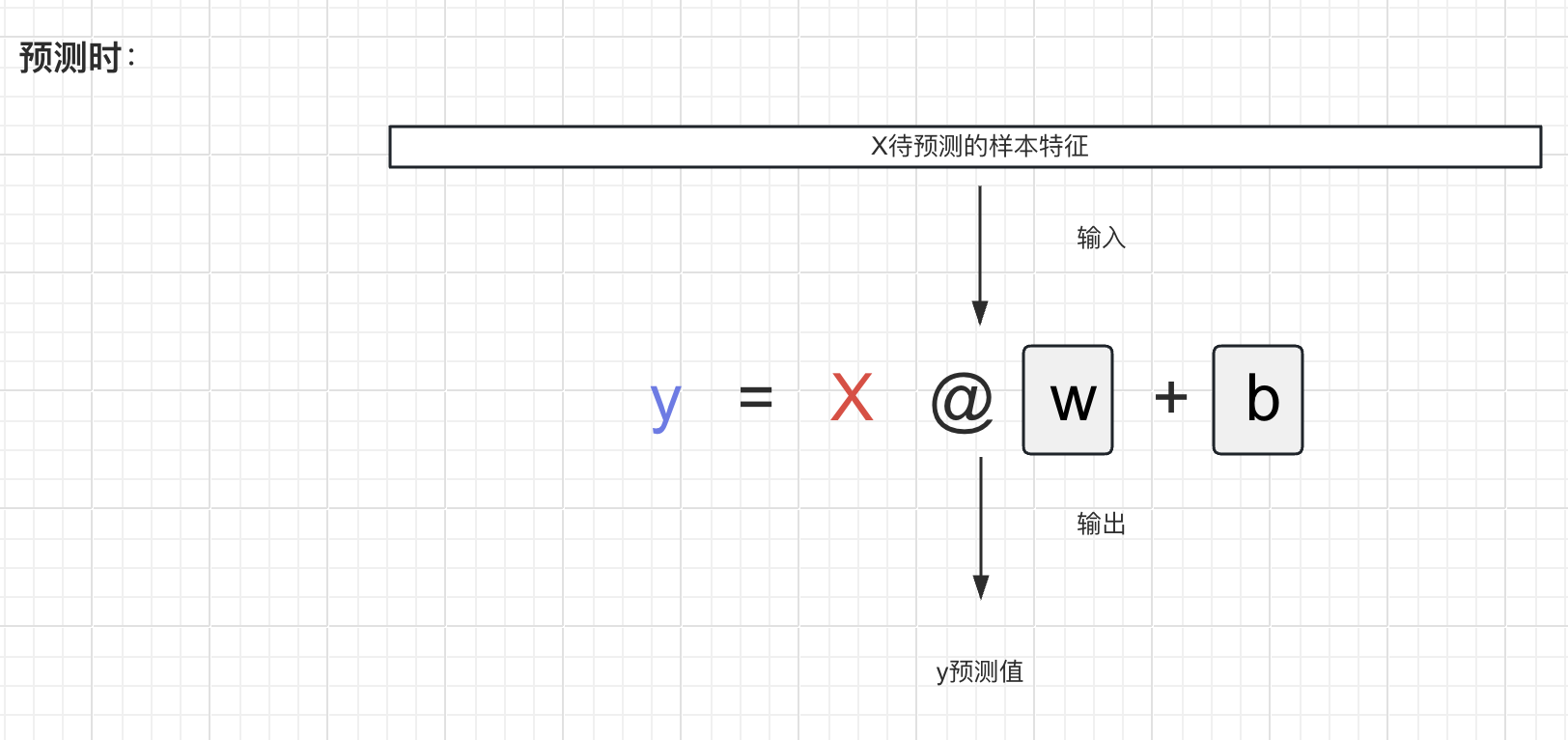
- 在训练时,
x和y是训练集中的特征和标签,看作是常量;w和b是待优化的参数值,看作是变量。 - 在推理时,
w和b已经找到了比较合适的值固定下来,看作常量;此时x是待预测的样本的特征,是变量; - 预测的本质:把x带入,求解y。
线性回归=求损失loss函数的最小值
训练过程
由上图可知,训练的大致过程是:

- 从训练集中取出一对x 和y
- 把x带入模型,求解预测结果y_pred
- 找到一种方法,度量y和y_pred的误差loss
- 由此推导:
- loss是y和y_pred的函数;
- y_pred是模型预测的结果,是w和b的函数;
- 所以简单来说,loss也是w和b的函数
训练的本质
由上图推导结果可知,训练的本质:求解loss什么时候是最小值。
数学表达:当w和b取得什么值的时候,loss最小
通俗表达:求loss函数的最小值
如何求函数的最小值?
一个例子
y = 2x^2

上述这个示例中,求y最小值是比较简单的,从图形中可以看到x=0时,y=0为最小值。但是实际工程中,并不是所有的函数y=f(x)都能画出来,简单地找到最小值,此时就需要使用导数求最小值。
如果你和我一样忘了导数相关的知识,可以查看《【重拾数学知识】导数、极值和最值》回顾一下。
求解方法(理论方法)
通过回归导数求极值的方法,我们知道大致步骤如下:
- 第一步:求函数的导数
- 第二步:令导数等于零
- 第三步:解方程,求出疑似极值点
- 第四步:验证该点是否是极值点以及是什么极值点
求解的问题
上述的方法是有一定前提条件的,即:
- 第一步的求(偏)导数是可以求得的;
- 第三步(偏)导数为零后,方程(组)是可以解的。
实际工程中,上述方法是不可行的。以Llama3-8B模型为例,其有80亿个输入参数x,按照上述的求解方法是无法求得最小值的!
由此可知,通过推导公式期望一次性求得最小值是不现实的;而我们可以借鉴人工智能中一个重要的思想:迭代法来逐步求解最小值。
求解方法(迭代法)
仍然以y = 2x^2为例,我们可以通过以下方法求得最小值。
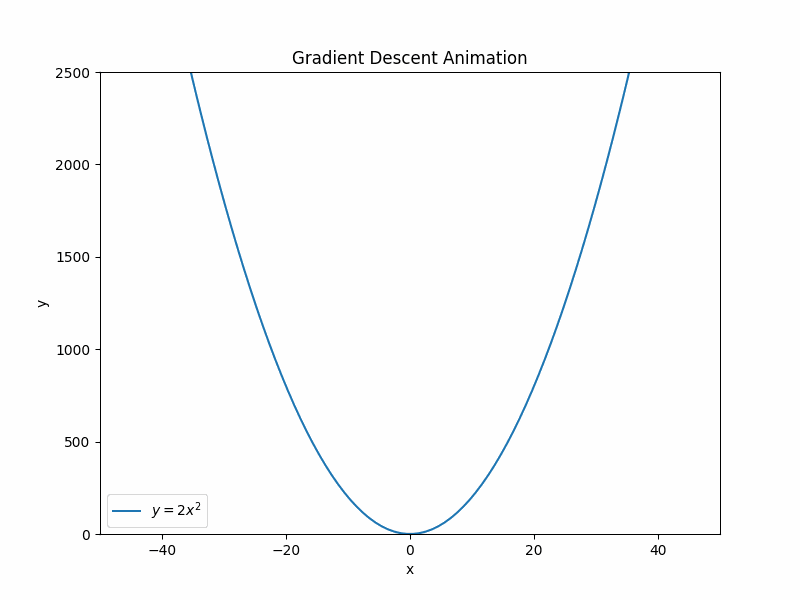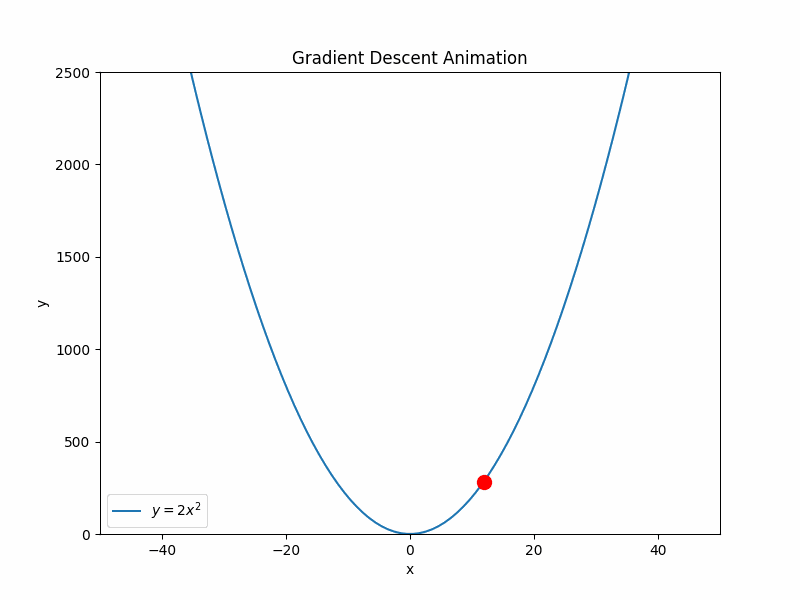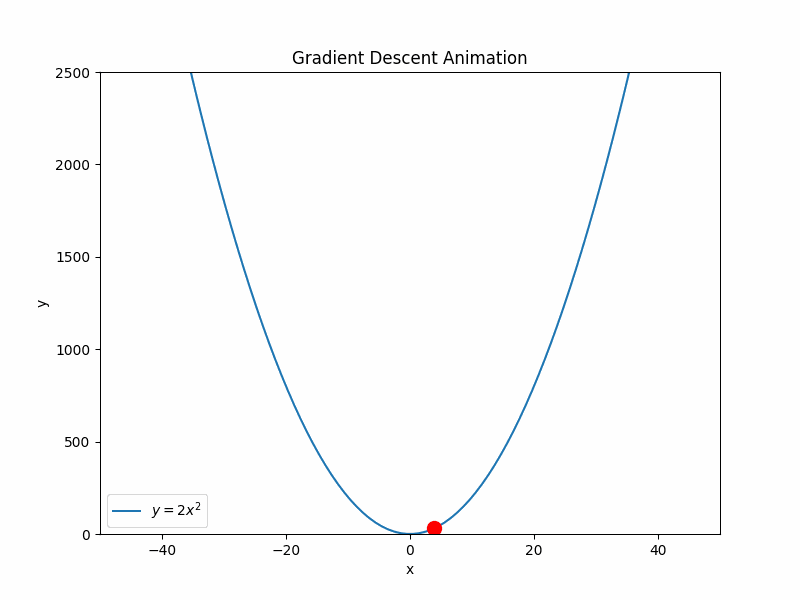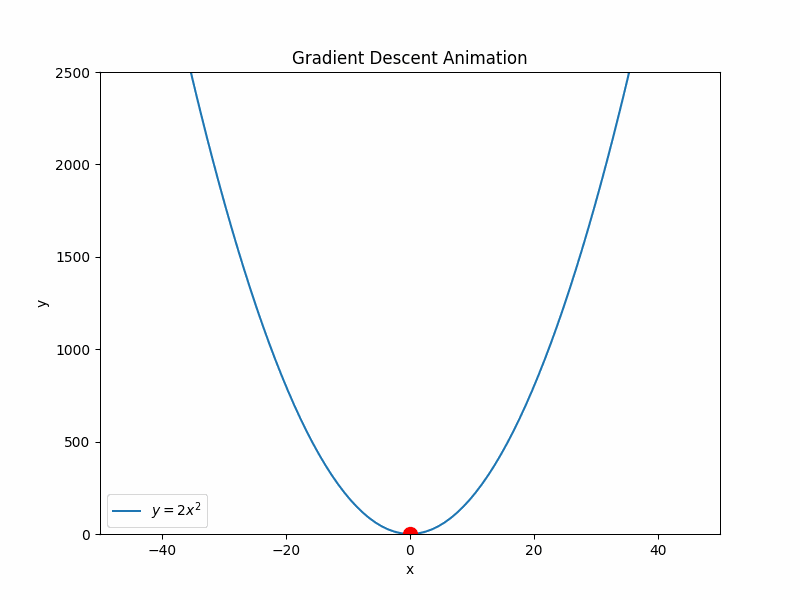
随机选择一个出生点x_0,
- 当
x_0在最小值的左侧时,x_0+ 正数(一个非常小的正数)向右侧移动; - 当
x_0在最小值的右侧时,x_0– 正数(一个非常小的正数)向左侧移动; - 当
x_0在最小值的时候,不用移动,此时就是最小值。
由导数的单调性可知:
- 当
x_0在左侧时,由于函数是单调递减的,所以导数<0 - 当
x_0在右侧时,由于函数是单调递增的,所以导数>0
因此上述的计算方法可以推导得到:
-
当
x_0在0的左侧时,x_0+ 正数 →x_0+ 导数 →x_0– 导数因为导数<0,加上一个小于的导数相当于减去导数
-
当
x_0在0的右侧时,x_0– 正数 →x_0– 导数因为导数>0,减去一个大于的导数相当于减去导数
-
当
x_0=0时,也可以看作是x_0– 导数
由此,我们可以得到结论:不管x_0在何处,求最小值时减去导数即向极值逼近。
概念补充
- 在一元函数中,求函数f(x)在某一点的斜率为导数;在多元函数中,称为偏导数,也就是梯度。
-
减去导数也就是减去梯度,这就是梯度下降法!
备注:深度学习在兴起之前,人工智能只能靠支持向量机撑门面;伴随着互联网+GPU芯片的兴起,梯度下降法拥有了使用的土壤,以此人工智能才真正兴起。
代码实现(手动求函数最小值)
以y = 2x^2为例
import numpy as np
def fn(x):
"""
原始函数
"""
return 2 * x ** 2
def dfn(x):
"""
导函数
"""
return 4 * x
def gradient_descent(x0, learning_rate, dfn, epochs):
"""
使用梯度下降法求函数的最小值
Parameters:
x0 (float): 初始点的位置
learning_rate (float): 学习率
dfn (function): 导函数
epochs (int): 迭代次数
Returns:
x_min (float): 最小值点的位置
"""
for _ in range(epochs):
x0 = x0 - learning_rate * dfn(x0)
return x0
# 随机选择一个出生点
x0 = np.random.randint(low=-1000, high=1000, size=1)
# 迭代次数
epochs = 1000
# 学习率
learning_rate = 1e-2
# 使用梯度下降法求最小值
x_min = gradient_descent(x0, learning_rate, dfn, epochs)
# 输出最小值
print("最小值点的位置:", x_min)运行结果:
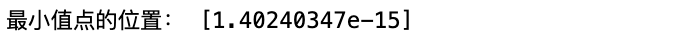
以f(x,y,z) = x^2 + y^2 + z^2为例
import numpy as np
def df_x(x, y, z):
"""
f 对 x 求偏导
"""
return 2 * x
def df_y(x, y, z):
"""
f 对 y 求偏导
"""
return 2 * y
def df_z(x, y, z):
"""
f 对 z 求偏导
"""
return 2 * z
# 随机选择出生点
x0 = np.random.randint(low=-1000, high=1000, size=(1,))
y0 = np.random.randint(low=-1000, high=1000, size=(1,))
z0 = np.random.randint(low=-1000, high=1000, size=(1,))
# 迭代次数
epochs = 1000
# 学习率
learning_rate = 1e-2
for _ in range(epochs):
# 求解每个变量的偏导
fx = df_x(x0, y0, z0)
fy = df_y(x0, y0, z0)
fz = df_z(x0, y0, z0)
# 每个变量都减去自己的偏导
x0 = x0 - learning_rate * fx
y0 = y0 - learning_rate * fy
z0 = z0 - learning_rate * fz
# 输出更新后的变量值
print("更新后的 x 值:", x0)
print("更新后的 y 值:", y0)
print("更新后的 z 值:", z0)运行结果:

代码实现(使用pytorch求函数最小值)
上述通过求导数得到函数最小值的方法,也可以通过pytorch来实现,具体代码如下:
以y = 2x^2为例
import torch
# 定义原始函数和导函数
def fn(x):
return 2 * x ** 2
# 说明:pytorch可以通过grad函数求导,所以可以省去写导函数
# def dfn(x):
# return 4 * x
# 随机选择出生点
# requires_grad=True用来告诉框架该变量是一个张量,需要计算梯度。
x0 = torch.randint(low=-1000, high=1001, size=(1,),
dtype=torch.float32,
requires_grad=True)
# 迭代次数
epochs = 1000
# 学习率
learning_rate = 1e-2
# 使用 PyTorch 进行梯度下降
for _ in range(epochs):
# 正向传播计算损失
loss = fn(x0)
# 反向传播计算梯度
loss.backward()
# 获取梯度并更新参数
with torch.no_grad():
grad = x0.grad
x0 -= learning_rate * grad
# 梯度清零
x0.grad.zero_()
# 输出最小值点的位置
print("最小值点的位置:", x0.item())运行结果:

以f(x,y,z) = x^2 + y^2 + z^2为例
import torch
def fn(x, y, z):
"""
函数定义
"""
return x**2 + y**2 + z**2
# 说明:pytorch可以通过grad函数求导,所以可以省去写导函数
# def df_x(x, y, z):
# return 2 * x
# def df_y(x, y, z):
# return 2 * y
# def df_z(x, y, z):
# return 2 * z
# 随机选择出生点
x0 = torch.randint(low=-1000, high=1001, size=(1,),
dtype=torch.float32,
requires_grad=True)
y0 = torch.randint(low=-1000, high=1001, size=(1,),
dtype=torch.float32,
requires_grad=True)
z0 = torch.randint(low=-1000, high=1001, size=(1,),
dtype=torch.float32,
requires_grad=True)
# 迭代次数
epochs = 1000
# 学习率
learning_rate = 1e-2
# 使用 PyTorch 进行梯度下降
for _ in range(epochs):
# 正向传播计算损失
loss = fn(x0, y0, z0)
# 反向传播计算梯度
loss.backward()
# 获取梯度并更新参数
# 在测试阶段或者不需要计算梯度的情况下使用 torch.no_grad()
# 以提高计算效率并避免不必要的梯度计算。
with torch.no_grad():
x0 -= learning_rate * x0.grad
y0 -= learning_rate * y0.grad
z0 -= learning_rate * z0.grad
# 梯度清零
x0.grad.zero_()
y0.grad.zero_()
z0.grad.zero_()
# 输出更新后的变量值
print("更新后的 x 值:", x0.item())
print("更新后的 y 值:", y0.item())
print("更新后的 z 值:", z0.item())运行结果:

内容小结
-
线性回归
- 在训练时,
x和y是训练集中的特征和标签,看作是常量;w和b是待优化的参数值,看作是变量。 - 在推理时,
w和b已经找到了比较合适的值固定下来,看作常量;此时x是待预测的样本的特征,是变量; - 预测的本质:把x带入,求解y。
- 在训练时,
-
求损失loss函数
- 由训练的过程可知:损失函数loss也是w和b的函数
- 训练的本质:求损失loss函数的最小值
-
求函数最小值
- 理论的求解方法,在现实工程中由于参数巨大,实际不可行。
- 实际的求解方式是使用迭代思想逐步求解。
- 不管$x_0$在何处,求最小值时减去导数即向极值逼近,所以我们可以通过迭代法+迭代中减去导数求最小值,这就是梯度下降法。
-
求导即可使用numpy方法,也可以使用pytorch
- 梯度下降法使用过程中,一般需要定义epochs迭代次数、learning_rate学习率
- 梯度下降法的一般过程为:正向传播计算损失→反向传播计算梯度→获取梯度并更新参数→梯度清零
- 在循环减去梯度的过程中,需要记得使用.grad.zero_()进行梯度清零
欢迎关注公众号以获得最新的文章和新闻



